- The paper presents β-GRPO, an RL-based method that improves agentic search decisions by integrating confidence thresholds to mitigate over- and under-searching.
- Experiments across multiple QA datasets show a 4% improvement in exact match scores and reduced redundant search actions.
- The method enhances LLM self-awareness of knowledge limits, paving the way for more efficient multi-step reasoning in complex retrieval tasks.
Search Wisely: Mitigating Sub-optimal Agentic Searches By Reducing Uncertainty
Introduction
The paper "Search Wisely: Mitigating Sub-optimal Agentic Searches By Reducing Uncertainty" addresses inefficiencies in Agentic Retrieval-Augmented Generation (RAG) systems, specifically over-searching and under-searching behaviors. These issues hinder the efficiency and reliability of LLMs performing complex reasoning tasks. The authors formally define these behaviors and investigate their prevalence across various QA datasets, demonstrating a correlation with the models’ uncertainty regarding their knowledge boundaries. The paper introduces β-GRPO, an RL-based approach to enhance search decision-making by incorporating confidence thresholds.
Identifying Sub-optimal Search Behaviors
The paper identifies over-search and under-search as critical challenges in enhancing RAG systems. The authors conduct experiments across four QA datasets using models like R1-Searcher and Search-R1 to quantify the extent of these behaviors.
For over-search, a significant portion of search actions are unnecessary, relying on information the model already knows. Figure 1 illustrates that models often retrieve redundant information, evidenced by Search-R1 avoiding searches in 27.7% of cases.
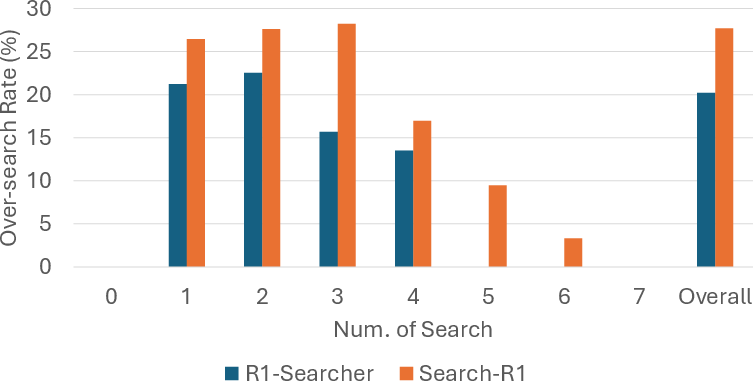
Figure 1: Percentage for all search steps that can be answered without performing searches of R1-Searcher and Search-R1 on 4 datasets combined, with respect to the number of searches of each test sample.
Conversely, under-search is reflected in incorrect reasoning when models fail to retrieve needed information. Both models show high error rates in non-search steps, indicating failures in acquiring critical external knowledge.
Approach: β-GRPO
To address these inefficiencies, the paper presents β-GRPO, an RL-based training method. This method uses the model’s confidence in its search queries to guide training, rewarding more certain search decisions. β-GRPO modifies GRPO by incorporating a confidence threshold for search call rewards, improving the model's ability to discern between internal knowledge and necessary external information.
Implementation Details:
- Confidence Measurement: The minimum probability of tokens in search queries is used to infer the model's certainty.
- Reward Structure: Rewards are based on both correct answers and the confidence level of search calls, encouraging high-certainty generation paths.
- Training Setup: β-GRPO is implemented within a reinforcement learning framework, leveraging dynamic search queries to optimize performance across complex QA tasks.
Experiments and Results
Empirical results from seven QA benchmarks highlight the effectiveness of β-GRPO over existing baselines. It improves exact match scores by 4%, and significantly reduces instances of both over-search and under-search.
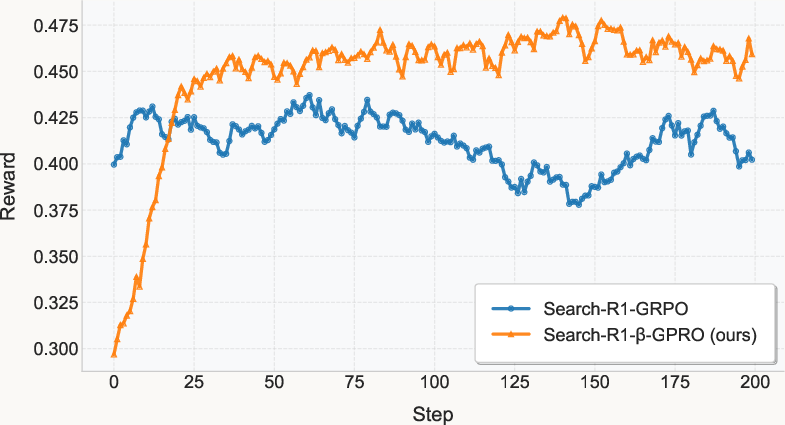
Figure 2: Training Rewards for Search-R1-GRPO and Search-R1-beta-GRPO.
Experimentation shows that candidate responses generated with greater certainty achieve higher accuracy, underscoring the value of improving knowledge boundary awareness.
Implications and Future Work
The research implies significant improvements in the efficiency and reliability of agentic RAG systems. By refining the model’s self-awareness of its knowledge boundaries, β-GRPO could pave the way for more sophisticated multi-step reasoning capabilities in AI models. Future work could explore extensions of this method to larger models and more open-ended tasks, such as deep research contexts, to further mitigate sub-optimal searching behaviors.
Conclusion
The introduction of β-GRPO offers a promising strategy for optimizing agentic search behaviors in RAG systems by reducing uncertainty. This approach not only enhances model performance in QA tasks but also opens avenues for more efficient multi-step reasoning capabilities, improving the practical applicability of LLMs in complex information retrieval scenarios.