- The paper introduces TikTalkCoref, the first Chinese multimodal coreference resolution dataset tailored for Douyin dialogues.
- It presents a robust three-part pipeline integrating textual coreference, visual tracking, and cross-modal alignment through contrastive learning.
- Experiments demonstrate enhanced accuracy in entity linking and effective handling of singleton clusters in dynamic social media contexts.
The paper presents TikTalkCoref, the first Chinese multimodal coreference resolution dataset tailored for real-world social media dialogues, specifically from the Douyin platform. It addresses critical gaps in multimodal CR research for naturally occurring dialogues, providing valuable resources and a robust benchmark method for effective evaluation. The study includes detailed analysis on the necessity of multimedia integration in understanding dialogic interactions and introduces a sophisticated pipeline architecture for MCR tasks.
Introduction
Multimodal Coreference Resolution (MCR) expands the traditional coreference resolution domain by integrating visual information with textual context, enabling more comprehensive entity identification across modalities. The advent of short video platforms, such as Douyin, amplifies the need for MCR to improve content personalization and interaction understanding. TikTalkCoref significantly advances this field by offering a dataset with meticulously annotated coreference clusters, linking textual mentions to corresponding visual identifiers within video frames. Consequently, this enhances the fidelity of CR models to real-world social media dialogues.

Figure 1: An example of TikTalkCoref.
TikTalkCoref's annotations, demonstrated in Figure 1, underscore its focus on person entities within texts and visuals, establishing an innovative mapping between dialogues and video representations.
Previous MCR endeavors, primarily in English, centered on human-machine dialogue or media descriptions, lacking coverage for dynamic social interactions. Datasets like MPII-MD and VisPro illustrate multimodal CR by aligning textual narratives with images or videos, but fail to capture the nuanced interactions present in social dialogues. TikTalkCoref fills this void, presenting the first Chinese dataset to address this complexity in naturally occurring social media contexts.
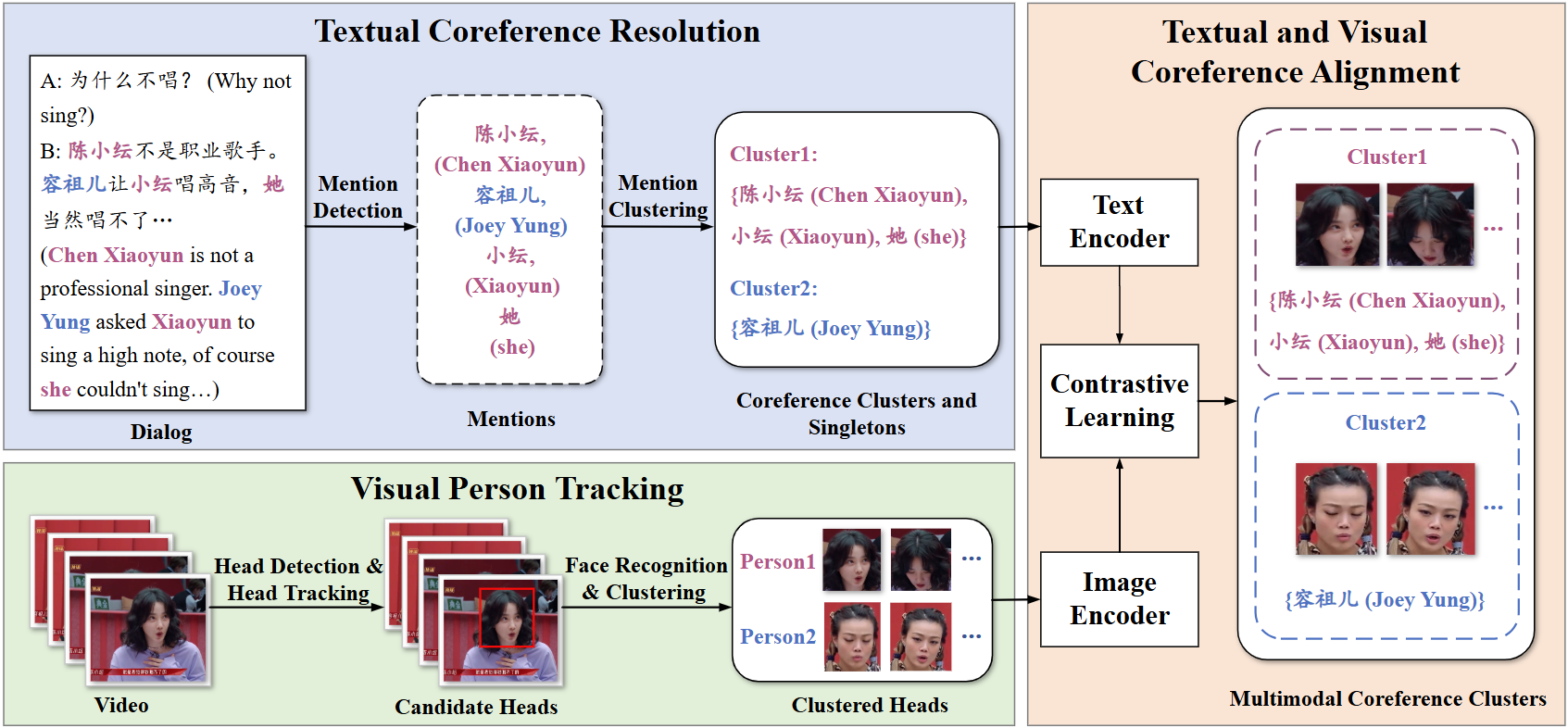
Figure 2: The overview of our model architecture.
Methodology
The proposed approach for MCR involves a three-part pipeline: textual coreference resolution, visual person tracking, and cross-modal alignment, as depicted in Figure 2.
Textual Coreference Resolution
The textual resolution framework utilizes a DeBERTa-based Maverick model to extract mentions and cluster them, employing a coarse-to-fine antecedent scoring approach. This is instrumental in handling the high variance in mention types and densities typical to social media dialogues.
Visual Person Tracking
Employing YOLOv5 and DeepSORT algorithms, the model achieves robust tracking of head regions across video frames. The integration of MTCNN and MobileFaceNet ensures accuracy in face recognition and clustering, adapting to the challenges posed by disjointed video segments in social media posts.
Textual and Visual Coreference Alignment
Using Chinese CLIP, the method achieves alignment across modalities via contrastive learning, enhancing retrieval accuracy of coreferential entities in text and visuals. This process aligns coreferential textual clusters with respective visual entities, crucial for establishing seamless multimodal relationships.
Experiments and Results
Experiments demonstrate significant improvements in coreference resolution accuracy using TikTalkCoref. Maverick outperforms existing models significantly, particularly in handling singleton clusters due to its specialized mention clustering technique. The bilingual coreference alignment system achieves high retrieval accuracy, benefiting extensively from domain-specific fine-tuning.
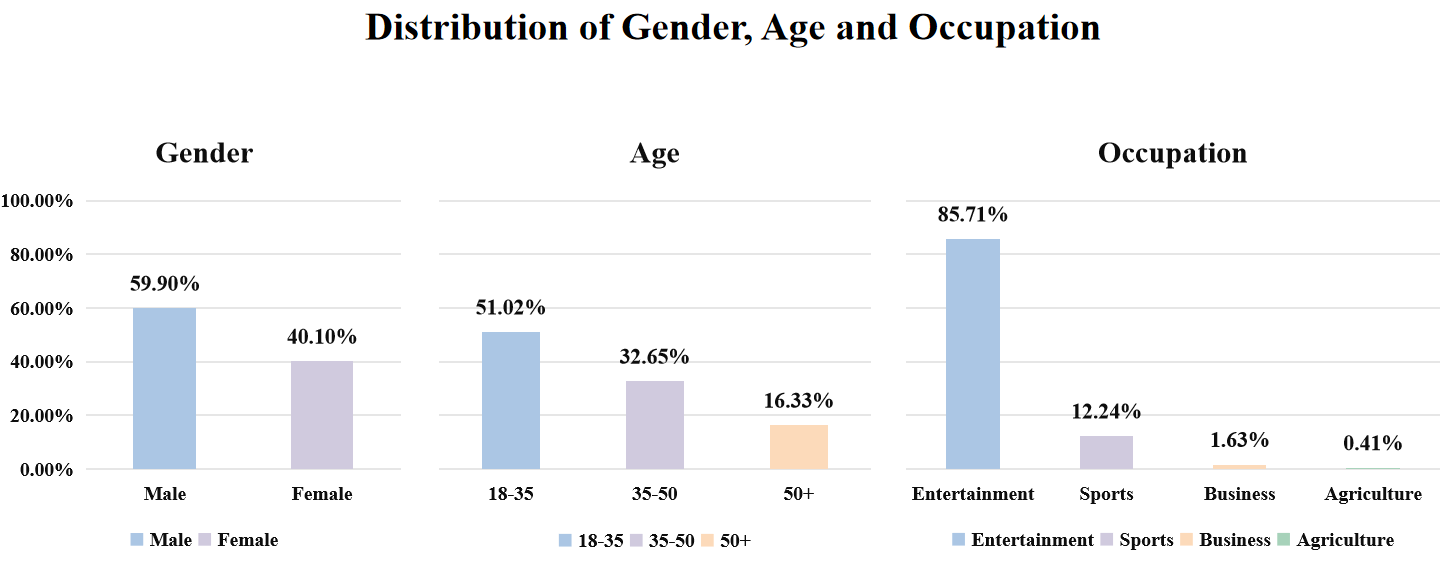
Figure 3: The distribution of gender, age and occupation of persons in the TikTalkCoref.
Empirical analysis reveals insights into gender, age, and occupation distributions, as shown in Figure 3, highlighting demographics predominant in social media contexts, thereby guiding future enhancements in model training paradigms.
Conclusion
TikTalkCoref establishes a crucial foundation for future research aimed at enhancing MCR in dialogic exchanges on social media. The dataset's release facilitates exploration of nuanced, multimodal interactions, advancing both theoretical and practical understanding of CR applications in real-world settings. Future work will explore scaling the dataset and employing semi-supervised methodologies for expanded applicability across diverse multimedia landscapes.
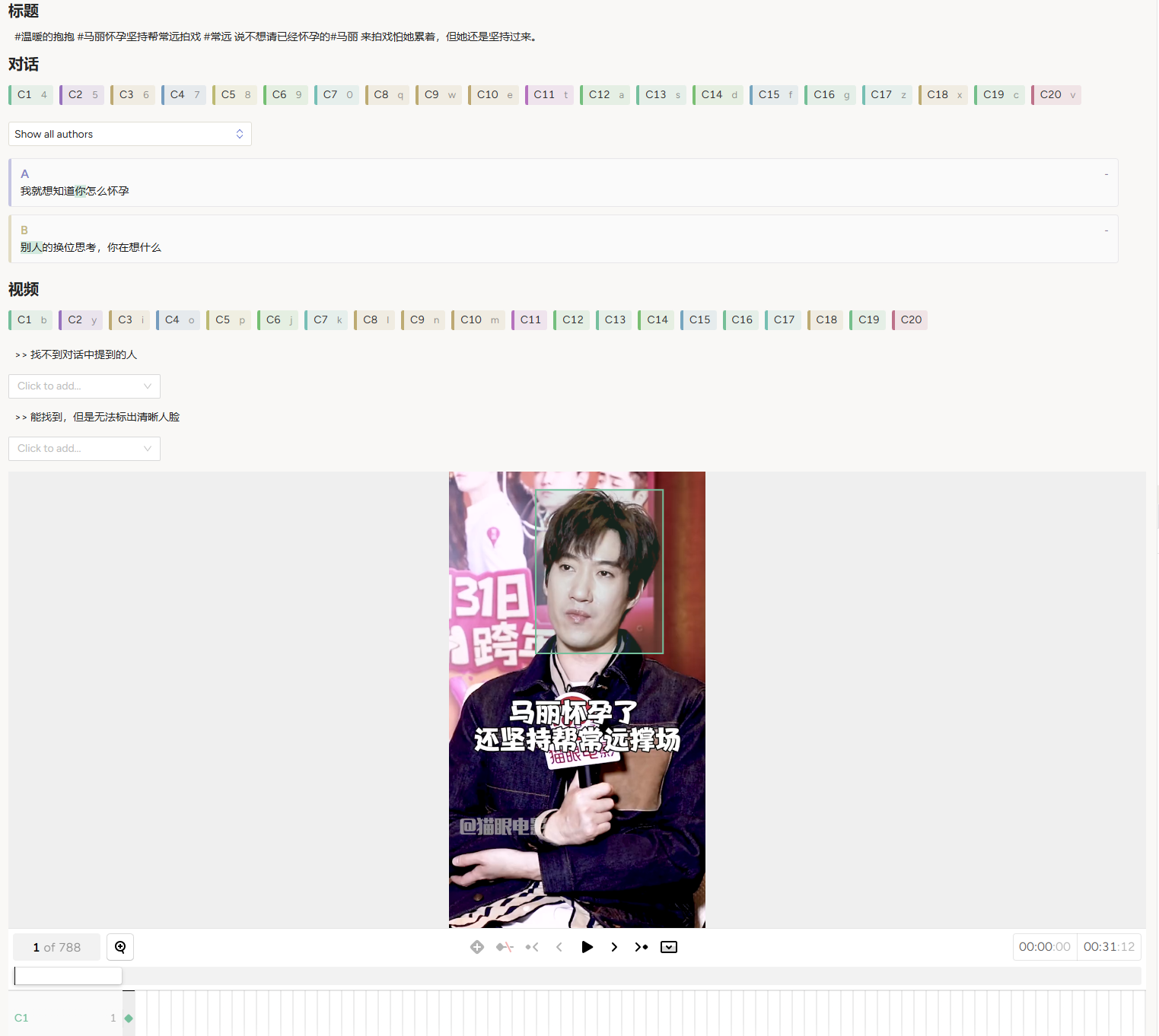
Figure 4: Annotation interface of our annotation tool.
TikTalkCoref's contributions pave the way for improved strategies in CR tasks, optimizing user interaction and personalization in digital platforms.