- The paper presents a dynamic programming-based scheduling approach that optimizes token allocations across multi-stage LLM requests to meet diverse SLOs.
- It demonstrates a 2.2x improvement in serving capacity per GPU compared to state-of-the-art systems through efficient batch scheduling and multi-replica handling.
- The study offers insights into resilient request routing and load balancing strategies, paving the way for scalable LLM serving under heterogeneous SLO constraints.
SLOs-Serve: Optimized Serving of Multi-SLO LLMs
Introduction
The paper "SLOs-Serve: Optimized Serving of Multi-SLO LLMs" (2504.08784) presents a novel system designed to efficiently serve LLM requests under application- and stage-specific service level objectives (SLOs). By leveraging multi-SLO dynamic programming-based algorithms, the system continuously optimizes token allocations, thus enhancing per-GPU serving capacity significantly compared to state-of-the-art systems.
Problem and Motivation
LLMs, such as those used in chatbots, coding assistants, and document summarizers, typically require multi-stage processing that includes prefill, decode, and, in some cases, reasoning stages. Each stage has specific SLO requirements that must be met to ensure optimal user experience. The challenge lies in resource sharing and aligned scheduling to support these diverse SLOs for different application demands.
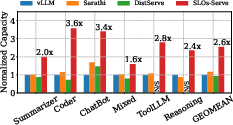
Figure 1: Serving Capacity comparison for LLM applications with heterogeneous SLOs, on a server with 4 A100s.
SLOs-Serve Architecture and Scheduling
SLOs-Serve introduces a scheduling algorithm tailored for dynamic and efficient request handling. It employs a multi-SLO dynamic programming-based method to explore the comprehensive design space of chunked prefill and speculative decoding. This allows for optimized token distribution and batch schedule formation, ensuring that SLOs across different stages are met without introducing bottlenecks.
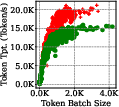
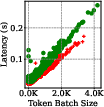
Figure 2: Throughput-latency trade-off for batching. Each data point represents a batch executed in SLOs-Serve's scheduling.
The system is designed to handle requests that exceed capacity gracefully, using a best-effort service tier to process requests that cannot meet stringent SLOs during high-load periods.
Multi-Replica Serving and Resilience
SLOs-Serve extends its functionality to multi-replica environments, employing a centralized scheduler for distributed request handling. This mechanism utilizes SLO-driven request routing, which dynamically assigns requests to available replicas based on real-time SLO attainment capabilities, ensuring optimal load distribution and resilience to bursty arrivals.
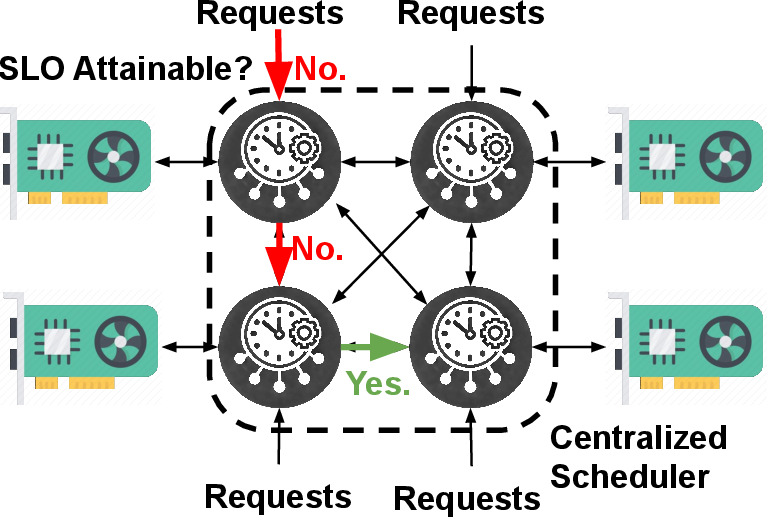
Figure 3: SLOs-Serve's Multi-Replica Serving.
Evaluation and Results
Empirical evaluation demonstrates that SLOs-Serve significantly improves serving capacity across multiple application scenarios, achieving an average serving capacity increase of 2.2x compared to Sarathi-Serve and vLLM systems. The system effectively handles variable request patterns and diverse SLO needs, showcasing robust scalability in multi-replica setups.
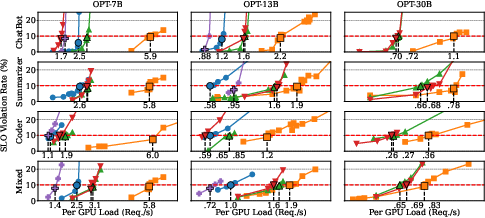
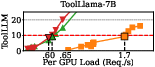
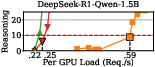
Figure 4: End-to-End evaluation of SLOs-Serve.
Additionally, detailed analysis and ablation studies confirm the contribution of each optimization in SLOs-Serve, underscoring its innovative scheduling approach and adaptive resource management strategies.
Implications and Future Work
The architecture and methodologies outlined in SLOs-Serve hold significant implications for the future of LLM serving systems. Its ability to meet complex multi-stage SLO requirements while optimizing token allocations represents a substantial step forward in serving system design. Future developments may explore enhancing admission control and routing strategies further and expanding scalability across larger clusters.
Conclusion
SLOs-Serve presents a comprehensive solution to the challenges of serving LLMs with multi-stage processing requirements under diverse SLO constraints. Through its dynamic programming-based approach and innovative scheduling mechanisms, the system offers substantial improvements in serving capacity and resilience, paving the way for more efficient and scalable LLM applications.