- The paper presents the Reinforced Energy-Based Bayesian Optimization (REBMBO) model that tackles one-step myopia with multi-step PPO-guided exploration.
- It integrates Gaussian Processes for accurate local surrogate modeling with Energy-Based Models to capture a global energy landscape.
- Experimental results demonstrate significant improvements over traditional methods, especially in high-dimensional, multi-modal optimization tasks.
Optimizing the Unknown: Black Box Bayesian Optimization with Energy-Based Model and Reinforcement Learning
Introduction to Black-Box Bayesian Optimization
The paper "Optimizing the Unknown: Black Box Bayesian Optimization with Energy-Based Model and Reinforcement Learning" (2510.19530) tackles the challenges inherent in optimizing expensive, complex functions through Bayesian Optimization (BO) methodologies. Extending traditional BO techniques, the work focuses on overcoming the "one-step myopia" constraint, which typically limits exploratory efficiency, especially in high-dimensional and multi-modal optimization landscapes.
Reinforced Energy-Based Model (REBMBO) Introduction
The core contribution of this study is the introduction of the Reinforced Energy-Based Bayesian Optimization Model (REBMBO). This model synergistically combines Gaussian Processes (GP) and Energy-Based Models (EBM) with a multi-step exploration strategy guided by Reinforcement Learning (RL). Specifically, the model frames BO as a Markov Decision Process (MDP) and utilizes Proximal Policy Optimization (PPO) to strike an adaptive balance between exploration and exploitation.
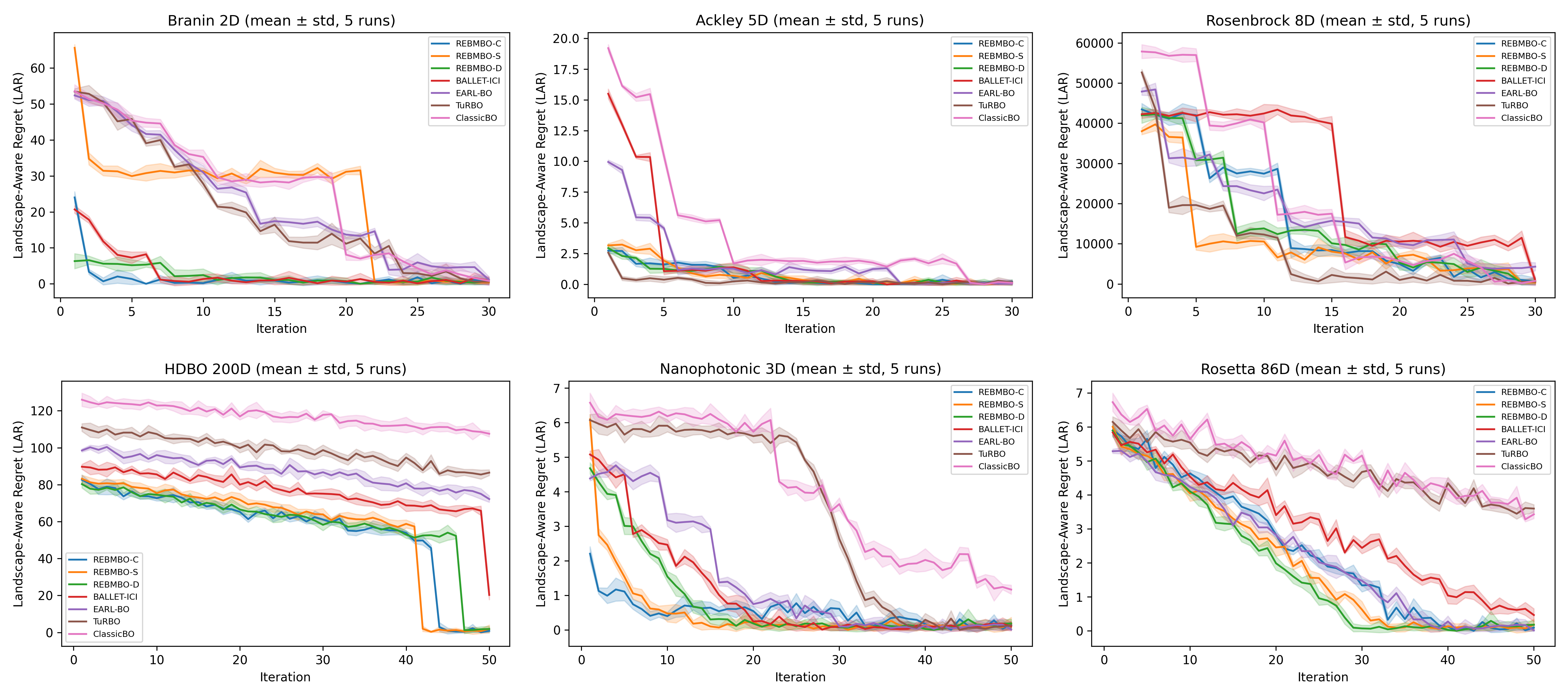
Figure 1: Bayesian optimization performance across benchmarks: (a) Branin 2D, (b) Ackley 5D, (c) Rosenbrock 8D, (d) HDBO 200D, (e) Nanophotonic 3D, (f) Rosetta 86D. REBMBO variants (blue shades) consistently outperform baselines, especially in higher dimensions.
Methodology
Gaussian Process Integration
The Gaussian Process in REBMBO functions as a local surrogate for the objective function, offering predictions about its behavior based on previously collected data. It is updated iteratively to provide the mean and uncertainty estimates that are critical for determining the utility of unexplored regions.
Energy-Based Model
The EBM facilitates global exploration by deriving and embedding an energy landscape that serves as a proxy for the distribution of potential promising regions. It is trained via short-run MCMC methods, striking a balance between computational tractability and exploration efficacy.
PPO-Based Reinforcement Learning
The unique aspect of this work is the use of PPO, an advanced RL algorithm, to adaptively manage exploration depth and direction within the BO framework. By dynamically considering multi-step rollouts, PPO helps circumvent the limitations of single-step acquisition strategies, which are prone to suboptimal local exploitation without further exploration incentives.
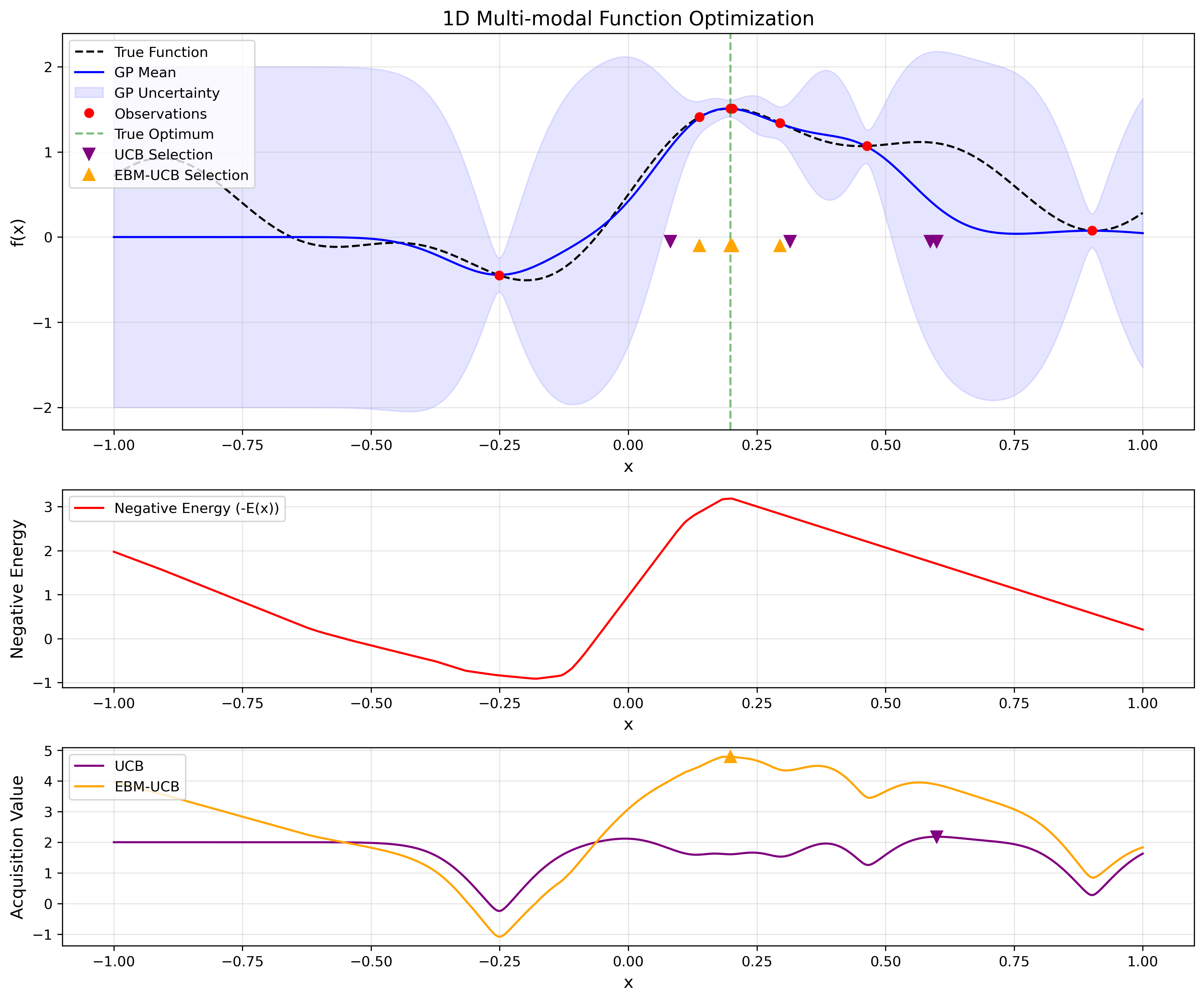
Figure 2: 1D multi-modal function experiment. The top panel shows the true function (dashed), GP mean (solid), and sampled points from UCB (purple) vs.\ EBM-UCB (orange). The middle panel illustrates the learned negative energy −Eθ(x). The bottom panel compares the two acquisition functions, emphasizing how EBM-UCB better targets the global peak near x≈0.25.
Experimental Results
Experiments conducted on varied benchmarks, from low-dimensional functions like Branin 2D to complex 200-dimensional spaces, demonstrate REBMBO’s superior performance over traditional methods. The model effectively reduces Landscape-Aware Regret (LAR) by combining local insights from GPs with the global landscape perspective provided by EBMs, and RL's adaptive strategy.
Future Implications
The integration of EBMs and RL into the BO paradigm suggests a marked advancement in optimizing unknown, black-box functions. Future studies could explore asynchronous evaluation mechanisms or extend the RL framework to deal with distributed and noisy environments. This methodology might also find significant applications in domains like materials science and pharmaceuticals, where optimization landscapes are notoriously rugged and evaluation costs are high.
Conclusion
REBMBO represents a methodological advancement in Bayesian optimization by addressing the limitations of both local exploitation and short-term exploratory sequences that characterize conventional models. The dual emphasis on local surrogate accuracy and a broader global exploration signals a pathway toward more efficient and robust optimization strategies in complex, high-dimensional spaces. As the method matures, it has potential for broader application across various optimization-intensive domains, underscoring the synergy between machine learning and optimization in advancing computational science.