Agent Data Protocol: Unifying Datasets for Diverse, Effective Fine-tuning of LLM Agents
Abstract: Public research results on large-scale supervised finetuning of AI agents remain relatively rare, since the collection of agent training data presents unique challenges. In this work, we argue that the bottleneck is not a lack of underlying data sources, but that a large variety of data is fragmented across heterogeneous formats, tools, and interfaces. To this end, we introduce the agent data protocol (ADP), a light-weight representation language that serves as an "interlingua" between agent datasets in diverse formats and unified agent training pipelines downstream. The design of ADP is expressive enough to capture a large variety of tasks, including API/tool use, browsing, coding, software engineering, and general agentic workflows, while remaining simple to parse and train on without engineering at a per-dataset level. In experiments, we unified a broad collection of 13 existing agent training datasets into ADP format, and converted the standardized ADP data into training-ready formats for multiple agent frameworks. We performed SFT on these data, and demonstrated an average performance gain of ~20% over corresponding base models, and delivers state-of-the-art or near-SOTA performance on standard coding, browsing, tool use, and research benchmarks, without domain-specific tuning. All code and data are released publicly, in the hope that ADP could help lower the barrier to standardized, scalable, and reproducible agent training.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
1. What is this paper about?
This paper introduces something called the Agent Data Protocol (ADP). Think of ADP like a “universal language” that different kinds of AI agent data can use. Today, many datasets that train AI agents (for tasks like browsing the web, writing code, or using tools) are stored in different, messy formats. ADP makes them all look the same so they can be easily combined and used to train better agents. The authors show that when they train AI agents on this unified data, the agents get much better—often by about 20%—across many kinds of tasks.
2. What questions did the researchers ask?
The paper looks at simple but important questions:
- Can we turn many different agent datasets into one common, easy-to-use format?
- Does training on this unified, mixed data make AI agents better across many tasks (not just one)?
- Can ADP save engineering time by avoiding custom code for each dataset and each agent framework?
- Does learning from diverse tasks help agents perform better even on specific, hard benchmarks?
3. How did they do it?
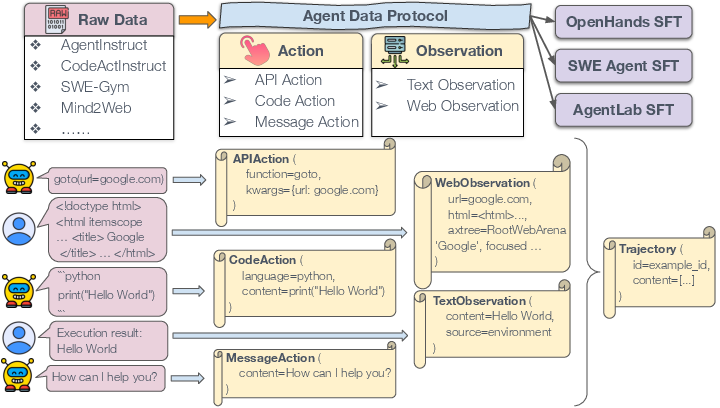
First, the authors designed ADP, a simple “template” for agent data. In ADP, every agent interaction is a Trajectory—like a play-by-play of what the agent does and sees. Each trajectory is made of two parts: actions (what the agent does) and observations (what the agent sees or reads).
Here are the action and observation types ADP supports:
- Actions (what the agent does):
- API Action: Calling a tool or function (like “open this website” or “run this search”). Imagine tapping an app’s button with specific settings.
- Code Action: Writing and running code (like Python). Think of it as the agent typing programs and pressing “run.”
- Message Action: Talking in plain language (explaining, asking questions, or responding to the user).
- Observations (what the agent receives):
- Text Observation: Any text the agent gets back (like a user’s message or a program’s output).
- Web Observation: What’s on a webpage (the URL, the HTML, the screen size, and optional screenshot info).
Next, they built a three-step “pipeline” (a clear process) to use ADP:
- Raw to Standardized: Convert 13 different datasets (coding, browsing, tool use, and software engineering) into the ADP format.
- Standardized to SFT: Turn ADP data into training examples for several agent systems (called “agent frameworks”), such as OpenHands, SWE-Agent, and AgentLab. SFT means supervised fine-tuning—like coaching the model with example tasks and correct answers.
- Quality Checks: Automatically verify that tool calls are valid, decisions are explained, and conversations are well-formed.
They trained popular base models (like Qwen2.5 and Qwen3, 7–32B sizes) with this ADP data and tested them on well-known benchmarks:
- SWE-Bench (real-world coding fixes)
- WebArena (realistic web tasks)
- AgentBench OS (tool and system use)
- GAIA (general assistant tasks requiring reasoning and tools)
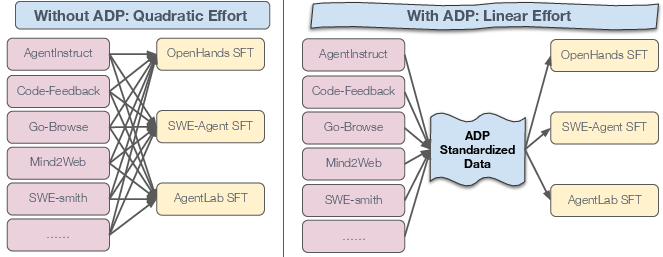
They also measured how much engineering effort ADP saves. Without ADP, you must write custom converters for each dataset and each agent framework—lots of duplicated work. With ADP, you convert each dataset once, and each agent needs only one ADP-to-training converter. This switches from “many-to-many” work to a simple “hub-and-spoke” setup.
4. What did they find?
The main results are clear and strong:
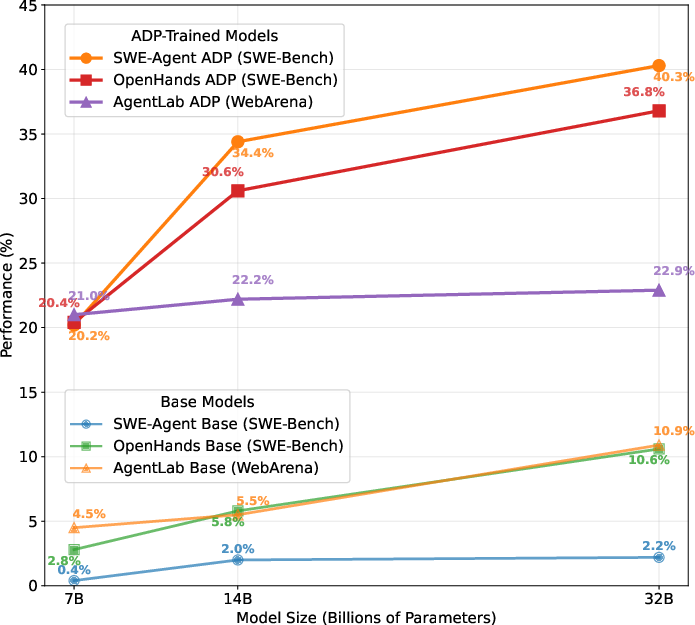
- Better performance across the board: Training on ADP data improved agents by about 20% on average. In some cases, the ADP-trained 7–32B models reached state-of-the-art (SOTA) or near-SOTA results on tough benchmarks.
- Works across tasks: Improvements showed up in coding (SWE-Bench Verified), web browsing (WebArena), tool use (AgentBench OS), and research tasks (GAIA).
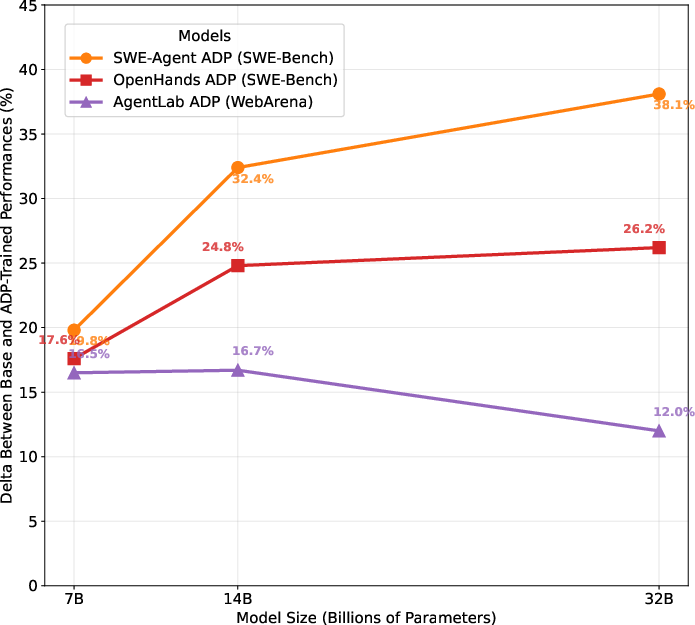
- Diverse data helps: Models trained on the mixed ADP dataset beat models trained only on single-task data. This “cross-task transfer” means learning from different kinds of tasks makes the agent more flexible and powerful.
- Huge engineering savings: ADP reduces the effort from quadratic (every dataset × every agent needs a custom converter) to linear (each dataset converts once to ADP; each agent converts once from ADP). It’s like building one universal plug instead of dozens of custom cables.
- Scales with model size: Bigger models trained on ADP data keep getting better in a smooth, predictable way.
5. Why does it matter?
ADP makes training AI agents practical, scalable, and reproducible for the whole community. Instead of struggling with incompatible datasets and one-off scripts, researchers and developers can:
- Combine lots of useful data easily and safely.
- Train agents that are strong across many real-world tasks.
- Share data and tools without redoing the same work.
- Grow faster as new datasets and agent frameworks arrive (they can “plug in” to ADP).
The authors also plan future steps like supporting more kinds of data (images, screens, recordings) and standardizing evaluation setups. They’ve released the code and data publicly so others can use, improve, and build on ADP. In short, ADP is a simple, common “language” for agent data that helps the whole field move faster and build better AI assistants.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to guide follow‑up research and engineering.
- Schema coverage beyond current action/observation types: ADP currently models
APIAction,CodeAction,MessageAction,TextObservation, andWebObservation. It lacks standardized support for desktop GUI actions (non‑web), mobile/Android/iOS controls, robotics/sensors, audio, and video streams—limiting applicability to broader agent domains. - Multimodality: ADP does not yet encode screenshots as first‑class multimodal training signals (only optional blobs), nor audio/video/touch/keystroke event streams. Define a multimodal extension (images, screen recordings, speech, OCR, eye‑tracking) and evaluate its impact on benchmarks like GAIA.
- Temporal and concurrency semantics: Trajectories omit timestamps, action durations, and asynchronous/callback semantics. Introduce time‑stamped events, parallel tool calls, and interrupt/resume primitives to capture realistic agent workflows.
- Environment state modeling: ADP lacks standardized state snapshots/deltas (e.g., filesystem diffs, repo state, process tables, browser session cookies/localStorage). Add schema elements for stateful side‑effects to enable reproducible replays and stronger learning signals.
- Error taxonomy and failure handling: There is no unified representation for exceptions, timeouts, retries, partial successes, or tool misconfigurations. Define a cross‑dataset error taxonomy and encode retry policies to support robust agent training.
- Web dynamics fidelity: Web observations include
htmlandaxtreebut ignore runtime JS state, event logs, CSS/DOM mutations, and network requests. Evaluate richer browser instrumentation and its effect on web agent performance. - Tool ontology and semantic alignment: Converters map heterogeneous tool names/arguments ad hoc. Establish a canonical ontology/registry for tools and argument types, with versioning and mapping guidelines to prevent semantic drift and collisions.
- Metadata standardization: The
detailsfield is flexible but underspecified. Define required metadata fields (dataset source, license, environment/tool versions, seeds, timestamps, provenance, annotator type—human/LLM/agent, curation method) to improve reproducibility and auditability. - Information loss assessment: The paper claims expressiveness but provides no systematic audit of lossy vs. lossless conversion per dataset. Design equivalence tests and per‑field loss metrics to quantify fidelity of Raw→ADP→SFT mappings.
- Dataset decontamination: No analysis of training–evaluation overlap or leakage (e.g., SWE‑Bench/WebArena tasks). Implement contamination checks (hashing/fingerprinting, URL/code overlap detection) and report decontaminated results.
- Quality assurance efficacy: QA checks (e.g., “80% tool calls paired with English thought”) are heuristic and unvalidated. Perform ablations on QA thresholds/features, correlate QA scores with downstream accuracy, and publish a data quality dashboard.
- Converter validation: Converters are hand‑coded with no formal test coverage. Provide unit/property tests and cross‑converter validation (round‑trip checks) to ensure consistent, correct mappings across datasets.
- Automation of conversion: Conversion pipeline requires manual engineering per dataset. Explore semi‑automatic/automatic converter synthesis (schema induction, pattern mining, LLM‑assisted mapping) and measure accuracy, effort savings, and failure modes.
- Adaptation breadth: ADP→SFT was demonstrated on only three harnesses (OpenHands, AgentLab, SWE‑Agent). Evaluate integration with additional frameworks (Cursor/VSCode agents, OS/database agents, ReAct/Graph‑of‑Thought, mobile/desktop control) to validate generality.
- Training paradigm scope: Experiments employ SFT only. Compare ADP under alternative training regimes (DPO, reinforcement learning, process reward models, imitation learning with process supervision) to quantify marginal gains and stability.
- Mixture design and data valuation: Mixture weights are in the appendix but there is no analysis of how domain/task composition affects performance. Conduct controlled studies (per‑domain ablations, curriculum schedules, data valuation) and publish optimized mixtures.
- Bias and imbalance: Orca AgentInstruct (synthetic tool‑use) dominates the corpus (~1M). Quantify domain imbalance, source biases (human vs. synthetic vs. rollout), and their downstream effects; apply re‑balancing and assess fairness and robustness.
- Multilingual coverage: ADP datasets appear predominantly English. Add non‑English trajectories and evaluate cross‑lingual generalization and multilingual tool‑use alignment.
- Long‑horizon limitations: Trajectories average 10 turns (up to ~27), with no discussion of very long tasks (hundreds/thousands of steps). Benchmark context‑length constraints, introduce hierarchical/segment annotations, and study memory strategies (retrieval, episodic memory fields).
- GAIA underperformance: Gains on GAIA are small, likely due to missing multimodality/tools. Diagnose failure cases and test multimodal ADP extensions and richer tool integration to close the gap.
- Safety and security: No protocol for permissions, capability boundaries, or sandbox policies in tool use. Add safety metadata (policy tags, PII detection flags, permission scopes) and evaluate safety‑aware training/evaluation.
- Privacy and licensing: Heterogeneous dataset licenses and potential PII are not audited. Incorporate license fields, PII filters, and compliance checks; publish a license matrix and redaction pipeline.
- Compute and efficiency reporting: Training costs (tokens, steps, GPU hours) and sample efficiency are not reported. Provide standardized efficiency metrics and scaling laws to guide practitioners.
- Base model dependence: Results rely mainly on Qwen series. Test portability across other open models (Llama, Mistral, Gemma, Phi) and report sensitivity to base model family and size.
- Evaluation breadth and metrics: Benchmarks are limited to SWE‑Bench (Verified), WebArena, AgentBench OS, GAIA. Expand to WorkArena, WebLINX, OS/database suites, UI control (desktop/mobile). Define protocol‑aligned metrics (tool‑use correctness, plan adherence, error recovery).
- Deduplication across sources: No dedup analysis across merged datasets. Implement code/text deduplication and measure its impact on generalization and overfitting.
- Schema evolution and governance: ADP versioning, migration guides, and backward compatibility guarantees are unspecified. Establish governance, versioning policy, and deprecation strategy for stable community adoption.
- Multi‑agent interactions: ADP models a single agent interacting with a user/environment. Extend schema to multi‑agent roles, communications, and coordination, and study training benefits.
- Human feedback standardization: Some sources include feedback/corrections, but ADP lacks a unified feedback schema (ratings, critiques, edits). Add structured feedback fields and evaluate process‑supervised training.
- Curriculum and difficulty: Tasks lack standardized difficulty labels. Introduce difficulty annotations and test curriculum learning vs. mixed training.
- Robustness to noise: The corpus aggregates diverse, potentially noisy sources. Quantify noise levels, run robustness ablations (e.g., filtering thresholds), and evaluate noise‑aware training methods.
- Tool execution environment parity: Mappings bridge IPython, bash, DOM, etc., but execution semantics can diverge across harnesses. Create adapter validation suites to verify semantic equivalence of actions/results after conversion.
- Community processes: The paper promises open releases but does not specify contribution guidelines, review processes, or dataset acceptance criteria. Publish contribution standards, CI checks, and a dataset registry for sustainable growth.
Practical Applications
Practical Applications of the Agent Data Protocol (ADP)
Below are actionable applications that stem from ADP’s standardized schema, conversion pipeline, and empirical results. They are grouped by timeframe and mapped to relevant sectors, with potential products/workflows and key assumptions/dependencies noted.
Immediate Applications
Industry
- Software engineering automation (software)
- What: Fine-tune small/medium LLMs into reliable code agents (e.g., IDE copilots, repo-level bug-fixing PR bots, CI/CD patchers) using the released ADP Dataset V1 or by converting internal developer-agent logs to ADP.
- Tools/workflows: ADP Data Lake → ADP→SFT connectors (OpenHands, SWE-Agent) → LLaMA-Factory training → deployment in IDE/CI.
- Evidence from paper: 7B–32B ADP-trained agents achieve large gains on SWE-Bench Verified (up to 40.3%).
- Assumptions/dependencies: Access to GPU/TPU for SFT; licensing/consent for internal data logs; robust sandboxing for code execution; ADP converters mapped accurately to in-house tools.
- Browser and back-office automation (e-commerce, operations, customer support)
- What: Train web agents to execute CRM/ERP updates, content moderation, procurement workflows, and site QA by converting internal task traces (HTML/AXTree screenshots + actions) into ADP and fine-tuning via AgentLab/BrowserGym.
- Tools/workflows: Raw logs → ADP Trajectory (APIAction + WebObservation) → ADP→SFT (AgentLab) → secure enterprise browser sandboxes.
- Evidence from paper: ADP-tuned models reach 21–23% on WebArena with 7B–32B models.
- Assumptions/dependencies: Stable DOMs/XPaths or accessibility trees; website terms of service; proper replay environments; privacy/compliance for browsing data.
- Tool-use assistants for IT and analytics (software, IT, finance, BI)
- What: Database/OS/file agents for internal helpdesk, BI report generation, and data ops, trained on heterogeneous tool logs standardized via ADP.
- Tools/workflows: Convert command/database execution trails to APIAction/TextObservation; ADP→SFT for OpenHands/AgentBench OS-like tasks.
- Evidence from paper: Large improvements on AgentBench OS (e.g., +23.6% at 7B).
- Assumptions/dependencies: Clear tool schemas; secure execution environments; audited permissions for tool invocation.
- Unified agent data engineering and observability (MLOps)
- What: Create an “Agent ETL” that normalizes all agent traces (product telemetry, user sessions, synthetic data, rollouts) into ADP, enabling reproducible SFT, versioning, and QA.
- Tools/workflows: Raw→ADP (dataset-specific converters) + automated validation checks (format, tool-thought pairings, end-of-conversation sanity) + data catalog + experiment tracking.
- Evidence from paper: ADP collapses many-to-many conversions (O(D×A)) into O(D+A), cutting integration cost and speeding experimentation.
- Assumptions/dependencies: Pydantic/Python stack; data governance approvals; quality validators adapted to org-specific tools.
- Data exchange and marketplaces (platform/software)
- What: Publish/consume agent trajectories in a common ADP format to accelerate model training across vendors or business units; establish internal “agent data hubs.”
- Tools/workflows: ADP schemas as the contract; organization-wide repository with CI validators; legal review for sharing terms.
- Assumptions/dependencies: Alignment on ADP schema versions; IP and privacy agreements; dataset documentation.
Academia
- Plug-and-play multi-dataset agent training and analysis
- What: Aggregate heterogeneous public datasets with ADP to perform large-scale SFT, cross-dataset ablation studies, and generalization research.
- Tools/workflows: Use released ADP converters and Dataset V1; swap in/out datasets with a single ADP→SFT script per agent harness; replicate benchmark results.
- Evidence from paper: Cross-task transfer beats single-domain fine-tuning on SWE-Bench, WebArena, AgentBench, GAIA.
- Assumptions/dependencies: Compute access; adherence to dataset licenses; reproducible environment setup.
- Teaching and coursework infrastructure
- What: Use ADP as a uniform format to teach agent pipelines, from data collection and conversion to SFT and evaluation.
- Tools/workflows: Classroom assignments using ADP schema, small-scale SFT with LLaMA-Factory, evaluation on open benchmarks.
- Assumptions/dependencies: Lightweight compute (or cloud credits); curated small ADP subsets.
Policy and Public Sector
- Standards-informed procurement and evaluation
- What: Require ADP-compatible datasets/telemetry in AI agent procurements to enable apples-to-apples auditing, reproducibility, and lifecycle traceability.
- Tools/workflows: Vendor reporting templates based on ADP; standardized evaluation packaging for web/OS environments.
- Assumptions/dependencies: Cross-agency agreement on schema; privacy/security requirements; benchmark hosting.
- Auditable digital service agents
- What: Log government service agent interactions (form filling, benefit eligibility steps) in ADP for oversight and red-teaming.
- Tools/workflows: ADP logs as audit trails; quality checks for tool call justification (“function thoughts”); reproducible replays.
- Assumptions/dependencies: PII redaction; legal retention rules; secure storage.
Daily Life
- Personal web and coding assistants (productivity)
- What: Turn browser macros and local coding sessions into ADP trajectories to fine-tune a personal agent that can pay bills, fill forms, or patch personal projects.
- Tools/workflows: Export from popular automation tools or IDE logs → ADP → SFT on a 7B model → desktop sandbox execution.
- Assumptions/dependencies: Technical setup tolerance; local compute or affordable cloud; careful handling of credentials/PII.
- Community-driven open datasets
- What: Contribute home-grown agent trajectories (e.g., research workflows, study tools) in ADP to open-source communities to improve small models.
- Tools/workflows: Use the ADP SDK; run validation scripts; publish with licenses.
- Assumptions/dependencies: Proper anonymization and consent; minimal legal friction.
Long-Term Applications
Industry
- Enterprise-wide agent telemetry and interoperability standard (software, platforms)
- What: Adopt ADP as an “OpenTelemetry for agents,” standardizing traces across products, vendors, and teams to enable multi-agent orchestration and vendor portability.
- Tools/workflows: ADP-driven event bus; schema versioning; cross-framework ADP→SFT and ADP→Eval adapters; monitoring/search over agent trajectories.
- Dependencies: Broad ecosystem buy-in; stable schema governance; integration with existing observability stacks.
- Sector-specific agentized workflows
- Healthcare: EHR assistants for charting, prior auth, coding, and order sets with tool calls represented as ADP APIAction.
- Finance: Straight-through processing agents for reconciliations, reporting, policy checks where tool/database calls are auditable via ADP.
- Energy/Manufacturing: Procedure-following operator assistants interacting with SCADA/CMMS APIs.
- Dependencies: Domain adapters (action/observation extensions), strong compliance regimes (HIPAA, SOX), high-fidelity simulators/sandboxes for safe training.
- Continuous learning loops and active data curation
- What: Close the loop from production agent telemetry → ADP → QA filters → curriculum sampling → frequent SFT/RLHF updates.
- Tools/workflows: Automated Raw→ADP conversion; data quality scoring; drift detection; scheduled fine-tuning; rollback mechanisms.
- Dependencies: Robust safety gates; change management; compute budgeting.
Academia
- Multimodal ADP for GUI/vision/speech/robotics research
- What: Extend ADP to images, screen recordings, accessibility trees, speech, and sensor data to unify desktop/mobile agents and embodied systems.
- Tools/workflows: ADP-MM schema; simulator bridges (e.g., BrowserGym, UI environments, robotics simulators) → ADP; multimodal SFT pipelines.
- Dependencies: Community consensus on multimodal extensions; large-scale storage and bandwidth; standardized rendering/replay.
- Standardized evaluation artifacts and “ADP-Eval”
- What: Package evaluation environments (datasets + deterministic env snapshots + expected traces) to make results comparable and reproducible.
- Tools/workflows: Containerized evals; ADP-based gold trajectories; harness-agnostic scoring.
- Dependencies: Hosting and distribution of environments; version pinning; legal rights to mirror sites/data.
Policy and Public Sector
- Auditable, certifiable agent systems
- What: Use ADP logs as the evidence substrate for external audits, safety certifications, and post-incident investigations.
- Tools/workflows: Audit pipelines that reconstruct trajectories; red-team libraries trained on ADP; conformance testing.
- Dependencies: Clear standards (NIST/ISO-like) referencing ADP or similar; secure data enclaves; standardized retention policies.
- Privacy-preserving and federated ADP
- What: Differentially private or federated variants of ADP pipelines to enable cross-institution learning without raw data sharing.
- Tools/workflows: On-prem Raw→ADP; secure aggregation; DP-aware QA; compliance dashboards.
- Dependencies: Advanced privacy tooling; governance frameworks; cross-jurisdiction harmonization.
Daily Life
- Agent app stores and plug-and-play frameworks
- What: Consumer-facing marketplaces where agents trained on ADP datasets can be swapped across hosts (desktop/mobile/web) and tool ecosystems.
- Tools/workflows: ADP as the packaging format for skills/trajectories; universal adapters; trustworthy ratings based on standardized evals.
- Dependencies: Platform policies; sandboxed runtimes; user-consent management.
- Personalized continuous fine-tuning
- What: Background logging of consenting user interactions to ADP with local, on-device SFT for privacy-first personalized assistants.
- Tools/workflows: Lightweight ADP loggers; incremental SFT/distillation; periodic validation against safety filters.
- Dependencies: Efficient on-device training; battery/thermal constraints; robust local privacy protections.
Notes on Feasibility and Risk
- Compute and cost: Even with 7B–14B models, SFT requires GPUs and MLOps maturity. Plan phased pilots with small ADP subsets.
- Data rights and privacy: Converting real interactions to ADP must respect licenses, PII, and internal policies; apply redaction and consent mechanisms.
- Domain fit: ADP v1 targets messaging, tool use, coding, and web; robotics/IoT/voice need schema extensions.
- Converter quality: Real-world performance hinges on faithful Raw→ADP mappings and ADP→SFT adapters per harness; invest in unit tests and validators.
- Generalization: Reported gains are strongest in software/web/tool domains; expect domain-dependent returns without targeted data.
- Safety: ADP’s “function thoughts” are valuable for interpretability but may expose sensitive rationale; consider filtered variants for sharing.
In summary, ADP turns fragmented agent data into a reusable, scalable substrate for training, evaluation, and governance. Organizations can adopt it today for coding, tool-use, and web agents, while the roadmap enables multimodal, sector-specific, and policy-grade ecosystems over time.
Glossary
- Accessibility tree: A structured representation of a webpage’s elements used to support accessibility and programmatic interaction. "accessibility tree of the webpage"
- ADP (Agent Data Protocol): A lightweight, standardized representation language for agent data that unifies heterogeneous datasets and downstream training. "we introduce the agent data protocol (ADP), a light-weight representation language that serves as an ``interlingua'' between agent datasets in diverse formats and unified agent training pipelines downstream."
- Agent harness: An agent-specific framework or runtime that defines action/observation formats and training/evaluation procedures. "ADP eases adaptation to new agent harnesses"
- Agent rollouts: Recorded trajectories generated by agents during task execution, used as training data. "recorded agent rollouts"
- Agent trajectory: A sequential record of an agent’s actions and observations during interaction with an environment or user. "Each ADP standardized agent trajectory is represented as a Trajectory object."
- Agent–Computer Interface (ACI): A structured interaction layer enabling agents to navigate, edit, run code, and perform software engineering tasks. "SWE-Agent introduces a custom Agent‑Computer Interface (ACI) that enables LLM agents to autonomously perform software engineering tasks"
- Agentic workflows: Multi-step, decision-driven processes where agents plan, act, and adapt across tools and environments. "general agentic workflows"
- API Actions: Structured function calls with arguments and outputs representing tool use within an agent’s action space. "API Actions: Function calls with structured parameters and outputs capturing tool use."
- Code Actions: Actions involving code generation and execution across programming languages as part of an agent’s workflow. "Code Actions: Code generation and execution across programming languages."
- Cross-task transfer: Performance gains on a target task from training on diverse, mixed-domain data rather than task-specific data. "We also identify significant benefits from cross-task transfer"
- DOM-based web interactions: Agent operations that manipulate or reason over the Document Object Model to control web interfaces. "AgentLab focuses on DOM-based web interactions."
- Function thought coverage: The proportion of tool/function calls accompanied by explicit reasoning or explanation in training data. "a striking finding is the high function thought coverage across most datasets"
- Hub-and-spoke pipeline: A conversion strategy where datasets map to a central format (hub) and then to multiple agent formats (spokes), reducing engineering effort. "ADP collapses many-to-many conversions into a hub-and-spoke pipeline."
- Interlingua: A common intermediate representation that enables translation between heterogeneous data formats. "serves as an ``interlingua'' between agent datasets in diverse formats and unified agent training pipelines downstream."
- IPython: An interactive Python execution environment used by agents for code running and tool coordination. "OpenHands employs IPython execution with web browsing capabilities"
- Message Actions: Natural language communications from the agent to users or other components, typically containing explanations or responses. "Message Actions: Natural language communications between agents and users"
- Negative transfer: A degradation in performance on some tasks caused by training focused narrowly on a single domain. "avoids the negative transfer that single-domain tuning often induces on other tasks"
- Pydantic schemas: Typed, validated data models used to define and enforce the ADP schema for actions and observations. "Technically, ADP is implemented as Pydantic schemas"
- Sandboxed execution environments: Isolated computing contexts that safely run agent code and tools without affecting the host system. "It provides sandboxed execution environments, tool coordination, and benchmark evaluation."
- Supervised fine-tuning (SFT): Post-training with labeled instruction-response pairs to adapt models to specific agent tasks and formats. "This stage converts ADP standardized trajectories into supervised fine-tuning (SFT) format"
- Text Observations: Textual inputs from users or environments captured as the agent’s perceived state. "Text Observations: Captures the text information from various sources, including user instructions and environmental feedback."
- Tool use: The agent’s ability to invoke external functions, APIs, or systems to complete tasks. "agentic tool use (AgentBench)"
- Unified schema: A single, consistent data structure that standardizes heterogeneous datasets for interoperability and scalability. "ADP establishes a unified schema that bridges the gap between existing heterogeneous agent training datasets and large-scale supervised agent fine-tuning."
- Web Observations: Structured snapshots of webpage state, including HTML, accessibility tree, URL, viewport, and optional screenshots. "Web Observations: Represent the state and content of webpages."
Collections
Sign up for free to add this paper to one or more collections.