- The paper introduces Chat-TS, a framework that integrates time-series tokens into LLMs to enhance multi-modal reasoning.
- It leverages novel datasets and a discrete tokenizer that ensures near-perfect reconstruction of time-series data alongside text.
- Experimental results demonstrate a 13% improvement in time-series reasoning benchmarks, highlighting its practical potential.
Chat-TS: Enhancing Multi-Modal Reasoning Over Time-Series and Natural Language Data
Introduction
The paper "Chat-TS: Enhancing Multi-Modal Reasoning Over Time-Series and Natural Language Data" (2503.10883) addresses the limitations of current time-series models in integrating and reasoning with both time-series and textual data. Time-series data is indispensable across various domains, including healthcare and finance, where it is often coupled with contextual information represented in natural language. Despite advancements in LLMs, their integration for multi-modal reasoning involving time-series data alongside textual content remains under-explored. The paper introduces Chat-TS, an LLM-based framework that incorporates time-series tokens into the vocabulary of LLMs, thereby enhancing reasoning capabilities across these modalities without compromising natural language proficiencies.
Dataset Construction and Tokenization
A significant contribution of this paper is the novel datasets designed to support LLM training in time-series reasoning contexts. These include the TS Instruct Training Dataset, which pairs diverse time-series data with textual instructions and responses, the TS Instruct Question and Answer Gold Dataset for multi-modal reasoning evaluation, and the TS Instruct Quantitative Probing Set targeting math and decision-making. These datasets address the training data scarcity for models that combine time-series with textual data.
An equally crucial component is the discrete tokenizer designed for time-series data. This tokenizer prioritizes reconstruction accuracy over compression—essential for time-series data typically under 1000 points—and integrates time-series tokens directly into LLM vocabularies. Various tokenization strategies are explored, including vector quantization and residual vector quantization, but the simple discrete tokenizer provides near-perfect reconstruction without requiring training, mitigating potential out-of-distribution issues.
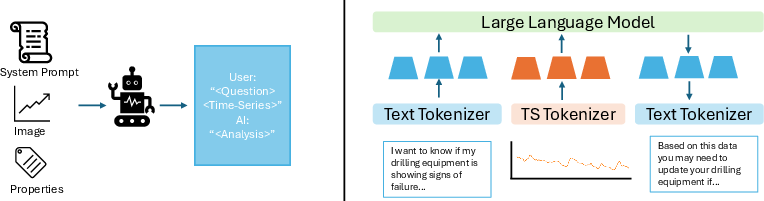
Figure 1: Overview of the TS Instruct Dataset construction followed by the Chat-TS models for time-series reasoning.
Integrative Training Strategy
The paper outlines a dual-dataset instruction tuning strategy combining multimodal TS Instruct data with a curated subset of text-based Open Orca instruction data. This integration bolsters multimodal reasoning capabilities while preserving language proficiency. Two primary initialization methods are tested: mean initialization of embeddings based on text tokens and pre-training of the embedding and final linear layers with time-series data. By strategically unfreezing specific model components, the training approach retains the inherent strengths of LLMs while enhancing them for multimodal contexts.
Experimental Results
Chat-TS demonstrates state-of-the-art performance in multi-modal reasoning tasks, improving time-series reasoning capabilities by approximately 13% on controlled benchmarks. The extensive experiments showcase how integrating time-series with text into LLMs boosts performance while maintaining general natural language strengths. Evaluations against several model variants highlight the effectiveness of the tokenization and training strategy, showing superior robustness and instruction-following abilities compared to existing methodologies.
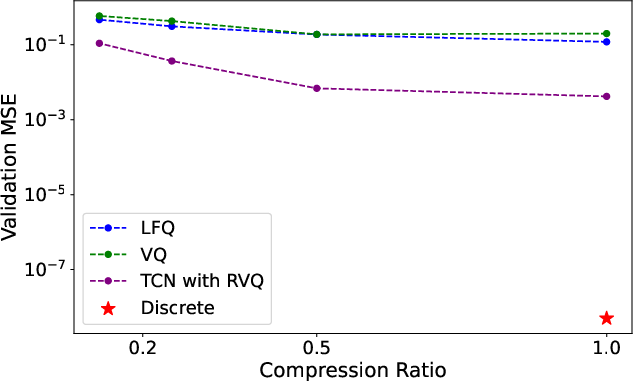
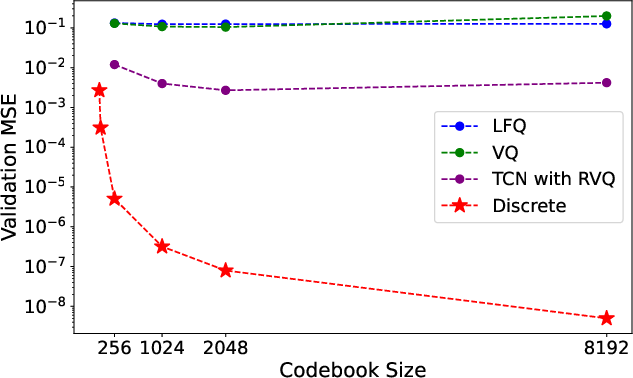
Figure 2: Tokenizer compression ratio vs reconstruction error.
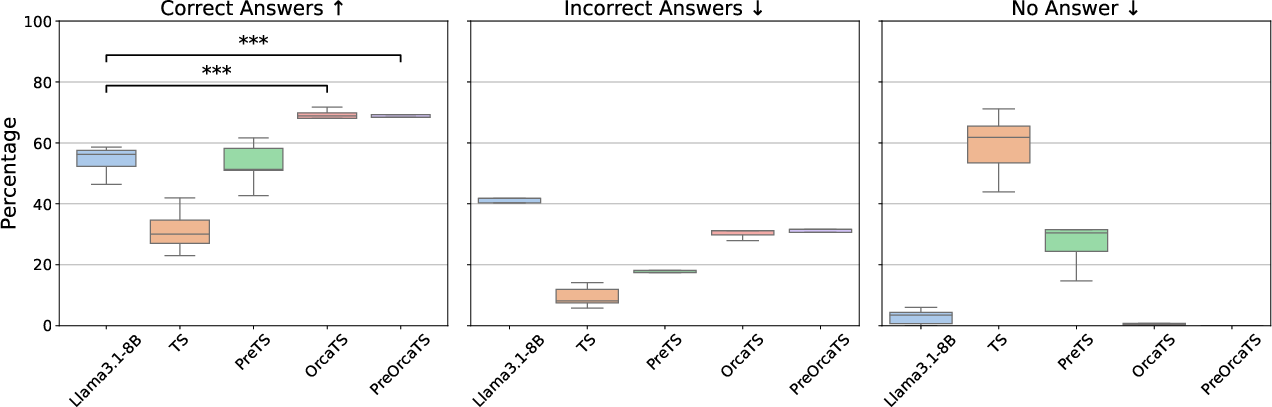
Figure 3: Performance of each model on the TS-Instruct QA dataset across prompt variations. Statistical significance between LLama 3.1-8B, OrcaTS, and PreOrcaTS is indicated by * (p-value < 0.05).
Implications and Future Directions
The findings from Chat-TS have profound implications for practical applications requiring integrated analysis of time-series and language data. The enhanced reasoning capabilities make it suitable for applications ranging from financial forecasting to advanced clinical decision-making. The paper opens avenues for future research focused on overcoming limitations such as time-series generation, improved tokenizer designs that preserve numeric precision, and extending classification performance across varied tasks.
Conclusion
"Chat-TS: Enhancing Multi-Modal Reasoning Over Time-Series and Natural Language Data" (2503.10883) provides a pioneering framework that integrates LLMs with time-series reasoning without sacrificing language modeling capabilities. By offering new datasets, a tokenization model prioritizing reconstruction, and a strategic training process, Chat-TS sets a benchmark for future innovations in multi-modal time-series reasoning. Further research inspired by these findings can continue to refine and expand the capabilities of LLMs in diverse real-world applications.