- The paper introduces an adaptive latent diffusion model using a novel MS-SPADE block to transform 3D MRI images between modalities.
- It employs a two-stage training process combining autoencoder compression with denoising diffusion for enhanced image synthesis.
- Experimental validation on BraTS2021 and IXI datasets shows superior PSNR, NMSE, and SSIM metrics compared to GAN-based methods.
Adaptive Latent Diffusion Model for 3D Medical Image Translation
Introduction
The study presents an innovative approach to 3D medical image-to-image translation leveraging latent diffusion models (LDM) to circumvent the challenges associated with the acquisition of multi-modal images in clinical practice. Clinicians often struggle with obtaining multiple imaging modalities due to constraints such as cost, time, and safety, which can impact diagnostic accuracy. The proposed model addresses these concerns by facilitating the generation of missing modalities, thereby enhancing diagnosis and treatment efficacy.
The cornerstone of this approach is the integration of a latent diffusion framework combined with a novel multi-switchable spatially adaptive normalization (MS-SPADE) block. This architecture enables dynamic transformation of source latents to desired target modalities, allowing for image synthesis in 3D without the necessity for patch cropping—a common drawback in previous methods.
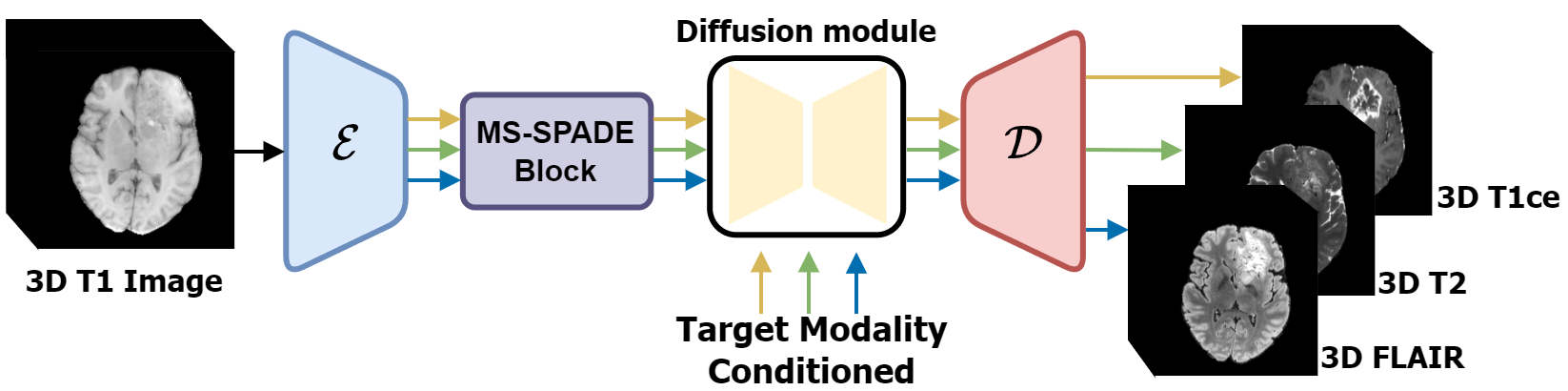
Figure 1: Overview of the proposed image-to-image translation process based on latent diffusion model.
Methodology
Latent Diffusion Model Framework
The latent diffusion model transforms the latent representation of source images into target modalities through conditioning mechanisms, overcoming traditional challenges of out-of-slice information loss in 2D methods. The MS-SPADE block, a pivotal innovation in this study, facilitates the translation tasks from one source modality to various targets within a singular unified model.
Moreover, the proposed LDM employs a two-stage training process. Initially, an autoencoder compresses the image into a latent representation followed by style transformation through the MS-SPADE block. The second stage harnesses the diffusion model to refine these target-like latents, bridging any disparities between predicted and actual target latents.
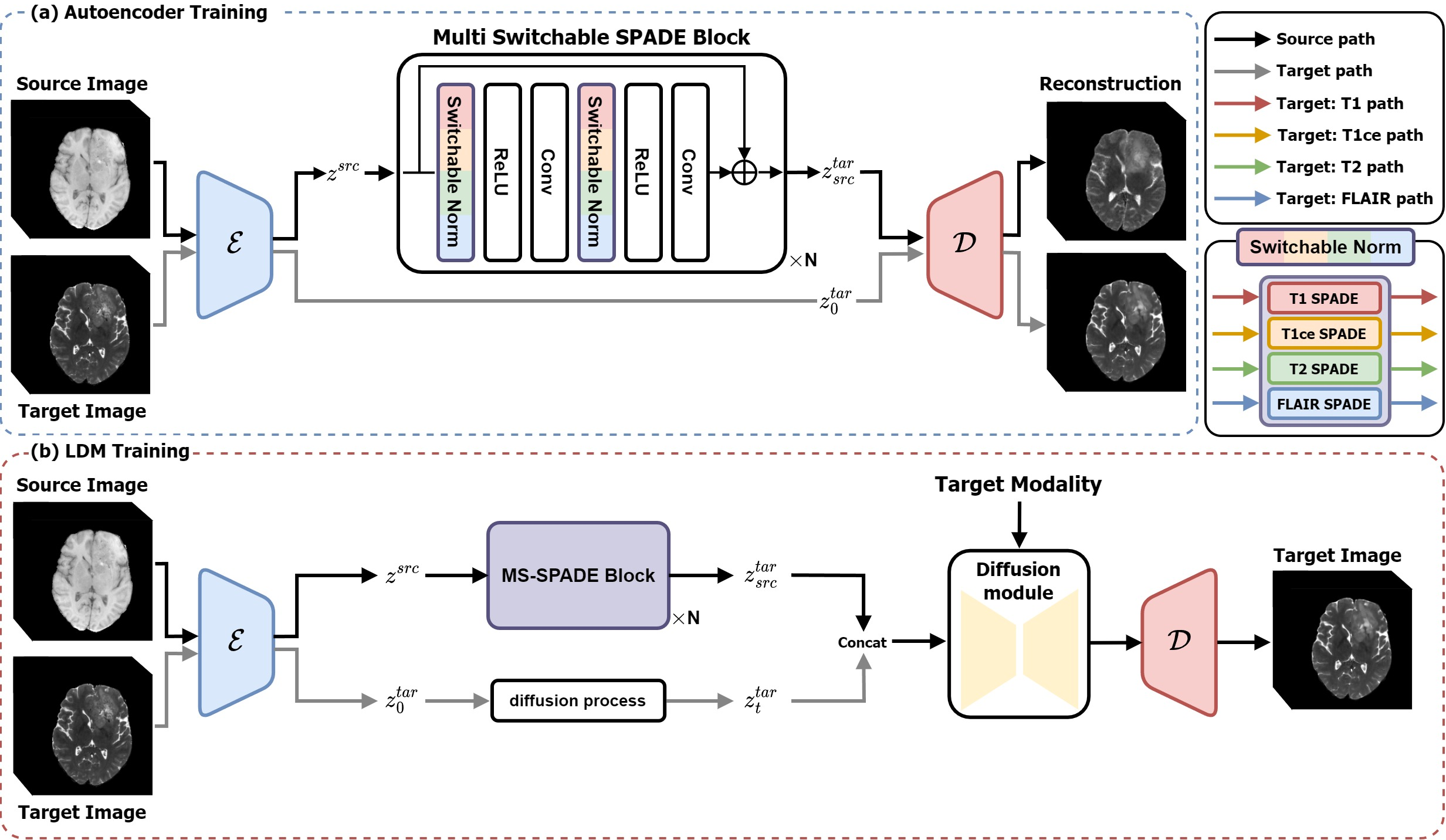
Figure 2: The source and target images are 3D volume images and our method is applied in a 3D manner.
Image Compression and Diffusion
The compression model, inspired by VQGAN, enforces perceptual regularization and vector quantization, enabling style transfer via conditional normalization layers. Complementary to this, the diffusion model processes these latents within a denoising framework optimized by a loss function targeting both the compressed latent and modality conversion.
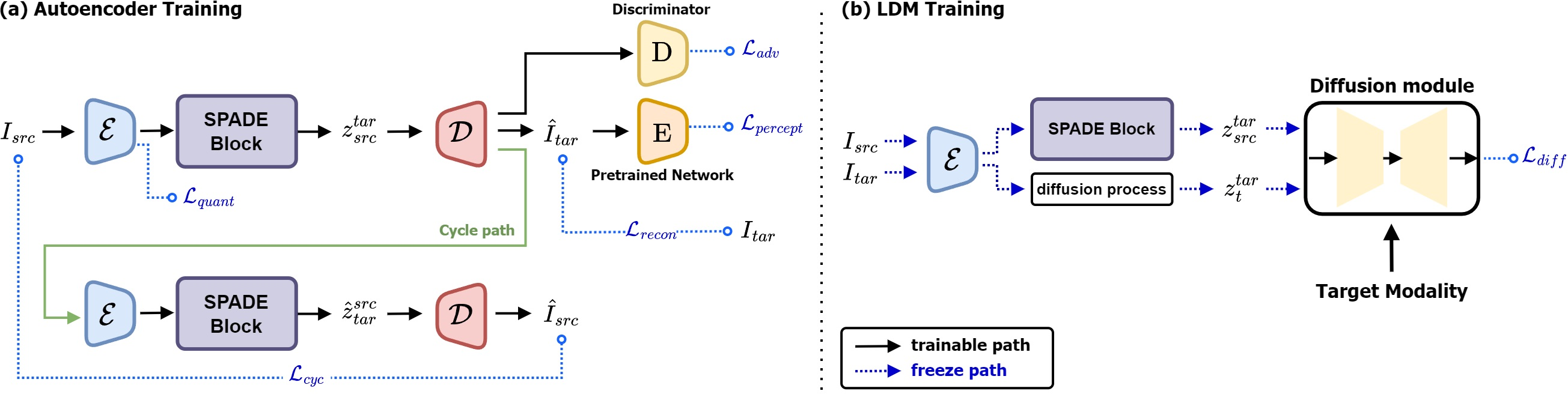
Figure 3: Illustrates the training process of the autoencoder during image compression phase to compute source latents.
Modality Conditioning
The model incorporated modality conditioning using cross-attention mechanisms which empower the UNet architecture to facilitate precise translation across multiple modalities. This integration ensures the synthesized images maintain the characteristics required for clinical interpretations and diagnostics.
Experiments
Dataset and Implementation
The model's efficacy was evaluated with two datasets: BraTS2021 and IXI, enabling extensive validation across multiple MRI modalities. The experiments used PSNR, NMSE, and SSIM metrics for quantitative analysis, affirming the new model’s superiority over existing GAN-based approaches.
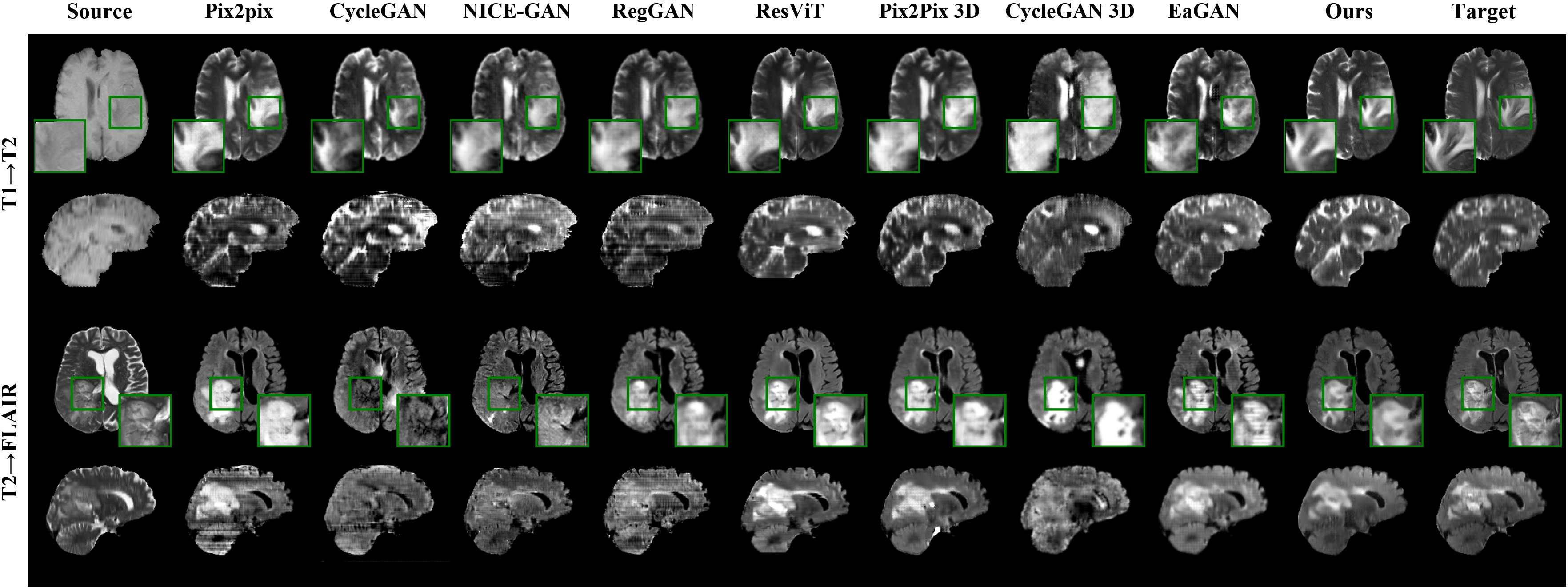
Figure 4: Results of the proposed model and comparison models on the BraTS2021 dataset for image-to-image translation tasks.
Results and Discussion
Presented results demonstrate the robust performance of the model in one-to-many modality translations. Notably, across tested scenarios, the model achieved superior qualitative and quantitative metrics compared to existing methods, showcasing high fidelity in tumor visualization and anatomical structures. Furthermore, ablation studies highlighted the incremental value provided by each novel component in the model.
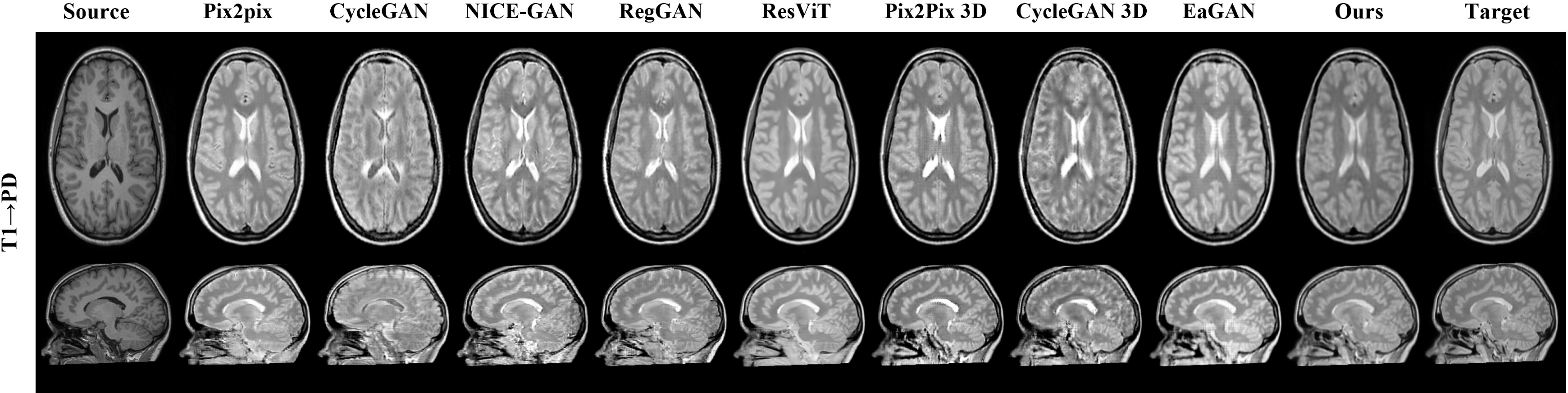
Figure 5: Results on the IXI dataset demonstrating effective image translation across modalities.
Conclusion
The adaptive latent diffusion model successfully advances the frontier of multi-modal medical image translation, overcoming previous limitations in model generalization and efficiency. Its application in clinical settings promises improved diagnostic data completeness and accuracy. Future directions involve expanding this approach to accommodate multi-source to single-target translations and broader applications across various medical imaging modalities.
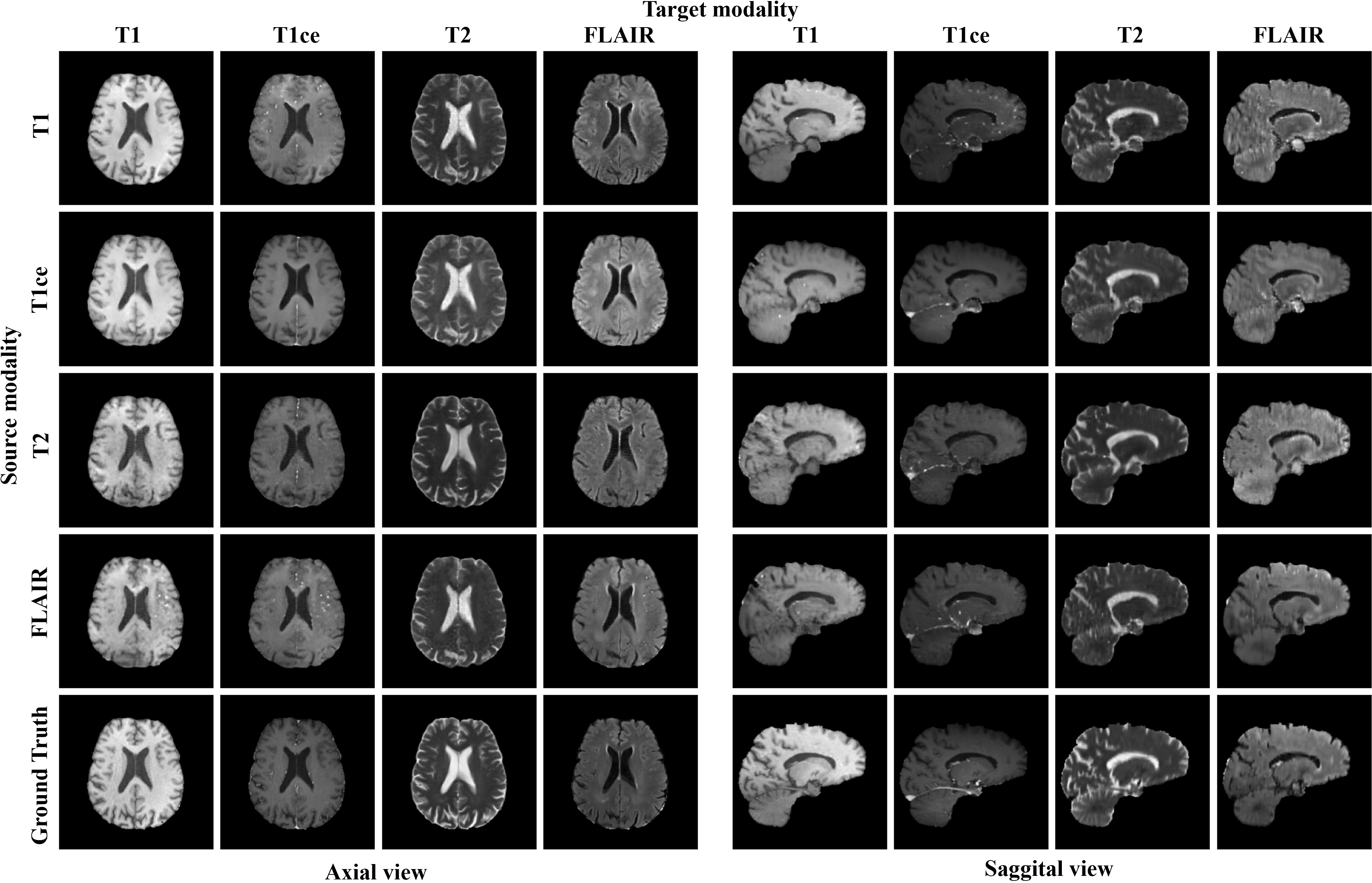
Figure 6: Image translation results from each source modality to the corresponding target modality using the proposed model for all possible combinations.