- The paper introduces SkipKV, which reduces memory overhead by selectively skipping key-value generation using a sentence-scoring mechanism.
- SkipKV employs an adaptive steering mechanism and batch grouping strategy to minimize redundant processing and optimize throughput.
- Benchmark evaluations show SkipKV improves accuracy by up to 26.7% while generating shorter sequences and reducing KV-cache usage.
An Essay on "SkipKV: Selective Skipping of KV Generation and Storage for Efficient Inference with Large Reasoning Models"
Introduction
The proliferation of large reasoning models (LRMs) in artificial intelligence has significantly expanded the capabilities of machines to handle complex reasoning tasks, such as mathematical derivations and code synthesis. Despite their impressive performance, LRMs face formidable challenges regarding their computational resource demands, particularly the memory overhead associated with key-value (KV) caches. This paper explores these challenges and proposes a novel approach, SkipKV, to enhance the efficiency of inference in LRMs by selectively skipping KV generation and storage.
LRMs, like DeepSeek-R1, often suffer from excessive memory consumption due to redundant reasoning traces. This has prompted the exploration of KV-cache eviction strategies to curb memory overhead without sacrificing model accuracy. Existing state-of-the-art methods suffer significant limitations in multi-batch settings, mainly due to inefficient token-wise eviction tactics that fail to maintain semantic coherence and lead to unnecessarily prolonged output sequences (Figure 1).
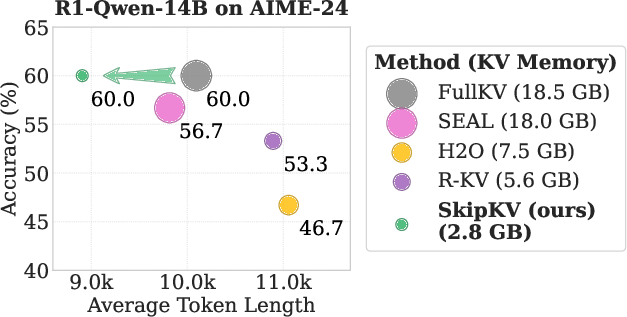
Figure 1: Comparison of KV cache eviction methods for a reasoning model. Marker size denotes KV memory usage. SkipKV yields shorter generation length while maintaining high accuracy under a smaller KV budget.
SkipKV Methodology
SkipKV innovatively integrates sentence-level redundancy detection to optimize KV-cache utilization. By relying on a sentence-scoring metric, SkipKV differentiates between tokens to strategically evict and retain those that preserve semantic integrity. This process is augmented by an adaptive steering mechanism, dynamically adjusting the skip strategies to suppress redundant generation, thereby improving both accuracy and throughput.
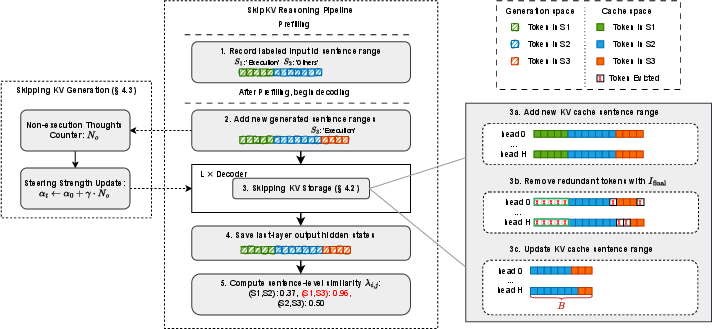
Figure 2: Overview of SkipKV framework. It selectively skips KV-cache storage and generation by leveraging sentence-level redundancy detection.
Critically, SkipKV addresses the padding inefficiency in multi-batch processing by introducing a batch grouping strategy that minimizes the insertion of padding tokens, enhancing both the effective KV budget and decoding stability. Performance evaluations reveal SkipKV achieving an impressive up to 26.7% increase in accuracy over existing methods, while consuming significantly less memory and generating shorter sequences (Figure 3).
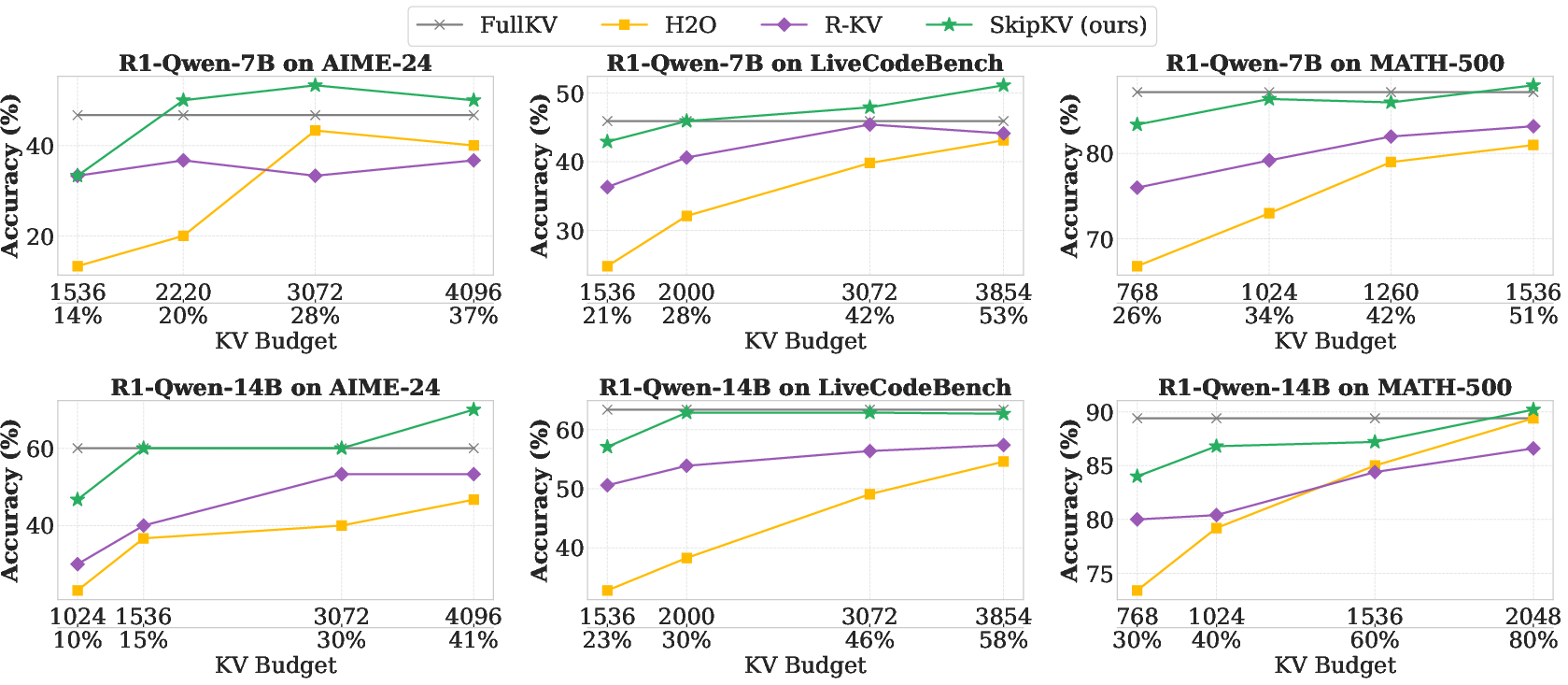
Figure 3: Accuracy comparison under different KV-cache budgets for SkipKV, H2O, R-KV, and FullKV across three reasoning benchmarks and R1-Qwen-7B and 14B models.
Results and Evaluation
Extensive benchmarking against traditional methods highlights the superior efficiency and accuracy of SkipKV. The framework consistently outperforms baselines like FullKV, yielding shorter generation lengths and leveraging substantial reductions in KV memory usage. Furthermore, empirical analysis demonstrates that SkipKV substantially reduces non-execution thoughts and high-redundancy sentence production, which traditionally contribute to inefficiencies in reasoning paths (Figures 5 & 14).
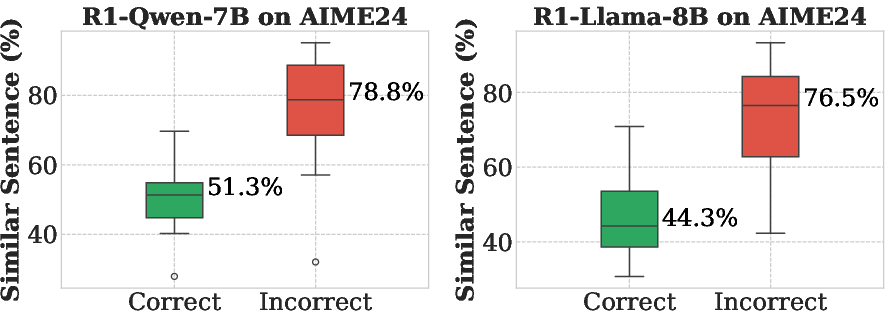
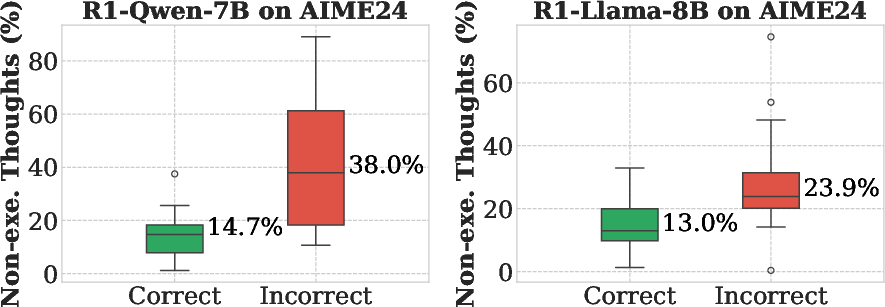
Figure 4: Statistics on the ratio of high-similarity sentences (top) and non-execution thoughts (bottom) generated for samples that the models answered correctly and incorrectly.
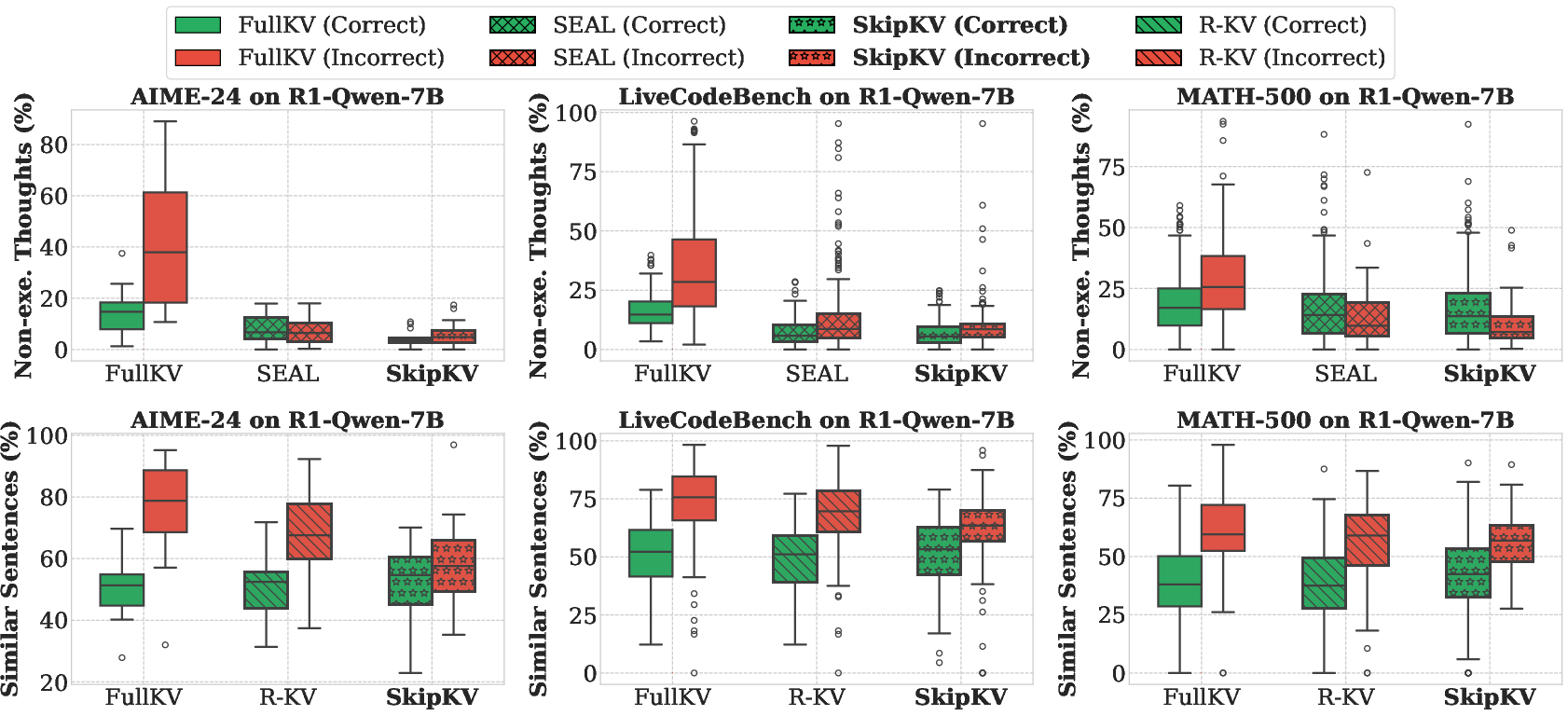
Figure 5: Comparison of the ratio of non-execution thoughts (top) and high-similarity sentences (bottom) generated by different methods.
Implications and Future Directions
The SkipKV framework embodies a pivotal advancement in the deployment of LRMs in resource-constrained environments. By alleviating the KV-cache memory bottleneck, SkipKV not only enhances computational efficiency but also broadens the practical applicability of LRMs across diverse domains—ranging from mathematical problem solving to advanced coding tasks—under tighter computational budgets.
The future of AI research will likely witness enhancements in KV-cache management techniques. Continued exploration of semantically aware evasive methods and integration with quantization strategies promise further improvements in model efficiency. SkipKV represents a foundational step toward this vision, providing a robust platform for sustained research momentum in resource-efficient AI.
Conclusion
SkipKV’s contributions mark a significant stride in addressing the KV-cache overhead challenge in large reasoning models. Through innovative sentence-scoring and adaptive steering techniques, combined with an effective batch-grouping policy, SkipKV establishes a powerful paradigm for optimizing memory usage without compromising precision or scalability. As AI applications demand increasing computational sophistication, frameworks like SkipKV will be instrumental in driving forward the deployability of intelligent systems in practical, real-world settings.