Ferret-UI 2: Mastering Universal User Interface Understanding Across Platforms
Abstract: Building a generalist model for user interface (UI) understanding is challenging due to various foundational issues, such as platform diversity, resolution variation, and data limitation. In this paper, we introduce Ferret-UI 2, a multimodal LLM (MLLM) designed for universal UI understanding across a wide range of platforms, including iPhone, Android, iPad, Webpage, and AppleTV. Building on the foundation of Ferret-UI, Ferret-UI 2 introduces three key innovations: support for multiple platform types, high-resolution perception through adaptive scaling, and advanced task training data generation powered by GPT-4o with set-of-mark visual prompting. These advancements enable Ferret-UI 2 to perform complex, user-centered interactions, making it highly versatile and adaptable for the expanding diversity of platform ecosystems. Extensive empirical experiments on referring, grounding, user-centric advanced tasks (comprising 9 subtasks $\times$ 5 platforms), GUIDE next-action prediction dataset, and GUI-World multi-platform benchmark demonstrate that Ferret-UI 2 significantly outperforms Ferret-UI, and also shows strong cross-platform transfer capabilities.
- Agent-e: From autonomous web navigation to foundational design principles in agentic systems. arXiv preprint arXiv:2407.13032, 2024.
- Minigpt4-video: Advancing multimodal llms for video understanding with interleaved visual-textual tokens. arXiv preprint arXiv:2404.03413, 2024.
- Digirl: Training in-the-wild device-control agents with autonomous reinforcement learning. arXiv preprint arXiv:2406.11896, 2024.
- Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966, 2023.
- Windows agent arena: Evaluating multi-modal os agents at scale. arXiv preprint arXiv:2409.08264, 2024.
- Amex: Android multi-annotation expo dataset for mobile gui agents. arXiv preprint arXiv:2407.17490, 2024.
- Guide: Graphical user interface data for execution. arXiv preprint arXiv:2404.16048, 2024.
- Gui-world: A dataset for gui-oriented multimodal llm-based agents. arXiv preprint arXiv:2406.10819, 2024a.
- Websrc: A dataset for web-based structural reading comprehension. arXiv preprint arXiv:2101.09465, 2021.
- Mindsearch: Mimicking human minds elicits deep ai searcher. arXiv preprint arXiv:2407.20183, 2024b.
- Seeclick: Harnessing gui grounding for advanced visual gui agents. arXiv preprint arXiv:2401.10935, 2024.
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/.
- Rico: A mobile app dataset for building data-driven design applications. In Proceedings of the 30th annual ACM symposium on user interface software and technology, pp. 845–854, 2017.
- Mind2web: Towards a generalist agent for the web. NeurIPS, 2024.
- The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- Assistgui: Task-oriented desktop graphical user interface automation. arXiv preprint arXiv:2312.13108, 2023.
- A real-world webagent with planning, long context understanding, and program synthesis. arXiv preprint arXiv:2307.12856, 2023.
- Webvoyager: Building an end-to-end web agent with large multimodal models. arXiv preprint arXiv:2401.13919, 2024.
- Cogagent: A visual language model for gui agents. arXiv preprint arXiv:2312.08914, 2023.
- Chat-univi: Unified visual representation empowers large language models with image and video understanding. In CVPR, 2024.
- Omniact: A dataset and benchmark for enabling multimodal generalist autonomous agents for desktop and web. arXiv preprint arXiv:2402.17553, 2024.
- Autowebglm: Bootstrap and reinforce a large language model-based web navigating agent. arXiv preprint arXiv:2404.03648, 2024.
- Spotlight: Mobile ui understanding using vision-language models with a focus, 2023.
- Mvbench: A comprehensive multi-modal video understanding benchmark. In CVPR, 2024a.
- On the effects of data scale on computer control agents. arXiv preprint arXiv:2406.03679, 2024b.
- Appagent v2: Advanced agent for flexible mobile interactions. arXiv preprint arXiv:2408.11824, 2024c.
- Llava-next: Improved reasoning, ocr, and world knowledge, January 2024a. URL https://llava-vl.github.io/blog/2024-01-30-llava-next/.
- Visualwebbench: How far have multimodal llms evolved in web page understanding and grounding? arXiv preprint arXiv:2404.05955, 2024b.
- Visualagentbench: Towards large multimodal models as visual foundation agents. arXiv preprint arXiv:2408.06327, 2024c.
- Gui odyssey: A comprehensive dataset for cross-app gui navigation on mobile devices. arXiv preprint arXiv:2406.08451, 2024.
- Laser: Llm agent with state-space exploration for web navigation. arXiv preprint arXiv:2309.08172, 2023.
- Mm1: Methods, analysis & insights from multimodal llm pre-training. arXiv preprint arXiv:2403.09611, 2024.
- Mobileflow: A multimodal llm for mobile gui agent. arXiv preprint arXiv:2407.04346, 2024.
- Webcanvas: Benchmarking web agents in online environments. arXiv preprint arXiv:2406.12373, 2024.
- Androidworld: A dynamic benchmarking environment for autonomous agents. arXiv preprint arXiv:2405.14573, 2024a.
- Androidinthewild: A large-scale dataset for android device control. NeurIPS, 2024b.
- Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
- Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118, 2024.
- Androidenv: A reinforcement learning platform for android. arXiv preprint arXiv:2105.13231, 2021.
- Mobile-agent-v2: Mobile device operation assistant with effective navigation via multi-agent collaboration. arXiv preprint arXiv:2406.01014, 2024a.
- Mobile-agent: Autonomous multi-modal mobile device agent with visual perception, 2024b.
- Mobileagentbench: An efficient and user-friendly benchmark for mobile llm agents. arXiv preprint arXiv:2406.08184, 2024c.
- Autodroid: Llm-powered task automation in android. In Proceedings of the 30th Annual International Conference on Mobile Computing and Networking, pp. 543–557, 2024.
- Webui: A dataset for enhancing visual ui understanding with web semantics. ACM Conference on Human Factors in Computing Systems (CHI), 2023.
- Os-copilot: Towards generalist computer agents with self-improvement. arXiv preprint arXiv:2402.07456, 2024.
- Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. arXiv preprint arXiv:2404.07972, 2024.
- Crab: Cross-environment agent benchmark for multimodal language model agents. arXiv preprint arXiv:2407.01511, 2024.
- Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v. arXiv preprint arXiv:2310.11441, 2023.
- Webshop: Towards scalable real-world web interaction with grounded language agents. NeurIPS, 2022.
- Ferret: Refer and ground anything anywhere at any granularity, 2023.
- Ferret-ui: Grounded mobile ui understanding with multimodal llms. arXiv preprint arXiv:2404.05719, 2024.
- Ufo: A ui-focused agent for windows os interaction. arXiv preprint arXiv:2402.07939, 2024a.
- Mobile-env: an evaluation platform and benchmark for llm-gui interaction. arXiv preprint arXiv:2305.08144, 2023.
- Mm1. 5: Methods, analysis & insights from multimodal llm fine-tuning. arXiv preprint arXiv:2409.20566, 2024b.
- Ferret-v2: An improved baseline for referring and grounding with large language models. arXiv preprint arXiv:2404.07973, 2024c.
- Gpt-4v (ision) is a generalist web agent, if grounded. arXiv preprint arXiv:2401.01614, 2024a.
- Synapse: Trajectory-as-exemplar prompting with memory for computer control. In ICLR, 2023.
- Agentstudio: A toolkit for building general virtual agents. arXiv preprint arXiv:2403.17918, 2024b.
- Webarena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854, 2023.
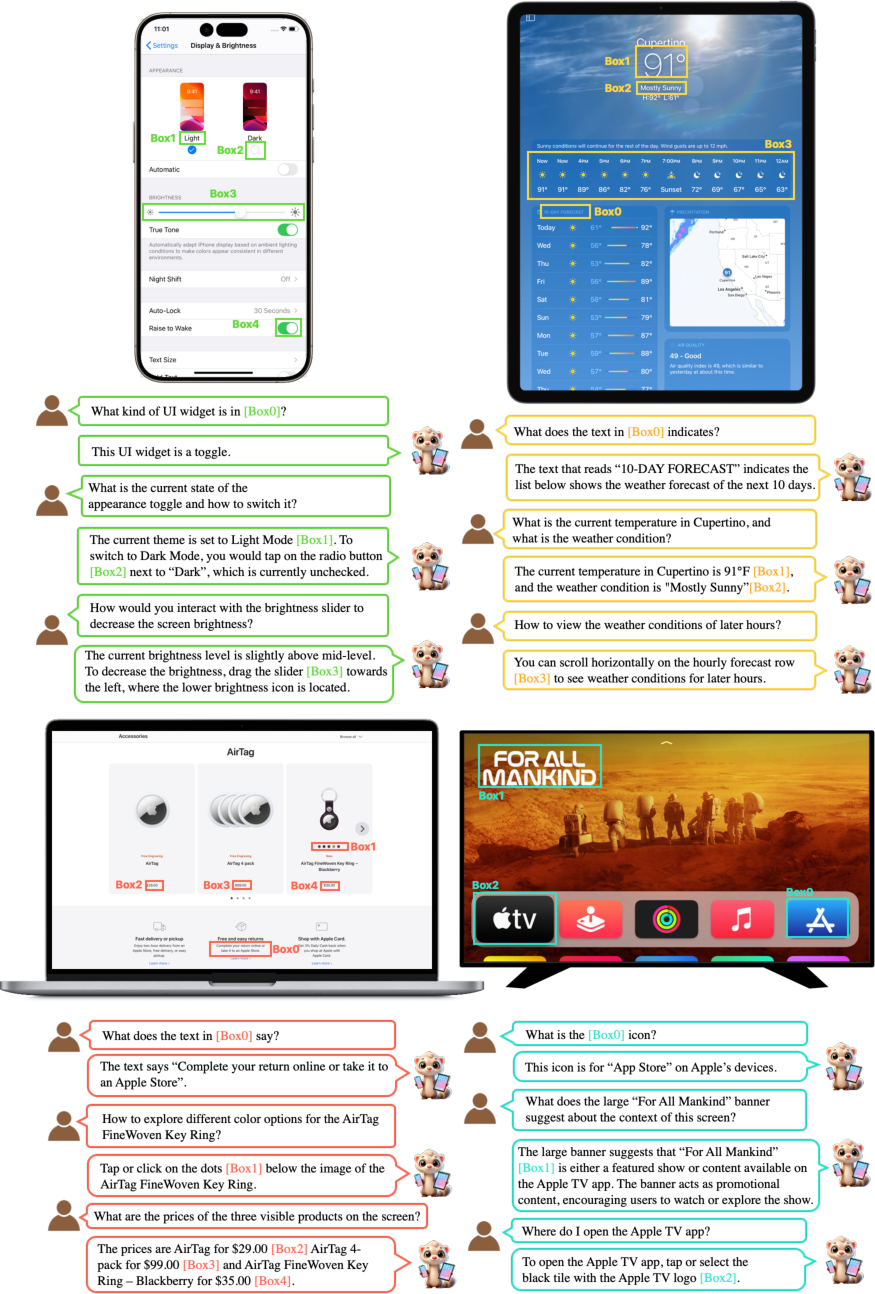
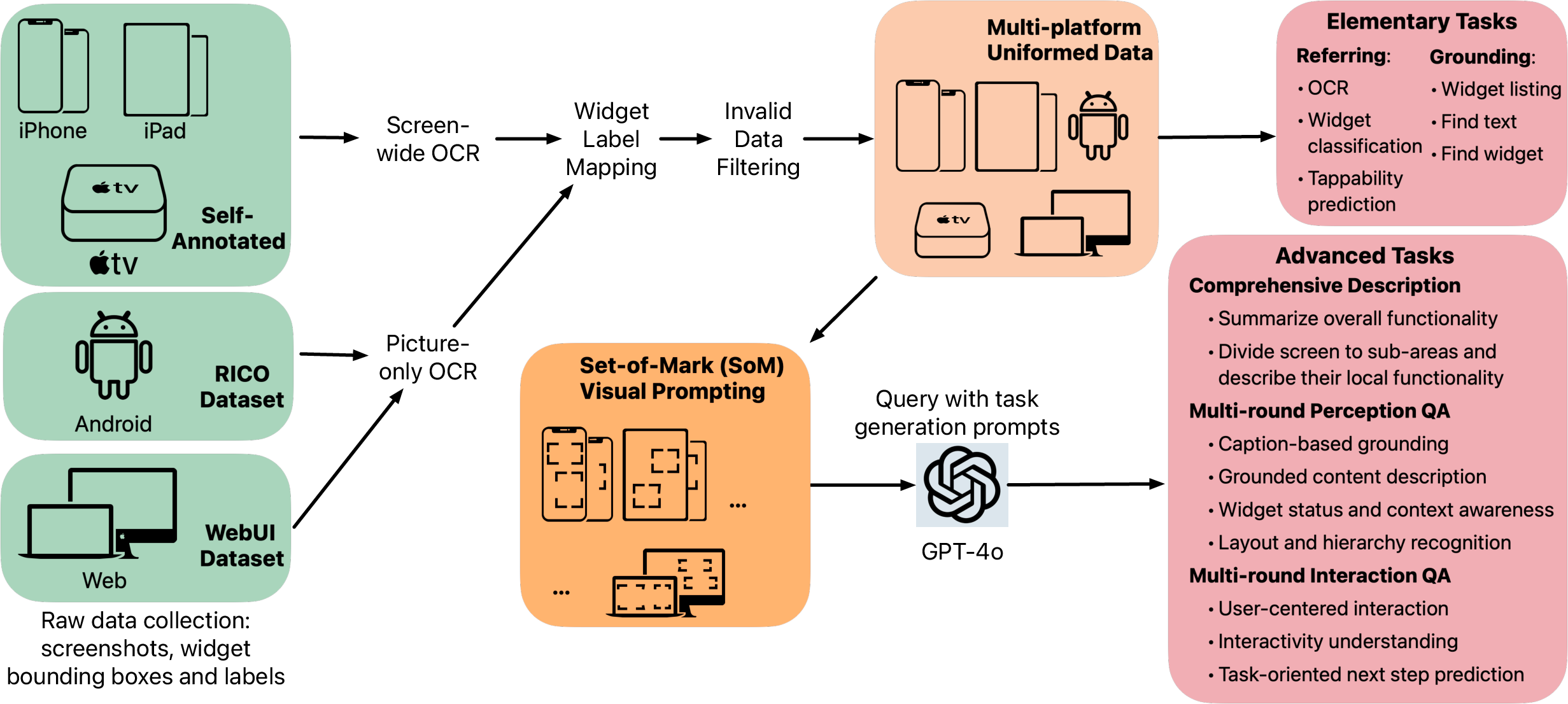
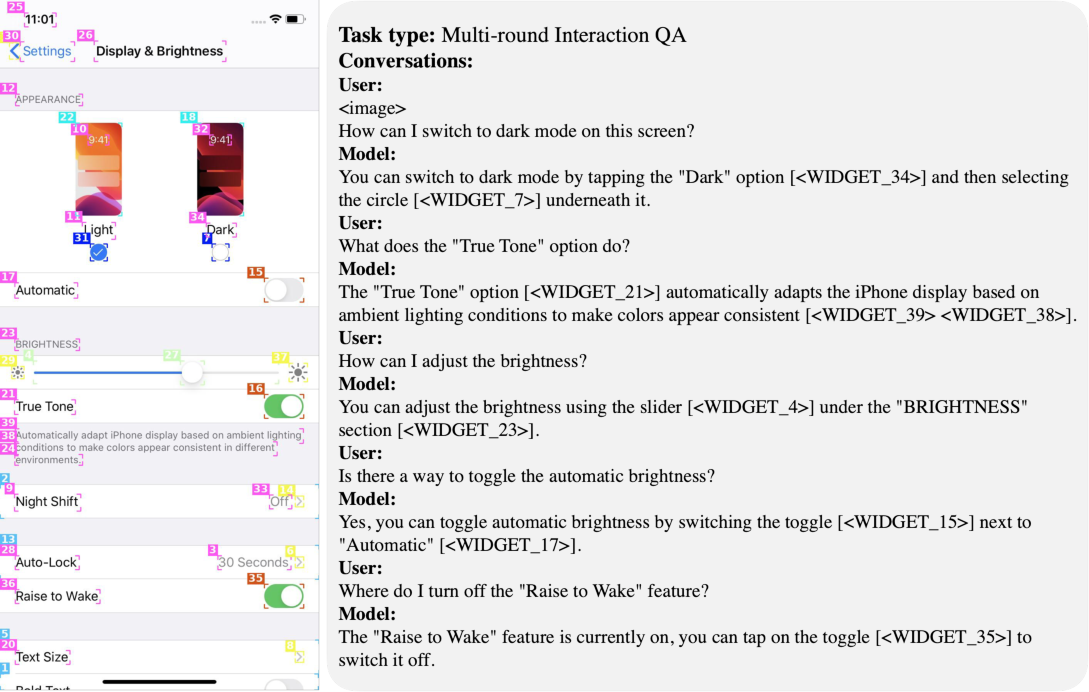
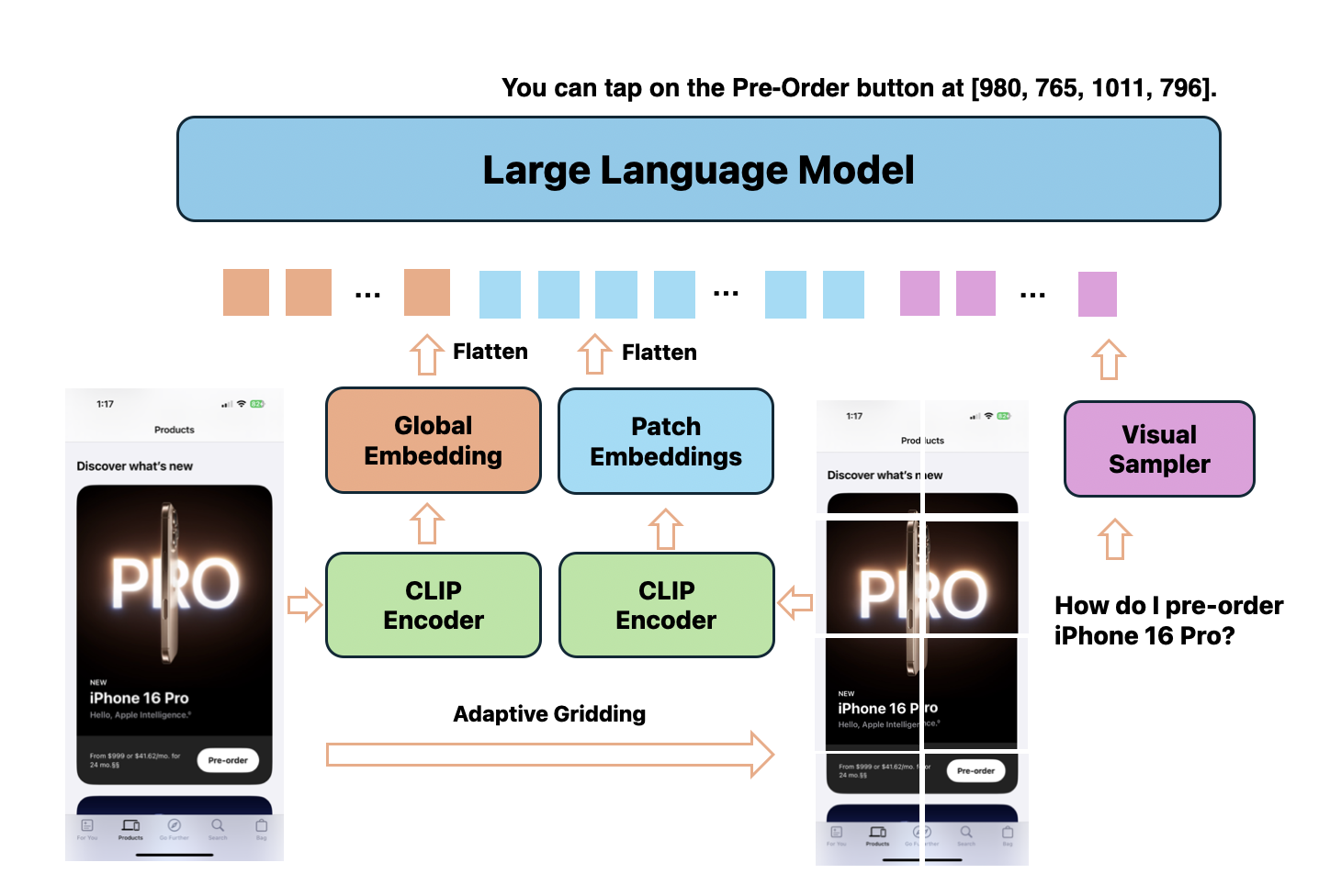
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.