- The paper introduces GLANCE, which optimizes node predictions by selectively invoking LLMs for complex nodes based on routing features.
- The framework employs a lightweight MLP router and a hybrid training strategy that combines direct loss minimization with reward-based updates.
- GLANCE demonstrates superior scalability and performance on diverse TAG datasets, particularly in low-homophily and low-degree scenarios.
Overview of "Glance for Context: Learning When to Leverage LLMs for Node-Aware GNN-LLM Fusion"
The paper introduces GLANCE, a framework designed to efficiently integrate Graph Neural Networks (GNNs) with LLMs for enhanced graph learning on text-attributed graphs (TAGs). GLANCE strategically leverages LLMs only when necessary, optimizing the balance between predictive accuracy and computational cost by targeting nodes difficult for GNNs.
Methodology
GLANCE Framework
GLANCE is structured around three primary components:
- Routing Features: GLANCE generates features per node to decide whether to invoke the LLM. The routing features include GNN-derived embeddings, local homophily estimation, degree, and prediction uncertainty. This information helps identify nodes where LLM intervention could refine predictions.
- Node Router: A lightweight Multi-layer Perceptron (MLP) determines routing decisions based on the generated features. The top k nodes most likely to benefit from additional LLM context are selected in each batch, optimizing for computational cost.
- LLM Embeddings Generation and Fusion: For routed nodes, their neighborhood context is serialized and processed by a pre-trained LLM to generate embeddings. These embeddings are combined with GNN embeddings using a refiner MLP to produce final node predictions.
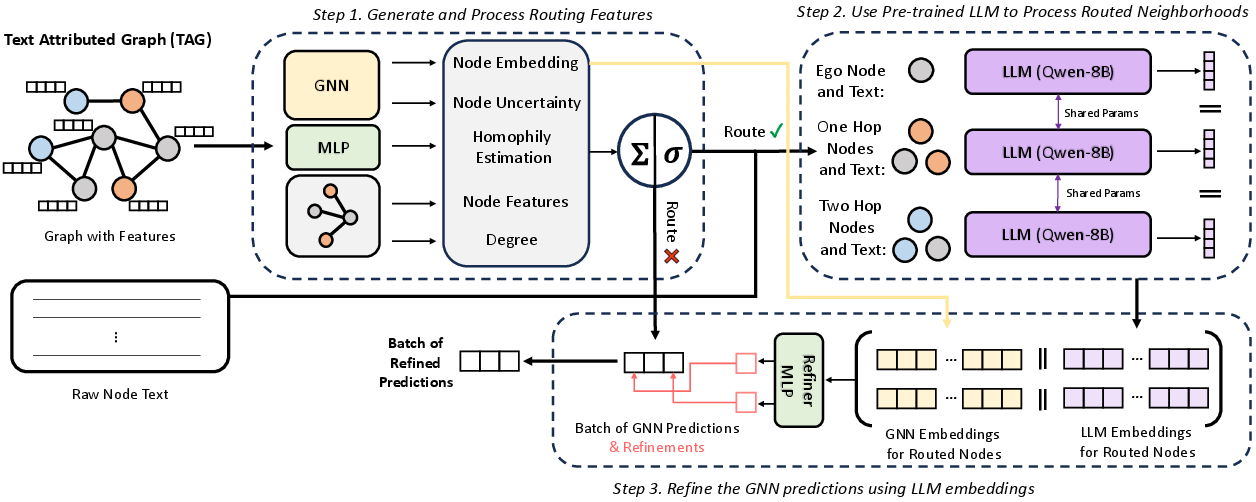
Figure 1: GLANCE Overview - shows the step-by-step process by which GLANCE makes use of LLMs alongside GNNs.
Training Strategy
GLANCE utilizes a hybrid training strategy involving both direct loss minimization for node classification and a reward-based approach for optimizing routing decisions. The router weights are updated using a policy gradient-inspired method that favors routes resulting in reduced prediction error, penalized by an embedding cost metric β.
The empirical analysis demonstrates GLANCE's superior performance across diverse TAG datasets. Notably, GLANCE achieves a balanced accuracy across nodes characterized by varying degrees of homophily, excelling particularly in low-homophily, low-degree contexts where GNNs traditionally underperform.
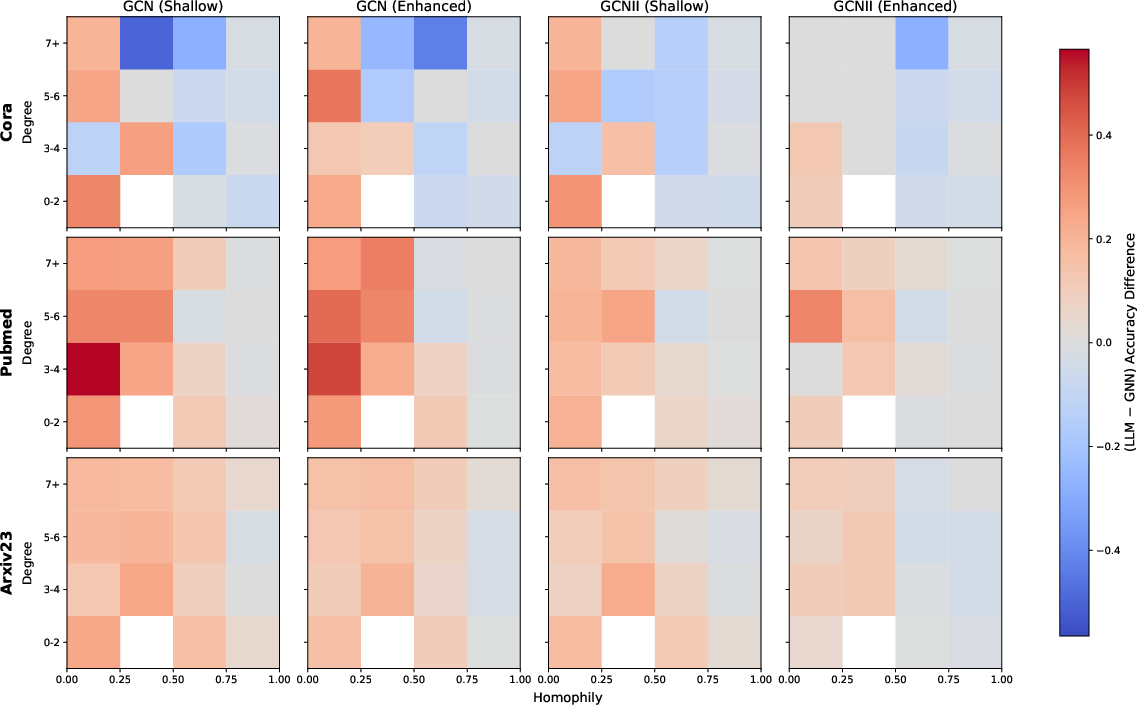
Figure 2: Stratified performance based on homophily and degree shows the variance in model performance where LLM assistance is most effective.
Sensitivity to Routing Budget
Investigating the impact of different routing budgets, GLANCE utilizes larger budgets effectively to improve performance on heterophilous nodes without degrading results on more homophilous nodes, showing flexibility in resource allocation.
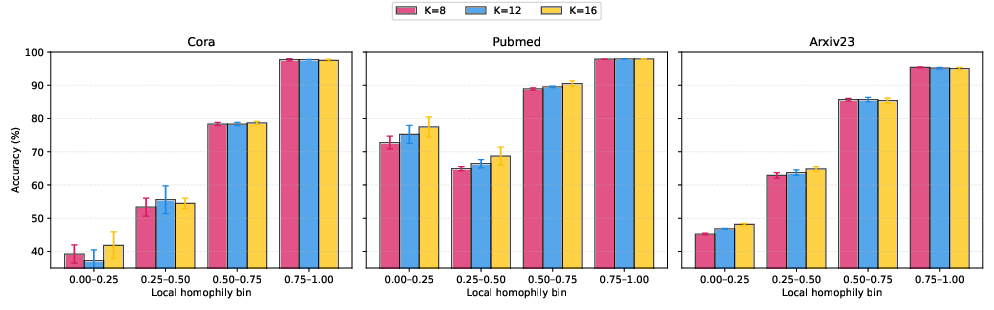
Figure 3: Performance changes as the routing budget 'K' is varied at test time reflect GLANCE's ability to scale resources effectively.
Ablation Studies
A detailed ablation study of the routing features underscores the importance of each feature, particularly local homophily, in maintaining robust performance. The largest drops occur in heterophilous regions when specific features are omitted, highlighting their critical role.
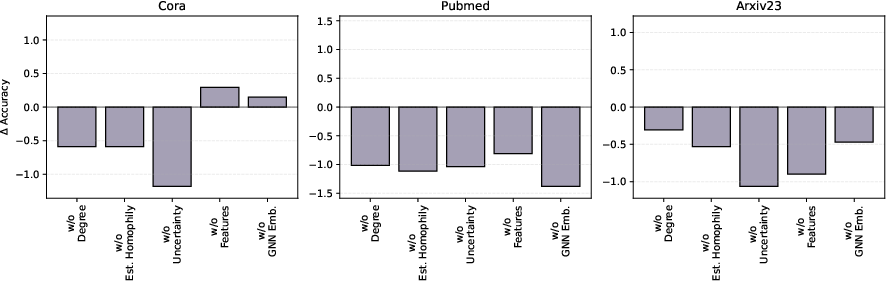
Figure 4: Shows the decay in performance resulting from training without specific routing features, emphasizing their importance.
Scalability and Efficiency
GLANCE is shown to be scalable, integrating LLMs with negligible overhead from GLANCE-specific operations compared to LLM computation. This efficiency ensures that GLANCE is applicable to larger datasets, enabling its application to large-scale TAGs like Arxiv-Year and OGB-Products.

Figure 5: Runtime breakdown illustrates the scalability of GLANCE, with negligible overhead from routing and refinement compared to LLM computation.
Conclusion
GLANCE presents a strategic pathway for deploying GNN-LLM hybrids, effectively utilizing LLMs' strengths while avoiding unnecessary computational costs. By employing adaptive routing based on node-specific structural properties, GLANCE achieves improved performance across complex graph scenarios, demonstrating significant promise for future scalable graph learning applications.