ChoiceMates: Supporting Unfamiliar Online Decision-Making with Multi-Agent Conversational Interactions
Abstract: From deciding on a PhD program to buying a new camera, unfamiliar decisions--decisions without domain knowledge--are frequent and significant. The complexity and uncertainty of such decisions demand unique approaches to information seeking, understanding, and decision-making. Our formative study highlights that users want to start by discovering broad and relevant domain information evenly and simultaneously, quickly address emerging inquiries, and gain personalized standards to assess information found. We present ChoiceMates, an interactive multi-agent system designed to address these needs by enabling users to engage with a dynamic set of LLM agents each presenting a unique experience in the domain. Unlike existing multi-agent systems that automate tasks with agents, the user orchestrates agents to assist their decision-making process. Our user evaluation (n=12) shows that ChoiceMates enables a more confident, satisfactory decision-making with better situation understanding than web search, and higher decision quality and confidence than a commercial multi-agent framework. This work provides insights into designing a more controllable and collaborative multi-agent system.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping people make good choices when they don’t know much about a topic yet—like picking a camera, a robot vacuum, or a new hobby. The authors built a chat-based tool called ChoiceMates. Instead of talking to just one AI, you chat with a small “team” of AI helpers (agents), each with a different viewpoint. These agents explain what they care about (the criteria) and what they would pick (the options), so you can learn quickly and feel confident about your decision.
Goals and Questions
The researchers wanted to solve common problems people face when deciding in unfamiliar areas. In simple terms, they asked:
- How can we show people different viewpoints without making them dig through tons of web pages?
- How can we help people find what matters most for their situation (their criteria)?
- How can we make it easier to collect, sort, and compare important information?
- How can we help people know when they’ve learned enough to choose and feel confident in their choice?
Methods and Approach
First, the team studied how people currently make unfamiliar decisions online:
- They interviewed and observed 14 people making choices about things they didn’t know much about (like buying a car seat or planning a trip). This revealed their main struggles: not enough diverse viewpoints, too much information to sort through, and uncertainty about when to stop researching.
Then, they built ChoiceMates, a chat tool powered by LLMs. Think of LLMs as very smart text AIs (like ChatGPT) that can understand questions and generate helpful answers.
Here’s how ChoiceMates works, using everyday ideas:
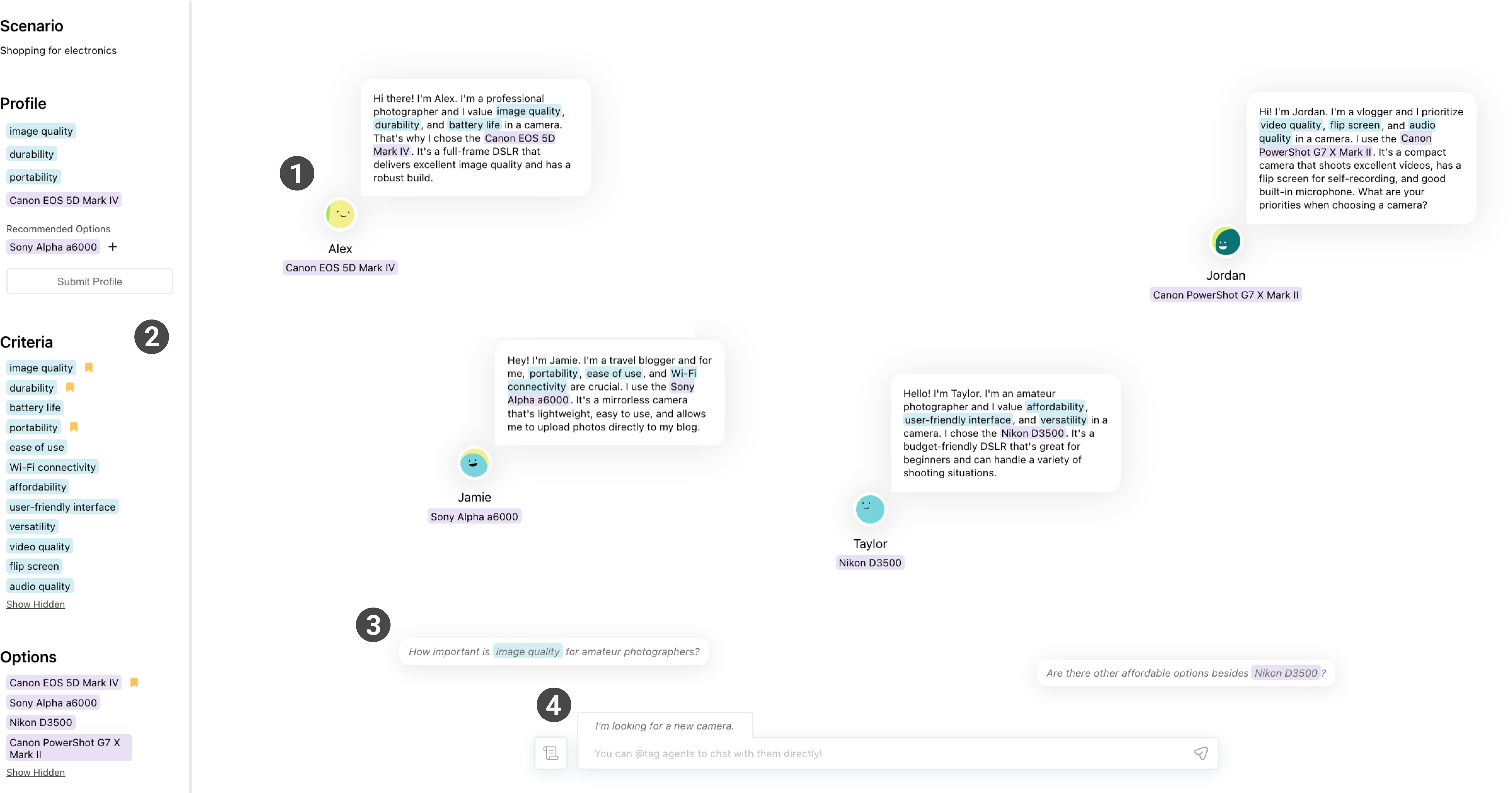
- Multi-agent chat: Instead of one AI, you get a “group chat” of several AI helpers (agents) with different personalities and opinions—like a pro photographer, a traveler, or a hobbyist, if you’re picking a camera.
- Criteria vs. options: “Criteria” are the qualities you care about (like price, portability, battery life). “Options” are the actual things you can choose (like specific camera models).
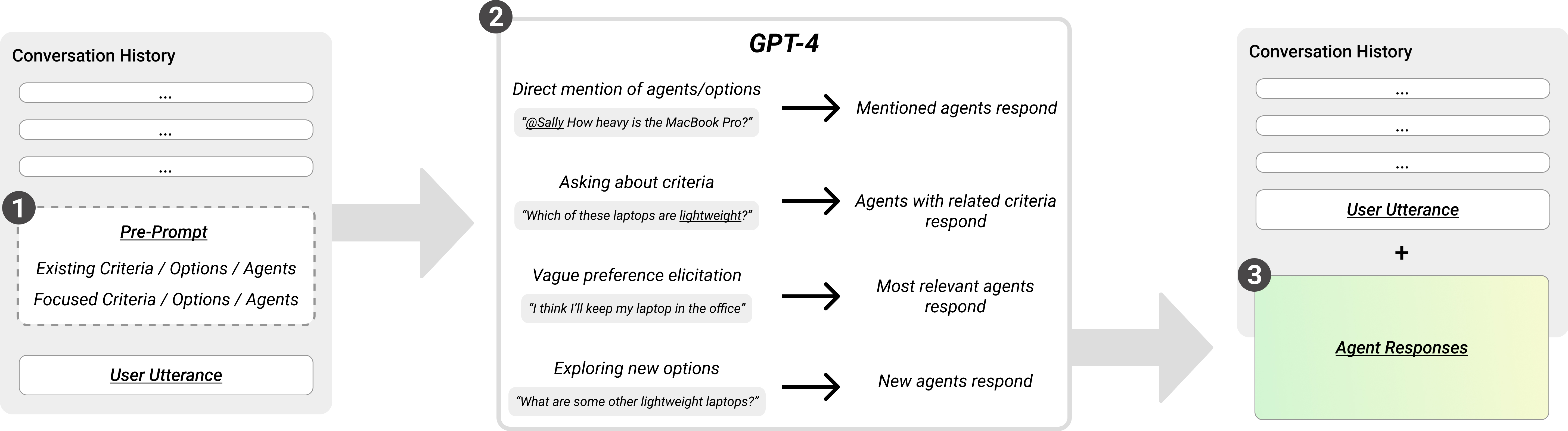
- Summary bar: A simple panel that auto-collects and highlights the criteria and options mentioned. It’s like a tidy list of sticky notes you didn’t have to write yourself.
- Profile card: As you figure out what matters to you, you “pin” criteria and options to build your personal profile. This helps you narrow down to a final choice.
- Focus view and agent management: You can select certain agents and compare their opinions side by side, or filter the conversation to focus only on what’s most relevant to you.
- Thought bubbles: Helpful suggested questions that keep the conversation moving even if you’re not sure what to ask next.
- Fact support: When agents recommend something (like a product), the system can pull in basic info from the web to ground the conversation in real facts.
Finally, they tested ChoiceMates with 36 people and compared it to:
- Regular web search
- A single-chatbot setup (like chatting with one AI)
Main Findings and Why They Matter
The study found that ChoiceMates helped people more than regular web search, and often more than a single AI chat, especially for unfamiliar decisions.
Key results:
- People discovered more diverse perspectives. Multiple agents with different personas gave a fuller picture of the topic.
- People dug deeper into relevant information without feeling overwhelmed. The summary bar and focus tools made it easier to manage lots of details.
- People felt more confident about when to stop researching and make a decision. Pinning criteria and options to a profile helped them see their preferences clearly.
- People had more control over the process. They could choose which agents to talk to, filter by criteria, and compare opinions side by side.
In short, ChoiceMates made learning a new domain feel more like talking to a helpful group of advisors than hunting across the internet alone.
Implications and Impact
This research suggests that future decision tools shouldn’t rely on a single AI voice. Instead, giving users a small “team” of AI helpers with different viewpoints can:
- Reduce information overload
- Speed up learning in unfamiliar areas
- Help people form their own preferences, not just follow a recommendation
- Build confidence in the final choice
Tools like ChoiceMates could be especially useful for students, shoppers, or anyone facing a new topic, from gadgets to travel plans. As AI gets better, we’ll likely see more systems that guide you through decisions with multiple perspectives, clear summaries, and thoughtful prompts—so you can make smart choices even when you’re just getting started.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The paper introduces a promising multi-agent conversational system (ChoiceMates) for unfamiliar online decision-making. The following concrete gaps and open questions remain for future work:
- External validity across domains: How well does ChoiceMates generalize beyond the studied scenarios (e.g., consumer products) to high-stakes or non-product decisions (health, finance, legal, education, civic choices) where requirements, risks, and evidence standards differ substantially?
- Participant diversity and sample size: With small samples (formative n=14, evaluation n=36) and limited demographic diversity, do findings hold across broader populations (age, culture, digital literacy, language proficiency, disability)?
- Longitudinal effectiveness: Does ChoiceMates improve decision quality, preference formation, and regret over longer time horizons (days/weeks), and support multi-session continuity, memory, and re-engagement?
- Objective decision quality vs. confidence: The study reports higher confidence, but is confidence calibrated to actual decision quality? Do users become overconfident? How do accuracy, satisfaction, regret, and post-decision outcomes correlate with system use?
- Measurement rigor and reproducibility: What are the precise evaluation metrics, effect sizes, statistical tests, and task difficulty controls? Are prompts, models, seeds, and datasets released for reproducibility?
- Ablation of design components: Which elements drive the observed benefits—multi-agent debate, summary bar, thought bubbles, agent selection, or grounding? How does each component contribute when isolated?
- Baseline strength and fairness: How were “conventional web search” and “single-agent ChatGPT” configured (prompts, guidance, interfaces)? Are results robust to stronger baselines (e.g., search with advanced filters, tool-augmented single agent, state-of-the-art conversational recommenders)?
- Persona generation validity: How is the diversity, coverage, and non-redundancy of agent personas ensured? What guarantees that generated personas reflect meaningful, representative perspectives (not stereotypes or synthetic noise)?
- Coverage completeness: Can the system estimate when users have encountered a sufficiently comprehensive set of criteria and perspectives for the domain? Can it quantify coverage and diminishing returns to support “knowing when to stop”?
- Hallucination and misinformation control: Despite web scraping, how often do agents hallucinate or misstate facts? How reliable is retrieval grounding? Are sources cited, ranked for credibility, and exposed to users?
- Criteria/option extraction accuracy: How precise is auto-detection of criteria and options (precision/recall, deduplication, synonym merging)? Do extraction errors propagate into the summary bar and profile, misguiding users?
- Evidence provenance and traceability: Can users trace each claim to sources, view contradictions, and evaluate evidence strength? How does the interface surface uncertainty and conflicts across agents?
- Debate quality and dynamics: Do inter-agent debates improve understanding or add noise? What mechanisms manage argumentative quality, redundancy, or collusion among agents?
- Cognitive load and clutter management: Does the multi-agent setup reduce or increase cognitive load, especially as agent count grows? Are UI controls (filtering, focusing) sufficient for scalability without overwhelming users?
- Orchestration transparency and control: How are responding agents selected (system-guided vs. user-selected)? What algorithms determine relevance, and can users inspect and override these choices?
- Personalization and user modeling: Beyond pinning criteria, can the system learn a user model over time, proactively tailor agents/personas, and adapt conversation strategies based on evolving preferences?
- Risk-sensitive domains and safeguards: What guardrails, disclaimers, and escalation mechanisms exist for high-stakes decisions? How are bias, fairness, and harm mitigated when personas advocate particular options?
- Ethical and bias considerations: Do personas encode demographic or cultural stereotypes that could skew recommendations? How is representational fairness of perspectives enforced and audited?
- Accessibility and inclusivity: Is the interface usable for screen readers, keyboard-only users, and color-blind users (given reliance on color coding)? How does it perform for non-native speakers or in multilingual settings?
- Multi-modal information needs: Many domains require images, specs, charts, or videos. How will the system integrate multi-modal retrieval and reasoning into conversations and summaries?
- Performance, latency, and cost: What are the computational costs of multi-agent orchestration and real-time grounding? How do latency and API costs scale with agent count and session length?
- Security and safety: How resilient is the system to prompt injection (from user or retrieved content), data exfiltration, or malicious content in sourced webpages?
- Session continuity and provenance over time: Can users persist sessions, revisit decisions, compare across sessions, and maintain long-term preference profiles with versioned provenance?
- Integration with recommender systems and structured comparison: How can ChoiceMates interoperate with CRS/recsys to rank options, generate comparison tables, and support structured trade-off analysis alongside free-form dialogue?
- Cross-cultural and context-aware adaptation: How does the system adapt criteria importance and option sets to cultural, regional, regulatory, or availability differences?
- User education and meta-cognition: Can the system teach users domain literacy (not just options), scaffold critical evaluation, and support reflection on trade-offs to improve future independent decision-making?
- Failure modes and fallback strategies: When retrieval fails, domain coverage is thin, or agents converge prematurely, what fallback strategies notify the user, seek clarifications, or expand search?
- Impact on group decisions: How does ChoiceMates support multi-user decision-making (e.g., families/teams), negotiation among stakeholders, and reconciliation of differing preferences?
- Regulatory and privacy compliance: How are user data, conversation logs, and browsing traces handled with respect to GDPR/CCPA and institutional review standards in real deployments?
These gaps suggest concrete avenues for controlled experiments, algorithmic development (grounding, orchestration, extraction), UI/UX refinements, ethical audits, and deployment studies needed to robustly validate and generalize ChoiceMates.
Glossary
- autonomous LLM architectures: Architectures where LLMs are arranged to operate with minimal human supervision to plan, coordinate, or execute tasks. "multi-agent autonomous LLM architectures"
- between-subjects study: An experimental design in which different groups of participants are assigned to different conditions. "Our between-subjects study (n=36)"
- case-based preference elicitation: A method of uncovering user preferences by presenting concrete examples or cases for users to choose from or react to. "novices preferred case-based preference elicitation"
- choice-based preference elicitation: A technique that derives user preferences by asking users to make choices among alternatives, often more effective for novices. "choice-based preference elicitation is more effective for novices"
- conversational breakdowns: Failures or misunderstandings in dialogue that disrupt the flow and require repair strategies. "repair conversational breakdowns"
- conversational recommender systems (CRS): Recommender systems that engage in multi-turn natural language dialogue to refine and personalize recommendations. "Conversational recommender systems (CRS) build on top of existing recommender systems"
- conversational user interfaces (CUIs): Interfaces that allow users to interact with systems through natural language conversation, typically via text or speech. "conversational user interfaces (CUIs)"
- direct manipulation: Interaction style where users act on visible objects directly (e.g., clicking, dragging) rather than issuing abstract commands. "direct manipulation of objects as an interaction modality"
- formative study: An early-stage exploratory study aimed at understanding user needs, contexts, or challenges to inform design. "Through our formative study (n=14)"
- graphical user interface (GUI): A visual interface composed of graphical elements (windows, icons, menus) enabling user interaction with a system. "a graphical user interface (GUI)"
- Human-AI Interaction: The study and design of how humans interact with artificial intelligence systems. "Human-AI Interaction"
- information overload: A state where the volume of available information exceeds a user’s capacity to process it effectively, harming decision quality. "information overload"
- LLMs: Large-scale neural models trained on extensive text corpora to understand and generate human-like language. "LLMs"
- microtasks: Small, narrowly scoped tasks that can be distributed or chained to accomplish larger goals. "utilizing agents for microtasks"
- multi-agent conversational system: A system in which multiple agents interact (with users and/or each other) through dialogue to support a task. "a multi-agent conversational system"
- multi-modal inputs: Inputs spanning multiple modes (e.g., text, GUI actions), enabling richer interactions with a system. "multi-modal inputs"
- multi-turn interactions: Dialogues involving multiple back-and-forth exchanges, allowing context to build over time. "multi-turn interactions"
- opinionated personas: Agent or user profiles that embody specific perspectives or preferences to surface diverse viewpoints. "Agents, as opinionated personas, flexibly join the conversation"
- orchestrate (multiple agents): To coordinate and manage the roles, sequencing, and interactions of several agents toward a goal. "automatically orchestrate and coordinate multiple agents"
- preference elicitation: The process of uncovering and structuring a user’s preferences to inform recommendations or decisions. "guidance for preference elicitation"
- prompt engineering: The practice of crafting and refining prompts to steer LLMs toward desired outputs and behaviors. "prompt engineering"
- prompt-tuned: Adapted to a task via tailored prompts or instructions rather than changing model parameters. "a prompt-tuned ChatGPT condition"
- self-prompting: An approach where an LLM generates prompts for itself or other LLMs to autonomously progress on tasks. "self-prompting, an architecture for feeding LLM-generated responses into other LLMs"
- sensemaking: The process of organizing and interpreting information to build understanding, often in complex or unfamiliar domains. "sensemaking of LLM-generated text"
- snowball sampling: A recruitment method where existing participants refer additional participants, expanding the sample iteratively. "snowball sampling"
- think-aloud study: A method in which participants verbalize their thoughts while performing tasks, revealing reasoning and challenges. "think-aloud study"
- uni-directional: Interaction that flows in one direction without reciprocal back-and-forth, limiting adaptability. "uni-directional"
- web scraping: Automated extraction of data from web pages for use in downstream processing or context. "the web scraping function"
Practical Applications
Immediate Applications
Based on the paper’s multi-agent conversational approach (agents with distinct personas, inter-agent debate, auto-extracted criteria/options, Summary Bar, Focus View, Profile Card), the following use cases can be deployed with today’s LLMs and available data integrations.
- Industry (E-commerce/Marketplaces): “Shop with Perspectives” assistant for novice buyers
- What it does: On product pages (e.g., cameras, robot vacuums, baby car seats), spawn agents representing archetypal buyers (e.g., “budget student,” “power user,” “parent”) who explain their choices; auto-extract criteria (e.g., battery life, ease of use) and options; let users pin preferences and compare top 3 options in a Focus View; agents can “debate.”
- Tools/products/workflows: Marketplace plugin/extension; browser add-on that summarizes reviews and specs into agent personas; “Profile Card” exported to shopping cart or wishlist.
- Assumptions/dependencies: Reliable product metadata and review scraping; guardrails to reduce hallucinations; compliance with site ToS; cost/latency of multi-agent LLM calls; clear disclaimers for safety-critical products.
- Industry (Travel & Hospitality): Multi-perspective trip planner
- What it does: Agents embody traveler types (budget traveler, foodie, accessibility-focused) and propose/differentiate itineraries; Summary Bar captures criteria like budget, transit time, accessibility; Focus View compares two or three itineraries.
- Tools/products/workflows: Integration into OTAs/metasearch; live data via booking/routing APIs; itinerary export to calendars.
- Assumptions/dependencies: Up-to-date availability; geospatial APIs; content accuracy; handling personalization and privacy.
- Industry (Enterprise Procurement/IT & Software): Role-aware procurement assistant
- What it does: Agents represent stakeholder roles (security, finance, developer, legal) debating SaaS/cloud/library choices; Summary Bar tracks compliance needs, TCO, integration; Profile Card records chosen criteria and shortlisted vendors.
- Tools/products/workflows: Confluence/Jira plugin; RAG over vendor docs, SOC2s, pricing; exportable “decision record.”
- Assumptions/dependencies: Access to internal policy docs; robust retrieval; source attribution; info security/governance.
- Academia (Learning/Advising): Course/major selection copilot
- What it does: Agents with different goals (research-focused, industry-ready, work–life balance) compare courses/programs; Summary Bar captures workload, outcomes, skills; Focus View for side-by-side course comparison.
- Tools/products/workflows: LMS/advising portal integration; links to course catalogs and evaluations; export to degree plan.
- Assumptions/dependencies: Accurate, current course data; privacy for student inputs; human advisor oversight.
- Academia (Research): Literature exploration with multi-perspective synthesis
- What it does: Agents embody theoretical/methodological schools; extract and cluster criteria (methods, sample sizes, metrics); Profile Card captures researcher’s focus; Focus View contrasts seminal papers.
- Tools/products/workflows: Plugins for Zotero/Overleaf; RAG on open corpora (e.g., Semantic Scholar); exportable reading lists.
- Assumptions/dependencies: High-quality retrieval; citation provenance; limits on hallucinated interpretations.
- Finance (Consumer): Product chooser for credit cards, bank accounts, insurance
- What it does: Agents reflect personas (fee minimizer, reward maximizer, travel hacker) and debate offers; Summary Bar auto-extracts APR, fees, perks; Profile Card stores preferences and shortlisted cards.
- Tools/products/workflows: Banking/fintech site widget; comparison site add-on.
- Assumptions/dependencies: Real-time product terms; compliance and disclaimers; fair-balance presentation; suitability checks.
- HR/Careers (Job Seekers & Employers): Career and employer fit exploration
- What it does: Agents representing different workplace values (growth, stability, mission) discuss roles/companies; criteria include benefits, culture, growth paths.
- Tools/products/workflows: Job boards and career services integration; candidate-facing planning tool.
- Assumptions/dependencies: Bias/fairness controls; current & accurate employer information; privacy.
- Customer Support/Knowledge Navigation: Multi-agent troubleshooting coach
- What it does: Agents present alternative troubleshooting paths; Summary Bar surfaces key constraints; Profile Card records steps tried and recommended next steps.
- Tools/products/workflows: Help center widgets; internal support assistant for agents; knowledge base RAG.
- Assumptions/dependencies: Access to up-to-date help docs; escalation handoff; error containment.
- Daily Life (General Consumer Choices): Personal buying/selection assistant
- What it does: Apply the paper’s workflow to common purchases (strollers, home lighting, skateboards, hobby gear); extract criteria, maintain a running shortlist, compare final contenders.
- Tools/products/workflows: Mobile app or browser extension; shareable Profile Cards for friend/family feedback.
- Assumptions/dependencies: Local availability and regional specs; safety disclaimers for regulated items (e.g., car seats).
- Product Review Aggregation: Review-to-persona lens
- What it does: Cluster reviews into archetypes; spawn agents per cluster that summarize pros/cons; Summary Bar aggregates emergent criteria.
- Tools/products/workflows: Browser extension for Amazon/YouTube; site-native feature for retailers.
- Assumptions/dependencies: Review scraping permission; cluster quality; detection of spam/fraud.
- UX/Research Ops (Internal): Sensemaking across user feedback
- What it does: Agents represent customer segments debating feature trade-offs; Summary Bar captures themes; Focus View compares competing feature requests.
- Tools/products/workflows: Integration with research repositories (Dovetail, Notion); exportable decision memos.
- Assumptions/dependencies: Data governance; anonymization; provenance and auditability.
Long-Term Applications
These opportunities extend the paper’s approach but require additional research, domain-grade data, scaling, or regulatory frameworks.
- Healthcare (Patient Decision Aids): Multi-perspective clinical guidance
- What it could do: Agents represent clinician, patient advocate, insurer, and guideline perspectives; summarize risks/benefits/costs; enable preference-sensitive decisions with a validated Profile Card.
- Tools/products/workflows: EHR portal integration; linkage to clinical guidelines, evidence databases; clinician-in-the-loop.
- Assumptions/dependencies: Regulatory approval (e.g., as a medical device class); rigorous evidence integration; human oversight; bias/safety validations via RCTs; liability frameworks.
- Public Policy & Civic Engagement: Deliberation at scale
- What it could do: Agents embody stakeholder views in urban planning, zoning, climate policies; surface criteria (equity, cost, feasibility) and alternatives; produce auditable “decision records.”
- Tools/products/workflows: Municipality engagement platforms; live moderation; transparent source lists.
- Assumptions/dependencies: Trust and legitimacy; bias mitigation; open data integration; procedural fairness.
- Integrated Conversational Recommenders: Orchestrated multi-agent CRS
- What it could do: Combine perspective coverage metrics with recommender back-ends so agents curate and critique recommendations; seamlessly transition from exploration to ranked lists.
- Tools/products/workflows: Marketplace-native CRS; evaluation frameworks for diversity and calibration; cost-optimized agent orchestration.
- Assumptions/dependencies: New metrics for perspective diversity; feedback loops between agents and recommenders; compute costs.
- Persistent, Cross-Application Preference Memory: Portable “decision profile”
- What it could do: Maintain user criteria/preferences across domains (e.g., “values durability and simplicity”); reduce rediscovery overhead; privacy-preserving sync.
- Tools/products/workflows: Personal data stores; consent management; interoperability standards.
- Assumptions/dependencies: Data portability regulations; consented profiling; robust privacy and security.
- Standardized Decision Provenance Artifacts: Auditable “Profile Cards”
- What it could do: Formalize the paper’s Profile Card as a machine-readable decision artifact for compliance (finance, procurement, safety) and AI governance.
- Tools/products/workflows: Integration with GRC tools; APIs for storing/retrieving decision records; attestations and sign-off workflows.
- Assumptions/dependencies: Industry standards; organizational adoption; verifiable sources.
- Education (Critical Thinking & Debate Pedagogy): Curriculum built around agent debates
- What it could do: Teach bias, trade-offs, and perspective-taking via agent debate; students curate criteria and defend choices; graded via structured Profile Cards.
- Tools/products/workflows: LMS modules; classroom dashboards; rubrics aligning to learning objectives.
- Assumptions/dependencies: Pedagogical validation; accessibility; educator training.
- Finance (Advisory/Wealth Management): Multi-agent portfolio planning
- What it could do: Agents model risk profiles and strategies (passive, factor, thematic) debating allocations; constraints captured in Summary Bar; produce a compliance-ready investment policy statement.
- Tools/products/workflows: Advisor workstation integration; data feeds; human advisor oversight.
- Assumptions/dependencies: Licensing/fiduciary duty; suitability and KYC; market data reliability; robust guardrails.
- Energy & Home Upgrades: Complex retrofit choices (solar, heat pumps, storage)
- What it could do: Agents represent installer, building scientist, utility, and homeowner; evaluate trade-offs (capex, efficiency, incentives); output staged plan.
- Tools/products/workflows: Utility/contractor platforms; local code databases; incentive calculators.
- Assumptions/dependencies: High-quality local data; updated incentives; safety and permitting compliance.
- Engineering/Robotics/Design Reviews: Multi-role design deliberation
- What it could do: Agents for safety, cost, performance, manufacturability, sustainability; debate design options; export design rationale.
- Tools/products/workflows: CAD/PLM integration; standards libraries; change-control logs.
- Assumptions/dependencies: Domain ontologies; validated technical reasoning; IP protection.
- Scientific Synthesis & Field Mapping: Automated perspective maps
- What it could do: Agents representing methods/theories co-synthesize large literatures; auto-extract criteria (measures, populations); produce living maps with debates.
- Tools/products/workflows: Research graph integrations; open-science APIs; reproducibility links.
- Assumptions/dependencies: High-recall retrieval; credible summarization; community acceptance.
- Cross-cultural/Fairness-Aware Decision Support: Perspective calibration
- What it could do: Agents calibrated for cultural norms and fairness constraints to prevent one-sided advice; transparency about value trade-offs.
- Tools/products/workflows: Datasets and evaluations for cross-cultural competence; fairness dashboards.
- Assumptions/dependencies: Representative training data; continuous bias auditing; stakeholder governance.
- Regulatory & Industry Standards: Transparency for multi-agent systems
- What it could do: Define disclosure norms (persona identities, sources, conflicts of interest), auditing requirements, and user control (e.g., selecting/weighting agents).
- Tools/products/workflows: Compliance checklists; standardized UI patterns for source provenance.
- Assumptions/dependencies: Regulator engagement; industry consortia; enforcement mechanisms.
Collections
Sign up for free to add this paper to one or more collections.