- The paper presents a framework that autoformalizes mathematical statements by generating multiple candidates and ranking them using symbolic equivalence and semantic consistency evaluations.
- It employs automated theorem provers and text-embedding comparisons to ensure that formal outputs are logically valid and semantically faithful to the original statements.
- Empirical evaluations on MATH and miniF2F datasets demonstrate up to 1.35x improvements across various LLMs, underscoring the framework’s practical effectiveness.
The paper "Autoformalize Mathematical Statements by Symbolic Equivalence and Semantic Consistency" (2410.20936) introduces a novel framework for improving the autoformalization capabilities of LLMs in translating natural language mathematical statements into formal language. This framework focuses on bridging the accuracy gap between pass@1 and pass@k results by integrating two self-consistency checks: symbolic equivalence and semantic consistency.
Framework Overview
The autoformalization framework is designed to generate multiple candidate formalizations for a given mathematical statement using LLMs. After generation, it ranks these candidates using symbolic equivalence and semantic consistency methods.
Symbolic equivalence assesses the logical homogeneity across formalization candidates using automated theorem provers (ATPs), checking if the premises and conclusions of different candidates are logically equivalent. Meanwhile, semantic consistency evaluates whether the informalized version of the formal candidate maintains the original meaning by comparing text embeddings.
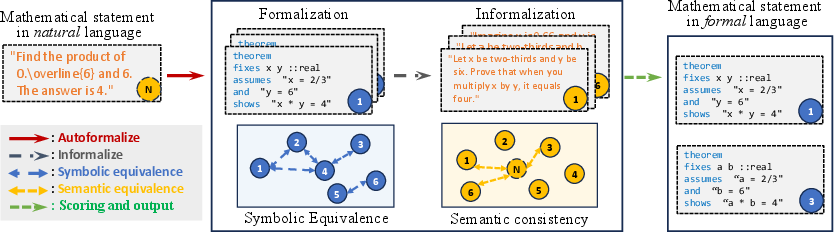
Figure 1: The overview of our autoformalization framework. In the framework, symbolic equivalence is constructed among formalized statements, and semantic consistency is computed between the informalized statements and the original statement. The scores from these two evaluations are combined to rank and select the final formalization results.
Symbolic Equivalence
Symbolic equivalence is based on the premise that correct formalizations should exhibit logical equivalence despite variable naming differences. The framework standardizes these formulations by introducing auxiliary variables to decompose them into premises and conclusions, checking their logical equivalence through ATPs like Sledgehammer, Z3, and CVC5.
Using bipartite matching to align variable names, the framework constructs equivalence classes among formalization candidates, assigning scores based on symbolic equivalence to reliably select the most accurate formalizations.
Example of autoformalization demonstrating symbolic equivalence usage:

Figure 2: An illustrative example of autoformlization. The mathematical statement from the MATH dataset is translated into a formal version by GPT-4. Only two formalization results (No.2 and No.3) are correct, while the others fail in the grounding ($\mathtt{0.\string\overline6$ to 2/3).
Semantic Consistency
Semantic consistency is determined by informalizing each formal candidate back into natural language and computing the embedding similarity to the original text using LLMs like BERT. This ensures the semantic integrity of the autoformalization result.
Semantic consistency helps detect and rectify errors in symbolic reasoning that might be overlooked, complementing the symbolic equivalence approach. It offers insight into subtle semantic nuances that purely symbolic methods may miss.
Combination Strategy
The framework combines symbolic equivalence and semantic consistency scores using three strategies—logarithmic, linear, and quadratic combinations—to optimize the selection process. Each strategy performs differently depending on the characteristics of the problems and LLM outputs.
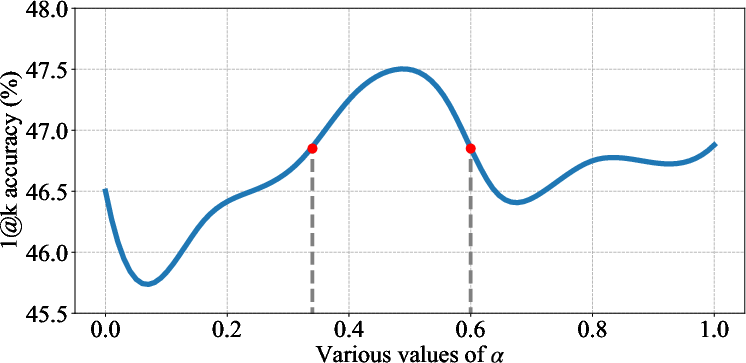
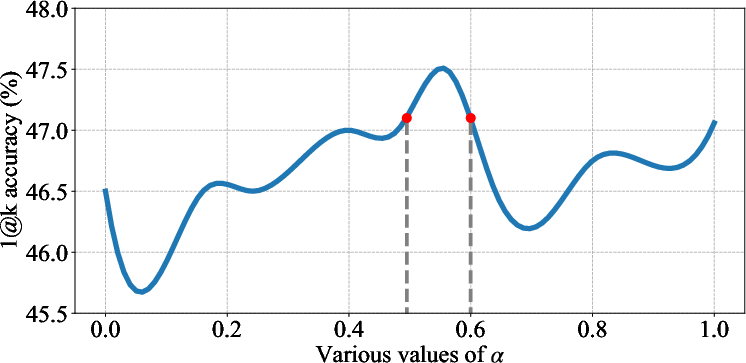
Figure 3: Performance curves of linear- (left) and quad- (right) comb across various values of alpha. The formalization results are generated by GPT-4. The results show that both combination strategies successfully improve autoformalization accuracy, while the effective range of quad-comb is smaller.
Performance analyses show that log-comb significantly boosts autoformalization accuracy across different LLMs on the MATH and miniF2F datasets, suggesting the advantage of using combined scoring techniques.
Empirical Results
Comprehensive evaluations on the MATH and miniF2F datasets demonstrate the framework's efficiency in improving autoformalization accuracy, achieving up to 0.22-1.35x relative improvements across various models and settings. The experiments include proprietary and open-source LLMs such as Codex and GPT-4, validating the broad applicability of the framework.
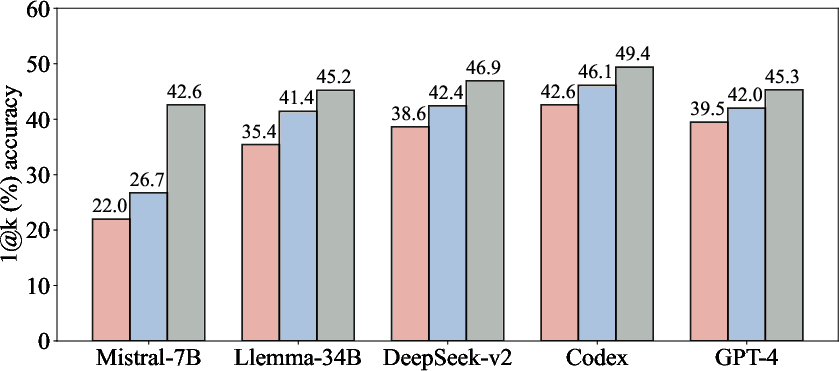
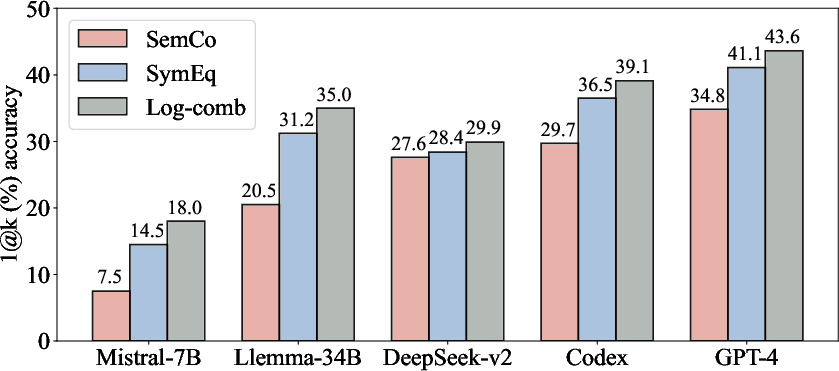
Figure 4: The performance of our proposed combination strategy (log-comb) on the MATH (left) and miniF2F (right) datasets. The results show that the log-comb further boost the autoformalization performance across various LLMs on the two datasets.
Conclusion
The paper contributes a significant enhancement to the field of mathematical autoformalization by developing a framework that leverages both symbolic equivalence and semantic consistency, demonstrating improved performance across different models. Future directions suggest adapting the method for more theorem provers and integrating advanced LLMs to further optimize the autoformalization process. Moreover, generating comprehensive datasets through this framework could propel advancements in formal language understanding and application.