When Does Multimodality Lead to Better Time Series Forecasting?
Abstract: Recently, there has been growing interest in incorporating textual information into foundation models for time series forecasting. However, it remains unclear whether and under what conditions such multimodal integration consistently yields gains. We systematically investigate these questions across a diverse benchmark of 16 forecasting tasks spanning 7 domains, including health, environment, and economics. We evaluate two popular multimodal forecasting paradigms: aligning-based methods, which align time series and text representations; and prompting-based methods, which directly prompt LLMs for forecasting. Our findings reveal that the benefits of multimodality are highly condition-dependent. While we confirm reported gains in some settings, these improvements are not universal across datasets or models. To move beyond empirical observations, we disentangle the effects of model architectural properties and data characteristics, drawing data-agnostic insights that generalize across domains. Our findings highlight that on the modeling side, incorporating text information is most helpful given (1) high-capacity text models, (2) comparatively weaker time series models, and (3) appropriate aligning strategies. On the data side, performance gains are more likely when (4) sufficient training data is available and (5) the text offers complementary predictive signal beyond what is already captured from the time series alone. Our study offers a rigorous, quantitative foundation for understanding when multimodality can be expected to aid forecasting tasks, and reveals that its benefits are neither universal nor always aligned with intuition.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “When Does Multimodality Lead to Better Time Series Forecasting?”
What is this paper about?
This paper asks a simple but important question: If you combine numbers over time (called a “time series,” like daily temperatures or sales) with related text (like weather reports or product descriptions), do you always get better forecasts? The short answer: no. It helps in some situations, but not in others. The authors ran a big, careful study to discover when adding text actually improves predictions.
What are the main goals or questions?
The researchers studied two main ways to mix text with time series and tested them across many different kinds of data. They focused on these questions, in easy terms:
- When does adding text improve forecasts?
- Does using a bigger, smarter text model help?
- Does the strength of the time series model matter?
- How should you combine (or “align”) the text with the time series?
- Do the amount of training data and the length of the time window affect results?
- Does it matter whether the text adds new information or just repeats what the numbers already show?
How did they do it? (Methods in simple terms)
Think of forecasting like planning your week using two clues:
- a chart of what happened before, and
- notes that give context.
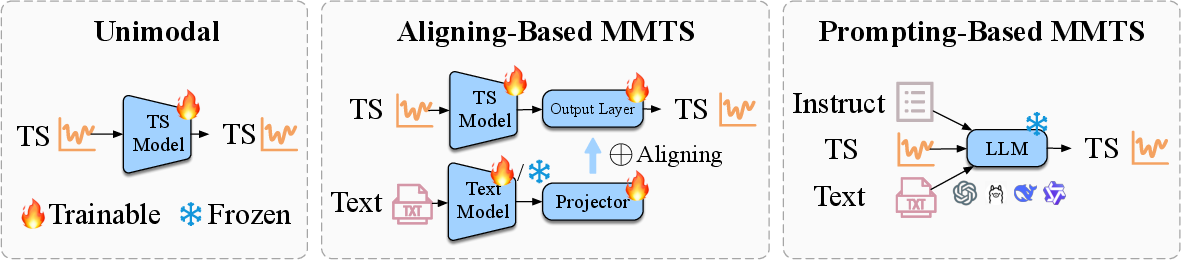
The paper compares two main ways to use these clues:
- Aligning-based methods: Imagine you have two “readers.” One reads the numbers (the time series), and the other reads the text. Then a “combiner” puts their understandings together before making a prediction. This is like having a sports stats expert and a journalist each summarize a game, then merging their summaries.
- Prompting-based methods: Here, you turn the numbers into words and give both the text and the converted numbers directly to a LLM, like asking a smart chatbot to forecast after reading a written description.
They tested these approaches on 16 real-world forecasting tasks from 7 areas (like health, environment, energy, and economics). They also did controlled experiments, including:
- Changing model sizes (small vs. big text models).
- Changing how the two types of information are combined.
- Varying training data size and input length.
- Creating synthetic (simulated) data where they know exactly whether the text adds new information or not.
They measured prediction quality using standard scores for errors (smaller is better).
What did they find, and why does it matter?
Here are the key results, with simple explanations:
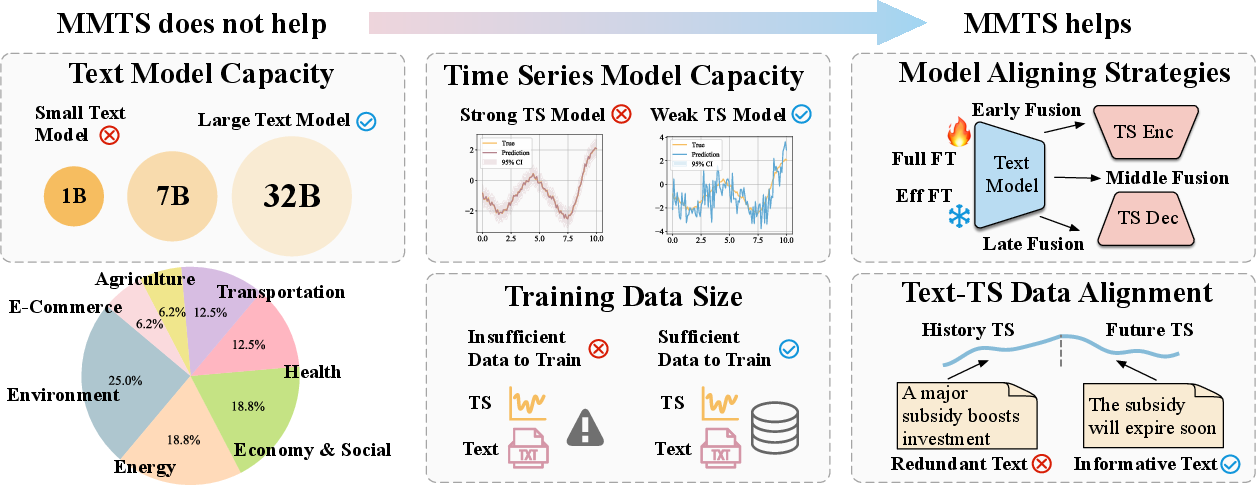
- Adding text is not a guaranteed win. Across many datasets, the best time-series-only models were often as good as or better than multimodal models. So, more information doesn’t automatically mean better predictions.
- Aligning-based methods usually beat prompting-based methods. Letting a dedicated time-series model handle the numbers and then combining its output with text worked better than asking an LLM to do everything from text prompts. A likely reason: current LLMs are great with language but still struggle with precise number patterns.
- Bigger LLMs help prompting—but still lag behind strong time-series specialists. Using larger LLMs improves prompting-based results, but they still often don’t catch up to top time-series-only models. LLMs’ general knowledge doesn’t fully replace specialized time-series skills.
- “Reasoning” LLMs didn’t help here. Models trained to show their reasoning didn’t improve forecasting in this study. They tended to use simplistic methods and didn’t make the most of the time-series plus text combination.
- Text helps more when the time-series model is weaker. If your number-only model isn’t very strong, adding text gives a bigger boost. If your number-only model is already excellent, text adds less.
- How you combine text and numbers matters.
- Add the signals rather than just stacking them to avoid bloating the features.
- Use average pooling (think: taking the overall meaning of a sentence) rather than relying on one special token.
- Use a “residual” projection (a gentle adapter) that keeps the time information intact.
- Combine (“fuse”) later in the forecasting pipeline so you don’t disturb the core time pattern learning.
- Use efficient fine-tuning for large datasets, and a two-stage approach (first adapt the connector, then fine-tune more) for smaller datasets.
- More training data helps multimodal models shine (for aligning-based methods). Multimodal models benefited more when there was lots of training data. It seems they need enough examples to learn how to mix text and numbers well.
- Shortening the time window didn’t change much. Cutting the input length (less past data) didn’t strongly change whether text helped. This suggests the text is useful mainly for extra context, not for making up for short number histories.
- Text must add something new. In controlled tests, when the text explained future changes that weren’t visible in the past numbers (“unique” info), multimodal models clearly beat number-only models. But when the text just repeated what the numbers already showed (“redundant” info), it didn’t help. In real datasets, more explicit and future-relevant text led to bigger gains. Descriptions of past history—without new insights—helped the least.
Why is this important?
This study gives practical guidance for students, researchers, and engineers:
- Don’t assume text will always improve forecasts. It depends on the model, the data, and the quality of the text.
- Use text when:
- Your time-series model is not very strong,
- You have enough training data,
- The text provides new, future-relevant clues (not just rephrasing the past).
- For model design:
- Prefer aligning-based approaches when possible,
- Combine text and numbers carefully (late fusion, add signals, average pooling, residual adapters),
- Scale LLMs for prompting if you must, but expect a gap with specialized time-series models.
Big-picture takeaway
Multimodal forecasting can be powerful, but only under the right conditions. Text helps most when it truly adds fresh, predictive context, the combining strategy is well-designed, and there’s enough data to learn from. This paper replaces hype with tested guidelines, helping people build smarter, more reliable forecasting systems.
Collections
Sign up for free to add this paper to one or more collections.