- The paper introduces Themis, an LLM-as-a-Judge model leveraging scenario-dependent evaluation prompts to enhance grading efficiency.
- It details a comprehensive pipeline including prompt design, controlled instruction generation, fine-tuning with Qwen-2 models, and performance assessment with metrics near GPT-4.
- The study reveals practical lessons on balancing fine-tuning data, multi-objective training, and unifying performance metrics to optimize evaluations.
Training an LLM-as-a-Judge Model: Pipeline, Insights, and Practical Lessons
This essay provides a detailed analysis of the paper "Training an LLM-as-a-Judge Model: Pipeline, Insights, and Practical Lessons" (2502.02988), which introduces a fine-tuned LLM judge, Themis. The paper outlines the development pipeline, scenario-dependent evaluation prompts, controlled instruction generation methods, and insights into the LLM-as-a-judge paradigm.
Development Pipeline
The development pipeline for Themis is comprehensive, encompassing prompt design, data construction, fine-tuning, and performance assessment.
Prompt Design
The effectiveness of LLM-as-a-Judge is significantly influenced by evaluation prompts. Themis employs scenario-dependent evaluation prompts, which provide context-awareness for instruction-specific evaluations.
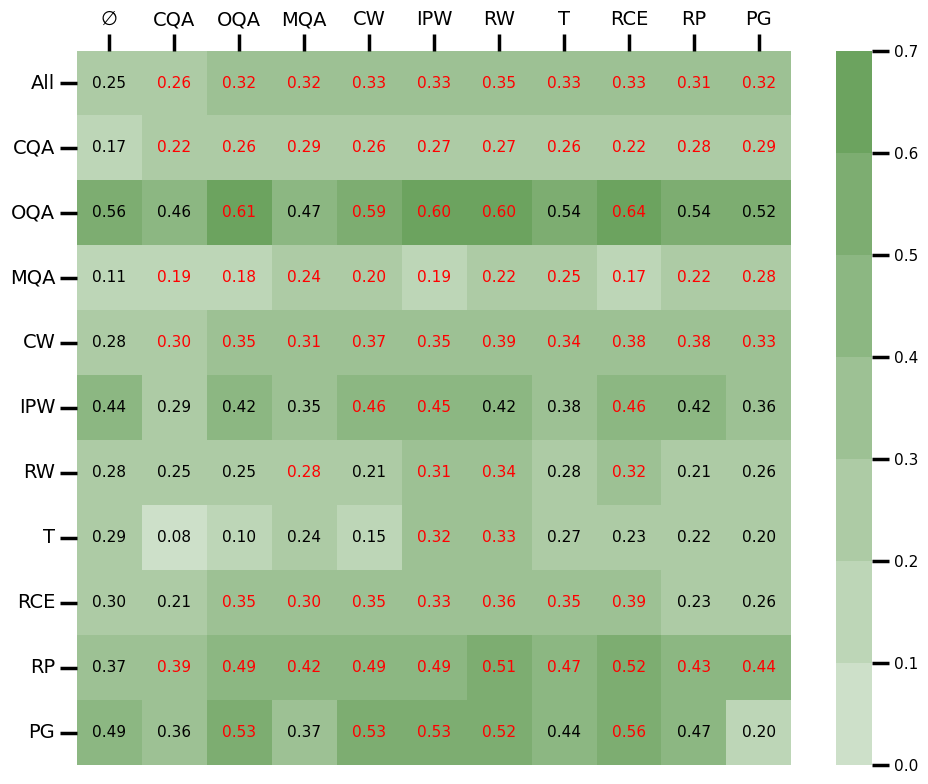
Figure 1: Performance of fine-tuning with single scenario data. Each column denotes a model fine-tuned using data from a single scenario, with emptyset being the baseline without fine-tuning. Each row reports the performance of different models on a specific scenario.
Each scenario has specific judge criteria, and detailed, step-by-step prompts are constructed for single answer grading, reference-guided grading, and pairwise comparison. These are formulated to enhance learning efficiency and interpretability.
Data Construction
Data is constructed through a combination of controlled instruction generation methods: reference-based questioning and role-playing quizzing. These methods ensure a balanced and comprehensive collection of user instructions across diverse scenarios.
Fine-tuning
The fine-tuning process utilizes Qwen-2 series base models, ensuring efficient model adaptation. Scenario classification and questioning LLMs are fine-tuned to handle specific task assignments.
Two human preference benchmarks, Alignbench and SynUI, are created for performance assessment. Themis demonstrates effectiveness, achieving performance metrics close to its teacher model, GPT-4, while using fewer parameters.
Insights from Scenario-centric Analysis
The paper provides several insights into the LLM-as-a-judge paradigm through scenario-centric analysis.
A positive correlation is observed between LLMs' inherent capacity and their evaluative performance. Themis excels in open-ended scenarios but shows limitations in close-ended scenarios.
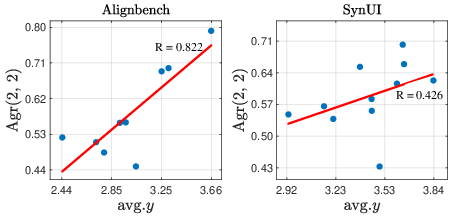
Figure 2: Impacts of data composition.
Reference Answers' Impact
Reference answers generally benefit performance in close-ended scenarios but have negligible or negative effects in open-ended ones.
Data Composition and Scaling
Fine-tuning significantly impacts performance based on data composition, and advanced data selection strategies, like Instruction-Following Difficulty (IFD), have shown promise in optimizing data scaling.
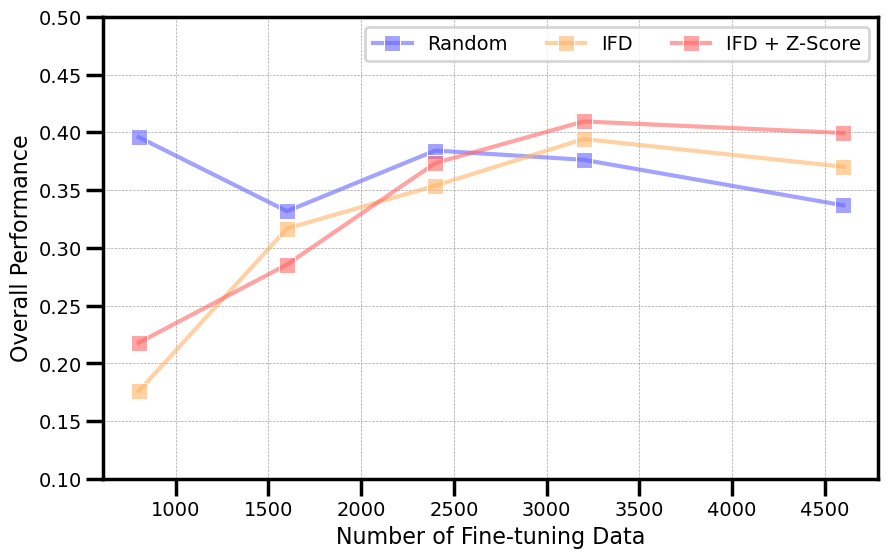
Figure 3: Impacts of scaling w.r.t. data selection strategies.
Practical Lessons
The following practical lessons are shared for developing LLM-as-a-Judge models:
- Balancing Fine-tuning Data: Distributions of evaluation scores and ratings influence model bias.
- Supporting Custom Evaluation Prompts: Enhancements include rephrased criteria and diversified evaluation prompts.
- Enabling Multi-objective Training: This method uses different optimization targets for structure-related and explanation-related text.
- Unifying Performance Metrics: Aggregating metrics helps in efficient decision-making during model optimization.
Conclusion
The paper presents a comprehensive pipeline for developing an LLM-as-a-Judge named Themis, providing insights and practical guidelines for future research. Themis offers automatic evaluations close to GPT-4's accuracy, using significantly fewer resources. Future research could explore mitigating data quality issues and developing specialized foundation models for enhanced generalization.