- The paper demonstrates how RAG systems in healthcare are vulnerable to contradictory evidence, with an 18.2% drop in ROUGE-1 scores under conflicting conditions.
- It employs a temporal-citation balanced selection algorithm and diversity-aware scoring to create robust evidence sets reflecting evolving medical knowledge.
- The findings highlight the need for advanced contradiction-aware filtering strategies as even state-of-the-art LLMs degrade when exposed to conflicting inputs.
Toward Safer Retrieval-Augmented Generation in Healthcare
Introduction
The paper "When Evidence Contradicts: Toward Safer Retrieval-Augmented Generation in Healthcare" investigates the challenges faced by retrieval-augmented generation (RAG) systems in healthcare, specifically focusing on how LLMs handle contradictory information. In healthcare, LLMs can generate hallucinations or misinformation, and RAG aims to mitigate these issues by grounding model outputs in external, domain-specific documents. Despite its potential, RAG systems may introduce errors when source documents contain outdated or contradictory information. The paper evaluates five LLMs in the context of generating RAG-based responses to medicine-related queries and identifies the need for contradiction-aware filtering strategies to enhance reliability in high-stakes domains.
Methodology
Problem Formulation: The study addresses the issue of evaluating RAG's effectiveness in medical QA, where accuracy and temporal consistency are paramount. It defines a structured approach using medicine-related queries extracted from consumer medicine information documents by the Australian Therapeutic Goods Administration (TGA). The study retrieves PubMed abstracts using TGA headings, stratified across multiple publication years, to conduct a controlled evaluation of outdated evidence. The primary objectives are to assess the temporal diversity of evidence, identify contradictions, and evaluate RAG's performance in handling medicine-related queries.
Evidence Set Construction: A temporal-citation balanced selection algorithm is employed to curate evidence sets. This algorithm ensures temporal diversity and quality by ranking abstracts based on citation counts and iteratively selecting top-cited abstracts across different years. This approach aims to capture evolving medical knowledge while prioritizing high-impact research.
Diversity-Aware Scoring: The retrieval process incorporates a diversity-aware scoring mechanism using maximal marginal relevance (MMR) with temporal augmentation. This framework balances relevance, redundancy, and temporal diversity in document selection. Document embeddings are generated using a specific encoder, and temporal diversity is incorporated into the scoring to ensure a robust selection process.
Contradiction Detection: The study develops a scoring framework to quantify conflicting information among retrieved abstracts. It employs natural language inference classifiers to assess entailment and contradiction probabilities between sentence pairs, defining contradiction salience to evaluate document consistency.
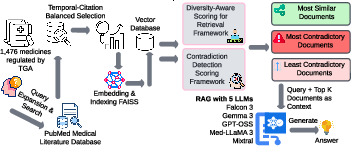
Figure 1: Contradiction-aware medical RAG pipeline, showing data progression from TGA queries through search, embedding, and three retrieval strategies to final LLM-based generation and evaluation.
Experimental Setup and Results
The experiments were conducted on a dataset comprising 8,856 query instances, linking TGA consumer medicine information with PubMed abstracts. Various retrieval configurations were tested across five LLMs: Falcon3, Gemma-3, GPT-OSS, Med-LLaMA3, and Mixtral. Evaluation metrics included lexical overlap (ROUGE), semantic similarity (BERT cosine similarity), vector similarity, and distributional divergence (JSD, KLD).
Overall Performance: The analysis revealed significant performance degradation when contradictory documents were introduced. Across models, the average ROUGE-1 score decreased by 18.2% in the most-contradictory condition compared to the most-similar condition. Semantic similarity showed greater stability, suggesting that while lexical precision decreases, models can maintain conceptual understanding.
Model-Specific Observations: Mixtral achieved the highest performance in the most-similar retrieval condition, attributed to its mixture-of-experts architecture. However, model performance consistently degraded with contradictory information, highlighting the susceptibility of larger models to conflicting inputs.
Contradiction and Diversity-Aware Score Distribution: The study revealed a significant number of documents with high contradiction scores, particularly those with moderate diversity-aware scores. This finding suggests that documents with moderate relevance are more likely to contain conflicting information.
Temporal Distribution of Contradiction Scores: The temporal analysis indicated an increasing prevalence of contradictions over time, underscoring the need for RAG systems to account for rapidly evolving biomedical literature and historical changes in clinical consensus.
Conclusion
The paper highlights the critical challenge of handling contradictory information within retrieval-augmented generation systems in healthcare. Despite RAG's promise in grounding LLM outputs with authoritative sources, unresolved contradictions significantly degrade system performance. Future work should focus on integrating sophisticated contradiction resolution strategies and temporal dynamics to ensure reliable and factual medical QA. This study serves as a benchmark for evaluating RAG robustness, emphasizing the urgent need for enhanced architectures to address contradictions in high-stakes domains.