- The paper introduces adaptive tree morphing that adjusts split criteria using gradient and information-theoretic metrics.
- The paper employs automatic problem fingerprinting to optimize tree configurations based on dataset complexity.
- The paper demonstrates a mean accuracy improvement of 0.84% over traditional models, highlighting enhanced performance and robustness.
MorphBoost: A New Paradigm in Gradient Boosting
MorphBoost introduces advanced methodologies to gradient boosting, enhancing adaptability through dynamic tree morphing. Unlike traditional frameworks with fixed structures, it employs self-organizing mechanisms that evolve during the training process to optimize decision-making based on gradient statistics and problem complexities.
Introduction
Gradient boosting has become pivotal in machine learning due to its ability to achieve state-of-the-art performance in numerous applications, particularly when dealing with structured data. Despite its success, conventional methods such as XGBoost and LightGBM utilize static tree architectures with fixed criteria for splits, leading to inefficiencies in handling dynamic gradient distributions and diverse data characteristics throughout training. MorphBoost addresses these limitations through its innovative approach, allowing split functions to evolve adaptively, thus enabling better adjustment to complex datasets.
MorphBoost Architecture
MorphBoost's architecture marks a distinct departure from static boosting frameworks, characterized by its dynamic split morphing, automatic problem fingerprinting, and optimized tree prediction capabilities.
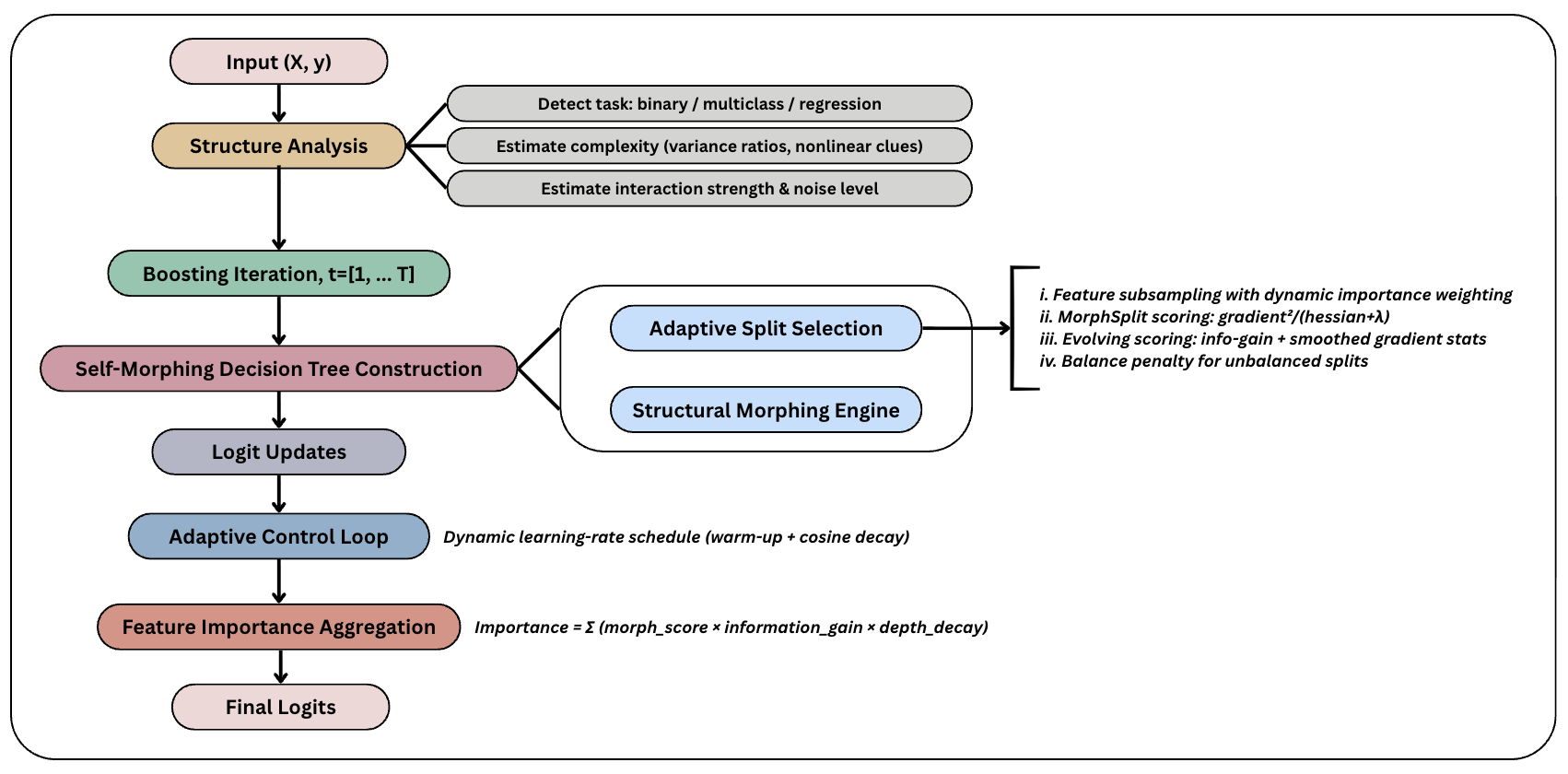
Figure 1: Overview of MorphBoost Architecture.
The algorithm adapts split evaluation criteria by combining gradient-based scores with normalized information-theoretic metrics, transitioning smoothly from aggressive early learning strategies to refined optimization as training progresses. Automatic problem fingerprinting analyzes dataset characteristics pre-training to inform parameter configuration, while vectorized tree prediction increases computational efficiency, processing sample batches simultaneously through optimized breadth-first traversal.
Algorithms and Methodologies
MorphBoost distinguishes itself with three cornerstone innovations: adaptive split morphing, automatic problem fingerprinting, and vectorized tree prediction. The morphing technique adjusts split score evaluations dynamically, incorporating gradient statistics and additional information-theoretic metrics to enhance tree evolution during training. For dataset adaptation, it uses fingerprinting processes to automatically configure parameters such as tree depth and regularization based on quantified measures of complexity and non-linearity. Vectorized tree prediction further optimizes computation, streamlining batch processing through efficient node traversal.
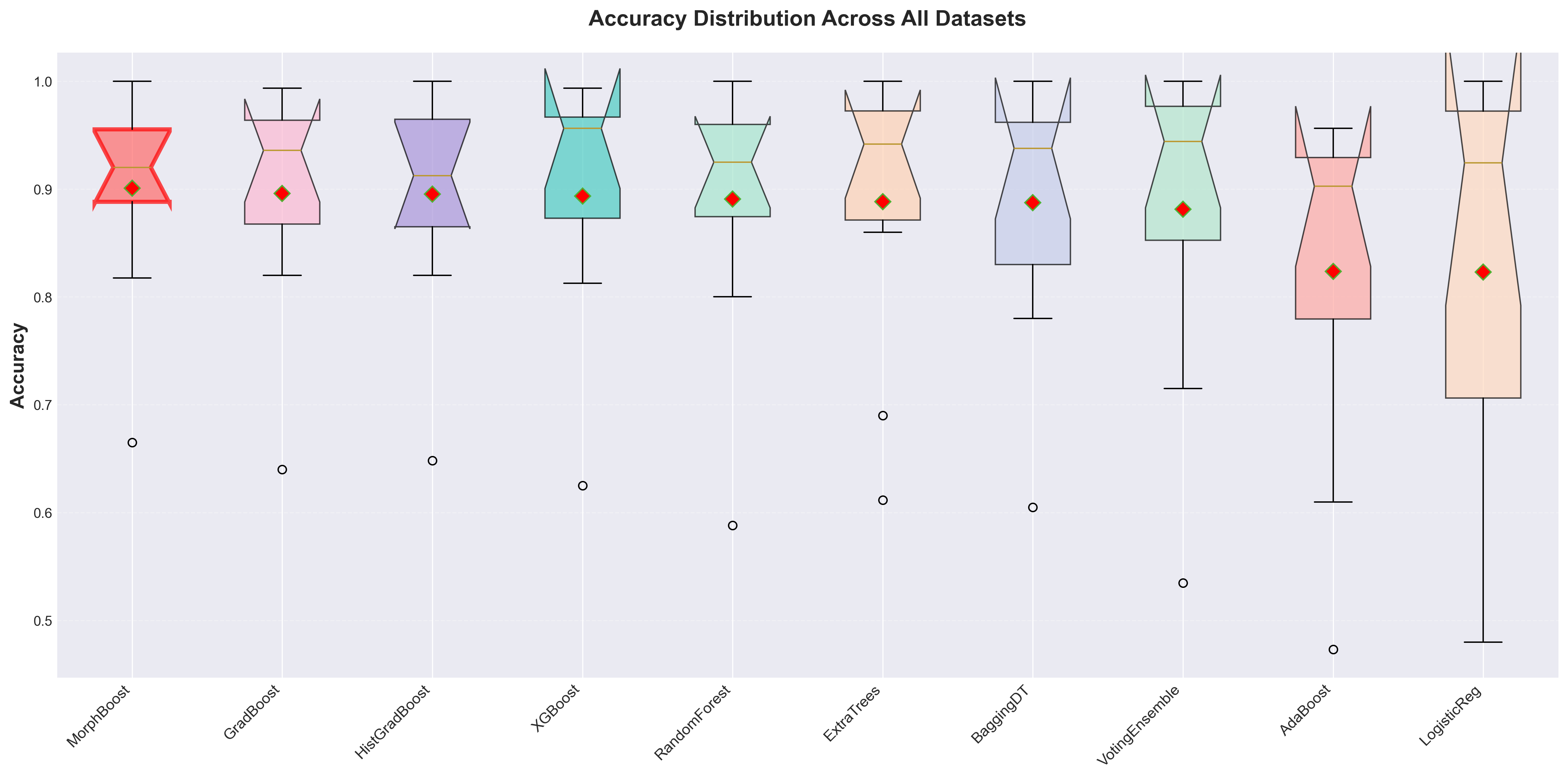
Figure 2: Accuracy distribution across all 10 benchmark datasets.
Extensive benchmarking highlights MorphBoost's superiority over existing models like XGBoost. Across 10 diverse datasets, MorphBoost demonstrated a mean accuracy improvement of 0.84% over leading models, showcasing higher consistency and robustness by maintaining lower performance variance. Particularly on complex, high-dimensional datasets, MorphBoost showed substantive improvements due to its advanced morphing capabilities.
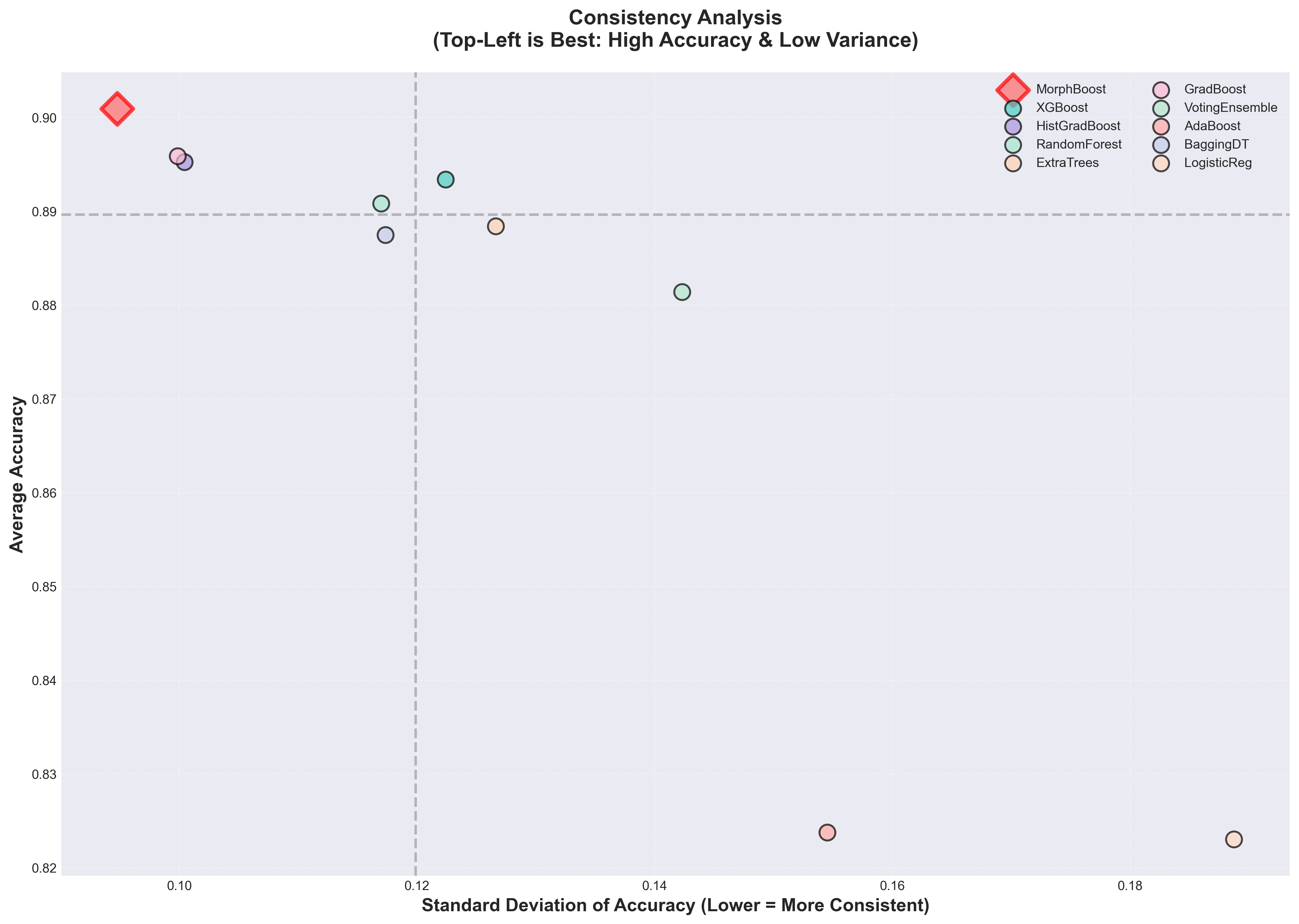
Figure 3: Model-wise performance consistency analysis.
Statistical tests confirmed MorphBoost's advantages in handling complexity variances, outperforming traditional methods with consistent high accuracy across challenging data scenarios. It achieved the highest minimum accuracy scores across all models, indicating robust generalization beyond conventional architectures.
Conclusion
MorphBoost presents a transformative approach in gradient boosting, offering a self-organizing framework that dynamically adapts its structure to evolving data characteristics. By successfully outperforming established methods across diverse datasets, it sets a new benchmark for adaptive machine learning models. Future work could explore extending these dynamic methodologies to other ensemble frameworks, implementing compiled environments for efficiency gains, and investigating theoretical underpinnings to further enhance adaptive capabilities. MorphBoost represents a significant advance towards intelligent ensemble models designed to tackle the complexities of modern data landscapes.
Figures like the accuracy distribution across benchmarks (Figure 2) or the performance radar chart (Figure 3) reinforce the effectiveness of MorphBoost’s adaptive strategies. As machine learning continues to evolve, models like MorphBoost will be crucial in navigating increasingly heterogeneous and complex problem domains.
