- The paper shows that maximum entropy methods can enhance the prediction of Markov transition dynamics, especially under short-sample conditions.
- It develops an analytical MaxEnt solution for two-state Markov chains under autocorrelation constraints, leading to a symmetric transition matrix.
- Empirical results demonstrate superior performance of MaxEnt over frequency sampling in non-stationary systems and financial time series risk estimation.
Maximum Entropy Methods for Enhanced Predictability in Markov Time Series
Introduction
This paper presents a rigorous adaptation of maximum entropy (MaxEnt) methods for reconstructing the transition dynamics of Markov processes from empirical time series data, with a strong focus on situations where only short samples are available. By explicitly contrasting MaxEnt-based inference with conventional frequency sampling, the authors identify substantial regimes in low-dimensional stochastic processes where MaxEnt achieves superior predictive performance, especially in contexts of smoothly non-stationary processes and practical applications such as financial time series.
Maximum Entropy Estimation of Markov Dynamics
The traditional sample-frequency approach estimates Markov transition matrices by direct empirical counting of state transitions over a historical window. In contrast, the MaxEnt approach builds the transition matrix subject to structural and empirical constraints—most notably, stationarity (enforced via detailed balance), stochasticity, normalization, and a fixed one-step autocorrelation. The entropy rate h is the natural objective for Markov processes, but due to the dependence of the stationary distribution on the unknown transition matrix, the authors maximize a surrogate entropy η, utilizing an independent distribution and enforcing stationarity via detailed balance.
For two-state (±1) Markov chains under an autocorrelation constraint, the explicit MaxEnt solution yields a symmetric transition matrix, where off-diagonal and diagonal elements directly reflect the empirical autocorrelation A:
W(ME)=(21+A21−A 21−A21+A)
This analytical tractability underpins the subsequent statistical analyses.
Employing a folded normal analysis, the authors compute the expected error (mean absolute deviation) for both MaxEnt and frequency sampling estimates of the transition parameters as a function of sample size n. They define a practical metric, nc(W), delineating the sample size threshold below which MaxEnt estimation is empirically preferable for a given transition matrix.
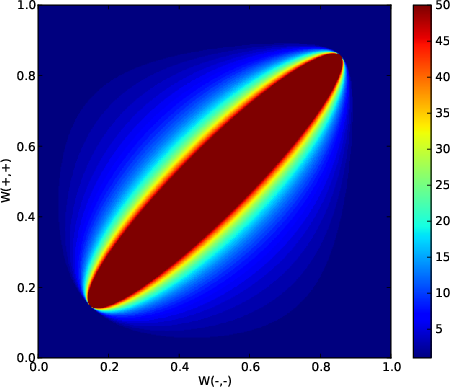
Figure 1: nc(W) plotted over the space of 2×2 stochastic matrices parametrized by W−− and W++. Regions with higher nc benefit more from MaxEnt when sample sizes are limited.
Empirical evaluation across 2×2 stochastic matrices demonstrates that up to μ(50)≈0.15, i.e., 15% of all matrices, MaxEnt yields lower estimation error for sample sizes below n=50, especially for matrices with high entropy (low predictability). Extending to three-state Markov processes, the subset of matrices favoring MaxEnt (for n=50) remains significant but reduces in proportion.
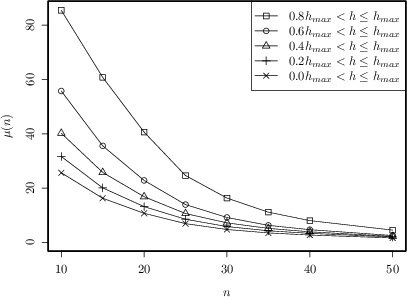
Figure 2: Percentage of favorable 3-state matrices for MaxEnt estimation versus sample size, stratified by entropy rate quintiles.
The key finding is that MaxEnt efficiency is most pronounced in high-entropy processes, which are of particular practical interest for stochastic modeling.
Application to Non-Stationary and Empirical Processes
The advantage of MaxEnt methods manifests strongly in non-stationary environments. When dynamic parameters of the Markov process evolve on timescales comparable to, or shorter than, the accessible sample window, MaxEnt can furnish more responsive estimates than frequency-based alternatives. This is because MaxEnt, by construction, leverages structural constraints and recent data, while sampling-based methods suffer from delayed adaptation due to statistical inertia.
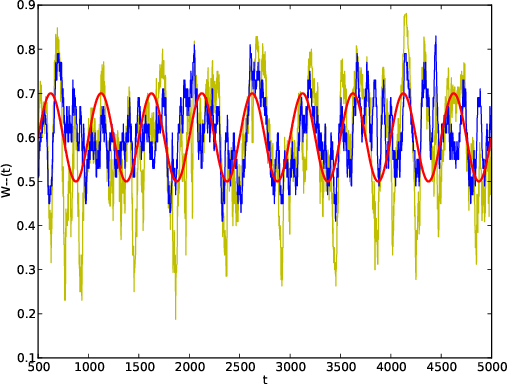
Figure 3: Temporal tracking of the true coefficient W−−(t) (red) compared to MaxEnt (blue) and sampling (yellow) based estimates on a synthetic non-stationary 2-state process.
The authors demonstrate that, for a time-varying transition matrix, MaxEnt closely tracks the true dynamics, while sampling displays lag and increased deviation, particularly when using moderate sliding window sizes.
Empirical Results in Financial Time Series
The utility of the MaxEnt approach is underscored by application to high-frequency EUR/USD exchange rate data. By discretizing returns into a three-state process and reconstructing short-term trajectories, the methodology allows for an accurate estimation of risk-sensitive tail behaviors in the sequence distribution. The average error in estimating the probability mass in the tails—critical for financial risk assessment—is substantially lower for MaxEnt estimators than for frequency sampling, especially with short data segments.
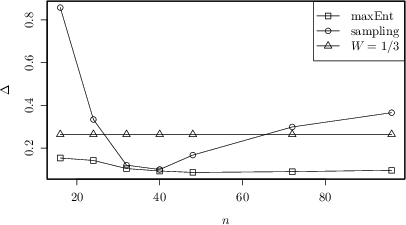
Figure 4: Average error in estimating fat-tail distributions as a function of sample size; MaxEnt (squares), frequency sampling (circles), and equiprobable guess (triangles) compared.
Remarkably, even with lower underlying autocorrelation and potential model misspecification, MaxEnt continues to outperform the naive approaches, corroborating its robustness in practical, noisy environments.
Theoretical and Practical Implications
The results establish that MaxEnt methods can yield materially better estimates of Markovian transition dynamics under data constraints, provided the true process is compatible with the MaxEnt-implied structure (e.g., high entropy, low persistence). For systems exhibiting non-stationarity or when only short data segments are reliable (e.g., due to time-varying parameters), MaxEnt offers a principled and effective inference tool.
On the theoretical side, this work demonstrates that MaxEnt-based procedure can be extended beyond two-state and three-state systems, although current numerical challenges limit tractable analytic solutions to higher dimensions. The observed dependence of MaxEnt’s advantage on entropy rate and sample size invites further investigation into automated selection or adaptation of MaxEnt constraints to better suit complex, real-world stochastic processes.
Practically, the methodology is directly applicable to financial modeling, neuroscience, and any domain where time series exhibit regime shifts or limited stationarity. The approach is amenable to further sophistication by introducing richer constraints (e.g., higher-order moments), potentially enhancing predictive power without extensive increases in sample requirements.
Conclusion
The paper rigorously establishes the conditions under which maximum entropy methods surpass traditional sample-frequency based inference for Markovian time series, specifically highlighting regimes of high-entropy and short sample availability. The approach’s superior tracking of non-stationary dynamics, robust empirical performance on financial data, and framework extensibility position it as a valuable paradigm for structural time series prediction. Future research may address scalability, constraint complexity, and automated model selection for broader applicability in complex, real-world systems.