- The paper introduces UALM, a unified model that performs audio understanding, text-to-audio generation, and multimodal reasoning without sacrificing quality compared to specialized systems.
- The paper details advanced training techniques including curriculum learning, classifier-free guidance, and direct preference optimization to enhance generation fidelity and convergence.
- The paper presents UALM-Reason, a novel framework for multimodal chain-of-thought reasoning that iteratively refines audio outputs and improves controllability and user satisfaction.
Unified Audio LLM for Understanding, Generation, and Reasoning
Overview and Motivation
Audio intelligence research has historically approached understanding (e.g., audio event recognition) and generation (e.g., text-to-audio synthesis) with specialized, distinct architectures and training paradigms. Reasoning—especially generative multimodal reasoning—remains significantly under-explored. The paper “UALM: Unified Audio LLM for Understanding, Generation and Reasoning” (2510.12000) proposes a unified framework, UALM, designed to address these limitations. UALM performs high-quality audio understanding, text-to-audio generation, and multimodal reasoning (including generative audio reasoning and self-reflection), within a single LLM. This work provides new technical recipes to make such integration viable, addresses data and optimization challenges, and establishes empirically that unification does not incur quality loss relative to prior specialized systems.
Architecture and Training Paradigm
Fundamentally, UALM extends a decoder-only LLM backbone initialized from Qwen2.5-7B, equipped to handle text and audio. Audio inputs are processed via an Encoder-Adapter-LLM stack—using a continuous acoustic encoder that avoids the lossy effects of audio tokenization. Audio outputs are generated as sequences of discrete codec tokens, produced using X-codec and residual vector quantization (RVQ) with delay pattern parallelization for efficient auto-regressive modeling.
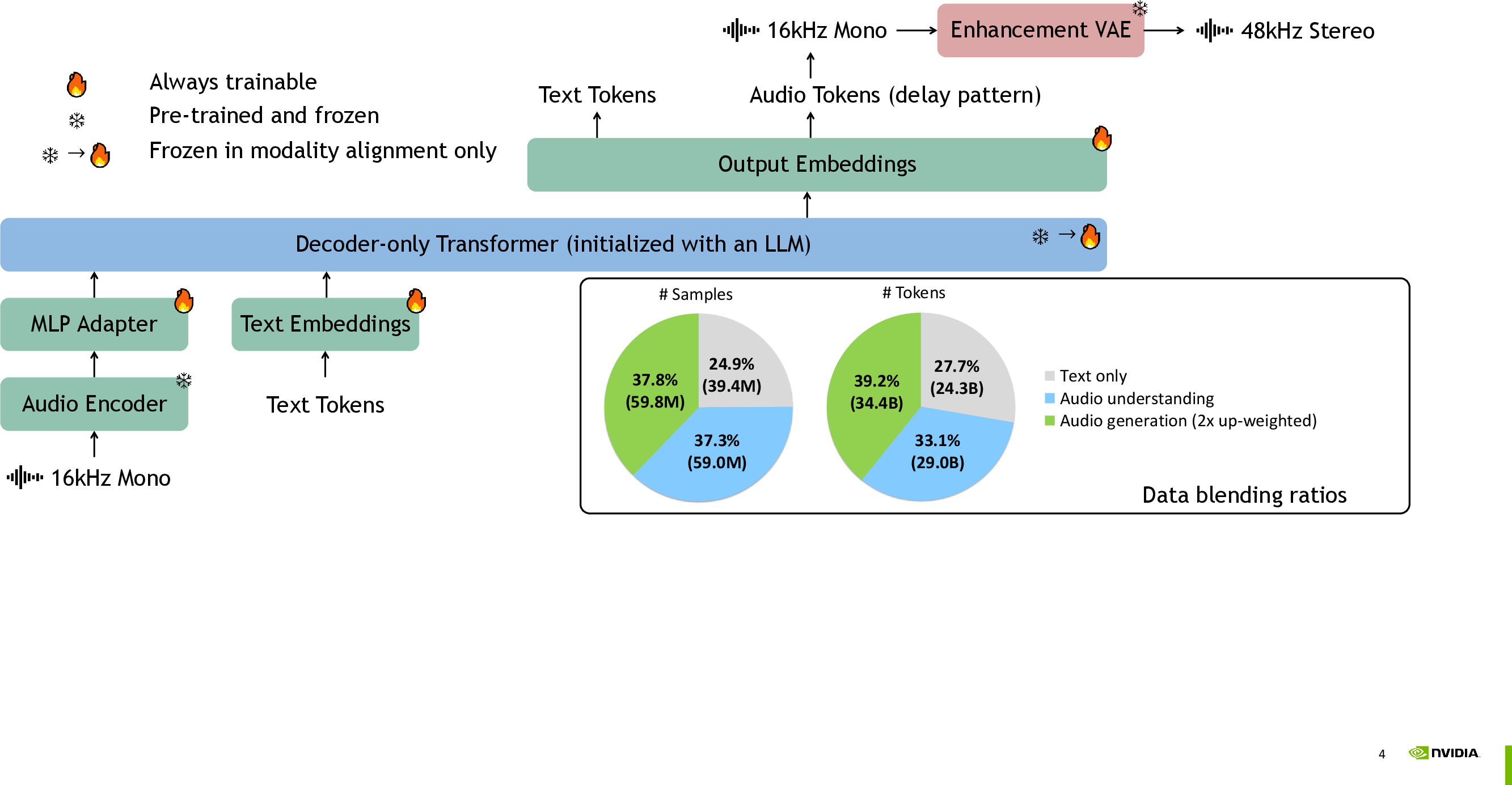
Figure 1: UALM overview; the multimodal architecture integrates text and audio modalities with optimized data blending.
The enhanced output is further post-processed by an upsampling VAE module, boosting signal fidelity from 16kHz mono to 48kHz stereo. This enhancement pipeline leverages adversarial, spectrogram, and feature-matching losses for robust waveform restoration.
Unified modeling across tasks is achieved through careful pre-training regimens. Key mechanisms include:
- Data mixing: Empirically optimized blending ratios across text reasoning, audio understanding, and generation datasets ensure balanced task mastery.
- Modality alignment: A curriculum that freezes the LLM backbone and updates adapter/audio embedding layers at initialization prevents catastrophic forgetting.
- Sequence packing: Fine-grained token sequence packing supports efficient joint modeling and stable multi-task convergence.
LM-based Audio Generation and Preference Optimization
UALM-Gen is the base instantiation of the LM-based text-to-audio generator. Unlike prior approaches that relied on cross-attending to externally encoded caption embeddings, UALM-Gen handles BPE-tokenized text naturally—leveraging LLM pre-training for semantic alignment. Several novel findings underpin the approach:
- Data scaling: LM-based generation requires an order of magnitude more paired audio-text data than diffusion-based models to reach quality parity. Scaling to 30M pairs (17B tokens) is essential for SOTA performance.
- Classifier-Free Guidance (CFG): Direct application of CFG at inference time (optimal λ=3) is crucial for fidelity and prompt adherence.
- Direct Preference Optimization (DPO): Post-hoc DPO fine-tuning using synthetic preference pairs (ranked by CLAP and Aesthetic scores) leads to further improvements in faithfulness and perceptual quality. DPO is combined with a cross-entropy regularizer to control divergence from the base model.
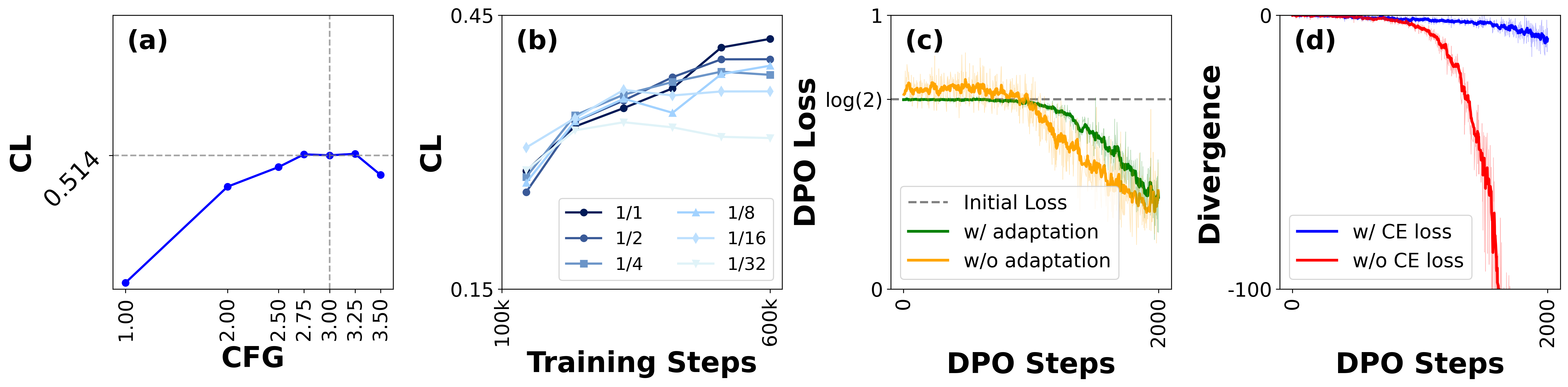
Figure 3: Ablation analyses for CLAP scores, data down-weighting, DPO loss, and divergence regularization during training.
Empirical studies reveal that successive application of CFG, DPO, and enhancement VAE modules are each critical for SOTA generation metrics (FD, KL, CL, IS, Aesthetic).
Unified Pre-Training for Understanding, Generation, and Reasoning
The full UALM model is subject to joint pre-training over fused text, audio understanding, and generation data. The optimized blend ensures no marked regression in text-only benchmarks (MMLU, GSM8K, HumanEval) compared to the initializing Qwen2.5-7B model. Simultaneously, UALM matches or exceeds leading open-source audio understanding models (e.g., Audio Flamingo 3, Qwen2.5-Omni) on MMAU/MMAR benchmarks.
Empirical training traces show that understanding converges substantially faster than generation, underscoring the slower signal learning in the generative domain.
UALM-Reason: Chain-of-Thought Multimodal Reasoning
A pioneering aspect is the extension to UALM-Reason: enabling the model to perform nontrivial, multimodal chain-of-thought (CoT) reasoning that encompasses both understanding and generation. This is instantiated via post-training with interleaved SFT and DPO on specifically curated tasks:
- Rich captions: Intermediate, machine-usable, compositional scene descriptions (keywords, layout, descriptions) serve as generation blueprints.
- Enrichment: Abstract user prompts are exhaustively elaborated into rich captions automatically.
- Dialogue: The model engages in multi-turn, user-driven caption planning, clarifying imprecise specifications through natural language interaction.
- Self-Reflection: UALM-Reason iterates a generate-understand-critique-refine cycle—first generating, understanding, critiquing, and then regenerating audio based on its own diagnosis of prior mistakes.
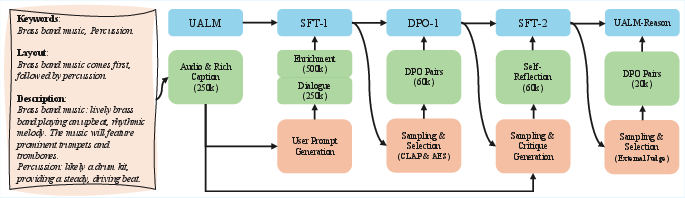
Figure 4: Example of a rich caption and the structured post-training workflow for UALM-Reason.

Figure 2: Demo cases illustrating advanced audio reasoning and iterative joint understanding-generation pipelines.
Figure 6: Qualitative results for enrichment (imaginative, underspecified prompts).
Figure 5: Dialogue-oriented rich caption construction for multi-turn user interaction.

Figure 7: Illustration of self-reflection, where the model critiques and corrects its own generations.
Subjective evaluations on Mechanical Turk confirm significant improvement in controllability, semantic faithfulness, and user satisfaction for enrichment, dialogue, and self-reflection categories. UALM-Reason outperforms non-reasoning-enabled UALM baselines by 0.2–0.3 points on a 5-scale MOS for these tasks.
SOTA-level or superior performance is achieved in all domains:
- Audio generation: UALM-Gen and UALM reach competitive CLAP, FD, and Aesthetic scores versus prevailing diffusion and autoregressive models, matching human-level relevance and quality ratings. The model generalizes to broad and challenging prompt types.
- Understanding: UALM matches or exceeds open-source specialists, with strong results specifically in sound and music domains of the MMAU and MMAR benchmarks.
- Textual reasoning: Degradation in language, math, and code tasks is marginal compared to baseline LLMs and much lower than prior unified vision-speech models, demonstrating successful knowledge preservation.
Implications and Future Directions
The main practical implication is that strong AI audio systems no longer require task-segregated models; competitive understanding, generation, and reasoning capabilities co-exist within a single LLM-scale architecture when built with careful data and optimization strategies. Theoretically, UALM highlights the importance of multimodal chain-of-thought and self-reflective iteration as routes to more general, agentic, and creative audio models.
Several promising directions for further work include:
- Unified audio representation: Harmonizing discrete/dense encodings between input and output streams, further facilitating joint training and reducing redundancy.
- Robust caption quality control: As synthetic captions are subject to misalignment and hallucination, scalable, quantitative methods for filtering/correcting them are required.
- Advanced audio evaluation metrics: New metrics that better align with human assessment of quality, diversity, and cross-modal coherence will enable more robust optimization and reward modeling, particularly for reasoning chains and aesthetic targets.
Conclusion
UALM constitutes a unified paradigm for audio language modeling, demonstrating that text, audio understanding, and generative reasoning can be effectively amalgamated in a single LLM framework without sacrificing performance on any particular task. Introduction of UALM-Reason, with its explicit multimodal chain-of-thought capabilities, marks a substantial advancement for controllable, versatile, and autonomous audio agents. The methodology sets the groundwork for broader multimodal intelligence research, where generative reasoning and self-improvement become architectural primitives.