- The paper demonstrates that advantage shaping techniques and direct Pass@K policy gradient optimization are mathematically equivalent, unifying diverse RL methods.
- It introduces a surrogate reward framework that reduces gradient variance and stabilizes learning in complex reinforcement learning settings.
- Empirical analysis shows that the unified approach improves model performance, particularly in large language models and RL with verifiable rewards.
Advantage Shaping as Surrogate Reward Maximization: Unifying Pass@K Policy Gradients
Introduction
This paper presents a comprehensive analysis of methods for optimizing policy gradients in reinforcement learning with verifiable rewards, focusing on the Pass@K metric. The authors explore two main approaches: direct policy gradient optimization for Pass@K and advantage shaping techniques. They demonstrate that these methods are fundamentally equivalent, both aiming to maximize a unified surrogate reward, providing a new framework for understanding and developing algorithms in reinforcement learning.
Problem Setup
The paper investigates reinforcement learning (RL) models where the objective is to maximize the probability of generating at least one correct response among multiple attempts for each problem, known as the Pass@K objective. The authors consider reinforcement learning with verifiable rewards (RLVR) under a distribution P of problem-answer pairs (x,a), where the policy πθ aims to produce responses matching a reference answer.
Reward Functions
Two reward functions are central to the problem: the binary 0/1 reward function for single responses, and the Pass@K reward that measures success if any of K responses is correct. The authors argue that optimizing for Pass@K at training time aligns more closely with how LLMs are applied in practice.
Policy Gradient Methods
The authors compare several methods for policy gradient optimization:
- REINFORCE: A classical algorithm suffering from high variance.
- RLOO (REINFORCE with Leave-One-Out): Reduces variance by incorporating an advantage function.
- GRPO (Group Relative Policy Optimization): Normalizes advantage scores by their estimated standard deviation.
Each method provides a different way to estimate and optimize the expected gradient, adjusting for variance and bias in distinct manners.
Pass@K Optimization
Building on previous work, the authors derive new formulations for optimizing the Pass@K gradient:
Unified View through Surrogate Rewards
A major contribution of this paper is showing that advantage shaping methods can be interpreted as maximizing a surrogate reward function. This perspective is developed through both reverse and forward engineering:
- Surrogate Rewards: Advantage shaping becomes equivalent to regularized surrogate reward maximization, where commonly used heuristics are shown to align with this surrogate view.
- Reverse Engineering GRPO: Advantage shaping is shown to naturally arise from targeting variance-stabilized transformations of the Pass@K rewards, enabling more stable and interpretable algorithm design.
Empirical Analysis
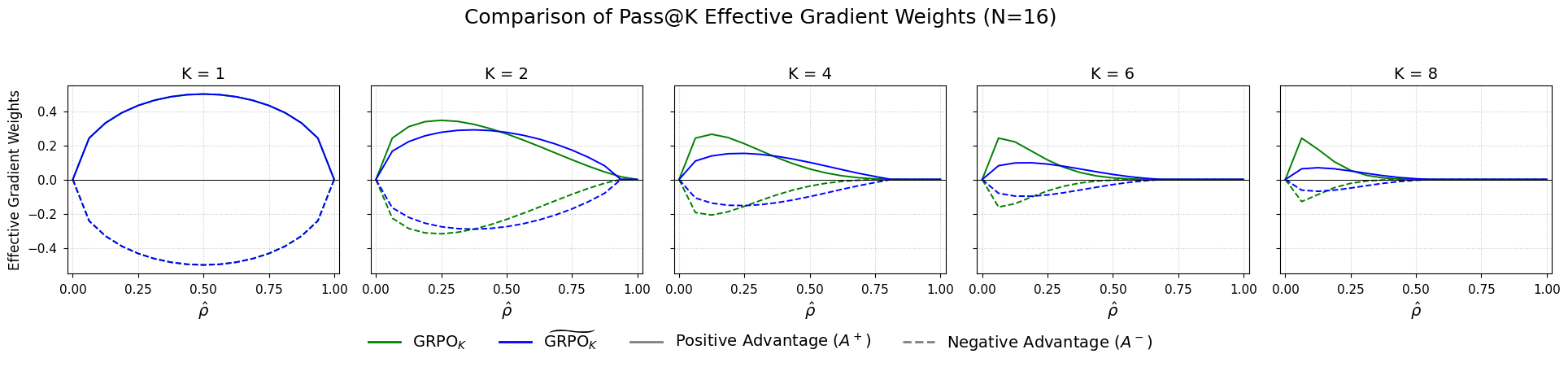
The authors conduct empirical comparisons of various Pass@K optimization strategies, including both unbiased and biased estimation methods. They show the impacts of different advantage weighting schemes on model learning, particularly under varying sample conditions and reward regimes.
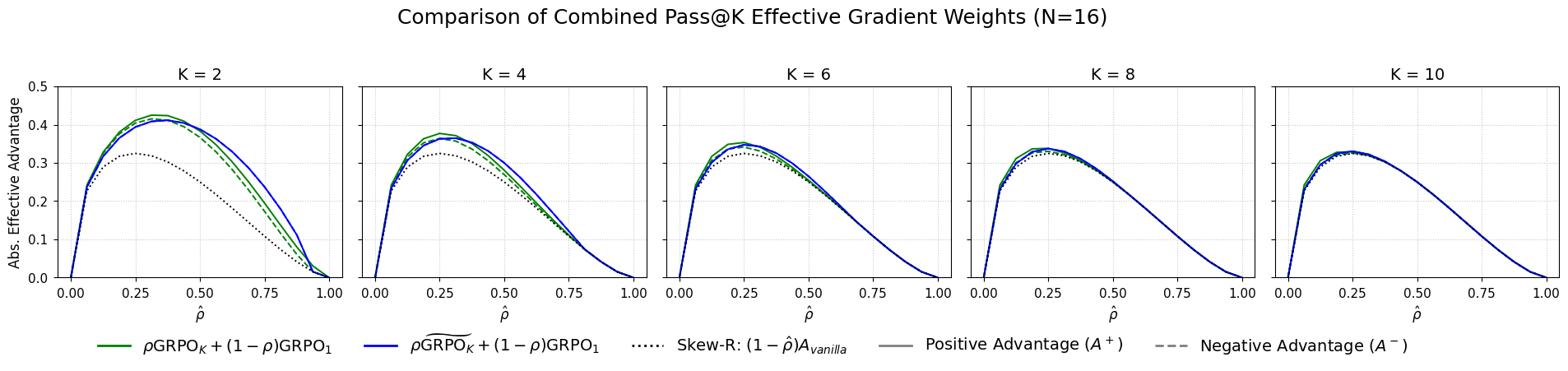
Figure 2: % Combined Pass@K effective gradient scores for N=16 and $K\in{2,4,6,8,10.
Implications and Future Work
The research suggests that by examining surrogate rewards and leveraging advantage shaping, new reinforcement learning algorithms can be developed that are generalized and stable across different environments. The authors discuss the implications for RLVR applications, potential improvements in balancing exploration and exploitation, and the broader significance for training strategies in large-scale LLMs.
Conclusion
The study concludes that advantage shaping techniques and direct policy optimization for Pass@K are fundamentally the same in terms of underlying principles. This unification through surrogate rewards provides a clear lens for extending reinforcement learning methods to complex, verifiable reward structures, pushing forward the development of more effective RL algorithms in AI.
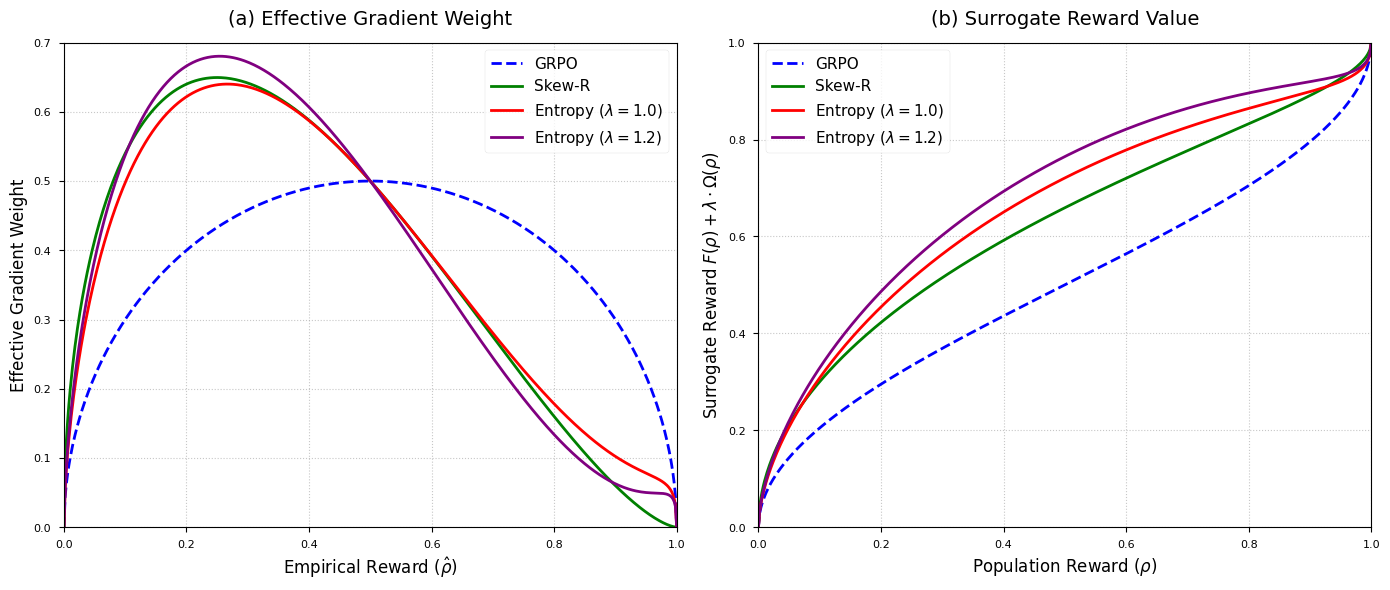
Figure 3: Comparison of (regularized) surrogate objectives (GRPO, Skew-R, and Entropy-Augmented).
Overall, this paper offers a new unified framework for understanding and designing policy gradients, suggesting that many existing and potential future advancements in reinforcement learning can be viewed through the lens of surrogate reward maximization.