RLAnything: Forge Environment, Policy, and Reward Model in Completely Dynamic RL System
This presentation introduces RLAnything, a groundbreaking reinforcement learning framework that dynamically co-evolves three critical components: the policy model, reward model, and environment tasks through closed-loop optimization. Unlike traditional RL approaches that rely on static environments and binary outcome rewards, RLAnything integrates step-wise process rewards with outcome signals, jointly optimizes the reward model and policy through consistency feedback, and actively adapts task difficulty based on the agent's current capability. The framework demonstrates substantial improvements across GUI agents, language model agents, and code generation tasks, achieving state-of-the-art results while revealing that optimized reward signals can surpass human-written evaluation scripts.Script
What if your reinforcement learning agent could rewrite its own training tasks, evolve its reward function, and optimize its policy simultaneously? RLAnything introduces a framework where environment, policy, and reward model forge themselves together in a closed-loop optimization cycle, fundamentally rethinking how agentic systems learn.
Building on this vision, the authors identify critical gaps in current reinforcement learning for language model based agents. When tasks grow complex, simple success or failure signals become inadequate, and fixed training environments can't keep pace with rapidly improving policies.
Let's explore how RLAnything addresses these challenges through three tightly coupled dynamic components.
The framework's power emerges from tight coupling of three elements. The policy integrates step-wise and outcome rewards at each decision point, the reward model learns from its own consistency with verified results, and the environment actively rewrites tasks based on where the agent struggles or succeeds too easily.
This architectural diagram captures the essential insight: reinforcement learning benefits tremendously when step-wise process rewards complement outcome signals, when the reward model co-evolves with the policy through self-consistency, and when environment difficulty tracks the agent's growing capability. These three feedback loops create a self-improving system where each component strengthens the others.
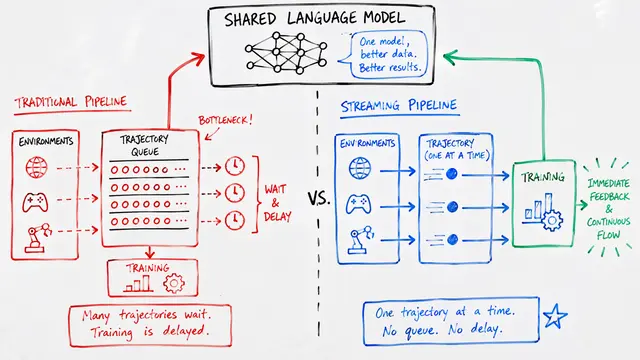
Contrasting traditional and dynamic approaches reveals the framework's advantages. The authors demonstrate theoretically that when task outcomes become skewed, reward estimation degrades significantly, but dynamic environment adaptation maintains balanced trajectories that benefit both policy generalization and reward model accuracy simultaneously.
Now let's examine how this translates into concrete performance gains.
The empirical validation is compelling across three representative domains. They achieve notable improvements in graphical user interface agents, language model agents, and code generation tasks, with RLAnything consistently outperforming both static baselines and variants with only partial dynamic components.
Perhaps most striking is this evidence of active learning from experience. The left panel shows nearly linear scaling in the number of accepted new tasks during training, demonstrating that critic-driven environment adaptation successfully synthesizes increasingly diverse challenges. Meanwhile, policy accuracy on these new tasks stabilizes, indicating robust generalization rather than overfitting to task rewrites.
The authors make a counterintuitive discovery that challenges conventional wisdom in reinforcement learning. Their optimized reward model signals, derived purely from closed-loop self-consistency, actually provide stronger learning signals than outcome labels based on human-written scripts, suggesting we may be approaching a regime where agents bootstrap their own supervision without human labeling bottlenecks.
RLAnything demonstrates that the future of reinforcement learning lies not in static components but in dynamically forged systems where environment, policy, and reward evolve together. To dive deeper into this research and explore how closed-loop optimization might transform agentic AI development, visit EmergentMind.com.