- The paper establishes that neural RL agents using a two-layer NN policy yield attainable state sets constrained to a low-dimensional manifold bounded by the linear function of the action space.
- It leverages a linearized policy model under the NTK regime to theoretically predict and empirically confirm the reduced intrinsic dimensionality in continuous control environments.
- Empirical results indicate that incorporating sparse representations in RL architectures enhances sample efficiency and performance in high-dimensional control tasks.
Geometry and Manifold Structure in Neural Reinforcement Learning with Continuous States and Actions
Introduction and Motivation
This work addresses a fundamental gap in the theoretical understanding of reinforcement learning (RL) in continuous state and action spaces. While empirical advances have enabled RL agents to solve high-dimensional control tasks, most theoretical analyses remain restricted to finite or discrete domains. The paper develops a geometric framework to analyze the set of states attainable by neural network (NN) policies trained via policy gradients in continuous, deterministic environments. The central claim is that, under certain conditions, the set of attainable states forms a low-dimensional manifold whose dimension is upper bounded by a linear function of the action space dimension, independent of the ambient state space dimension. This result is both theoretically novel and empirically validated, with implications for the design and analysis of RL algorithms in high-dimensional domains.
Theoretical Framework
The analysis is grounded in continuous-time Markov decision processes (MDPs) with deterministic transitions. The state evolution is governed by control-affine dynamics: s˙t=g(s)+∑i=1dahi(s)ai,
where g and hi are smooth functions, ds is the state dimension, and da is the action dimension. The policy is parameterized by a two-layer, wide neural network with GeLU activation, and the training is performed via semi-gradient policy updates.
A key technical device is the use of a linearized approximation of the NN policy in the infinite-width limit, following the neural tangent kernel (NTK) regime. The policy is approximated as: flin(s;W)=f(s;W0)+∇θf(s;θ)∣θ=W0(W−W0),
where W0 is the random initialization. This linearization enables tractable analysis of the policy's effect on the state space.
The main theoretical result is that, for small time intervals and under mild regularity assumptions, the set of states attainable by such policies is concentrated around a manifold of dimension at most 2da+1, regardless of the ambient state dimension ds. The proof leverages Lie series expansions of the system's flow, stochastic process convergence in the infinite-width limit, and concentration of measure arguments.
Empirical Validation
Manifold Dimensionality of Attainable States
The theoretical upper bound on the manifold dimension is empirically validated in several MuJoCo continuous control environments. The intrinsic dimension of the set of states visited by trained agents is estimated using the method of Facco et al. (2017), which is robust to non-uniform density and curvature.
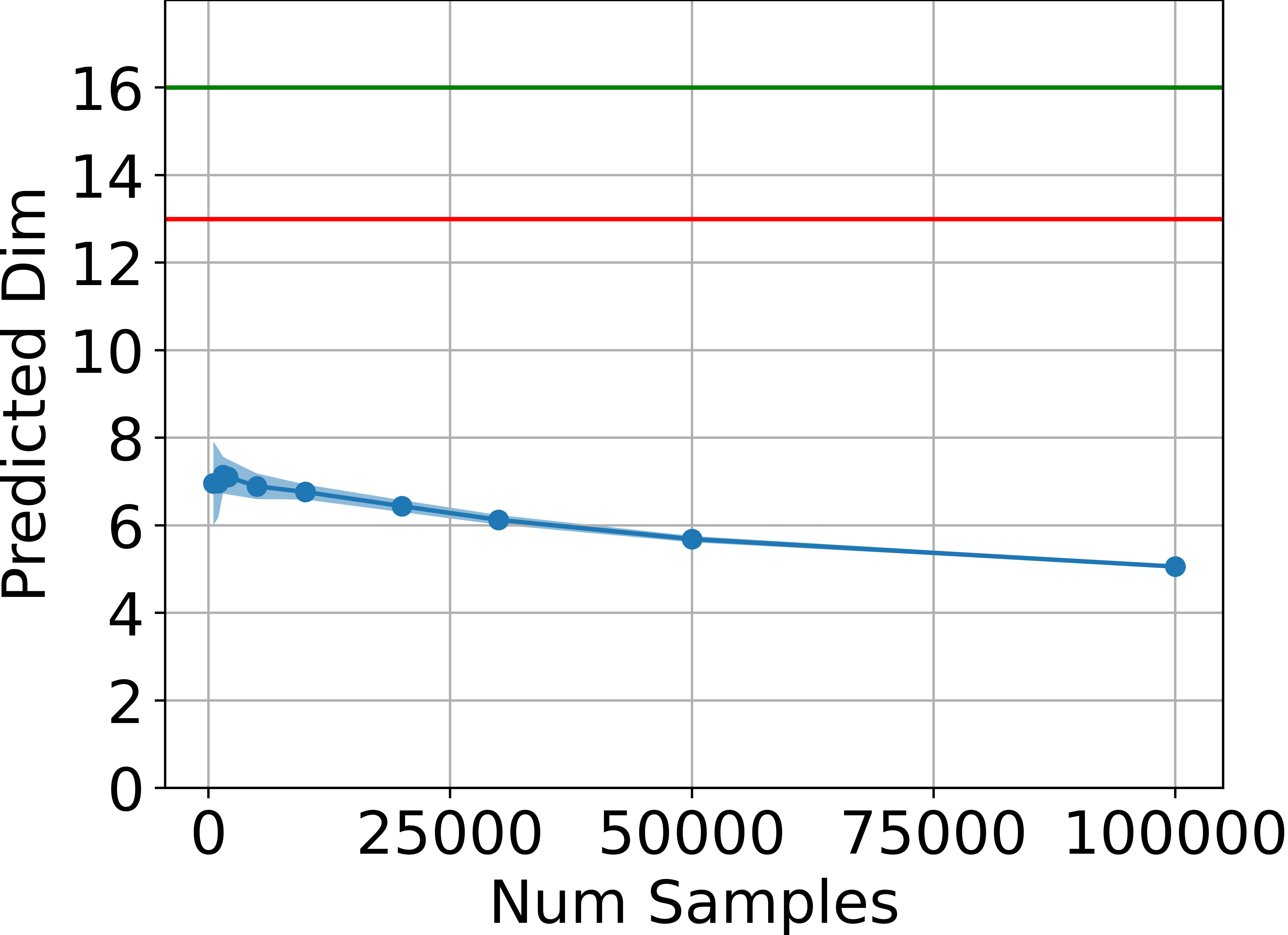
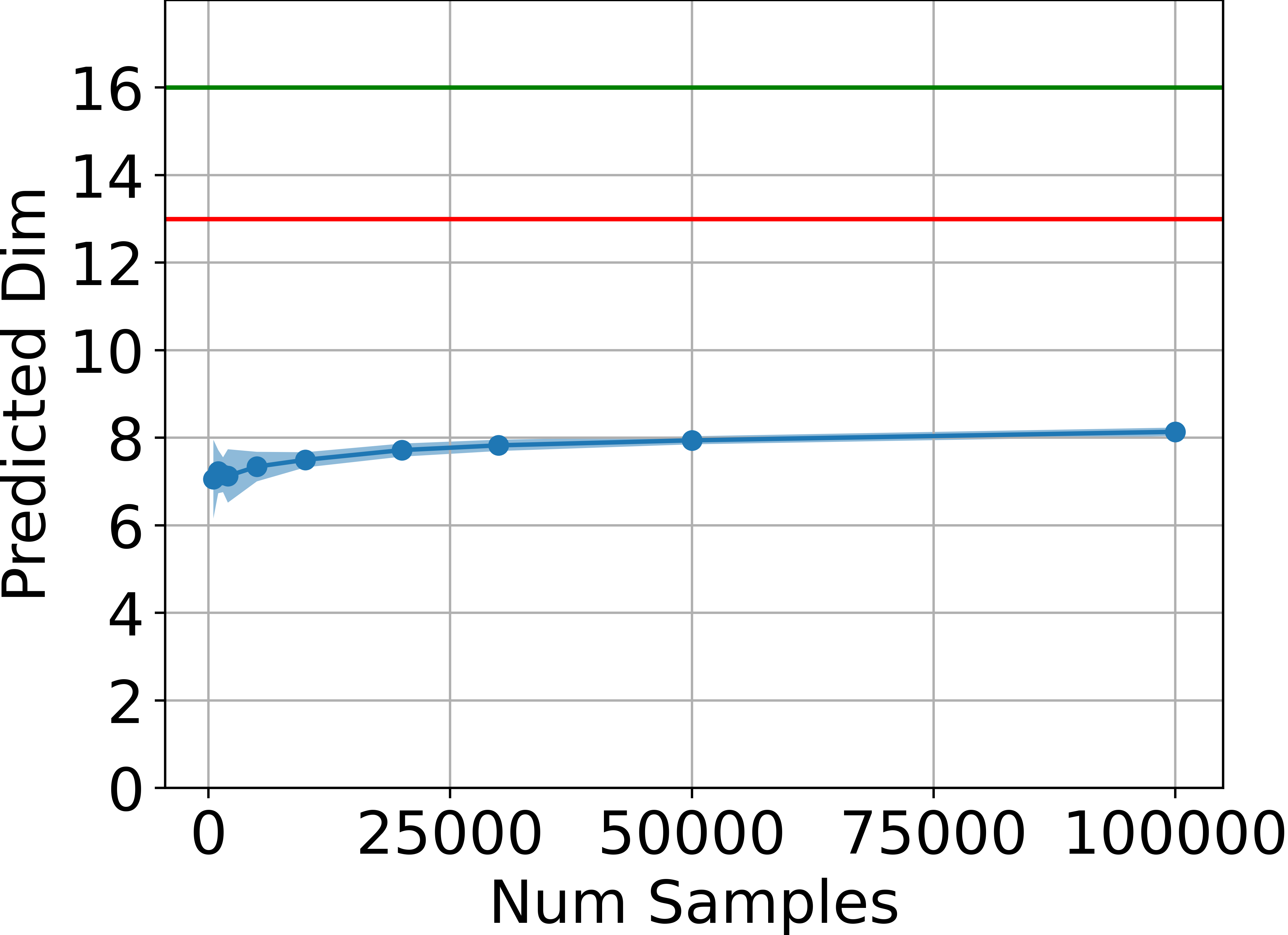
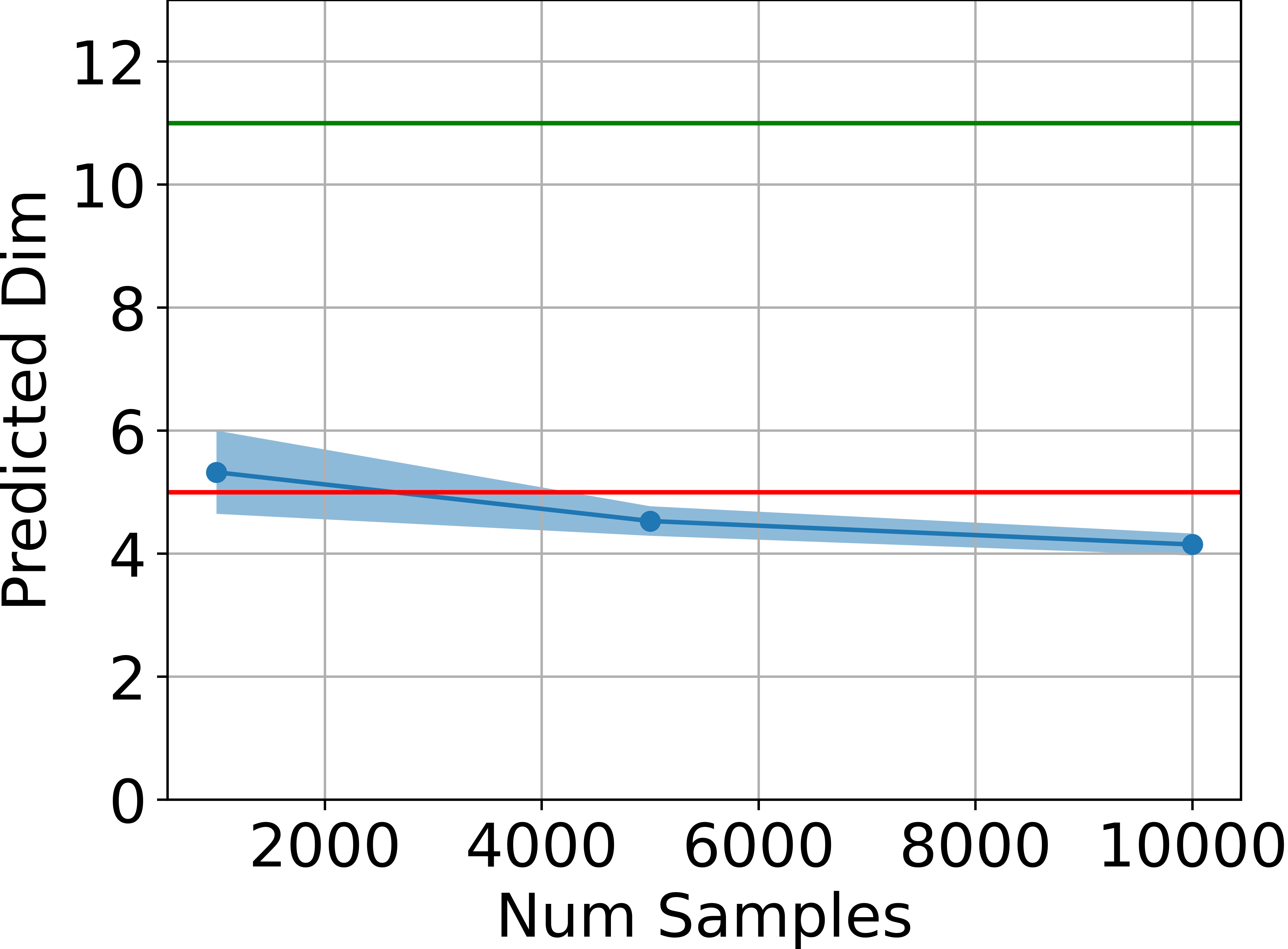
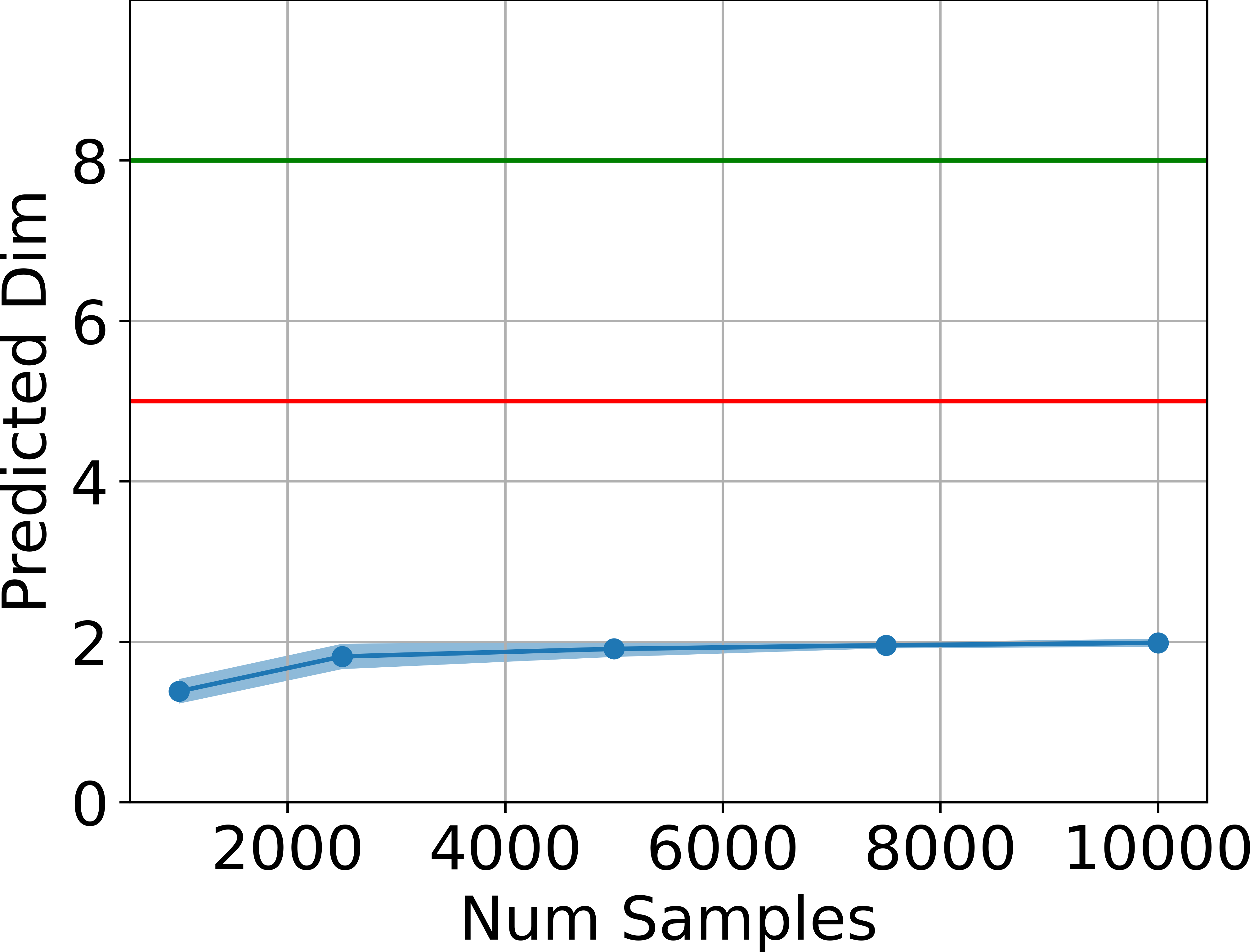
Figure 1: Estimated dimensionality of the attainable states, in blue, is far below ds (green line) and also below 2da+1 (red line) for four tasks, estimated using the method by Facco et al.
Across all tested environments, the estimated intrinsic dimension is consistently below the theoretical upper bound, and significantly lower than the ambient state dimension. This provides strong empirical support for the main claim.
Validity of the Linearized Policy Model
The paper also examines the fidelity of the linearized policy model as an approximation to canonical two-layer NNs. By comparing the returns achieved by DDPG agents using canonical versus linearized policies at varying network widths, it is shown that the difference in returns vanishes as the width increases.
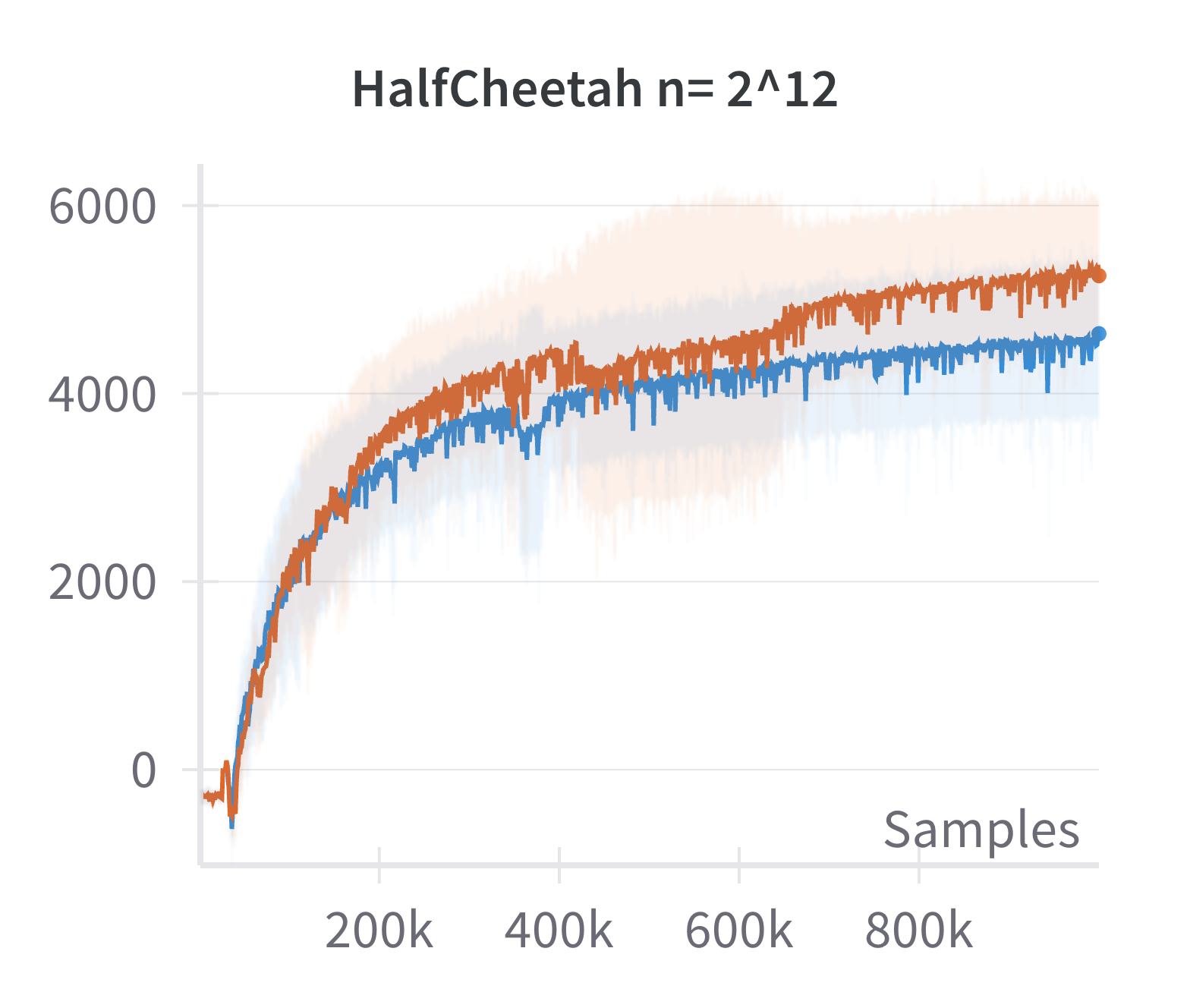
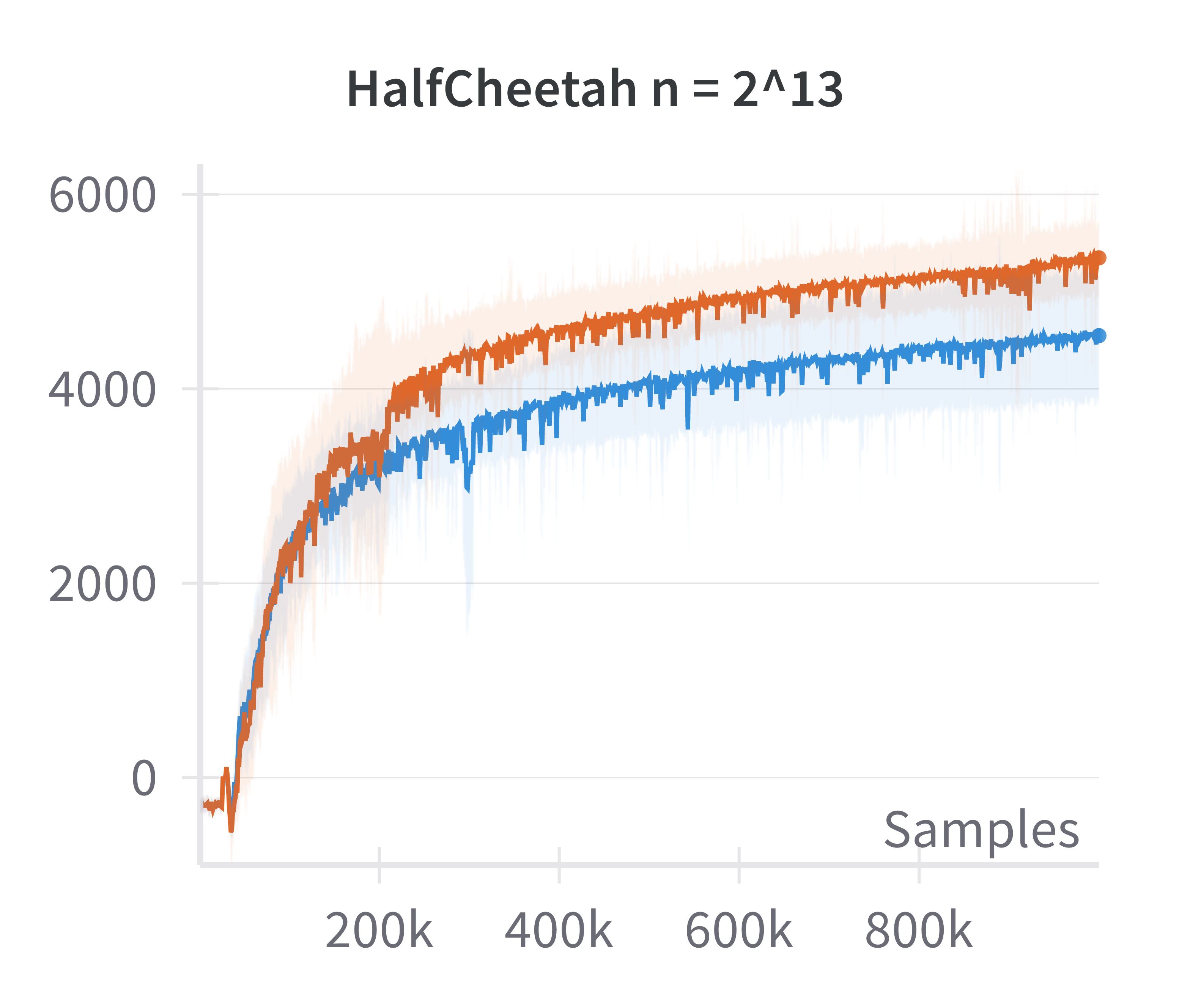
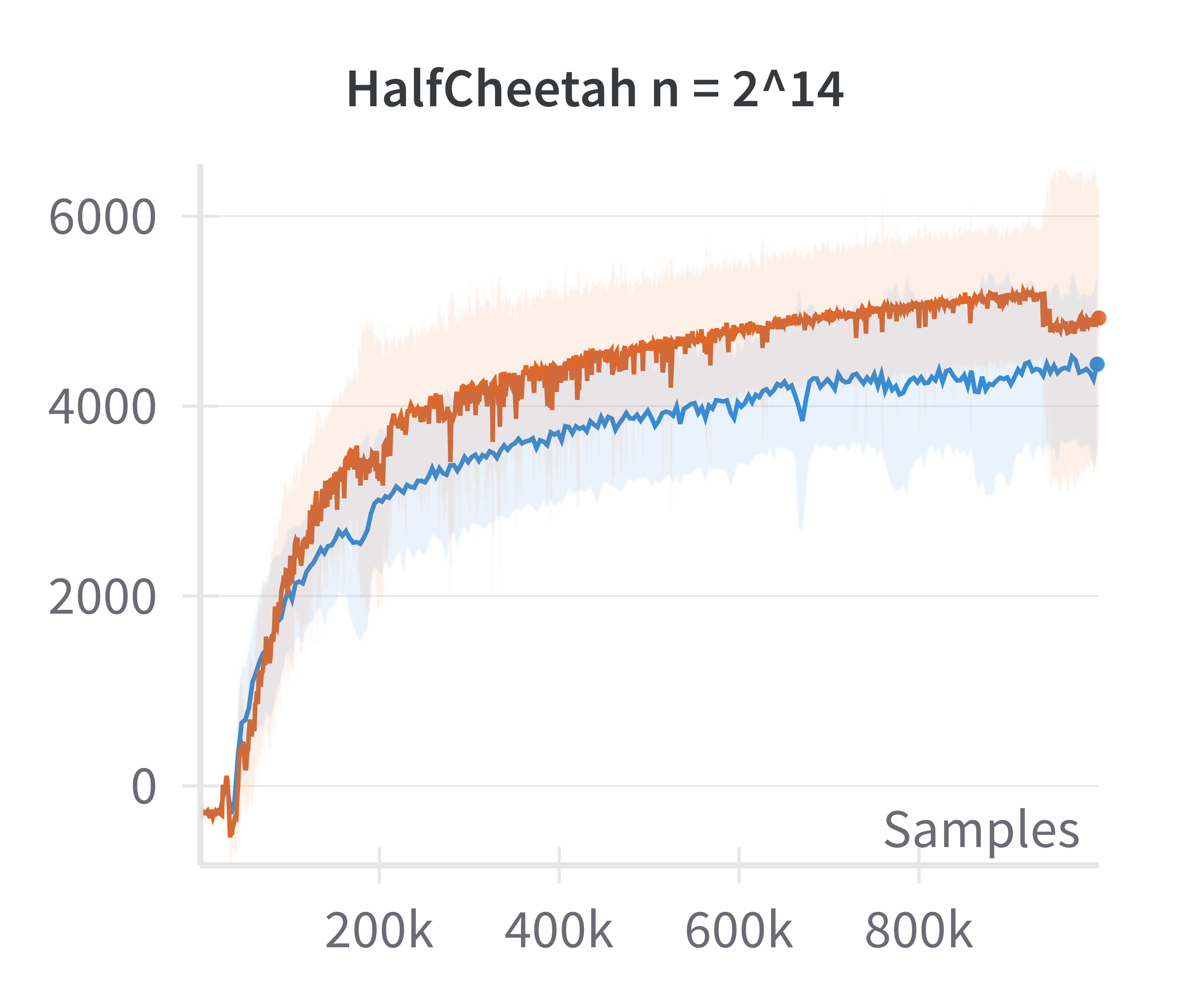
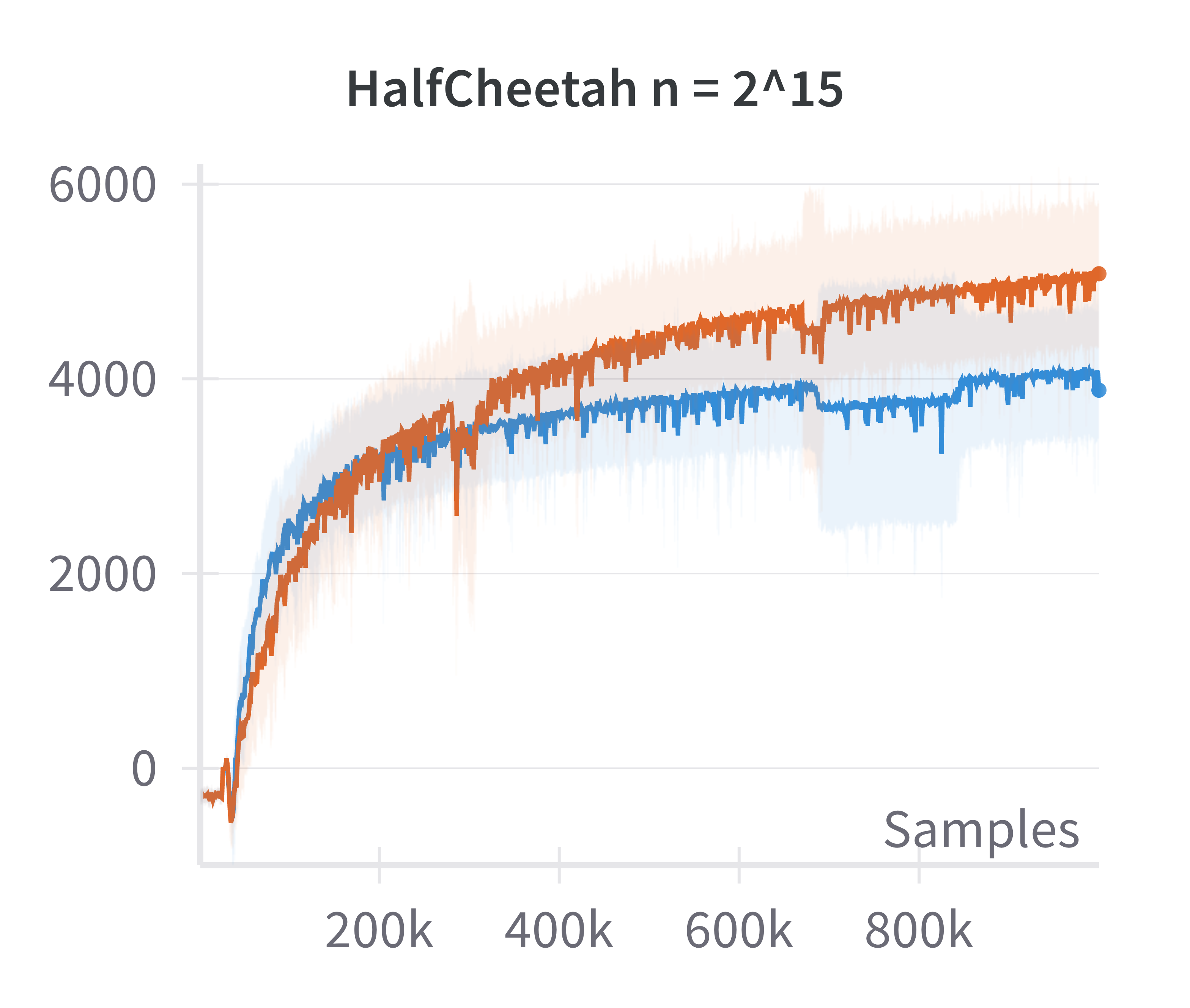
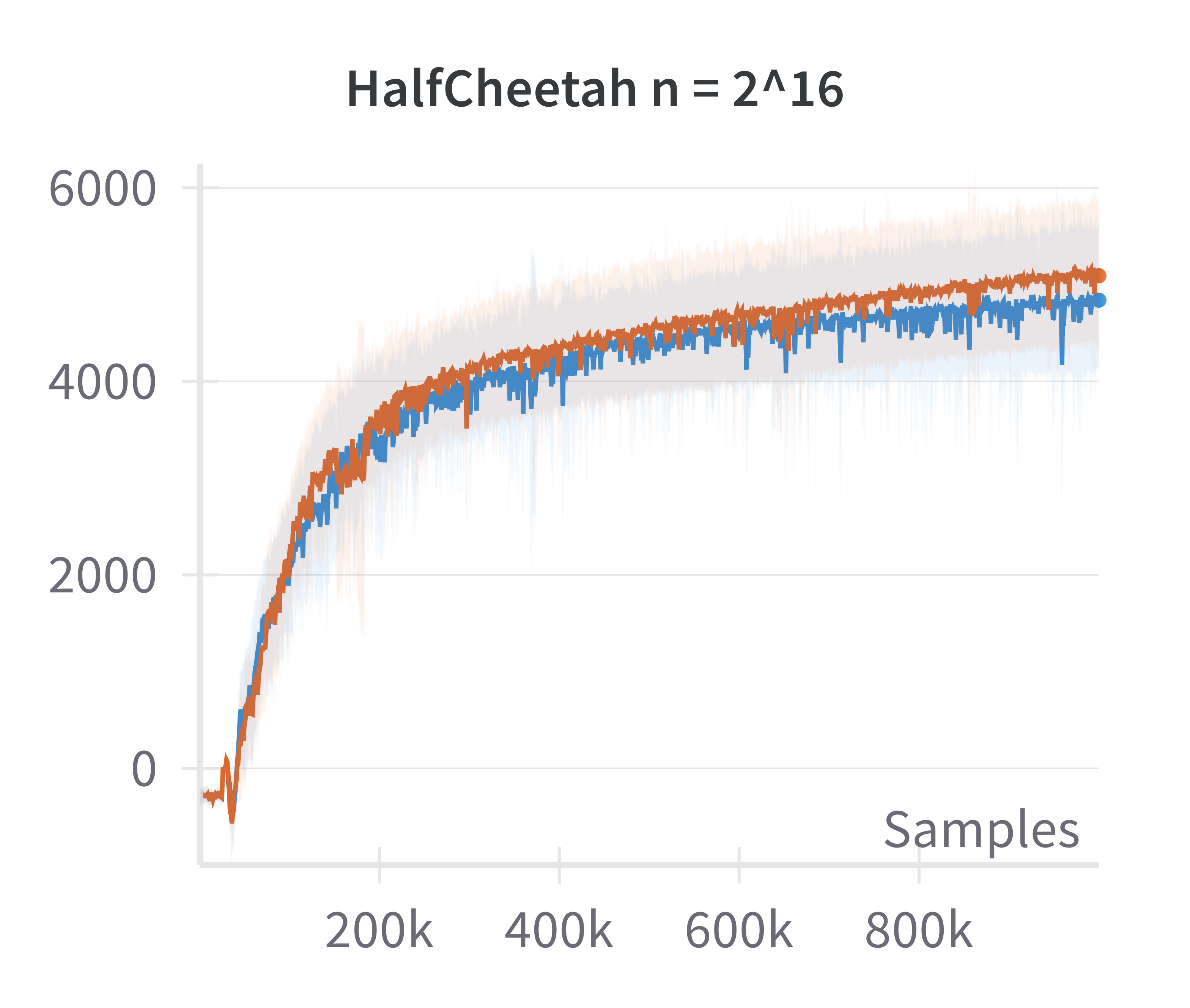
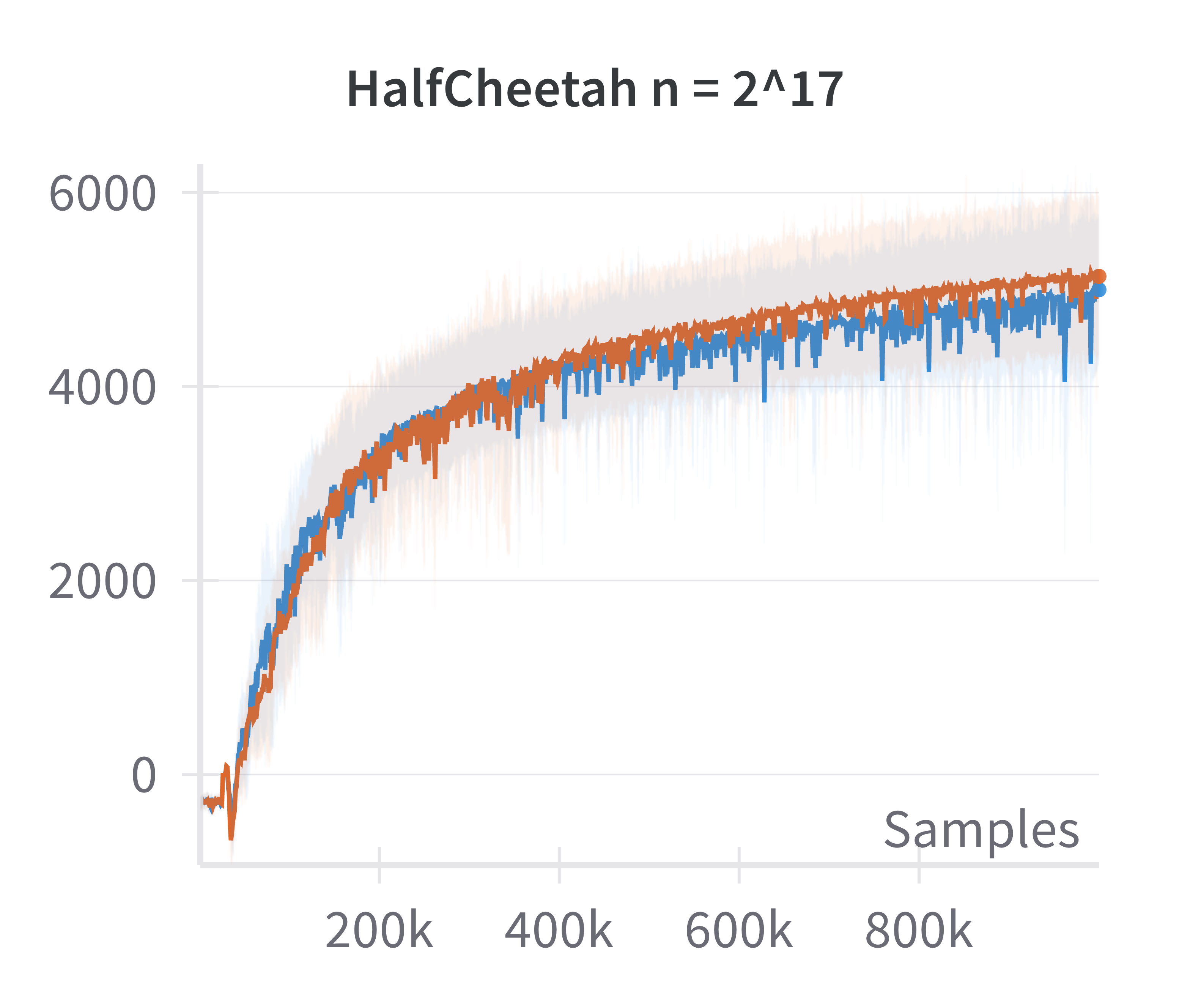
Figure 2: The canonical policy (in red) tracks the returns for linearised policy (in blue) at higher widths (log2n>15).
This justifies the use of the linearized model for theoretical analysis in the overparameterized regime.
Architectural Comparisons
The performance of single hidden layer GeLU networks is compared to standard multi-layer ReLU architectures in DDPG across several environments.
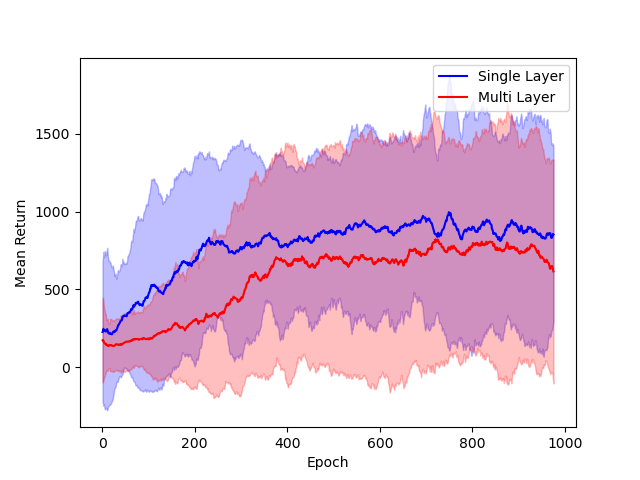
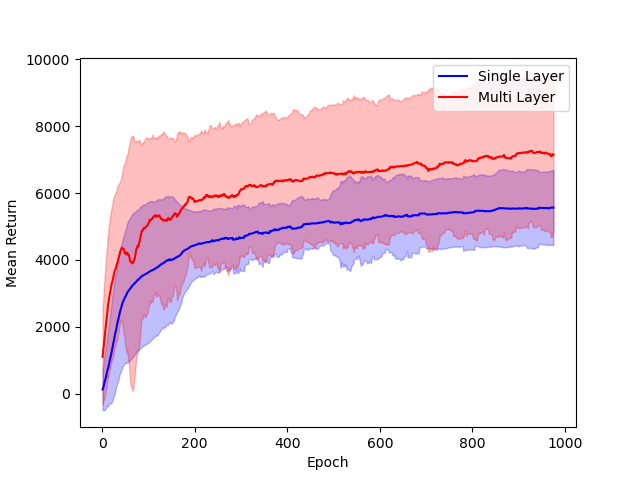
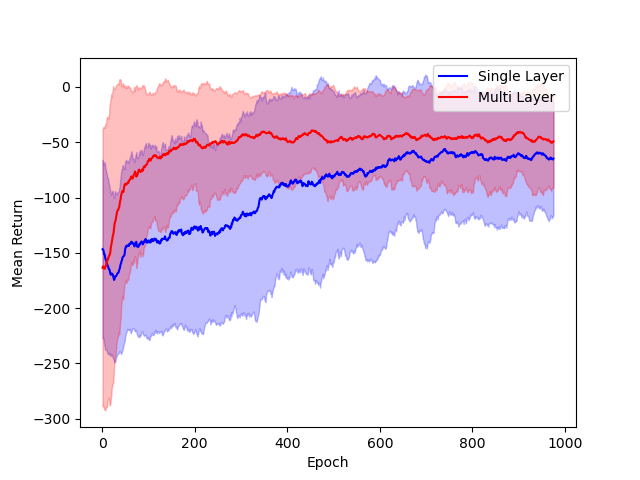
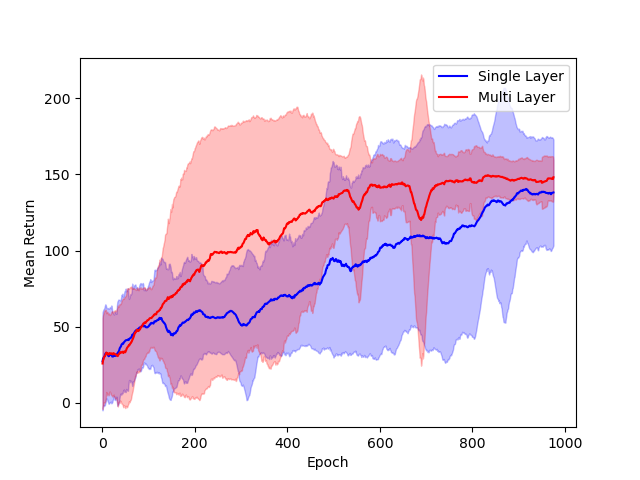
Figure 3: Comparison of single hidden layer with GeLU activation (blue) and multiple hidden layer with ReLU activation (red) architectures for DNNs.
The results indicate that the simplified architecture used for theoretical tractability does not significantly degrade empirical performance.
Building on the manifold hypothesis, the paper explores the practical benefits of explicitly encouraging sparse, low-dimensional representations in policy and value networks. By replacing a fully connected layer with a sparsification layer (as in the CRATE framework), the authors demonstrate improved performance in high-dimensional control tasks using the Soft Actor-Critic (SAC) algorithm.
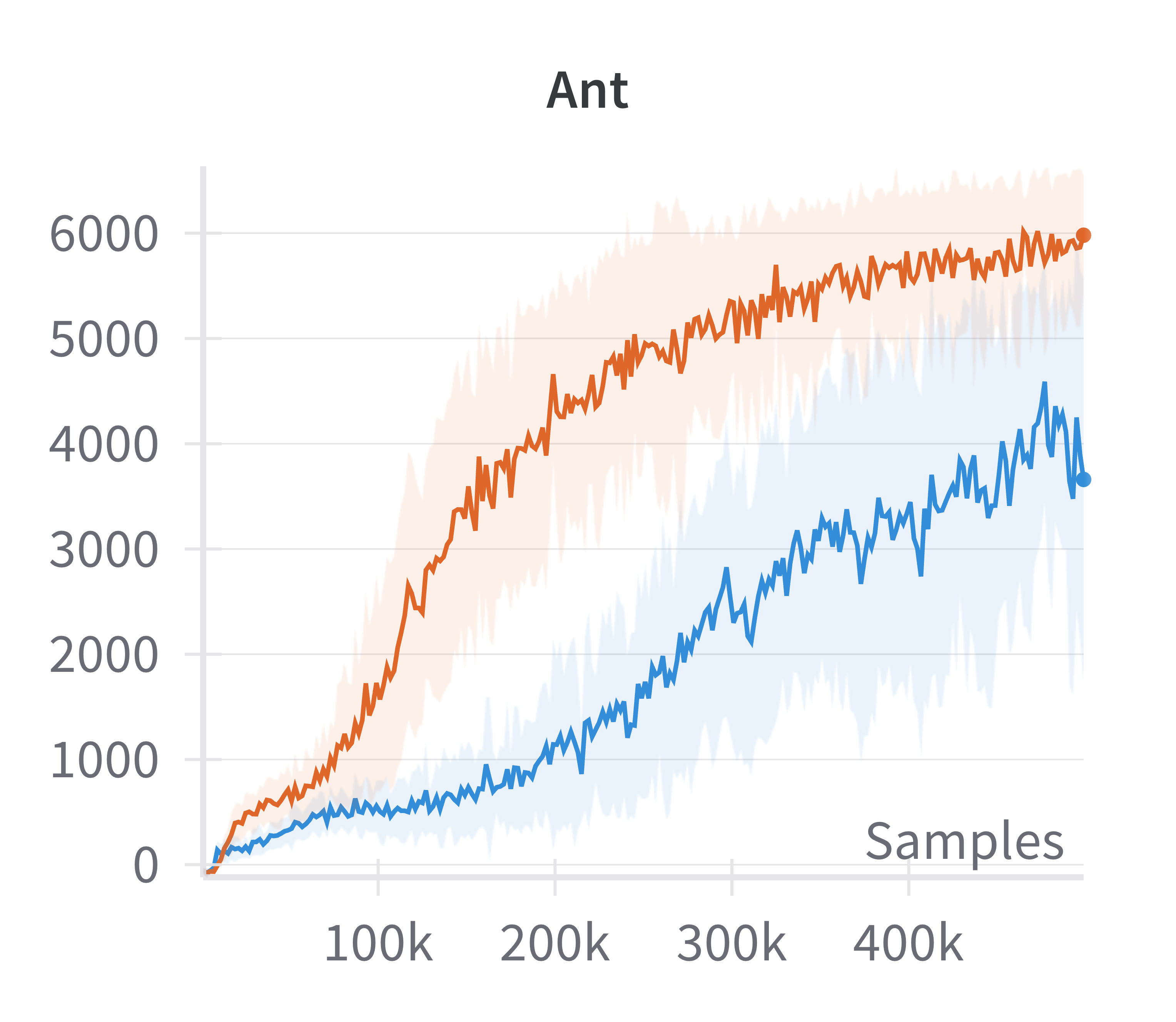
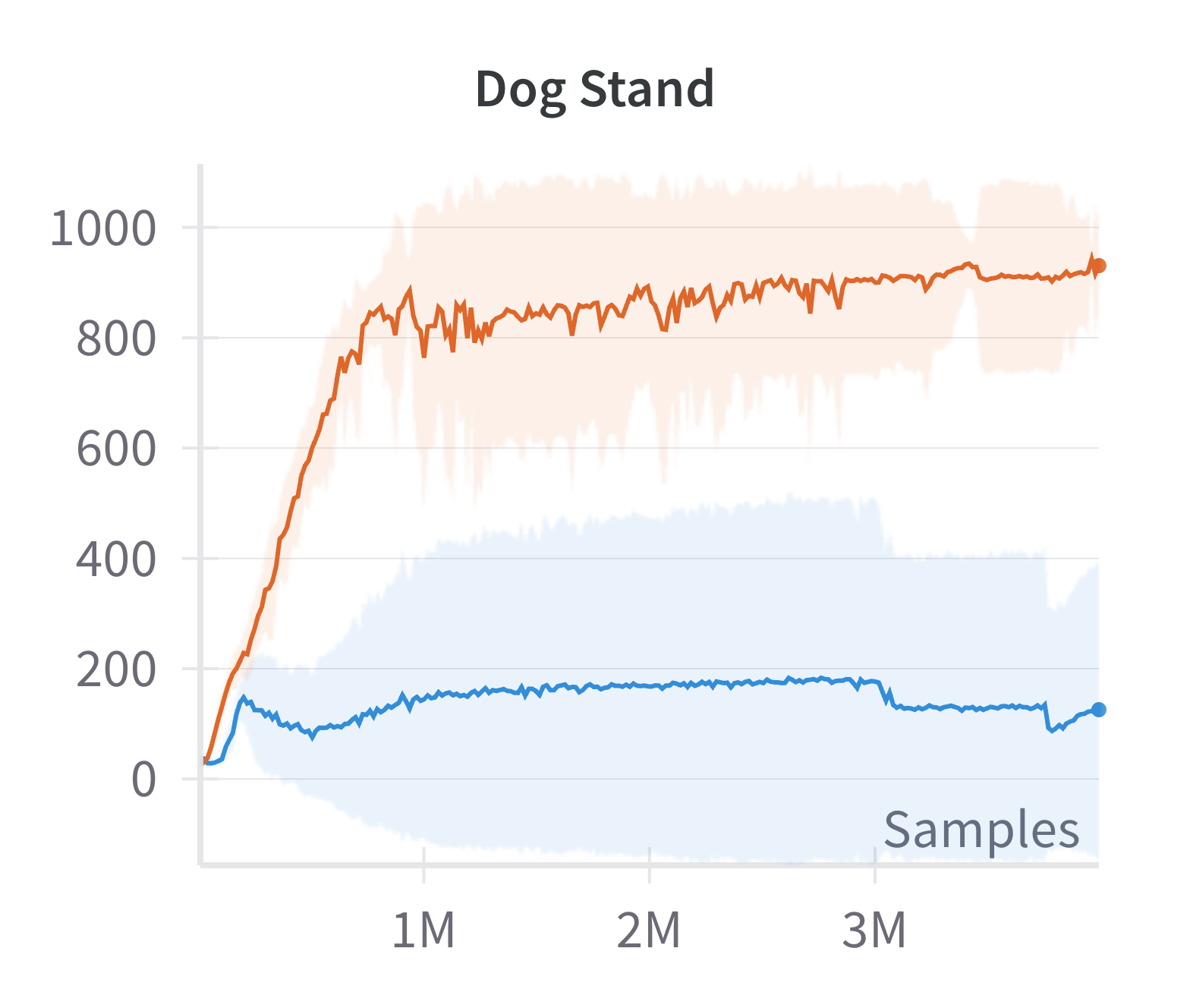
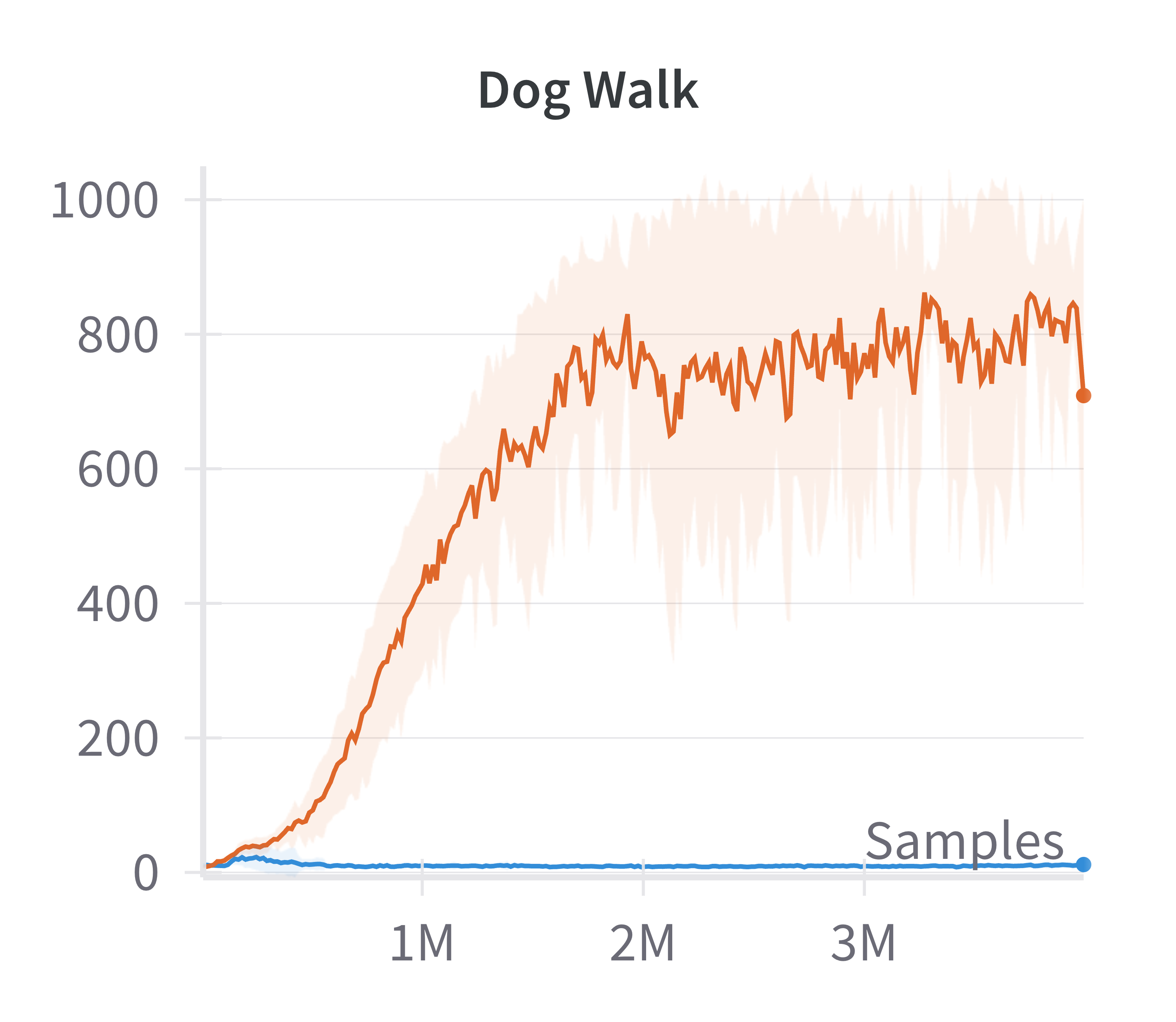
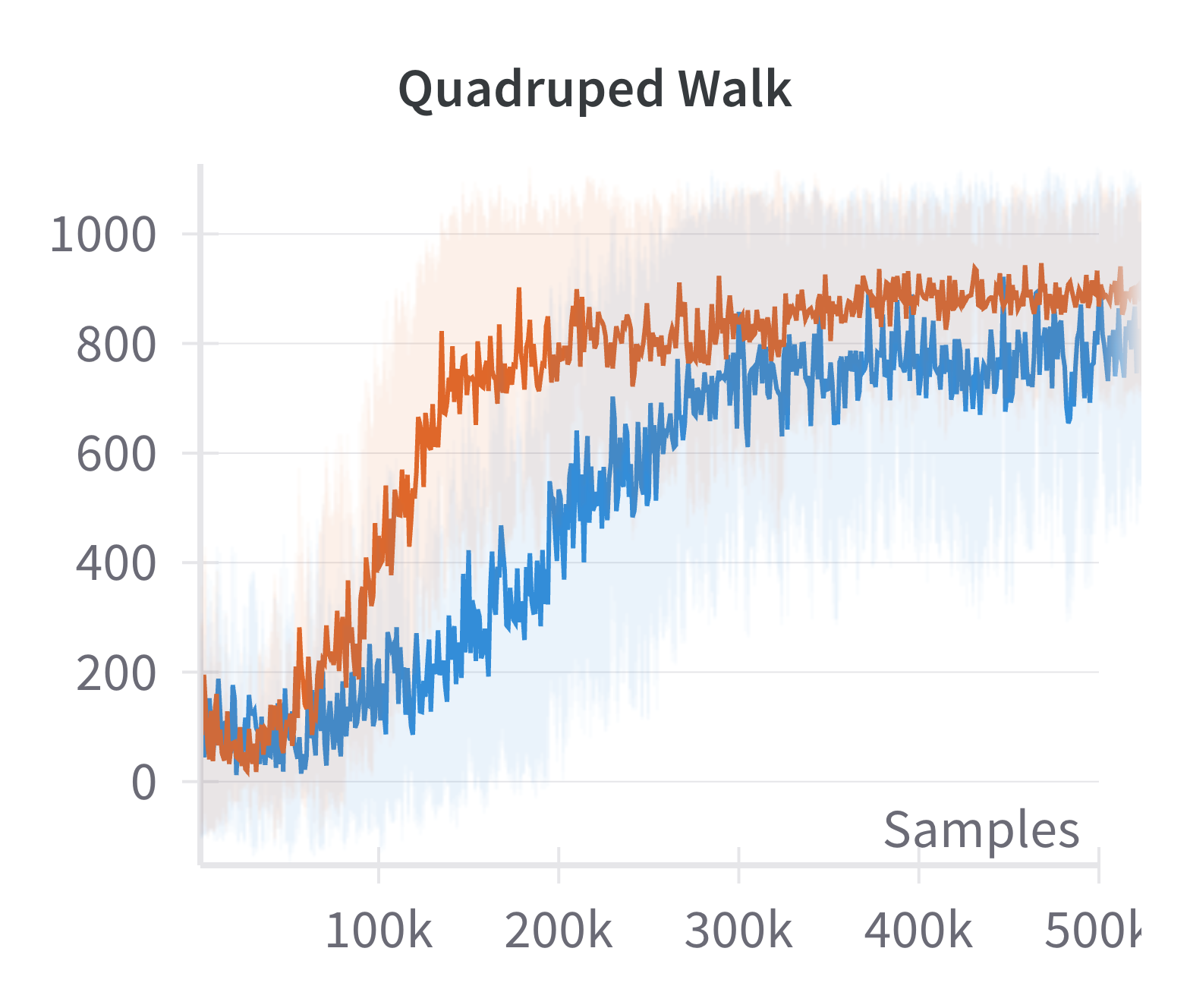
Figure 4: Discounted returns of SAC (blue) and sparse SAC (red) απ.
The sparse variant achieves higher returns, especially in environments where the standard SAC agent fails to learn effectively. This supports the claim that exploiting the emergent low-dimensional structure can yield practical gains in sample efficiency and final performance.
The computational overhead of the sparsification layer is also quantified.
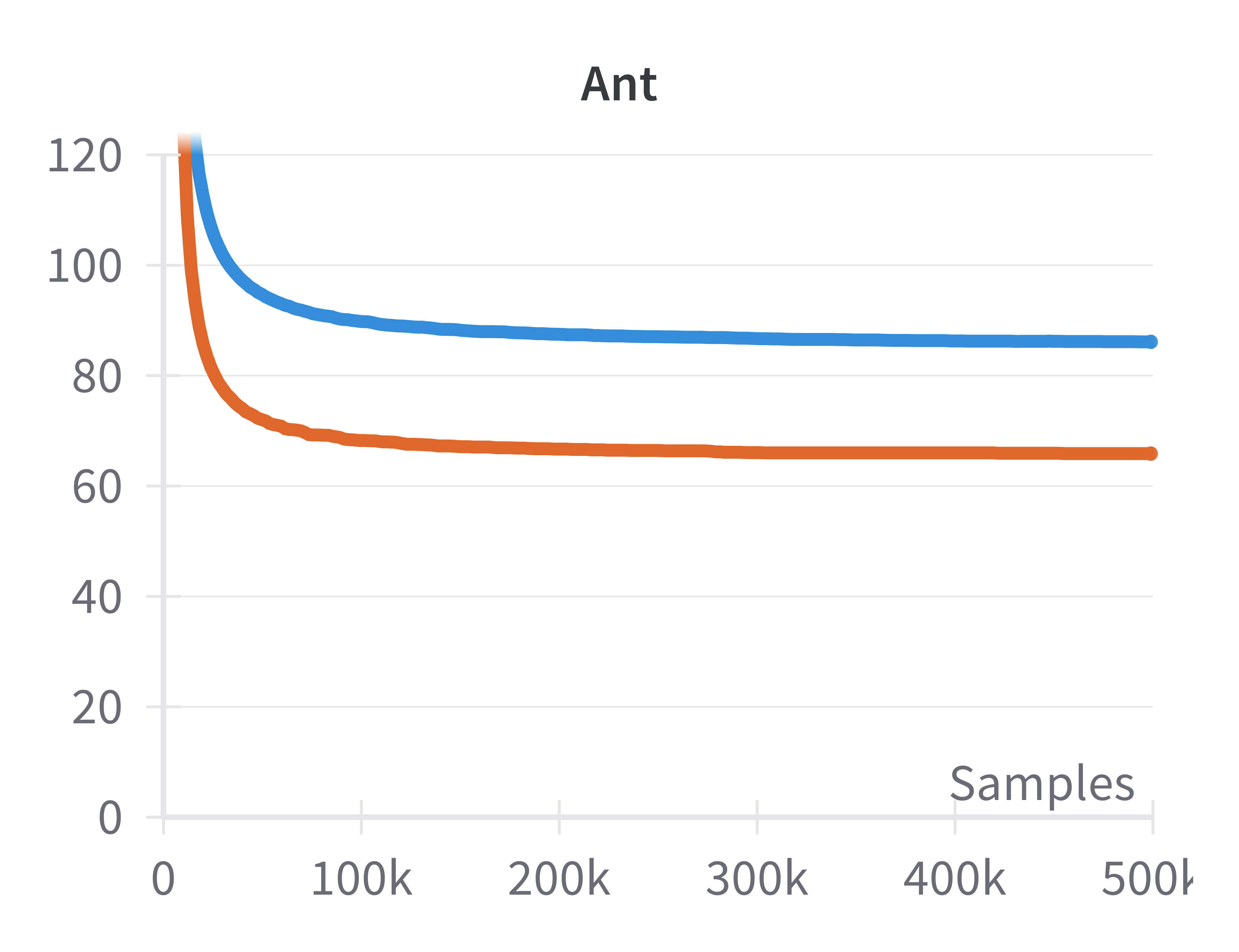

Figure 5: Steps per second for SAC (blue) and sparse SAC (red) as training progresses, showing a moderate decrease in throughput for the sparse variant.
While the sparse implementation reduces steps per second, the wall-clock cost is not prohibitive given the performance improvements.
Discussion and Theoretical Implications
The main theoretical contribution is the explicit connection between the geometry of the attainable state space and the action space dimension in neural RL. This result provides a rigorous foundation for the manifold hypothesis in RL, which has previously been assumed but not proven. The analysis also clarifies the role of overparameterization and the NTK regime in shaping the learning dynamics and the structure of the data generated by RL agents.
The findings have several implications:
- Sample Complexity: Since the effective state space is low-dimensional, the sample complexity of RL algorithms may depend more on da than ds, suggesting new directions for theory and algorithm design.
- Representation Learning: Explicitly learning or exploiting low-dimensional representations can improve learning efficiency and generalization, as demonstrated empirically.
- Extension to Stochastic and High-Dimensional Settings: The current analysis assumes deterministic transitions and fixed ds. Extending the theory to stochastic environments and the regime where ds→∞ remains an open challenge.
Future Directions
Potential avenues for further research include:
- Extending the geometric analysis to deeper networks, alternative activation functions, and stochastic environments.
- Developing RL algorithms that adaptively exploit the emergent manifold structure for improved exploration and credit assignment.
- Investigating the interplay between the geometry of the attainable state manifold and the expressivity or generalization properties of RL agents in more complex domains.
Conclusion
This work establishes a rigorous geometric perspective on neural RL in continuous domains, demonstrating that the set of attainable states under wide, two-layer NN policies is confined to a low-dimensional manifold whose dimension is controlled by the action space. Theoretical results are corroborated by empirical evidence across standard benchmarks, and practical benefits are realized by incorporating sparse representation learning into RL architectures. These insights advance the theoretical understanding of RL in high-dimensional settings and suggest concrete strategies for improving algorithmic performance by leveraging the intrinsic geometry of the problem.