Learning a Generator Model from Terminal Bus Data
Abstract: In this work we investigate approaches to reconstruct generator models from measurements available at the generator terminal bus using ML techniques. The goal is to develop an emulator which is trained online and is capable of fast predictive computations. The training is illustrated on synthetic data generated based on available open-source dynamical generator model. Two ML techniques were developed and tested: (a) standard vector auto-regressive (VAR) model; and (b) novel customized long short-term memory (LSTM) deep learning model. Trade-offs in reconstruction ability between computationally light but linear AR model and powerful but computationally demanding LSTM model are established and analyzed.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
The following list enumerates what remains missing, uncertain, or unexplored in the paper, phrased to be concrete and actionable for future work.
- Validate the proposed VAR and WD-LSTM models on real PMU/SCADA datasets from diverse generators and grid conditions, including measurement noise, time synchronization errors, and missing data.
- Quantify the end-to-end computational cost (training and inference), memory footprint, and latency of the WD-LSTM and VAR models at typical PMU sampling rates (30–60 Hz), and assess real-time feasibility.
- Resolve the mapping-direction inconsistency: the paper states learning a mapping from (P, Q) to (V, φ), but the LSTM is trained to map (V, φ) to (P, Q). Clarify intended use (emulation vs estimation) and evaluate both directions.
- Establish formal stationarity diagnostics (e.g., ADF/KPSS tests) for input variables and their increments; quantify how differencing affects model bias, variance, and predictive fidelity.
- Provide a principled, rigorously validated method for selecting VAR order under non-Gaussian, nonstationary noise (telegraph and fault processes), and compare to AIC/BIC/HQIC across regimes.
- Analyze identifiability of a generator model from terminal bus measurements in multi-machine systems; determine conditions under which mapping between (P, Q) and (V, φ) is unique or confounded by network interactions.
- Examine sensitivity of the models to sampling rate changes and downsampling (e.g., from solver’s 100 kHz to 10 Hz vs 30–60 Hz), including aliasing and information loss effects.
- Characterize performance under realistic measurement noise models (additive, multiplicative, colored noise), sensor bias/drift, and data outages; test robustness and imputation strategies.
- Quantify how prediction error grows with horizon for both VAR and LSTM; implement and compare stabilization strategies (e.g., closed-loop corrections, Kalman filtering, scheduled re-initialization).
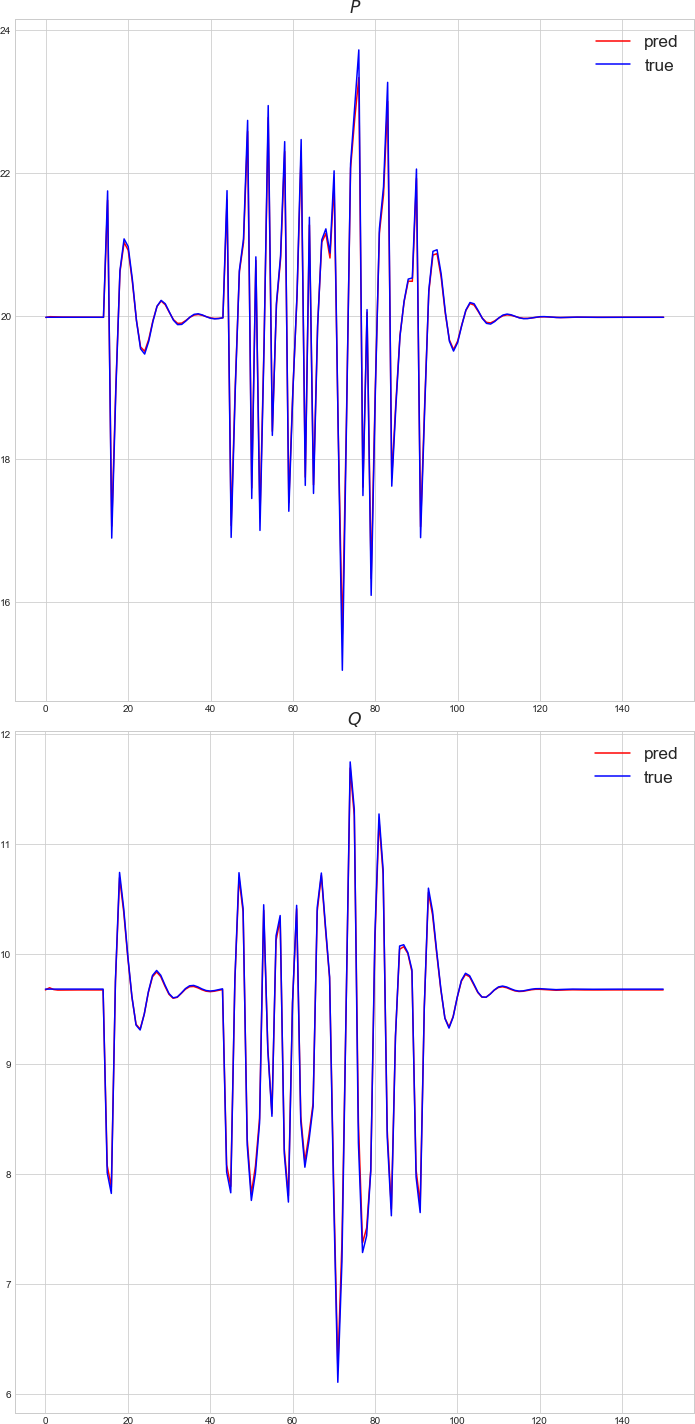
- Investigate why reactive power (Q) estimation degrades more than active power (P), including feature importance, observability limits, and controller interactions (AVR/PSS/governor).
- Report detailed LSTM training protocol (sequence length distributions, dropout rates, weight decay, learning rates, batch size, hidden sizes) and perform ablations to identify which components drive performance.
- Provide a sample complexity analysis: how many time-series samples and what sequence lengths are required to achieve target accuracy across generator types and noise regimes.
- Quantify fine-tuning requirements (data volume, number of epochs, runtime) for domain shifts (randomized generator parameters, high-order noise) and define triggering criteria for online adaptation.
- Demonstrate true online learning: incremental parameter updates, adaptation speed to changing generator/grid states, and mechanisms to avoid catastrophic forgetting.
- Compare against additional baselines beyond VAR (e.g., NARX, state-space models with observers, temporal convolutional networks, transformers, Gaussian processes), and hybrid physics-informed ML.
- Incorporate and evaluate physics constraints (e.g., power balance, voltage/current limits, rate-of-change limits), using constrained learning or regularization to prevent physically implausible outputs.
- Provide uncertainty quantification (prediction intervals, calibrated probabilistic outputs) and reliability metrics, especially for rare events or near-instability conditions.
- Test performance near operational limits (e.g., low inertia, large faults close to protection thresholds, saturation of limiters, OEL/V/Hz) and during protective actions, tripping, or islanding.
- Assess generalization across generator technologies (salient-pole vs round-rotor machines), controllers (AVR, PSS, governors), and parameter variations beyond those in the Kundur 13.2 example.
- Evaluate multi-generator settings and network-wide deployment: scalability, cross-coupling effects, and whether single-generator emulators remain accurate under strong inter-machine interactions.
- Clarify the supervised learning target: one-step vs multi-step prediction; specify loss aggregation across time and outputs, and explore multi-objective losses that weight variables differently (e.g., prioritize φ or V fidelity).
- Analyze the impact of using increments for VAR vs raw signals for LSTM; test alternative preprocessing (de-trending, filtering, normalization schemes) and their effect on performance and stability.
- Provide a rigorous explanation for the counterintuitive increase in optimal VAR order when noise magnitude decreases; determine whether this is overfitting, model misspecification, or a data-generation artifact.
- Evaluate the representativeness of the telegraph-process fault model relative to real-world fault statistics (spatial/temporal correlations, weather-induced patterns); explore more realistic stochastic processes.
- Specify dataset composition (number of time steps per sample, total duration, train/validation/test splits, fault parameter distributions) and release code/data to enable reproducibility.
- Investigate causality and lag structure: confirm that models are strictly causal (no leakage of future information), and reconcile the reported long lag dependence (up to 32 steps) with near-memoryless fault dynamics.
- Explore safety-aware deployment: define guardrails, anomaly detection, and fallback strategies when predictions deviate or the model encounters out-of-distribution conditions.
- Assess how models integrate with control and operations (e.g., AGC, dispatch tools): potential feedback-loop effects, stability implications, and requirements for certification in grid practice.
Collections
Sign up for free to add this paper to one or more collections.