- The paper introduces a task parallelizability framework that predicts when multi-agent reinforcement learning systems should adopt specialization versus generalist policies.
- It employs an analytic bound inspired by Amdahl's Law and validates the model across SMAC, MPE, and Overcooked-AI benchmarks.
- Findings reveal that environmental bottlenecks and state space complexity critically influence the emergence and effectiveness of specialized policies.
Predicting Multi-Agent Specialization via Task Parallelizability
Introduction
The paper "Predicting Multi-Agent Specialization via Task Parallelizability" (2503.15703) presents a theoretical and empirical approach for predicting when specialization or generalist behavior will emerge in cooperative multi-agent reinforcement learning (MARL) systems. Challenging the prevailing assumption of universal benefit from specialization, the authors formalize task parallelizability—rooted in system-level bottleneck analysis—as the critical determinant of emergent specialization. Building on a closed-form analytic bound inspired by Amdahl’s Law, the paper delivers a framework for predicting and diagnosing specialization in MARL across multiple domains, including StarCraft Multi-Agent Challenge (SMAC), Multi-Particle Environment (MPE), and Overcooked-AI.
Task Parallelizability Framework
The core contribution is a closed-form bound for predicting the advantage of specialization as a function of subtask allocation, team size, spatial, and resource bottlenecks. The framework operationalizes parallelizability S(N,C) as the achievable speed-up when N agents perform a decomposed task in parallel, given concurrency limitations:
S(N,C)=∑i=1mmin(N,Ci)fi1
where fi is fraction of time spent on subtask i and Ci is the capacity (minimum of spatial and resource bottlenecks) of i. When S(N,C)<N, specialization is predicted to be optimal. Policy differentiation is quantified by Jensen-Shannon divergence (Specialization Index, SI), measuring disjoint support in action distributions.
This analytic prediction is task- and environment-agnostic. The prediction asserts that removing bottlenecks always favors generalists, and only when parallelizability is limited does optimal performance require specialization.
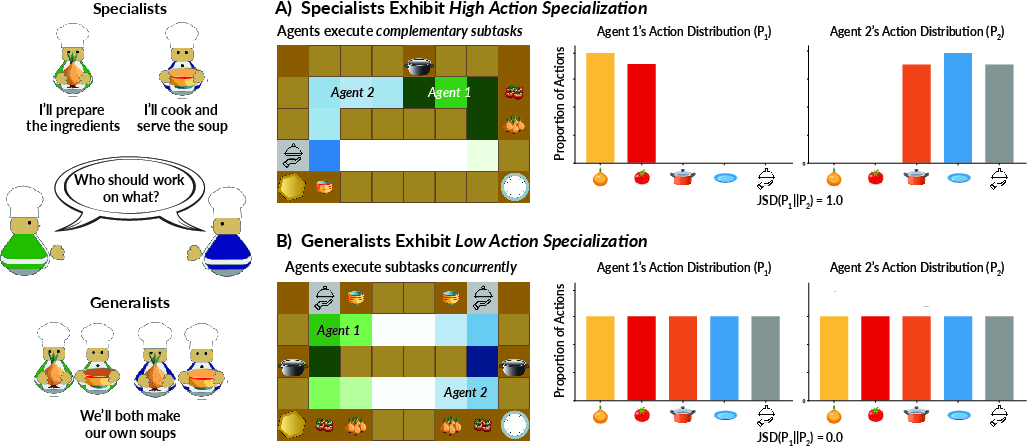
Figure 1: Illustration of specialist teams (high SI) versus generalist teams (low SI) as measured by divergence in action distributions.
Empirical Validation: Edge-Case Benchmarks
SMAC and MPE
The framework is first validated in two canonical MARL benchmarks with opposite bottleneck regimes:
- SMAC: Absence of spatial/resource bottlenecks (Ci→∞), leading to S(N,C)=N. Empirically, agents consistently evolved generalist policies (mean SI ≈ 0.06), with SI decreasing with team size (Pearson r=−0.86).
- MPE: Severe bottlenecks (Ci=1), so S(N,C)=1 regardless of N. Emergent policies are highly specialized (mean SI ≈ 0.61).
The logistic regression on parallelizability perfectly separates these regimes (accuracy=1.0). The inverse and nearly linear relationship between SI and S is strongly supported (r=−0.84).
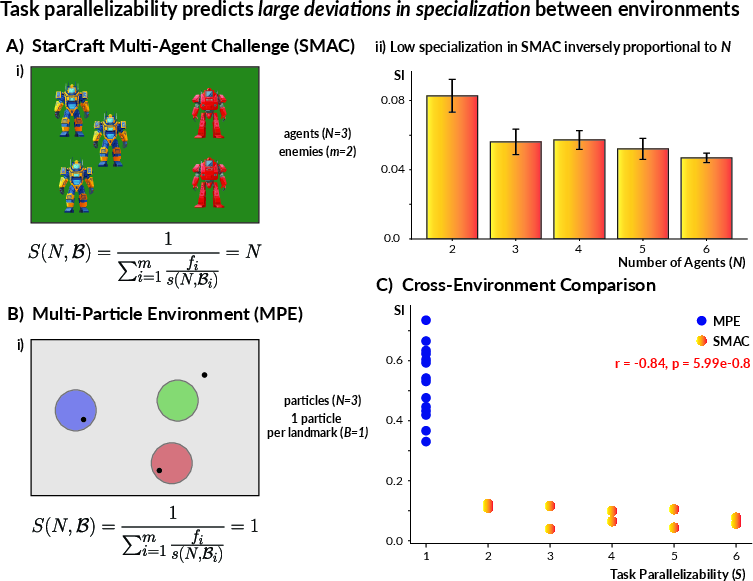
Figure 2: Across SMAC and MPE, specialization (SI) is strongly anti-correlated with predicted parallelizability, confirming the analytic model.
Environment Complexity: Overcooked-AI Experiments
Controlled Bottleneck Manipulation
In Overcooked-AI, the paper probes specialization along fine-grained axes by varying spatial layouts and workstation (resource) counts. Six different 5×5 layouts with varying numbers of pots induced a comprehensive array of concurrency structures.
A distinctly bimodal SI distribution was observed: teams clustered as either generalists or specialists, not intermediates. Model accuracy for predicting high vs. low specialization via logistic regression was 91%.
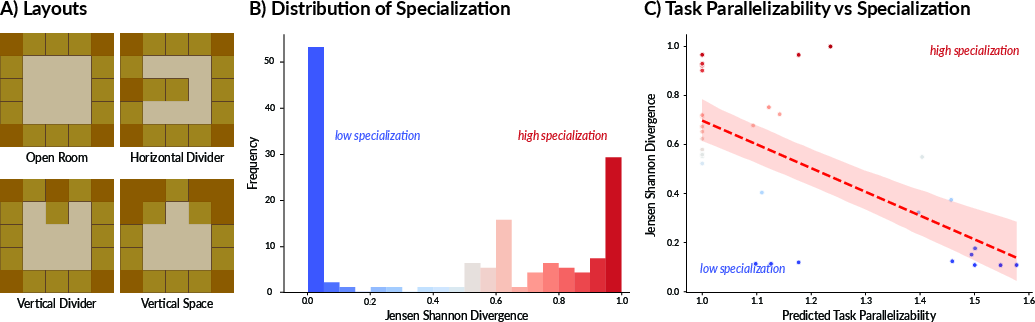
Figure 3: Overcooked-AI experiments reveal a bimodal SI distribution and strong negative correlation between parallelizability and SI across many layouts and resource configurations.
Large-Scale Layout Diversity
Scaling up, 3,200 unique Overcooked-AI layouts were analyzed. The anti-correlation between predicted parallelizability S and SI persisted, but with more pronounced deviations for complex environments (average r=−0.486). Increased layout size and recipe complexity led to higher SI (i.e., more specialization), even when the bottleneck analysis predicted generalist optimality. Classification accuracy for specialization remained high, but lower than in the smaller-scale setups (74.2%).
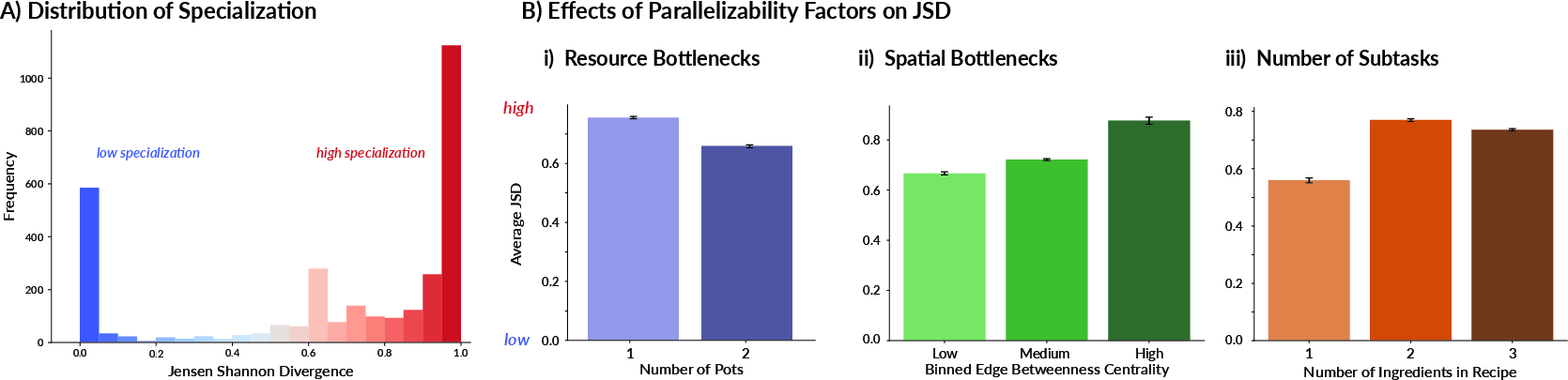
Figure 4: In the large-scale analysis, increasing concurrency (pots, reduced bottleneck severity) consistently lowers specialization, whereas more subtasks and complex layouts increase it.
State Space Size and Training Biases in MARL
Substantial state space size induces systematic deviation from parallelizability-based predictions. Despite bottlenecks permitting generalist solutions, agents in large or complex environments converged to locally optimal, specialist policies—commonly with lower rewards. Across multiple layouts, correlation between state space size and SI was r=0.383 (highly significant), and in controlled expansions, the size–SI relationship became even stronger (r=0.79, p=0.03 for one-onion recipe).
These results emphasize the role of exploration difficulty and coordination overhead, factors not captured in the analytic framework, as sources of bias toward specialization. Poor exploration and sample inefficiency make specialization an accessible local optimum.
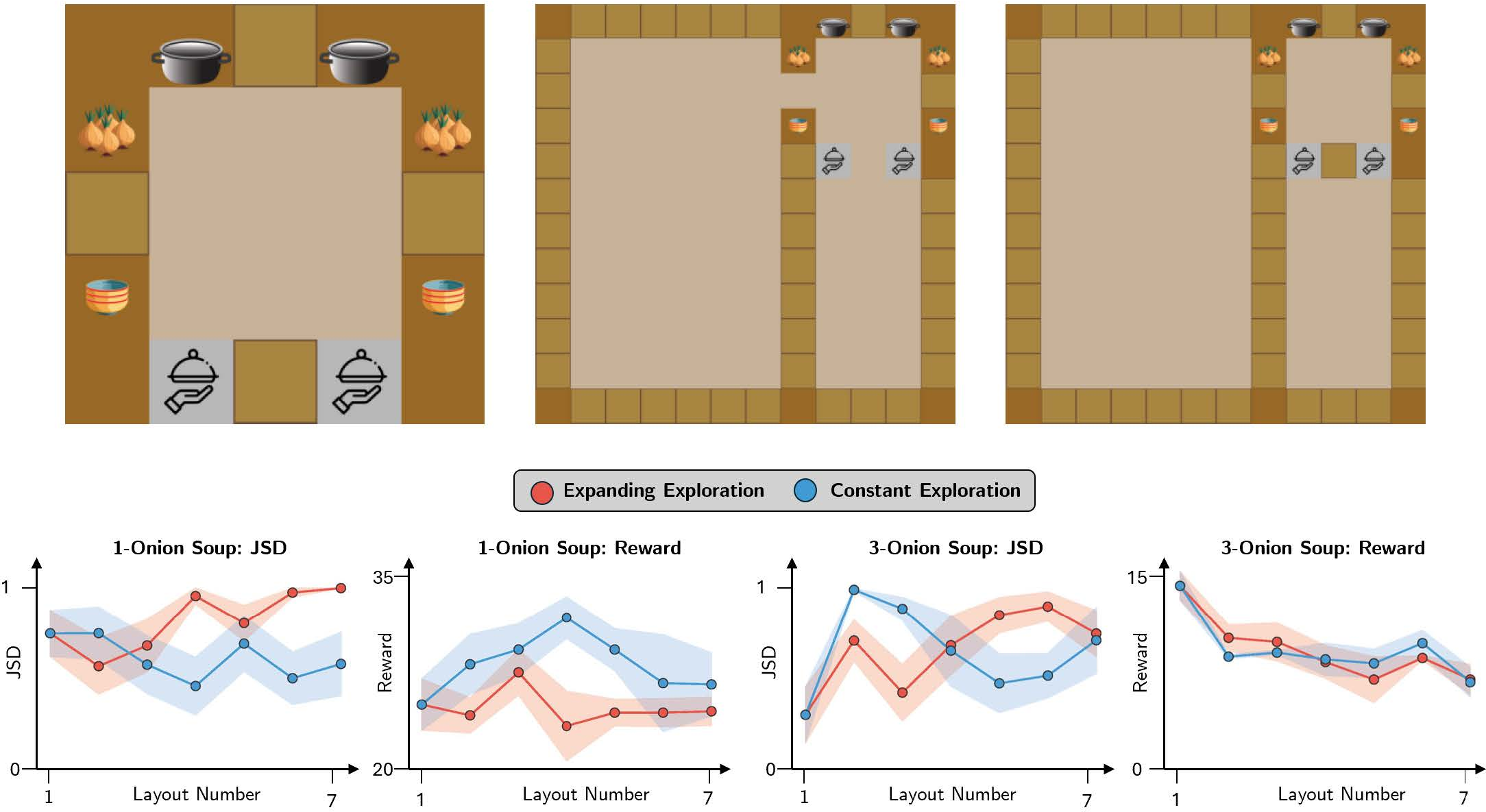
Figure 5: Increases in layout size, even with fixed task structure, drive increased specialization and concomitant reward drops, highlighting challenges outside bottleneck analysis.
Theoretical and Practical Implications
This work refines the understanding of specialization emergence in MARL. The analytic prediction directly connects environmental structure to optimal team behavior, providing a generic tool for environment or system design. The model’s domain-agnostic operationalizability allows diagnosis of when and why MARL algorithms converge to suboptimal specialization, aiding in principled algorithmic and environment design. Contradicting a key assumption, specialization is not always optimal; rather, high parallelizability mandates generalist policies for maximal throughput.
On MARL algorithm development, the results highlight persistent limitations: existing training approaches bias toward specialization in high-dimensional and sparse-reward environments, even when analytic bounds favor generalists. Reducing exploration cost and improving joint policy optimization remain open problems.
For broader AI systems, the framework provides a lens on the trade-offs between role-diversity, policy generalization, and task structure, with ramifications for efficient resource allocation, sample efficiency, and robustness.
Conclusion
Task parallelizability, as precisely quantified by concurrency-aware analytic bounds, robustly predicts the emergence and degree of specialization in cooperative MARL settings. Empirical results strongly support that specialization is driven by structural bottlenecks, rather than intrinsic policy diversity. Notably, training dynamics and state space complexity can induce substantial deviations from optimality, favoring specialization as a practical but sometimes suboptimal heuristic. These findings inform both the normative analysis of multi-agent efficiency and practical algorithm and environment design. The framework bridges distributed systems and MARL, providing actionable predictions for emergent coordination paradigms.