Learn to Refuse: Making Large Language Models More Controllable and Reliable through Knowledge Scope Limitation and Refusal Mechanism
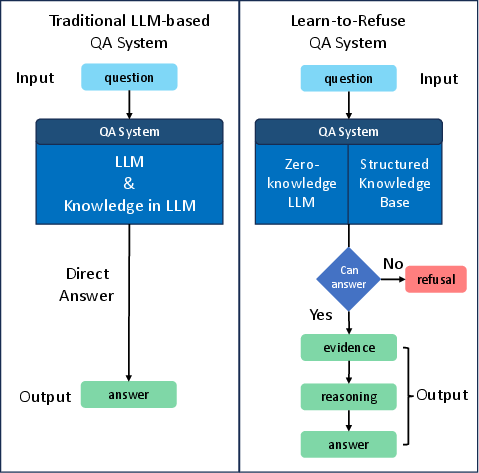
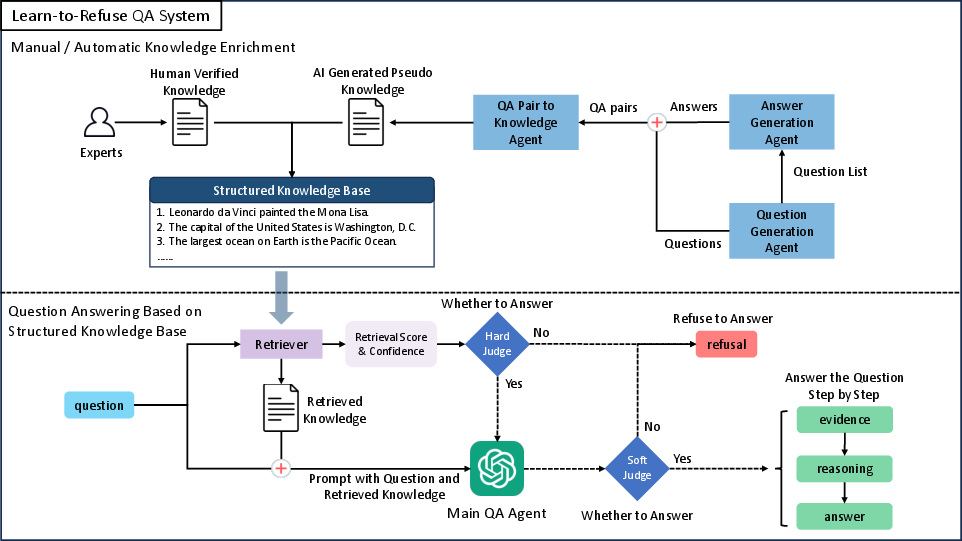
Abstract: LLMs have demonstrated impressive language understanding and generation capabilities, enabling them to answer a wide range of questions across various domains. However, these models are not flawless and often produce responses that contain errors or misinformation. These inaccuracies, commonly referred to as hallucinations, render LLMs unreliable and even unusable in many scenarios. In this paper, our focus is on mitigating the issue of hallucination in LLMs, particularly in the context of question-answering. Instead of attempting to answer all questions, we explore a refusal mechanism that instructs LLMs to refuse to answer challenging questions in order to avoid errors. We then propose a simple yet effective solution called Learn to Refuse (L2R), which incorporates the refusal mechanism to enable LLMs to recognize and refuse to answer questions that they find difficult to address. To achieve this, we utilize a structured knowledge base to represent all the LLM's understanding of the world, enabling it to provide traceable gold knowledge. This knowledge base is separate from the LLM and initially empty. It can be filled with validated knowledge and progressively expanded. When an LLM encounters questions outside its domain, the system recognizes its knowledge scope and determines whether it can answer the question independently. Additionally, we introduce a method for automatically and efficiently expanding the knowledge base of LLMs. Through qualitative and quantitative analysis, we demonstrate that our approach enhances the controllability and reliability of LLMs.
- Improving language models by retrieving from trillions of tokens.
- Instruction mining: High-quality instruction data selection for large language models.
- Chain-of-verification reduces hallucination in large language models.
- Wikimedia Foundation. Wikimedia downloads.
- Realm: Retrieval-augmented language model pre-training.
- Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38.
- What disease does this patient have? a large-scale open domain question answering dataset from medical exams.
- Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3):535–547.
- Language models (mostly) know what they know.
- Challenges and applications of large language models.
- Generalization through memorization: Nearest neighbor language models. In International Conference on Learning Representations.
- Philipp Koehn and Rebecca Knowles. 2017. Six challenges for neural machine translation. In Proceedings of the First Workshop on Neural Machine Translation, pages 28–39, Vancouver. Association for Computational Linguistics.
- Internet-augmented language models through few-shot prompting for open-domain question answering.
- Factuality enhanced language models for open-ended text generation.
- Retrieval-augmented generation for knowledge-intensive nlp tasks. In Advances in Neural Information Processing Systems, volume 33, pages 9459–9474. Curran Associates, Inc.
- Retrieval-augmented generation for knowledge-intensive nlp tasks.
- A survey on retrieval-augmented text generation.
- Inference-time intervention: Eliciting truthful answers from a language model.
- Let’s verify step by step.
- Truthfulqa: Measuring how models mimic human falsehoods.
- TruthfulQA: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214–3252, Dublin, Ireland. Association for Computational Linguistics.
- Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models.
- On faithfulness and factuality in abstractive summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1906–1919, Online. Association for Computational Linguistics.
- OpenAI. 2023. Gpt-4 technical report.
- The refinedweb dataset for falcon llm: Outperforming curated corpora with web data, and web data only.
- Check your facts and try again: Improving large language models with external knowledge and automated feedback.
- The curious case of hallucinations in neural machine translation. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1172–1183, Online. Association for Computational Linguistics.
- Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics.
- Language models that seek for knowledge: Modular search & generation for dialogue and prompt completion. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 373–393, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Aligning large multimodal models with factually augmented rlhf.
- CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, Minneapolis, Minnesota. Association for Computational Linguistics.
- Llama 2: Open foundation and fine-tuned chat models.
- Med-halt: Medical domain hallucination test for large language models.
- Chain-of-thought prompting elicits reasoning in large language models.
- Fine-grained human feedback gives better rewards for language model training.
- Benchmarking retrieval-augmented generation for medicine.
- Do large language models know what they don’t know? In Findings of the Association for Computational Linguistics: ACL 2023, pages 8653–8665, Toronto, Canada. Association for Computational Linguistics.
- Siren’s song in the ai ocean: A survey on hallucination in large language models.
- A survey of large language models.
- Lima: Less is more for alignment.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

