- The paper introduces a data-driven approach to disentangle static texture and dynamic motion in 3D CNN kernels through a two-stage optimization process.
- It employs pixel-domain optimization followed by decomposition into a static frame and deformation fields, using TV regularization and warping operations.
- Empirical results on architectures like I3D and C3D show that this method yields sharper, more interpretable spatiotemporal feature representations.
Disentangling Texture and Motion Preferences in 3D Convolutional Neural Networks
Introduction
The paper "Feature Visualization in 3D Convolutional Neural Networks" (2505.07387) introduces a method for visualizing and interpreting the internal feature preferences of 3D convolutional kernels, addressing the lack of clarity in the spatiotemporal features encoded by deep 3D architectures. While 2D feature visualization via activation maximization has become standard, the extension to 3D CNNs is nontrivial due to the simultaneous encoding of texture and motion. The presented approach systematically disentangles static (texture) and dynamic (motion) components in the optimal stimulus for a given 3D kernel, advancing the interpretability of video models and offering insights relevant to architectural design and biological vision analogs.
Methodology: Data-Driven Decomposition and Two-Stage Optimization
The proposed method begins with the generation of a synthetic video input by maximizing the activation of a chosen 3D kernel using a deep generative optimization. Crucially, it decomposes the resulting video into a static frame and a sequence of deformation fields, such that each frame is reconstructed by applying a learned spatiotemporal displacement to the static base.
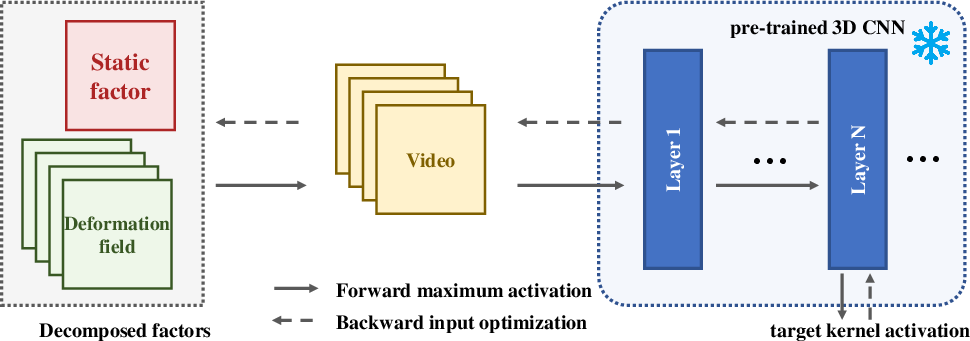
Figure 1: Overview of the visualization process, highlighting two-stage optimization and spatiotemporal decomposition.
A warping operation W(I,Dt) is employed, where I is a static image capturing spatial texture preferences and Dt is a pixel-wise deformation field at time t, analogous to non-parametric motion compensation. The frame Vt is reconstructed as I warped by Dt. This decomposition is optimized in two distinct phases:
- Pixel-Domain Optimization: The input video V is optimized directly to maximize kernel activation.
- Decomposition-Domain Optimization: The previously obtained V is then factorized into I and Dt by minimizing a composite loss. This encompasses reconstruction error, total variation (TV) regularization on both I and Dt for spatial coherence, and an alignment term for semantic consistency between I and the first frame.

Figure 2: Single-frame reconstruction via decomposition. Left: static factor; middle: learned deformation field; right: synthesized frame.
This two-stage approach mitigates the convergence challenges and representational ambiguities encountered in naïve end-to-end factorization, as substantiated in the empirical ablation.
Empirical Validation and Ablation Studies
Comprehensive experiments are performed on canonical 3D CNN architectures including I3D, C3D, and 3D VQ-VAE pretrained on large-scale action recognition datasets (Kinetics 400, UCF-101, Sports-1M).
A direct extension of 2D Fourier-domain activation maximization to 3D yields suboptimal, artifact-prone results due to the curse of dimensionality and spectrum scaling issues. Pixel-domain optimization circumvents these pitfalls, producing interpretable stimuli and facilitating effective decomposition.
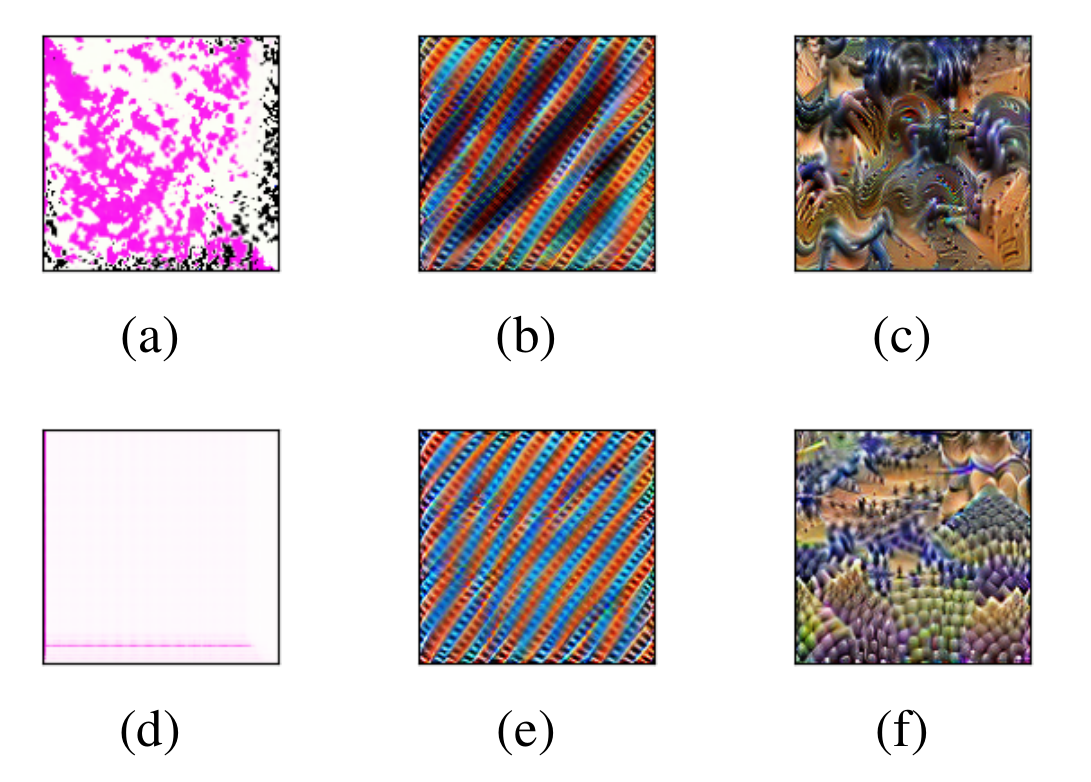
Figure 3: Comparisons of visualizations optimized in (a-c) Fourier and (d-f) pixel domains for layers at varying depths in I3D.
The ablation of individual loss components demonstrates that both TV regularization terms and the static-factor similarity loss are essential for suppressing noise and ensuring semantic integrity in the decomposition. The absence of these terms yields spurious deformation fields and incoherent static factors.

Figure 4: Effect of different loss function configurations on decomposition outputs and reconstructed video.
Further, substituting the two-stage procedure with a single-stage approach in which I and Dt are jointly optimized leads to less informative and less stable outputs; the two-stage approach yields both sharper texture factors and more interpretable motion representations.

Figure 5: Comparison of decomposed outputs from two-stage (top) and single-stage (bottom) optimization strategies.
Visualization and Interpretation of 3D Kernel Preferences
Visualization of representative kernels uncovers a diversity of spatiotemporal feature selectivities. For shallow layers, the preferred inputs often consist of static textures undergoing simple jitter or displacement. In deeper layers, preferences shift towards spatially complex, patch-wise textured patterns with highly nonuniform, temporally modulated motion fields—revealing the hierarchical abstraction and increasing nonlinearity of dynamic representations.

Figure 6: Visualization of optimal input videos and their decomposed static/deformation components for diverse kernels in I3D, C3D, and 3D VQ-VAE.
The qualitative phenomenology mirrors observations from neurophysiology: some 3D kernels display feature selectivity resembling motion energy detectors or direction-selective cells, with intricate, non-global motion preferences reminiscent of visual cortical circuitry.
Implications and Future Directions
This method provides a principled platform for investigating the internal computations of 3D CNNs, informing both model interpretability and the study of emergent visual representations, especially in the context of spatiotemporal modeling. The ability to disentangle texture and motion factors may foster architectures with separate dynamic and static pathways, or inspire regularization schemes grounded in biological vision constraints.
Practically, these insights into kernel-specific feature preferences have potential for network debugging, targeted pruning, and explicit design of domain-specific architectures (e.g., action recognition or video synthesis). On the theoretical side, the revealed complexity gradient across network depth invites further analysis connecting receptive field structure in artificial and biological neural systems.
Conclusion
The paper advances the interpretability of 3D CNNs by introducing a data-driven, two-stage decomposition method that isolates static and motion feature preferences of convolutional kernels. Extensive ablations validate the necessity of each component, and qualitative visualizations elucidate the spatiotemporal hierarchical representations learned in standard models. This analytic toolkit fills a crucial gap in the analysis of video recognition systems and opens avenues for biologically inspired network development and spatiotemporal representation learning.