- The paper introduces FormalAlign, a framework that combines cross-entropy and contrastive loss to improve alignment evaluation in autoformalization.
- It employs a dual-loss setup that trains models to generate similar embeddings for aligned sequences and differentiate misalignments.
- Evaluation on MiniF2F and FormL4 datasets shows significant gains, with precision scores up to 93.65% and alignment-selection reaching 99.21%.
The paper introduces a significant advancement in the field of autoformalization through the development of FormalAlign, an automated framework for evaluating alignment between informal (natural language) and formal (machine-verifiable) mathematical statements. FormalAlign addresses the challenge of semantic misalignment, which has been a persistent issue in tasks involving LLMs and formal theorem proving.
Autoformalization is aimed at converting informal mathematical proofs into machine-verifiable formats, thereby leveraging the strengths of both natural and formal languages. While natural language provides extensive logical reasoning and human knowledge, formal languages offer rigorous verification and proof capabilities. Existing methods, however, rely heavily on manual verification for semantic alignment, which proves inefficient and unscalable, as demonstrated by instances where logical validity is maintained, yet semantic misalignment is present (Figure 1).
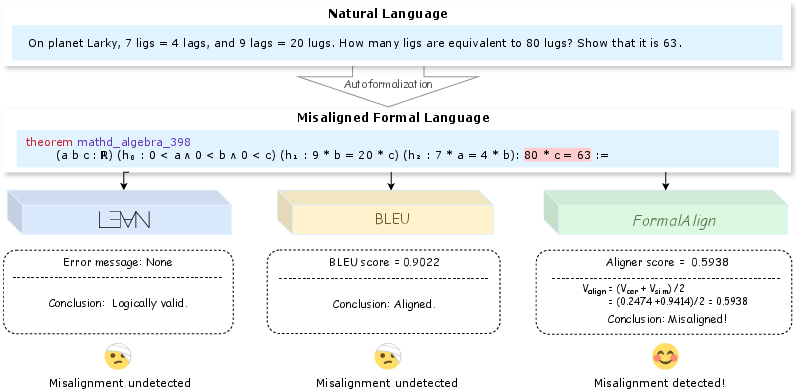
Figure 1: A comparison of current methods and FormalAlign in evaluating autoformalization. The formal statement is misaligned with the natural language statement.
FormalAlign introduces a dual-loss setup combining cross-entropy loss for sequence generation and contrastive loss for representational alignment. This framework is designed to enhance alignment evaluation by training models to produce similar embeddings for paired sequences and distinguish between aligned and misaligned ones. An overview of this mechanism is illustrated as the model processes both sequence generation and representation alignment tasks simultaneously (Figure 2).
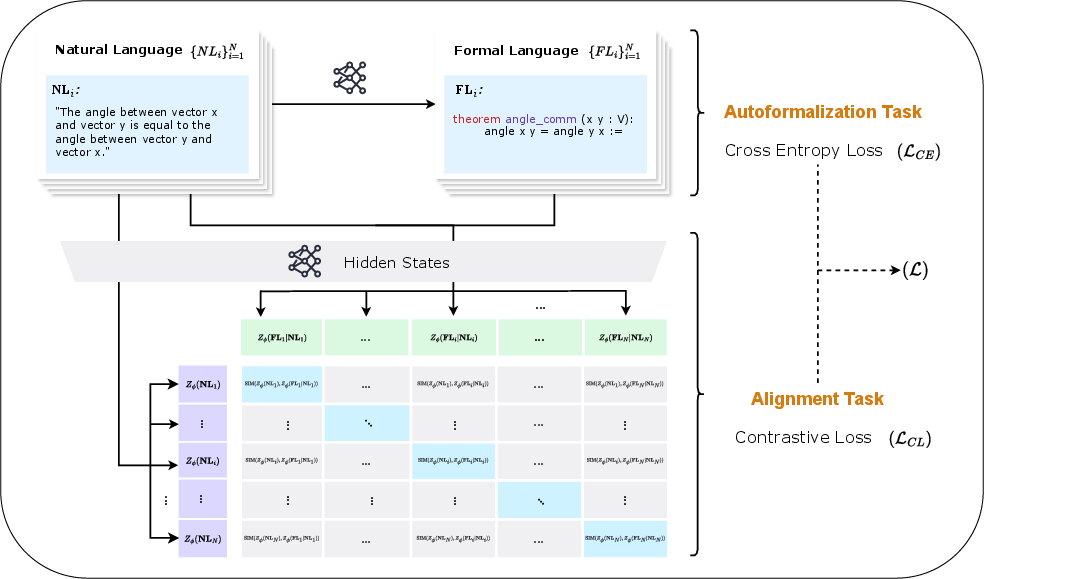
Figure 2: An overview of FormalAlign, which combines the cross-entropy loss in sequence autoformalization and the contrastive loss in hidden states to enhance the informal-formal alignment.
Evaluation and Results
To validate the effectiveness of FormalAlign, comprehensive evaluations were conducted on four benchmarks. These include datasets from MiniF2F and FormL4, which collectively undergo various misalignment strategies to generate diverse negative examples (Figure 3). Compared to state-of-the-art models like GPT-4, FormalAlign achieves significantly higher precision scores and alignment-selection metrics across these datasets. Notably, FormalAlign substantially outperforms GPT-4 in FormL4-Basic with a precision score of 93.65% and alignment-selection score of 99.21%.
Figure 3: Distribution of misalignment types across datasets. This figure illustrates the variety and proportion of misalignment strategies applied to generate negative examples in the FormL4-Basic, FormL4-Random, MiniF2F-Valid, and MiniF2F-Test datasets.
Implications and Future Directions
The introduction of FormalAlign marks a pivotal shift towards more scalable and reliable semantic alignment evaluations in autoformalization processes. While reducing reliance on manual verification, it enhances model performance in logical validity and semantic precision. Future developments might explore extending this framework to broader applications beyond mathematical reasoning, potentially enhancing AI systems in processing complex logic-based tasks across various domains.
Conclusion
FormalAlign presents a robust solution for automated alignment evaluation in autoformalization, significantly improving the scalability and accuracy of LLMs in theorem proving tasks. By combining sequence generation and representational alignment tasks, FormalAlign sets a precedent for future AI research aimed at bridging gaps between natural and formal languages. The insights derived from this framework could influence a range of applications requiring rigorous and semantically consistent autoformalization.