- The paper introduces ChatTime, a unified model that bridges numerical time series and textual data through innovative tokenization and vocabulary expansion.
- The methodology employs normalization, quantization, and discrete tokenization to enable pretrained LLMs to process time series as a language.
- Key results demonstrate superior zero-shot forecasting, multimodal context-guided prediction, and time series QA performance with significantly reduced training data.
ChatTime: A Unified Multimodal Time Series Foundation Model Bridging Numerical and Textual Data
Motivation and Background
Time series forecasting is central to real-world domains such as finance, energy, transportation, healthcare, and climate modeling. Historically, both statistical models (e.g., ARIMA) and deep learning-based architectures (RNNs, CNNs, Transformers) have been employed—primarily under unimodal numerical data paradigms. Despite the proliferation of increasingly complex models, saturated improvement curves and findings that simple linear approaches rival deep architectures signal limitations in current unimodal time series methodologies. Importantly, human experts naturally leverage both numerical and textual modalities when analyzing time series, integrating structured signals with contextual knowledge (e.g., policy reports, event descriptions). Conventional models remain inadequate in supporting such bimodal tasks, limiting their generalizability, flexibility, and real-world utility.
Recent advances in LLMs provide new opportunities for integrating sequential numerical prediction with powerful textual reasoning, enabling zero-shot and multimodal capabilities. Most LLM-based methods either inefficiently train from scratch on time series data—ignoring textual tasks—or resort to ad-hoc architectural changes with brittle dataset-specific adaptation, often lacking zero-shot generalization and robust output modalities.
The ChatTime Framework: Modeling Time Series as a Language
ChatTime introduces an architectural innovation by treating time series sequences as foreign language constructs, enabling their seamless processing within pretrained LLMs through vocabulary expansion and discrete tokenization. The workflow fundamentally revolves around normalization, quantization, custom tokenization, and vocabulary augmentation:
- Normalization and Quantization: Real-valued, unbounded time series are scaled using min-max strategies to [−1,1] (with buffer for future prediction) and discretized via uniform binning (10K bins). Each value is mapped to its bin center, creating a lossily quantized finite dictionary of discrete “foreign words.”
- Tokenization and Vocabulary Expansion: Each quantized value is encapsulated with special mark characters (e.g., “###0.2835###”) and added to the tokenizer’s vocabulary. Unlike bitwise tokenization schemes (LLMTIME) which are inefficient, ChatTime enables a single token per value regardless of precision, drastically reducing token consumption and inference cost.
- Pretraining and Finetuning: ChatTime leverages the pre-trained LLaMA-2 backbone, performing two training phases: continuous autoregressive pretraining (utilizing 1M high-quality time series slices selected via K-means clustering from large archives) and instruction fine-tuning on four tasks (unimodal forecasting, context-guided forecasting, time series QA, and textual QA). All training is performed via LoRA and 4-bit quantized models, requiring only a single RTX 4090 GPU.
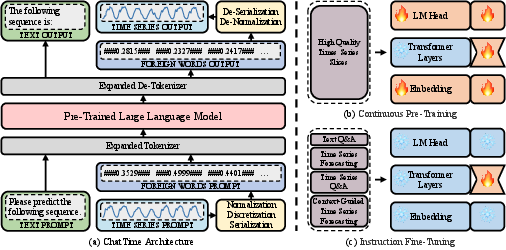
Figure 1: ChatTime architecture: numerical-real values and foreign-language tokens intertranslated with plug-ins and an expanded vocabulary; pretraining and fine-tuning reuse existing LLMs without architectural modifications.
Multimodal Task Design and Evaluation Protocol
ChatTime is evaluated on three central tasks:
- Zero-Shot Time Series Forecasting (ZSTSF): Classic unimodal forecasting on standard benchmarks across multiple domains, emphasizing out-of-domain generalization.
- Context-Guided Time Series Forecasting (CGTSF): Multimodal tasks where textual auxiliary context (e.g., weather, event description, calendar info) is integrated alongside numerical time series, and the output remains purely numerical.
- Time Series Question Answering (TSQA): Inference tasks where time series (as foreign language tokens) are provided in the prompt, and the output is textual—requiring comprehension and reasoning over time series features (trend, volatility, seasonality, and outlier detection).
Task prompts for each scenario encapsulate system, introduction, input, and response sections for unimodal, multimodal forecasting, and QA, respectively.

Figure 2: Prompt template for unimodal zero-shot time series forecasting.

Figure 3: Prompt paradigm for context-guided time series forecasting integrating textual context.
(Figures 6-9)
Figure 4: Trend-feature time series QA prompt.
Figure 5: Volatility-feature time series QA prompt.
Figure 6: Seasonality-feature time series QA prompt.
Figure 7: Outlier-feature time series QA prompt.
Experimental Analysis and Results
Zero-Shot Forecasting and Efficiency
ChatTime achieves 99.9% of the zero-shot prediction accuracy of Chronos using only 4% of the training data. In the context of models trained on single datasets (full-shot), it attains 90.9% of the accuracy of the GPT4TS SOTA. Contrary to the expectation that increasing model complexity yields substantial improvement, both GPT4TS and TimeLLM only marginally outperform DLinear, reinforcing the saturated efficacy of unimodal approaches.
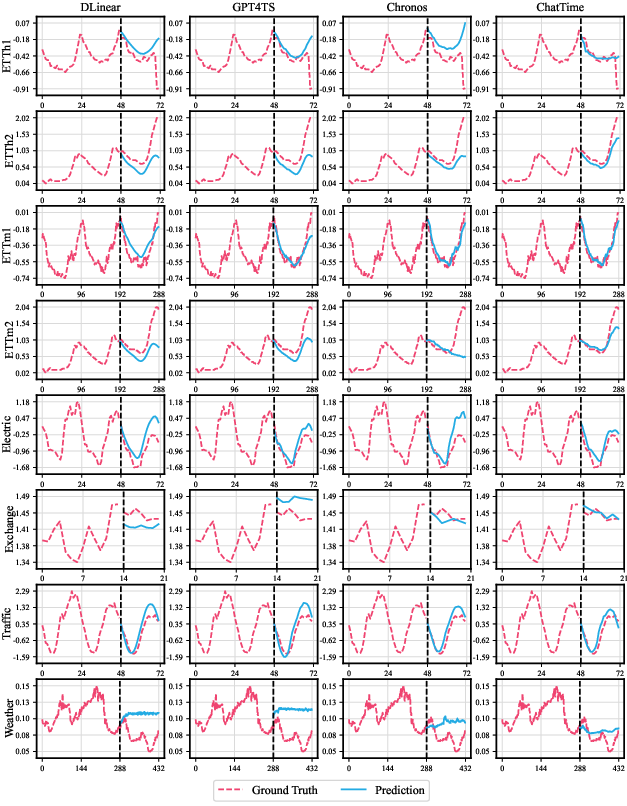
Figure 8: Representative forecasting cases on benchmark datasets with ChatTime vs. SOTA baselines.
Multimodal Context-Guided Forecasting
In CGTSF, ChatTime leverages textual context and outperforms TGForecaster, which is independently trained for each dataset, demonstrating robust generalization. Triggered by context (weather events, special days), ChatTime adjusts numerical forecasts appropriately—a capability beyond conventional unimodal models. Removing contextual input results in substantial performance degradation, validating the necessity of multimodal integration.
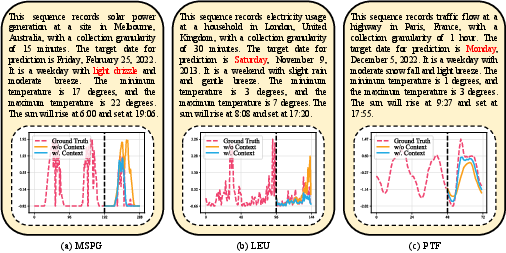
Figure 9: Forecasting showcases in context-guided multimodal settings—contextual events directly influence numerical predictions.
Time Series Feature Question Answering
In TSQA, ChatTime surpasses powerful generic LLMs (GPT4, GPT3.5, GLM4, LLaMA3-70B) by a wide margin on time series comprehension, demonstrating superior accuracy across feature categories (trend, volatility, season, outlier). This indicates that generic LLMs, despite their strength in text, lack robust time series reasoning unless explicitly trained with numerical modalities; ChatTime preserves LLM inferential capacity while bridging textual and numerical understanding.
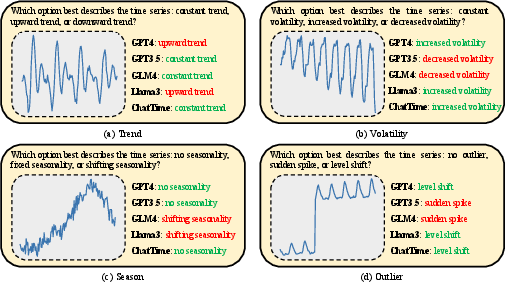
Figure 10: TSQA examples—ChatTime accurately classifies time series with feature labels, outperforming generic LLMs.
Ablation Study
Continuous autoregressive pretraining is indispensable: replacing time series pretraining data with fine-tuning data collapses zero-shot performance, causing overfitting. K-means-based data selection ("CL") and inclusion of QA in instruction fine-tuning both improve performance and generalization on all tasks; ablation confirms each component’s necessity. The loss curves corroborate these findings with visible overfitting when ablated.
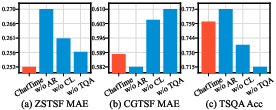
Figure 11: Ablation results on ZSTSF, CGTSF, and TSQA—removing design components significantly degrades performance across modalities and tasks.
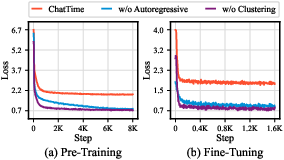
Figure 12: Training and fine-tuning loss curves for ChatTime and ablation variants—absence of high-quality, diverse pretraining leads to rapid overfitting.
Implications and Future Directions
The conceptualization of time series as a language within a unified tokenization/vocabulary paradigm enables leveraging powerful pretrained LLMs for efficient multimodal forecasting and inference. ChatTime represents a pragmatic approach to bridging the gap between sequential numerical modeling and natural language reasoning. The efficacy shown across zero-shot, multimodal forecasting, and comprehension tasks increases the potential of LLM-based time series models in heterogeneous, real-world applications. Importantly, ChatTime achieves strong accuracy using orders of magnitude less pretraining data and resources compared to prior foundation models.
Future research avenues include scaling ChatTime to larger pretraining corpora and model sizes, extending its capabilities to anomaly detection, classification, and summarization, and pursuing broader transfer learning in time series understanding. Additionally, the paradigm is extensible to other continuous modalities (e.g., sensor networks, bio-signals) and may benefit from integration with cross-modal retrieval and generative modeling frameworks.
Conclusion
ChatTime offers an efficient and unified foundation model for multimodal time series analysis, supporting zero-shot inference and seamless bidirectional integration between numerical and textual data. The architecture achieves competitive accuracy under strong benchmarking constraints with substantially reduced computation, while its design enables flexible, scalable task expansion. The framework paves the way for future multimodal foundation models bridging structured and unstructured data—heralding new research directions in sequential modeling and neural inference.