- The paper introduces a dual-process alignment framework that pairs LLM responses with fast heuristic (System 1) and slow deliberative (System 2) cognitive strategies.
- It employs Direct and Simple Preference Optimization to fine-tune performance across arithmetic, symbolic, and commonsense tasks.
- An entropy-based arbitration method dynamically selects between reasoning modes, enhancing accuracy by balancing speed and detail.
Reasoning on a Spectrum: Aligning LLMs to System 1 and System 2 Thinking
Introduction
The paper "Reasoning on a Spectrum: Aligning LLMs to System 1 and System 2 Thinking" (2502.12470) presents a systematic investigation into the alignment of LLMs with fast, heuristic (System 1, S1) and slow, deliberative (System 2, S2) thinking. Drawing on foundational theories of dual-process cognition, the work articulates both methodological and empirical advances: the design of a fine-grained dataset encapsulating cognitive heuristics, explicit preference-based alignment of LLMs, and comprehensive evaluation across a spectrum of established reasoning benchmarks. The authors interrogate the prevailing assumption that structured, step-by-step CoT reasoning is always optimal and introduce a dynamic, entropy-based arbitration mechanism to adaptively select between S1 and S2 strategies without additional training.
Dataset and Alignment Framework
A core contribution is the construction of a 2,000-example dataset where every question is paired with both a System 1 and System 2 response, each mapped to one of ten well-established cognitive heuristics (e.g., anchoring bias, overconfidence bias, status quo bias).
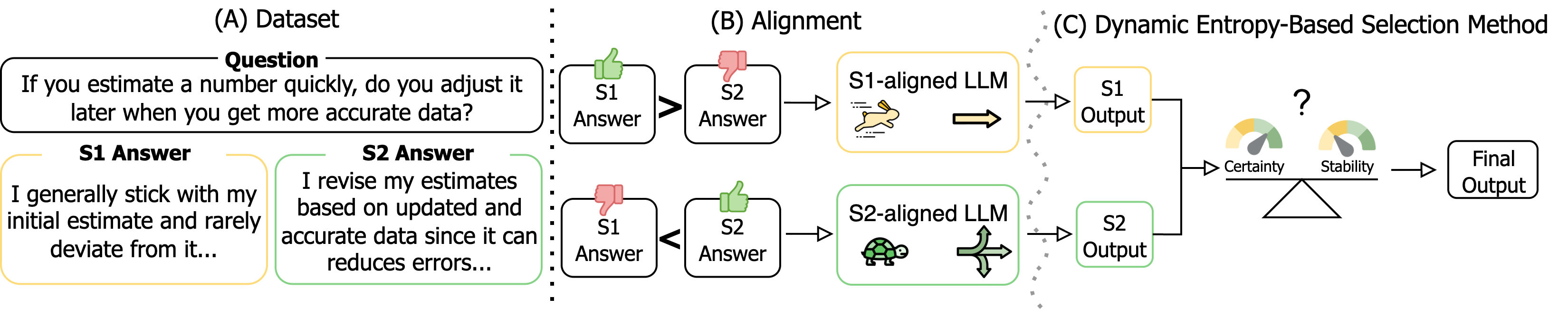
Figure 1: (A) Sample of dataset with System 1 and System 2 answers. (B) Overview of alignment with fast/slow thinking. (C) Entropy-based dynamic selection method.
Preference-based optimization methods—Direct Preference Optimization (DPO) and Simple Preference Optimization (SimPO)—are utilized to align Llama-3-8B-Instruct and Mistral-7B-Instruct models to either System 1 or System 2 responses. The framework captures fine-grained distinctions in reasoning process, not simply output content, with rigorous length adjustment to control for artifacts introduced by output verbosity.
Empirical Findings: Task-dependent Accuracy-Efficiency Trade-offs
Explicitly aligned models yield strongly differentiated behavior and performance across arithmetic (e.g., MultiArith, GSM8K, AddSub), symbolic (e.g., Last Letter Concatenation, Coin Flip), and commonsense (e.g., CSQA, SIQA, PIQA, Com2Sense) benchmarks. Key findings include:
- S2-aligned models surpass S1 and baseline models in all arithmetic and symbolic reasoning tasks, particularly where multi-step computation and logical structuring are required.
- S1-aligned models consistently outperform S2 and baseline models on commonsense reasoning tasks, mirroring humans' efficiency in heuristics-driven, context-sensitive inference.
- Performance trends observed in Llama-3-8B-Instruct are consistent in Mistral-7B-Instruct.
Notably, instruction-tuned models with zero-shot CoT offer only marginal gains over unaligned baselines, illustrating that CoT-style rationales are not universally optimal. The authors further confirm that S2 outputs are reliably longer and more detailed compared to the succinct outputs favored by S1, even after controlling for prompt/response length in the data curation process.
Uncertainty, Confidence, and Reasoning Commitment
Mechanistic analysis uncovers systematic differences in model uncertainty and commitment that robustly parallel psychological theory:
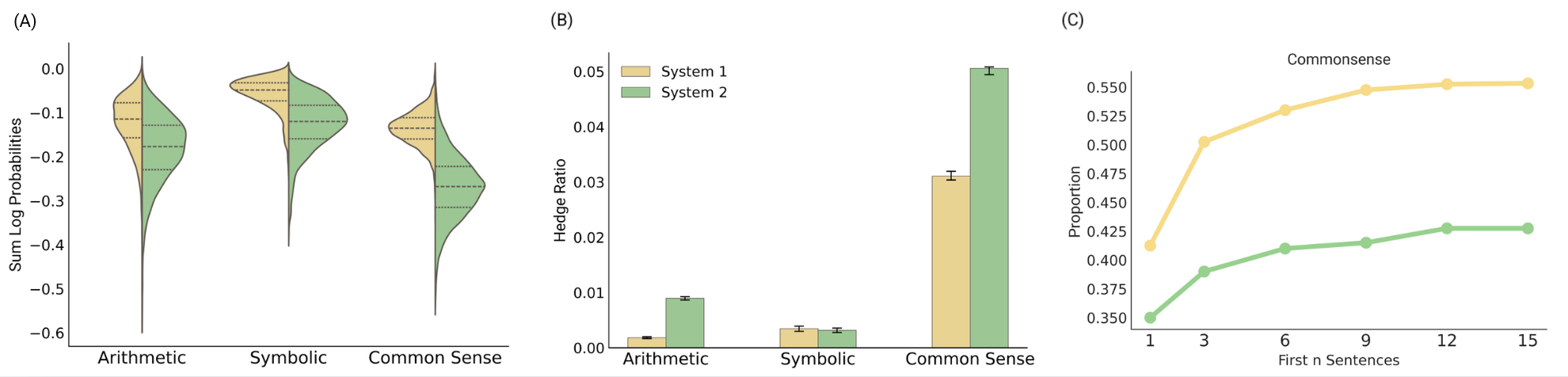
Figure 2: (A) System 2 models show greater internal uncertainty; (B) System 2 produces more hedge words; (C) System 1 yields more definitive answers in early reasoning.
- S2 responses display increased token-level entropy and a higher proportion of hedged language across all reasoning domains, reflecting analytical “caution.”
- S1 models generate more definitive answers, particularly in initial reasoning steps, evidencing heuristics-driven decisiveness advantageous in commonsense tasks.
Rigorous statistical analyses confirm these trends (e.g., t-tests, McNemar's χ2).
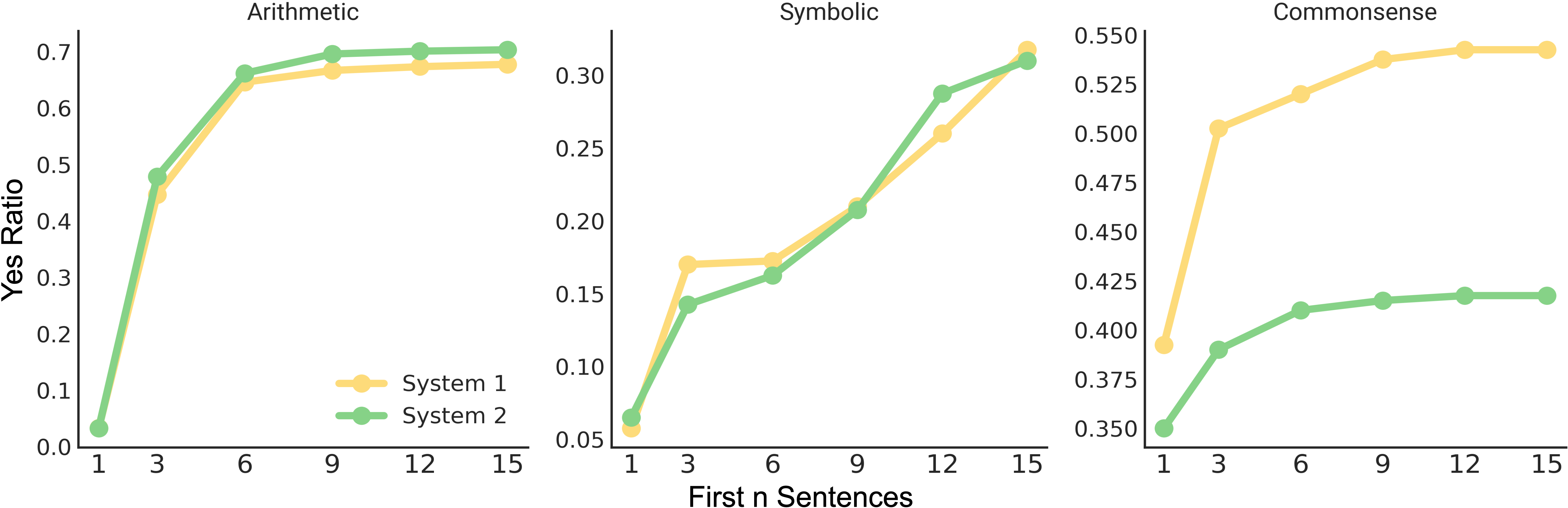
Figure 3: System 1 models consistently commit to definitive answers earlier in the reasoning process for commonsense tasks.
The Reasoning Spectrum: Interpolating Between Fast and Slow Thinking
Extending beyond dichotomous alignment, models are trained on datasets with varying S1:S2 preference ratios. As the interpolation proceeds from fast to slow thinking, the accuracy on arithmetic/symbolic tasks monotonically increases (favoring S2), while the reverse is observed for commonsense tasks. The transition appears smooth, continuous, and stable with no abrupt performance drops.
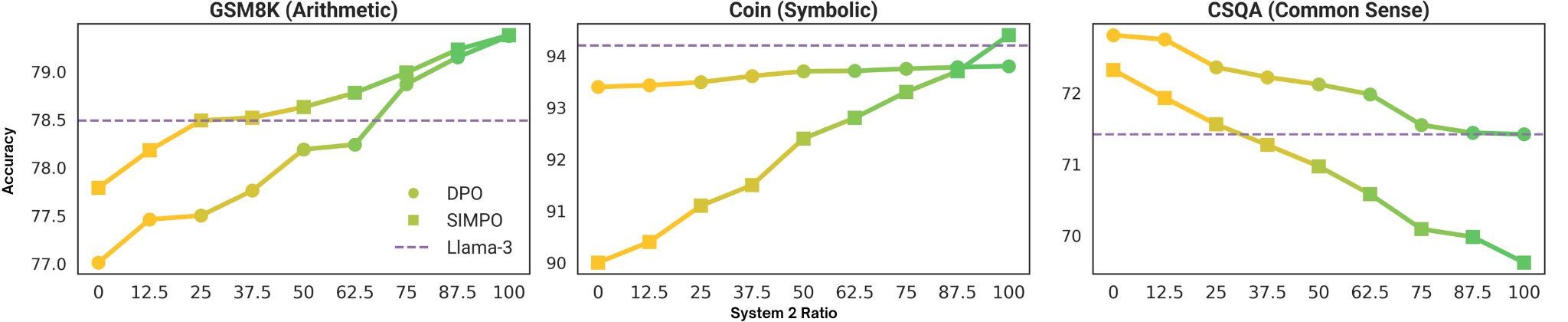
Figure 4: Accuracy across reasoning benchmarks as alignment interpolates from System 1 to System 2 preferences.
Figure 5: Fine-grained accuracy transitions for multiple benchmarks as reasoning shifts along the spectrum.
This suggests that LLMs possess latent capacity for nuanced reasoning style adjustment, enabling continuous task-dependent trade-offs between speed, accuracy, and response format.
Entropy-based Dynamic Arbitration
The authors propose a training-free arbitration mechanism: for any input, both S1 and S2-aligned models generate outputs; token-level entropy (Hˉ) and its variance (σ2) are computed and combined as a reliability score. For each query, the answer from the model with lower score is selected.
(Figure 1, Panel C)
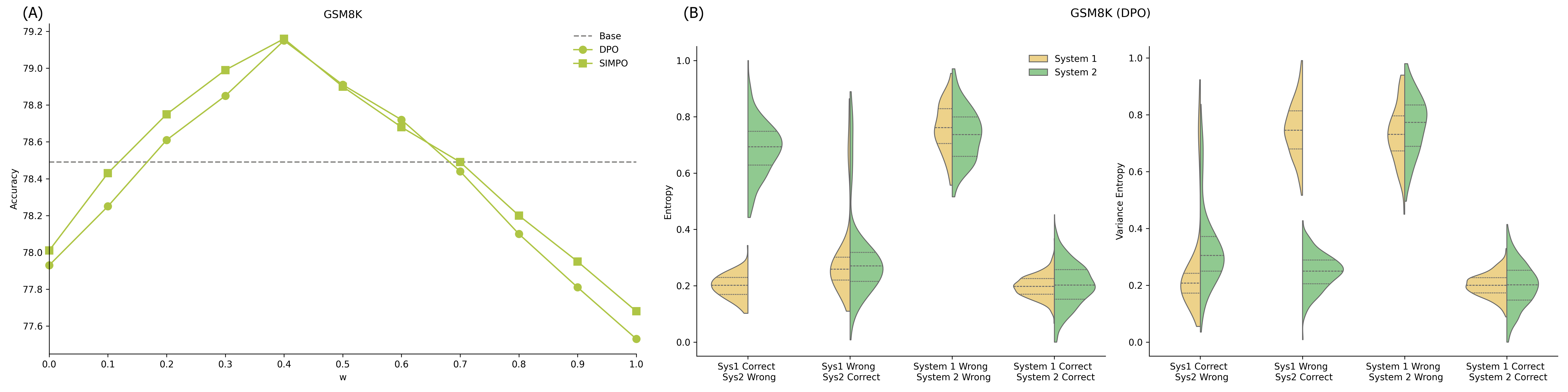
Figure 6: (A) Dynamic Llama model accuracy on GSM8K as the arbitration weight w is swept. (B) Entropy and variance statistics for correct/incorrect responses across systems.
This method yields higher accuracy than any single alignment across 11–12 out of 13 benchmarks without any new parameter training, and robust performance holds for both alignment algorithms and model architectures. The arbitration places higher penalty on instability (variance) than on caution (entropy), consistent with theoretical predictions and recent empirical work on LLM reasoning stability.
Implications, Limitations, and Future Directions
This study provides clear empirical evidence and systematic methodology supporting the view that step-by-step, deliberative CoT-style reasoning is not universally optimal. Instead, aligning LLMs with both S1 and S2 processes, and dynamically adapting the chosen style at inference time, produces more robust, efficient, and contextually appropriate outputs.
Bold claims include:
- Structured, step-by-step reasoning can degrade performance on commonsense problems—a direct contradiction to prevailing LLM training paradigms.
- Simple, training-free arbitration achieves state-of-the-art adaptation capability across diverse reasoning categories.
These findings have practical ramifications for real-world LLM deployment: enabling deliberate speed-accuracy trade-offs, reducing computational cost where quick responses are acceptable, and increasing reliability where deliberative reasoning is required. From a cognitive modeling perspective, the work demonstrates that LLMs, when carefully aligned and analyzed, recapitulate key features of human dual-process cognition, including metacognitive uncertainty and context-sensitive commitment.
Nonetheless, limitations remain. The dynamic selector currently incurs a compute cost by requiring both models to run for every query; distillation into a unified, efficient architecture is a crucial avenue for future work. The dataset, while broad, can be further expanded to encompass richer, less formulaic real-world reasoning problems. Extending, validating, and scaling the approach with more diverse model architectures and other alignment protocols are immediate directions.
Conclusion
The study rigorously demonstrates that aligning LLMs along a S1–S2 spectrum yields distinct, interpretable strengths and exposes the inadequacy of static, monolithic reasoning modes. The entropy-based, dynamic arbitration procedure allows task-adaptive selection, outperforming either fixed mode across a competitive suite of benchmarks, and provides a concrete, actionable framework for engineering more cognitively flexible, efficient, and human-aligned LLMs. This work constitutes a concrete advance toward adaptable, context-sensitive language reasoning, informing both model developers and cognitive scientists interested in the intersection of artificial and natural intelligence.