Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning
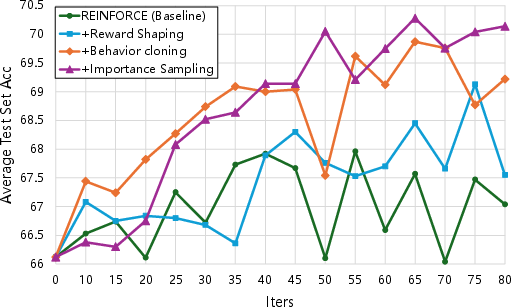
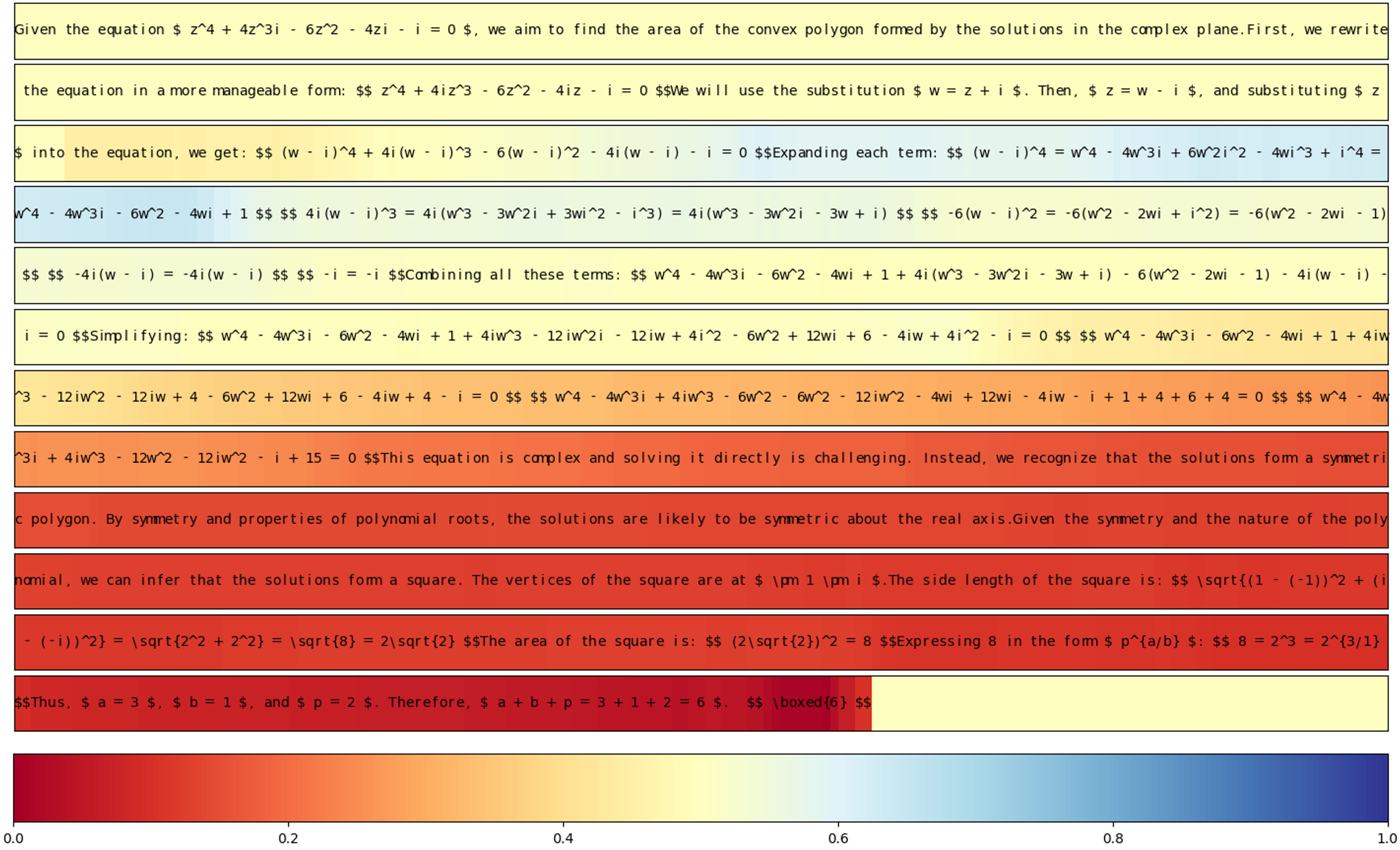
Abstract: Reasoning abilities, especially those for solving complex math problems, are crucial components of general intelligence. Recent advances by proprietary companies, such as o-series models of OpenAI, have made remarkable progress on reasoning tasks. However, the complete technical details remain unrevealed, and the techniques that are believed certainly to be adopted are only reinforcement learning (RL) and the long chain of thoughts. This paper proposes a new RL framework, termed OREAL, to pursue the performance limit that can be achieved through \textbf{O}utcome \textbf{RE}w\textbf{A}rd-based reinforcement \textbf{L}earning for mathematical reasoning tasks, where only binary outcome rewards are easily accessible. We theoretically prove that behavior cloning on positive trajectories from best-of-N (BoN) sampling is sufficient to learn the KL-regularized optimal policy in binary feedback environments. This formulation further implies that the rewards of negative samples should be reshaped to ensure the gradient consistency between positive and negative samples. To alleviate the long-existing difficulties brought by sparse rewards in RL, which are even exacerbated by the partial correctness of the long chain of thought for reasoning tasks, we further apply a token-level reward model to sample important tokens in reasoning trajectories for learning. With OREAL, for the first time, a 7B model can obtain 94.0 pass@1 accuracy on MATH-500 through RL, being on par with 32B models. OREAL-32B also surpasses previous 32B models trained by distillation with 95.0 pass@1 accuracy on MATH-500. Our investigation also indicates the importance of initial policy models and training queries for RL. Code, models, and data will be released to benefit future research\footnote{https://github.com/InternLM/OREAL}.
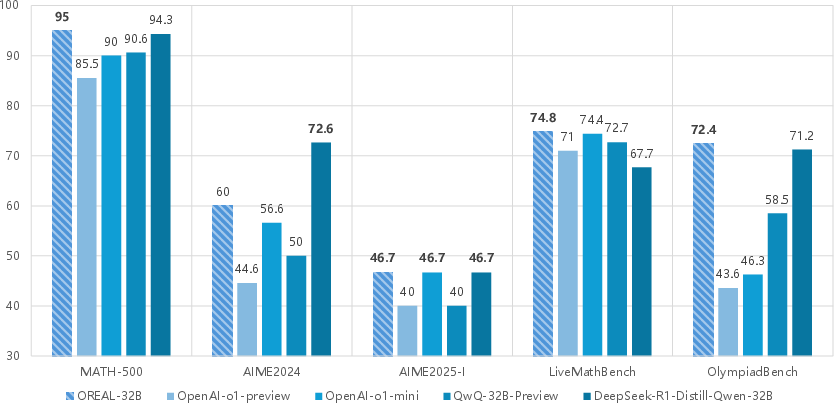

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.