Causal Judge Evaluation: Calibrated Surrogate Metrics for LLM Systems
Abstract: LLM-as-judge evaluation has become the de facto standard for scaling model assessment, but the practice is statistically unsound: uncalibrated scores can invert preferences, naive confidence intervals on uncalibrated scores achieve near-0% coverage, and importance-weighted estimators collapse under limited overlap despite high effective sample size (ESS). We introduce Causal Judge Evaluation (CJE), a framework that fixes all three failures. On n=4,961 Chatbot Arena prompts (after filtering from 5k), CJE achieves 99% pairwise ranking accuracy at full sample size (94% averaged across configurations), matching oracle quality, at 14x lower cost (for ranking 5 policies) by calibrating a 16x cheaper judge on just 5% oracle labels (~250 labels). CJE combines three components: (i) AutoCal-R, reward calibration via mean-preserving isotonic regression; (ii) SIMCal-W, weight stabilization via stacking of S-monotone candidates; and (iii) Oracle-Uncertainty Aware (OUA) inference that propagates calibration uncertainty into confidence intervals. We formalize the Coverage-Limited Efficiency (CLE) diagnostic, which explains why IPS-style estimators fail even when ESS exceeds 90%: the logger rarely visits regions where target policies concentrate. Key findings: SNIPS inverts rankings even with reward calibration (38% pairwise, negative Kendall's tau) due to weight instability; calibrated IPS remains near-random (47%) despite weight stabilization, consistent with CLE; OUA improves coverage from near-0% to ~86% (Direct) and ~96% (stacked-DR), where naive intervals severely under-cover.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a safer, smarter way to judge and compare AI chatbots without paying huge costs for human ratings. Many teams use a cheaper AI “judge” to score chatbot answers instead of expensive human experts. That seems efficient, but the paper shows this common practice can go badly wrong: it can flip winners and losers, give fake confidence, and collapse when comparing different chatbot settings. The authors introduce a fix called Causal Judge Evaluation (CJE), which carefully calibrates the cheap judge, stabilizes tricky math, and adds honest uncertainty, making evaluation both accurate and much cheaper.
Key Questions
The paper asks three simple questions:
- Can we trust scores from a cheap AI judge to stand in for human-quality labels?
- Why do popular math tools (like importance weighting) break even when they look healthy by standard checks?
- How can we get accurate rankings and honest error bars with only a small amount of expensive labels?
Methods Explained Simply
The authors build a three-part toolkit called CJE. Think of it like tuning, balancing, and adding safety margins.
AutoCal-R: Calibrating the judge’s score
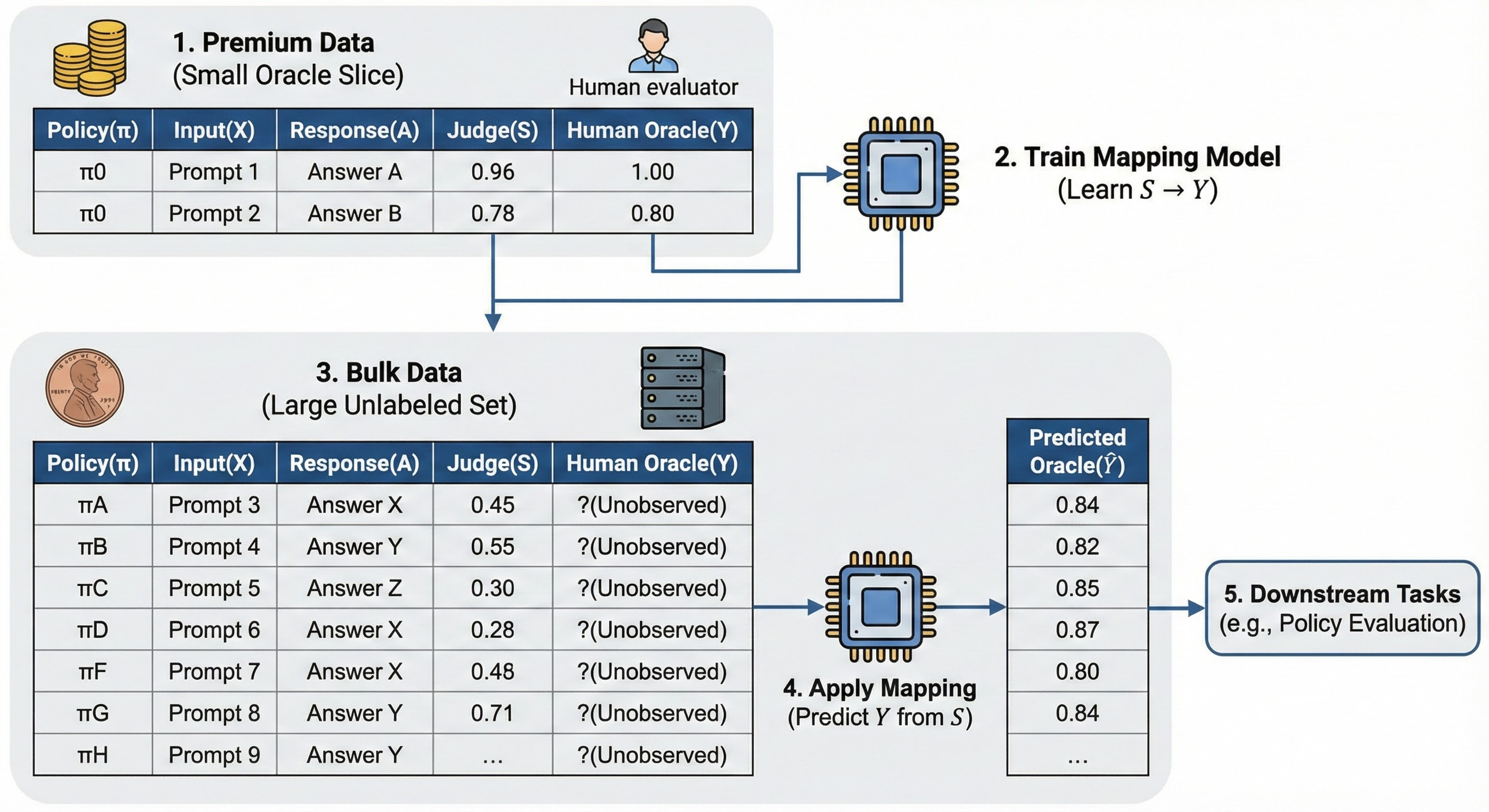
- Analogy: Imagine a thermometer that reads 5 degrees too high. Calibration is adjusting it so the reading matches the real temperature.
- What it does: It learns a mapping from the cheap judge’s score S to the “true” score Y (from expensive labels) so that higher S really means higher Y.
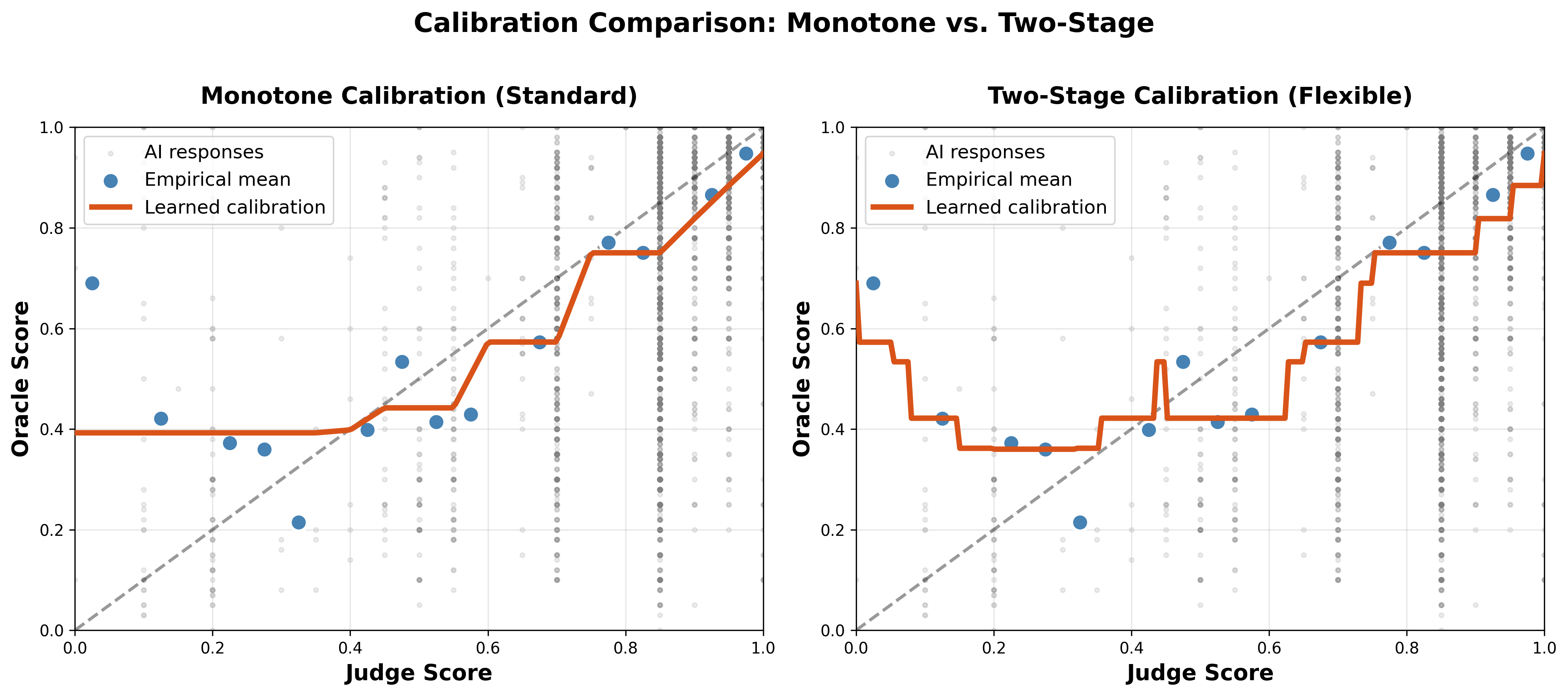
- How it stays sensible: It uses a method called isotonic regression (a curve that never goes down), which is like drawing a smooth staircase that always rises. This avoids weird jumps and keeps the average label exactly right.
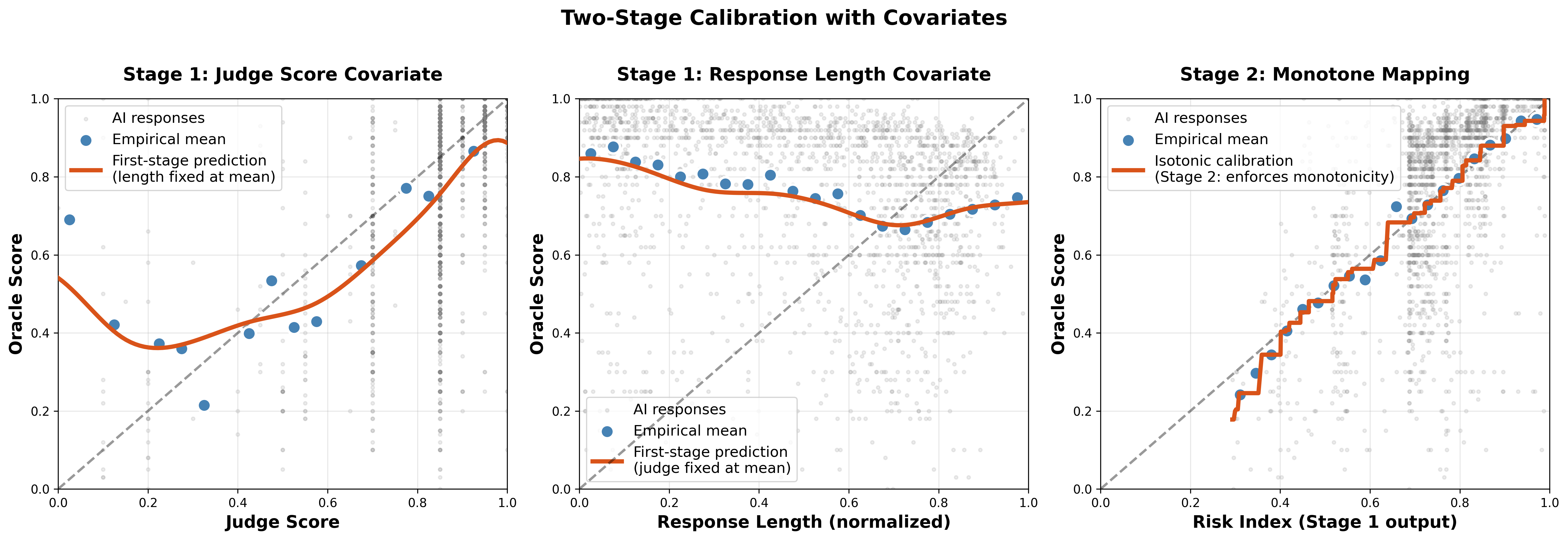
- Extra fix: If the judge is biased by things like how long the answer is, it adds a first step to account for those factors and then applies the same monotone “staircase” idea.
SIMCal-W: Stabilizing importance weights
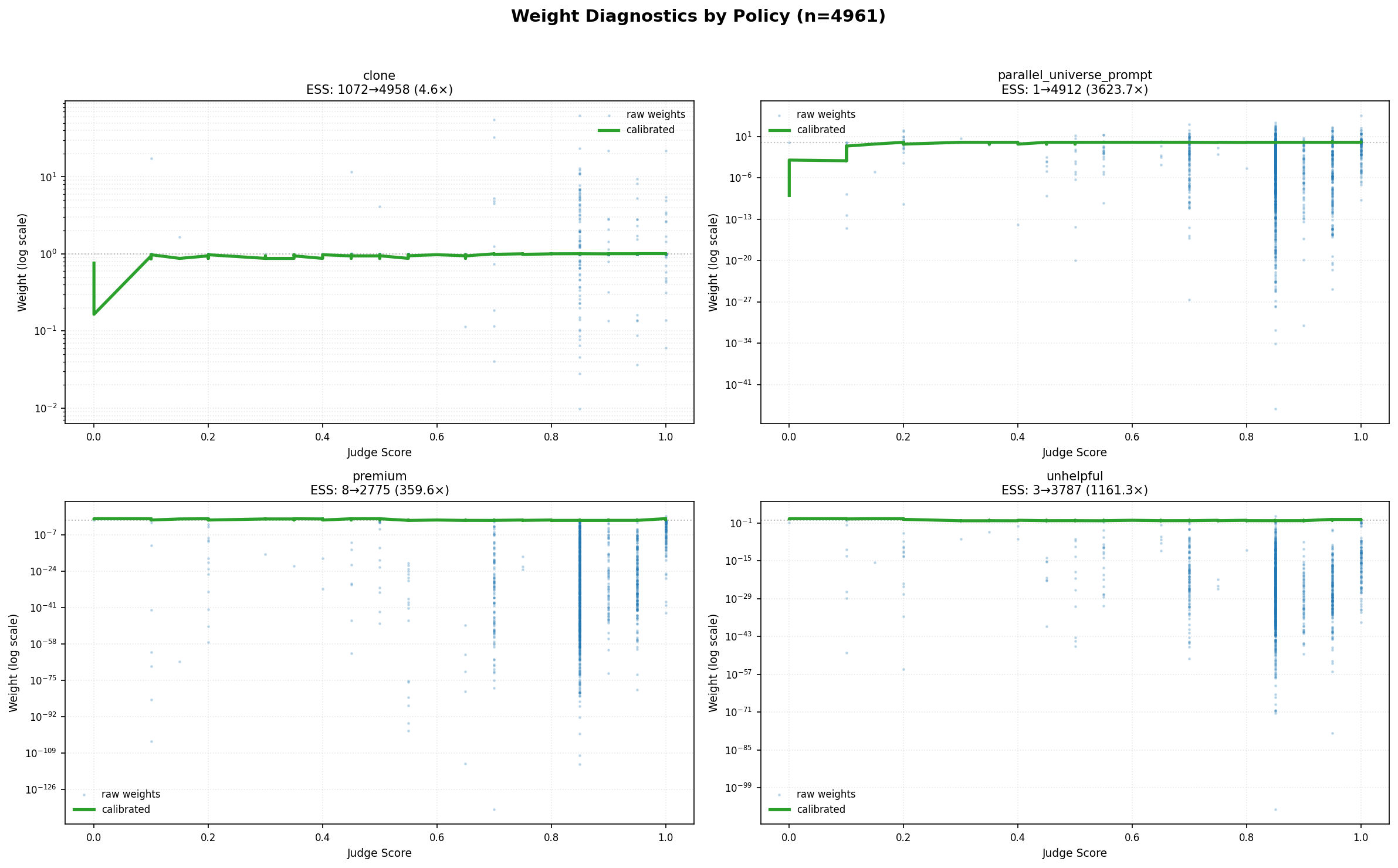
- Analogy: Suppose you’re averaging grades from different classes, but some classes count a lot more than others. Importance weights are those “counts.” If a few weights are huge, your average becomes unstable.
- What it does: It builds weights that are balanced, always average to one, and change smoothly with the judge’s score. It blends a few simple, monotone candidates to keep the variance in check and improve a metric called Effective Sample Size (ESS), which is like the “number of truly useful data points” after weighting.
OUA: Honest confidence intervals
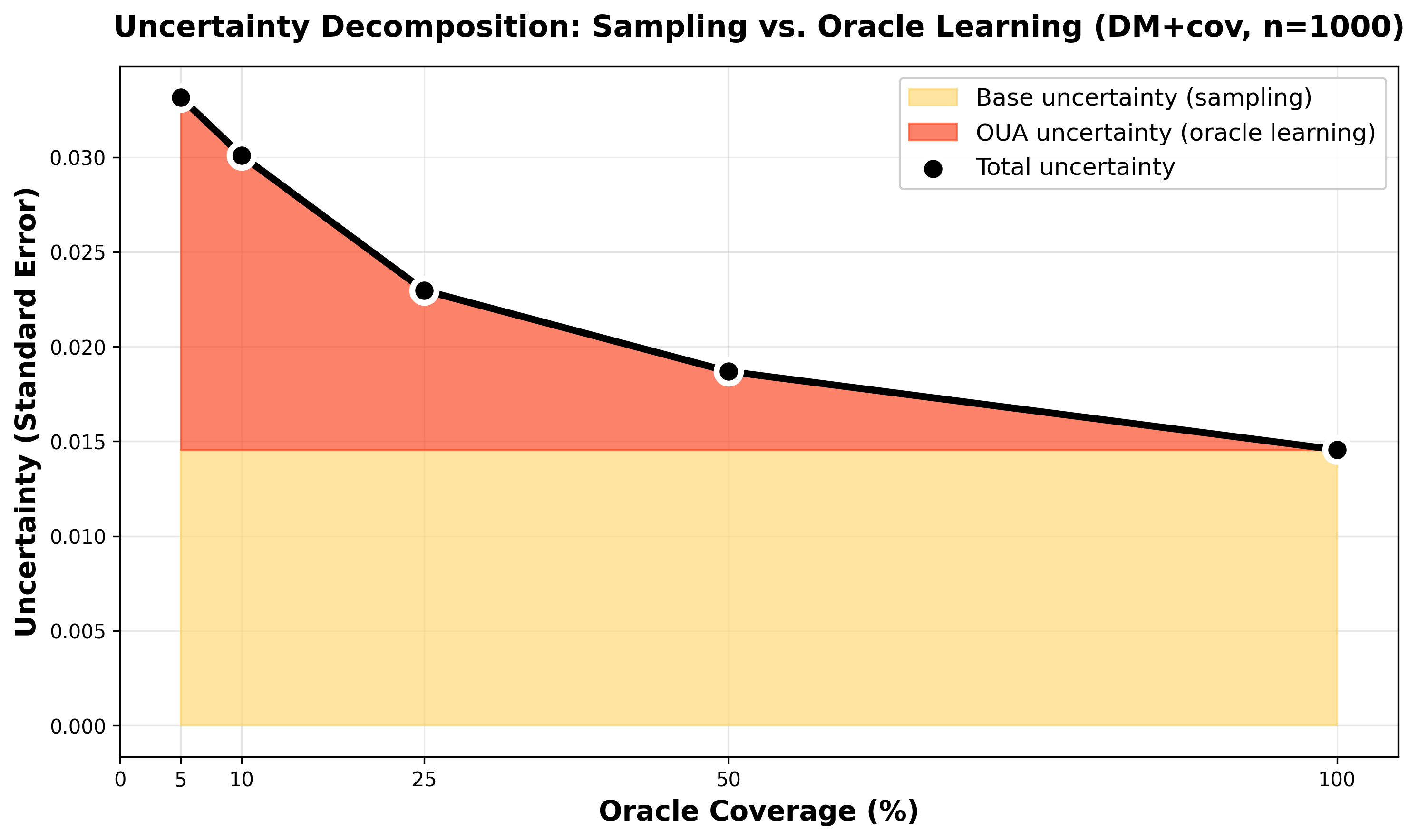
- Analogy: A confidence interval is a safety margin around your estimate. If you learned the calibration from only a small set of human labels, that adds extra uncertainty you must include.
- What it does: OUA (Oracle-Uncertainty-Aware) uses a jackknife trick: it repeatedly leaves out one fold of labels, recalibrates, and sees how much the final result changes. This captures the uncertainty from calibration so your safety margins aren’t fake-narrow.
A note on evaluation styles
- Logs-only (IPS/SNIPS): You reuse old data by reweighting it. Cheap, but risky when the old data doesn’t cover how new policies behave.
- Direct: You generate fresh answers and score them with your calibrated judge. No weights needed.
- Doubly Robust (DR): Mixes both—predicts outcomes and applies weights. In theory, it’s safer; in practice, it adds noise when overlap is poor.
Main Findings and Why They Matter
Here are the main takeaways, explained simply:
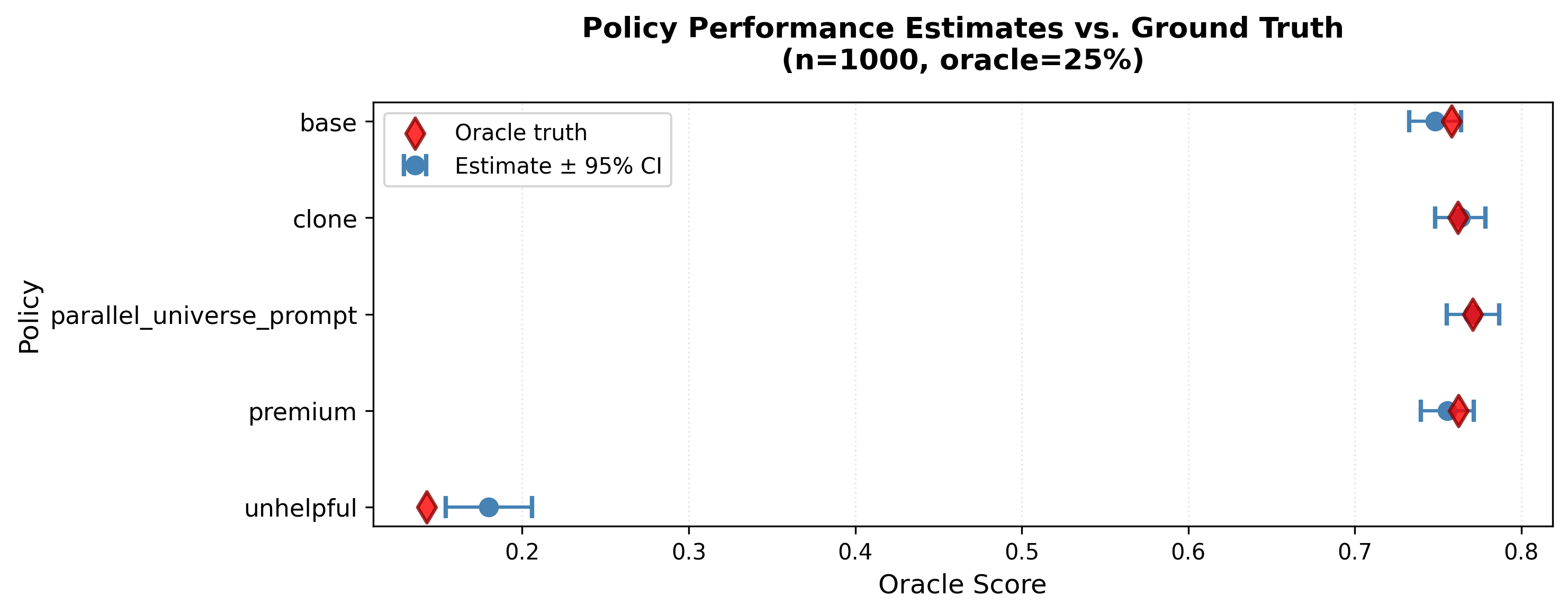
- Calibration fixes preference flips and ranking mistakes. Without calibration, the cheap judge can praise “sycophantic” responses (“You’re absolutely right!”) that users don’t actually prefer. With calibration, the system ranks policies correctly about 94% of the time on average, and up to 99% with full data, while costing about 14× less than labeling everything with the oracle.
- Honest uncertainty matters. Confidence intervals that ignore calibration uncertainty almost never include the truth. With OUA, coverage jumps to about 86% (Direct) and around 95–96% (stacked DR), which is close to the ideal 95%.
- High ESS doesn’t mean success. Even after stabilizing weights and boosting ESS above 80–90%, importance weighting still fails to rank policies accurately (near random, ~47%). Why? Coverage-Limited Efficiency (CLE): the old logger rarely visited the types of answers the new policy produces. Analogy: trying to judge the quality of forwards in soccer based on recordings that mostly show goalkeepers—the coverage is wrong, no matter how nicely you reweight.
- Direct often beats DR under low overlap. When coverage is poor, DR’s weighting piece adds noise, so Direct (fresh answers + calibrated judge) slightly outperforms.
These findings matter because they show why common shortcuts can mislead teams and how to fix them safely and cheaply.
Implications and Potential Impact
If you evaluate chatbots or other AI systems:
- Don’t trust raw judge scores. Calibrate them so “higher judge score” truly means “better for users.”
- Check coverage before using logs-only methods. If your old data doesn’t include the kinds of answers your new model produces, importance weighting will hit a hard accuracy limit (CLE). Prefer Direct or DR, and expect DR not to help when overlap is low.
- Always include calibration uncertainty in your confidence intervals. It keeps your error bars honest, especially when you used only a small amount of expensive labels.
- Use a small budget smartly. With about 5% of labels from the oracle (roughly 250 out of ~5,000 items), you can calibrate a 16× cheaper judge and still get near-oracle rankings at a fraction of the cost.
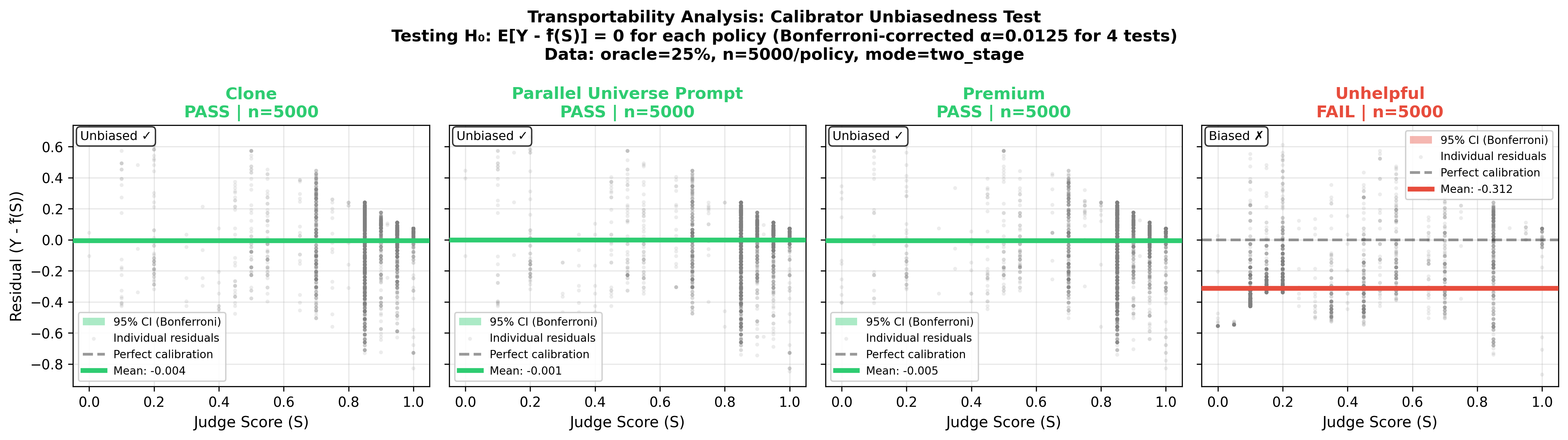
- Run a transport check. If a policy consistently shifts the relationship between judge and true scores (like the “unhelpful” policy), you’ll see a mean residual that flags the problem. Then recalibrate for that policy or rely on oracle labels for that case.
In short: CJE turns “LLM-as-judge” from a risky shortcut into a calibrated, stable, and honest evaluation system. It helps teams compare models accurately, cut costs, and avoid hidden traps that can lead to wrong decisions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that the paper leaves open, framed to guide follow-up research.
- Assumption validity for mean sufficiency: When does (or a low-dimensional index ) hold in real deployments? Develop diagnostics beyond the proposed mean-residual test (e.g., conditional calibration across subgroups/tails) and quantify the oracle sample size needed to reliably detect violations.
- Transportability across policies/environments: The mean-transport test requires an oracle slice per policy/environment. Can we design more sample-efficient tests (sequential, groupwise, or shrinkage-based) to decide when a single calibrator can be safely reused across policies, time windows, or domains?
- Oracle reliability and modeling: The oracle is GPT-5 with temperature 1.0 and no repeated labels. How much do oracle stochasticity and potential bias affect calibration and CI coverage? Develop methods that explicitly model oracle noise (e.g., measurement-error-aware calibration, repeated-rating aggregation) and propagate it through OUA.
- Human ground truth and external validity: Results rely on an automated oracle rather than human raters or downstream KPIs. Replicate the study with human-labeled datasets and real KPIs to validate cost, ranking accuracy, and coverage claims.
- Teacher-forcing propensities: Importance ratios hinge on TF log-probs and unspecified API behavior. Assess TF reliability systematically (e.g., reproducibility across APIs/versions) and design alternatives when log-probs are unavailable (e.g., learned density ratios, discriminators, or proxy propensities with guarantees).
- Coverage-Limited Efficiency (CLE) estimation and gating: The TTC threshold (e.g., 0.7) and target-typical region definition (90th percentile of per-token surprisal) are heuristic. Study sensitivity to thresholds/definitions, derive uncertainty for TTC estimates, and propose estimators for CLE factors when direct sampling from is infeasible.
- Turning CLE into actionable data collection: Provide principled logging designs that raise (logger coverage on target-typical regions), such as mixture-of-loggers, targeted exploration, or active acquisition guided by CLE, with theoretical gains (reductions in the CLE floor) and budgeted sample complexity.
- Conditions where DR strictly beats Direct: Empirically DR ≈ Direct under low overlap. Characterize regimes (via TTC, affinity, and effect sizes) where DR improves efficiency; design adaptive selectors that switch between Direct/DR/IPS based on pre-registered diagnostics with error control.
- SIMCal-W theory–implementation gap: The theoretical guarantees reference an exact IsoMeanOneS projection, while the implementation uses OOF stacking plus a variance guard. Provide finite-sample guarantees (bias/variance bounds, ESS monotonicity) for the implemented procedure and algorithms for the exact projection at scale.
- Monotonicity assumption for weight stabilization: Weights are constrained to be S-monotone. When is monotonicity in justified, and how to detect/handle non-monotonic cases? Explore richer shape constraints (e.g., piecewise monotone or isotonic in a learned index ).
- OUA inference theory for non-smooth learners: Formalize consistency and coverage for the delete-one-fold jackknife with isotonic regression (non-differentiable maps). Compare jackknife to bootstrap and influence-function–based debiasing under small oracle slices and heteroskedastic noise.
- Simultaneous inference for rankings: Extend OUA to simultaneous CIs for pairwise differences and entire rankings (top-1/top-k) with multiplicity control (FWER/FDR), acknowledging dependence across policy estimates.
- Distribution shift and adversarial robustness: The mean transport test caught a large level shift for an adversarial policy; tail/conditional miscalibration may persist. Develop tests and corrections for tail sensitivity, subgroup fairness, and adversarial manipulations that preserve ranking while controlling worst-case bias.
- Multi-objective evaluation: Many applications require vector-valued outcomes (helpfulness, safety, toxicity). Generalize CJE to multi-objective calibration, risk-sensitive functionals (quantiles/CVaR), and Pareto-aware ranking with valid uncertainty.
- Multi-turn, tool-use, and long-context settings: The benchmark is first-turn, single-response. Extend methods to multi-turn dialogues, tool-augmented responses, and long-context generation where propensities, surrogates, and calibration may vary across turns and tool calls.
- Black-box target policies: CLE/TTC uses surprisal under , requiring access to log-probs or sampling. Devise coverage diagnostics and OPE strategies for black-box targets (e.g., proxy policies, generative surrogates, or two-sample tests in surrogate space with guarantees).
- Data filtering and representativeness: About 1% of prompts were filtered for TF reliability. Quantify selection bias induced by filtering and validate that conclusions hold on unfiltered or more diverse corpora (other languages, domains, prompt types).
- Drift detection and recalibration policy: Judges drift over time. Specify drift tests (in surrogate and outcome spaces), safe reuse windows, and online/periodic recalibration schedules with budget-aware triggers and coverage guarantees.
- Multi-surrogate and multi-judge ensembling: Investigate combining multiple judges/surrogates (textual, behavioral, rubric-based) using efficiency-aware stacking and Blackwell-monotonicity to tighten bounds; study robustness to correlated surrogate errors.
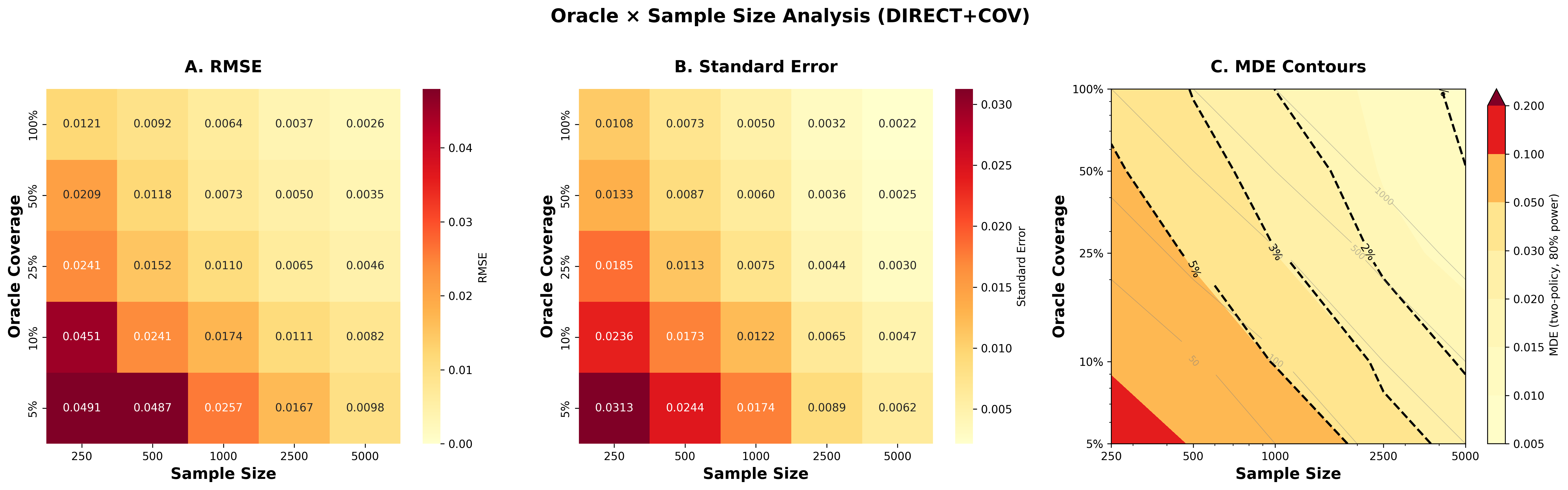
- Budget allocation in practice: The Square Root Law is presented in the appendix; evaluate empirically and extend to heterogeneous per-policy costs, non-linear pricing, and dynamic budget reallocation under sequential data collection.
- Ranking-resolution limits under CLE: Provide closed-form MDE (minimum detectable effect) curves for IPS/DR/Direct as functions of TTC, affinity, and oracle fraction, to guide practitioners in planning sample sizes and deciding when logs-only evaluation is futile.
- Feature choice in two-stage calibration: Only response length is used as a covariate. Systematically study which covariates (topic, difficulty, safety flags, stylistic markers) most reduce bias/variance without leakage, and propose automated covariate selection with OUA-aware penalties.
- Relationship between surrogate-space affinity and action-space divergence: Bhattacharyya affinity of score distributions is used as a proxy for shape mismatch. Theoretically and empirically validate its relation to the action-space term in CLE and calibrate operational thresholds.
- Heavy tails and robustness: Provide tail-index diagnostics and robustified estimators (e.g., Catoni-type or trimmed IPS/DR) with guarantees under heavy-tailed ratios and outcomes, and benchmark them under CLE-limited regimes.
- Reproducibility and broader benchmarks: Release code/artifacts and replicate on diverse datasets (coding, reasoning, multilingual, safety) to test generality of calibration, CLE gates, and OUA coverage.
- Goodharting risks: If models are optimized against calibrated surrogates, does the surrogate remain valid (surrogate paradox under optimization)? Develop guardrails (e.g., post-deployment audits, randomized oracle checks) and theory for stability under optimization pressure.
- Exact sample complexity for OUA components: Provide oracle-slice sizing rules (beyond asymptotics) for achieving target coverage and ranking accuracy as functions of estimator choice, TTC, and outcome noise.
Practical Applications
Overview
This paper introduces Causal Judge Evaluation (CJE), a unified framework for statistically sound evaluation of LLM systems using calibrated surrogate judges. It addresses three pervasive failures in current practice—preference inversion, invalid confidence intervals, and catastrophic off-policy evaluation (OPE) under limited overlap—through three components:
- AutoCal-R: mean-preserving isotonic reward calibration from judge scores to oracle quality.
- SIMCal-W: variance-optimal stabilization of importance weights via stacking of S-monotone candidates.
- Oracle-Uncertainty-Aware (OUA) inference: confidence intervals that propagate calibration uncertainty.
It further contributes:
- Coverage-Limited Efficiency (CLE): a diagnostic explaining why IPS/SNIPS estimators fail despite high effective sample size (ESS).
- Practical estimator guidance (Direct vs. DR vs. IPS), transport tests to audit calibration reuse, and an operational Square Root Law to optimally allocate budget between calibration and evaluation.
Below are actionable applications derived from these findings, grouped by timeframe.
Immediate Applications
These applications are deployable now with current tooling and the methods presented (AutoCal-R, OUA, CLE, Direct/DR estimators), assuming access to a cheap judge and a small oracle slice.
- Software/AI Product Evaluation (Software sector)
- Use case: Release gating and leaderboard ranking for chatbots, copilots, search, and summarizers using calibrated surrogate judges to approximate human or KPI ground truth at ~14× lower cost.
- Workflow: Collect ~5% oracle labels (≈250 labels for 5k samples), fit AutoCal-R, generate fresh responses, evaluate via Direct method, compute OUA CIs, apply CLE gates (TTC and Bhattacharyya) to decide Direct vs DR vs IPS.
- Assumptions/Dependencies: Small oracle slice available; judge scores accessible; prefer Direct when TTC < 0.7 or when teacher forcing/logprobs are unreliable.
- MLOps Evaluation Pipelines (Software/DevOps)
- Use case: Integrate calibration and uncertainty into CI/CD for model evaluation to prevent preference inversion and under-covered CIs.
- Tools/Workflows:
- AutoCal-R step in evaluation pipelines;
- OUA jackknife for CI coverage;
- CLE dashboard showing TTC and affinity;
- Transport test per policy/environment to validate calibrator reuse.
- Assumptions/Dependencies: Reliable judge scoring; periodic small oracle audits (50–200 labels per policy or time window).
- Prompt and Policy A/B Testing at Scale (Software, Customer Support)
- Use case: Rank prompts/policies for call-center assistants, support chatbots, or content generation using calibrated surrogate evaluation.
- Workflow: Two-stage calibration with response-length covariates to debias verbosity; Direct evaluation for new prompts; escalate low-confidence or transport failures to human review.
- Assumptions/Dependencies: Judge prone to length bias; small oracle slice; ability to generate fresh responses.
- RLHF/Reward Model Alignment (Software/AI Training)
- Use case: Align training rewards to true user value by calibrating LLM-as-judge scores to oracle targets, reducing “sycophancy” (preference inversion).
- Workflow: Pre-train calibrator on oracle slice; use calibrated reward in training/evaluation loops; monitor transport across new policies with mean residual tests.
- Assumptions/Dependencies: Mean sufficiency or a learned index Z(S,X) fits the outcome; small oracle labels; continuous recalibration under drift.
- Vendor Benchmarking and Procurement (Finance, Enterprise IT)
- Use case: Compare LLM vendors or configurations using calibrated surrogate scores with OUA CIs to support purchasing decisions.
- Workflow: Audit sample of domain-specific oracle labels; apply Direct method; present pairwise rankings with OUA CIs and CLE diagnostics.
- Assumptions/Dependencies: Domain-specific KPIs; judge access; ability to collect limited expert labels.
- Healthcare Documentation and Summarization Evaluation (Healthcare)
- Use case: Evaluate clinical note summarizers or triage assistants using calibrated surrogates to reduce expert labeling burden.
- Workflow: Small expert-annotated slice; two-stage calibration using relevant covariates (e.g., note length, section type); Direct evaluation; transport test per department/service line.
- Assumptions/Dependencies: IRB/privacy constraints; limited expert labels; scope restricted to non-diagnostic evaluation.
- Education Technology Tutor Evaluation (Education)
- Use case: Rank tutoring policies/prompts using calibrated judges, correcting for verbosity and style bias and reporting OUA CIs.
- Workflow: Collect teacher ratings on a slice; fit AutoCal-R with covariates; Direct evaluation; monitor transport across student cohorts.
- Assumptions/Dependencies: Teacher ratings available; judge access; guardrails for subgroup fairness checks.
- Content Moderation and Relevance Evaluation (Media/Search)
- Use case: Use calibrated surrogates to evaluate moderation/relevance models, with OUA intervals for trust and CLE gates determining when logs-only methods are unsafe.
- Workflow: Calibrate judge scores to human labels; prefer Direct under low TTC; DR used only when overlap is adequate.
- Assumptions/Dependencies: Limited human labels; judge reliability; overlap diagnostics run regularly.
- Policy and Governance Checklists (Public Sector, Compliance)
- Use case: Introduce procurement and oversight guidelines that require calibrated surrogates, OUA CIs, and CLE diagnostics, discouraging IPS-only evaluations.
- Workflow: Standardized templates for RFPs and audits; thresholds (e.g., TTC ≥ 0.7) to permit logs-only OPE; transport tests for calibrator reuse across departments or time.
- Assumptions/Dependencies: Institutional buy-in; minimal labeling budgets; judge access.
- Academic Reporting Standards (Academia)
- Use case: Improve reproducibility and validity in model evaluation sections by reporting OUA CIs, CLE diagnostics, and estimator selection rationale.
- Workflow: Include AutoCal-R details, oracle fraction, OUA variance decomposition, TTC/affinity metrics, and transport tests; avoid uncalibrated judge metrics.
- Assumptions/Dependencies: Access to judge; small oracle labels; adoption in peer review.
- SMB and Practitioner Model Selection (Daily life/SMB)
- Use case: Small teams compare AI assistants with a tiny human-audit set and scale evaluation using calibrated surrogates and OUA CIs.
- Workflow: 100–200 human ratings; AutoCal-R; Direct evaluation; pick top model with CI-aware thresholds.
- Assumptions/Dependencies: Minimal labeling budget; judge access; ability to generate test responses.
- Budget Optimization with the Square Root Law (All sectors)
- Use case: Minimize variance at fixed cost by balancing spend between oracle labeling and surrogate evaluation.
- Workflow: Use provided closed-form allocation to set oracle slice size; adjust dynamically based on OUA share of variance.
- Assumptions/Dependencies: Known unit costs for labels and evaluation; basic variance estimates from OUA decomposition.
Long-Term Applications
These require further research, standardization, platform integration, or broader ecosystem changes (e.g., API capabilities for teacher forcing/logprobs).
- Evaluation-as-a-Service Platforms (Software)
- Product: Hosted CJE services offering AutoCal-R, OUA CIs, CLE diagnostics, estimator stacking, and transport testing across policies and time.
- Dependencies: Secure data ingestion; judge APIs; configurable oracle workflows; multi-tenant governance.
- Industry Standards and Regulation (Policy/Governance)
- Outcome: NIST/ISO-style guidance that codifies calibrated surrogate evaluation, OUA confidence intervals, CLE gates (e.g., TTC thresholds), and transport audits for model deployment.
- Dependencies: Consensus-building; evidence of safety; regulators and standards bodies adoption.
- Adaptive Data Collection and Overlap Management (Software/AI Ops)
- Product/Workflow: Systems that detect low TTC and automatically collect targeted on-policy data or oracle labels to lift coverage, switching evaluation mode (Direct → DR) when overlap improves.
- Dependencies: Ability to execute target policies; teacher forcing/logprobs access; budget controls.
- Cross-Domain Surrogate Endpoints (Healthcare, Robotics, Recommenders)
- Outcome: Extending CJE beyond LLMs to tasks where surrogates can stand in for expensive outcomes (e.g., human ratings, safety KPIs), with domain-specific transport tests.
- Dependencies: Valid surrogates; domain-tailored calibration features; ethical oversight (especially in healthcare).
- Judge Model Design and Meta-Judging (Software/AI Research)
- Product: Specialized, monotone-friendly judge models optimized for calibratability, lower drift, and high Blackwell efficiency; ensembles stacked via influence-function variance.
- Dependencies: Training data; evaluation corpora; monitoring for drift and transport.
- MLOps SDKs and Integration (Software)
- Product: Open-source libraries implementing AutoCal-R, SIMCal-W, OUA, CLE diagnostics, transport tests, budget calculators, and estimator selection guides.
- Dependencies: Community adoption; compatibility with major ML platforms; maintainers.
- Fairness and Subgroup Transport Audits (Policy, Academia)
- Outcome: Routine transport tests and OUA CIs per demographic subgroup; calibrated surrogates tailored or gated by subgroup performance.
- Dependencies: Access to subgroup labels; privacy safeguards; audit trails.
- Reliable Teacher Forcing and Logprob APIs (AI Platform Providers)
- Outcome: Provider-level API support for trustworthy sequence logprobs to compute TTC/affinity, with documentation of reliability for evaluation.
- Dependencies: Provider engineering changes; verifiability and consistency guarantees.
- Drift-Aware, Online Calibration (Software)
- Outcome: Continual or periodic recalibration with streaming oracle labels; change-point detection; adaptive OUA to maintain CI coverage over time.
- Dependencies: Streaming feedback channels; labeling operations; efficient online isotonic methods.
- Education Assessment Modernization (Education)
- Outcome: Adoption of calibrated surrogate judges and OUA CIs in essay/scoring systems with human audits, reducing the need for full manual grading while preserving validity.
- Dependencies: Policy acceptance; evidence of fairness; teacher participation.
- Clinical AI Evaluation Frameworks (Healthcare)
- Outcome: Risk-managed use of calibrated surrogates for evaluating non-safety-critical clinical AI (e.g., documentation), with transport tests, OUA CIs, and escalation for critical use.
- Dependencies: Regulatory alignment; rigorous validation; expert oversight.
- Model Risk Management in Finance (Finance)
- Outcome: Incorporate CLE and OUA into model risk frameworks, explicitly discouraging IPS-only OPE under limited overlap; adopt stacked-DR where overlap is adequate.
- Dependencies: Regulator buy-in; internal controls; auditability.
Cross-cutting Assumptions and Dependencies
- Availability of a cheap but reasonably informative judge and a small oracle slice (5–25%).
- Access to teacher forcing/logprobs for TTC and affinity diagnostics; if unavailable, default to Direct.
- Mean sufficiency (or learned index Z(S,X)) for calibration validity; isotonic monotonicity is a modeling restriction.
- Cross-fitting and proper fold management for unbiased influence-function estimates.
- Stable API behavior; documented reliability of logprob outputs.
- Ethical, privacy, and compliance constraints when collecting oracle labels (especially in healthcare/education).
- Transport tests per policy/time/subgroup to detect calibration reuse failures; willingness to recalibrate or fall back to oracle-only evaluation when transport fails.
By adopting these applications and guardrails, organizations can immediately reduce evaluation cost while improving statistical validity, and steadily move toward standardized, adaptive evaluation ecosystems that are robust to distribution shift and overlap limitations.
Glossary
- AutoCal-R: A reward calibration method using mean-preserving isotonic regression to map judge scores to oracle labels. "AutoCal-R (reward calibration): Mean-preserving isotonic regression from judge score to oracle labels "
- Bhattacharyya affinity: A measure of overlap between two distributions, here used to assess shape mismatch in surrogate score space. "Measured by Bhattacharyya affinity in the surrogate space."
- Blackwell–efficiency monotonicity: Principle that coarser (garbled) signals cannot improve efficiency; finer surrogates yield lower variance. "If is a garbling of (i.e., ), then $Var\!\big(\phi_{\mathrm{sur}(S_1)\big)\le Var\!\big(\phi_{\mathrm{sur}(S_2)\big)$"
- Budgeted information bound: The optimal asymptotic variance achievable when enforcing a cap on weight variance. "The optimal asymptotic variance under the cap equals "
- Canonical gradient (EIF): The efficient influence function; the direction in the tangent space achieving the efficiency bound. "Let $\phi_{\mathrm{uncon}$ be the canonical gradient in the nonparametric model that does not use ."
- Carathéodory sparsity: Result that the variance-optimal convex combination of estimators uses at most r+1 components given rank r. "If has empirical rank , the variance-optimal convex combination uses at most base estimators."
- Causal Judge Evaluation (CJE): The proposed framework that unifies calibration, weight stabilization, and uncertainty-aware inference for LLM evaluation. "We introduce Causal Judge Evaluation (CJE), a framework that fixes all three failures."
- Chi-squared divergence: A divergence metric measuring shape mismatch between distributions; used inside the CLE bound. "and $\chi^2(\pi'_{\mathcal{T} \| \pi_{0,\mathcal{T})$ measures shape mismatch inside "
- Coverage-Limited Efficiency (CLE): Diagnostic explaining failure of importance-weighted estimators when logger coverage of target-typical regions is low. "We formalize the Coverage-Limited Efficiency (CLE) diagnostic, which explains why IPS-style estimators fail even when ESS exceeds 90\%"
- Cross-fitting: Sample-splitting technique to reduce bias in nuisance estimation and enable valid asymptotic inference. "All learners are cross-fitted; by the Efficiency via Model Restriction theorem, these projections encode justified knowledge that lowers the efficiency bound"
- Design-by-Projection (DbP): Design principle that encodes justified knowledge via projections onto restricted model classes to gain efficiency. "These components instantiate a single design rule, Design-by-Projection (DbP), that encodes justified knowledge as model restrictions."
- Direct Method (DM): Off-policy estimator that plugs in an outcome model averaged under the target policy. "The direct method (DM) plugs in ."
- Doubly robust (DR): Estimators that remain consistent if either the outcome model or propensity model is correctly specified. "Doubly robust (DR) estimators combine IPS and DM"
- DR-CPO (Doubly Robust Calibrated Policy Outcomes): A specific DR estimator that uses calibrated rewards and stabilized weights. "DR-CPO (Doubly Robust Calibrated Policy Outcomes)."
- Effective Sample Size (ESS): Stability metric for importance weights indicating the number of equivalent independent samples. "We monitor stability with the effective sample size (ESS),"
- Empirical cumulative distribution function (ECDF): Ranking-based transformation used in the two-stage calibration to map indices to mid-ranks. "map to mid-ranks "
- Efficiency bound: The minimal achievable variance for an estimator under a given semiparametric model. "the efficiency bound in the restricted model is at most the bound in the baseline model"
- Hilbert space: Functional-analytic setting for semiparametric theory; here, the mean-zero square-integrable space. "Let be the mean-zero Hilbert space"
- Influence function (IF): The first-order representation of an estimator’s fluctuation; used for stacking and variance estimation. "form the matrix of centered IF columns $\Phi=[\phi^{(e)}]_{e\in\mathcal{E}$"
- Inverse Propensity Scoring (IPS): Importance-weighted estimator using logged propensities to evaluate target policies. "IPS/SNIPS estimate by reweighting logged outcomes"
- Isotonic regression: Nonparametric monotone regression; Euclidean projection onto the cone of monotone functions. "Isotonic regression is the Euclidean projection onto the cone of monotone functions (PAVA)"
- Jackknife: Resampling method to estimate variance by leave-one-out (here, leave-one-fold) refits. "using a delete-one-fold jackknife"
- Kendall’s τ: Rank correlation coefficient used to assess ordering consistency between estimated and true rankings. "negative Kendall's "
- Majorization: Partial order on vectors capturing dispersion; isotonic projections weakly reduce dispersion via majorization. "it avoids extrapolation and weakly reduces dispersion by majorization"
- Mean sufficiency: Assumption that the conditional mean of the outcome depends only on the surrogate (or learned index). "Under mean sufficiency ()"
- Mean transport test: Diagnostic checking whether a calibration’s mean transports across policies or time. "Beyond variance control, CJE includes a mean transport test: for each target policy or time period, we test whether the mean residual is zero."
- MRDR: A doubly robust variant designed to improve robustness to misspecification. "For a small library of regular estimators (e.g., DR/TMLE/MRDR variants, capped IPS)"
- Off-policy evaluation (OPE): Estimating a policy’s performance using data logged under a different policy. "Standard off-policy evaluation (OPE) assumes the target policy cannot be executed."
- Orthogonal moments: Moment conditions constructed to be insensitive to nuisance estimation error, enabling valid inference. "orthogonal moments enable honest inference"
- Oracle-Uncertainty-Aware (OUA) inference: CI construction that adds calibration uncertainty to evaluation variance. "Oracle-Uncertainty-Aware (OUA) inference that propagates calibration uncertainty into confidence intervals."
- Overlap weighting: Weighting scheme emphasizing regions of covariate overlap to stabilize estimation. "Common stabilizers include truncation/clipping \citep{Ionides2008TruncatedIS}, overlap weighting \citep{LiMorganZaslavsky2018}"
- PAVA: Pool Adjacent Violators Algorithm; efficient solver for isotonic regression. "Isotonic regression is the Euclidean projection onto the cone of monotone functions (PAVA)"
- Semiparametric efficiency: Theory of optimal estimation in models with infinite-dimensional nuisances. "Building on established semiparametric theory, we show that when justified knowledge defines a restricted statistical model, the efficiency bound in the restricted model is at most the bound in the baseline model"
- SIMCal-W: Weight stabilization method stacking unit-mean S-monotone candidates with variance guards. "SIMCal-W, weight stabilization via stacking of -monotone candidates;"
- SNIPS: Sample-mean-one normalization for importance weights to reduce bias/variance. "We use the sample-mean-one normalization (SNIPS) when helpful."
- Square Root Law: Budget allocation rule balancing evaluation and calibration uncertainty to minimize variance. "A closed-form Square Root Law for optimal budget allocation"
- Surrogate endpoint: A proxy variable used to predict true outcomes; here, judge scores as surrogates for oracle labels. "Viewing as a surrogate connects to surrogate endpoints and mediation"
- Surrogate information bound: The efficiency bound attainable when conditioning on the surrogate. "with cross-fitting, our estimators attain the surrogate information bound."
- Surrogate paradox: Phenomenon where improving a surrogate metric correlating with the outcome can still harm the true outcome. "The surrogate paradox, wherein a policy improves and correlates with yet the policy harms , can arise even with high correlation"
- Surprisal: Negative log-likelihood per token, used to define target-typical regions. "let be the mean per-token surprisal."
- Tangent space: The space of score functions characterizing local model perturbations for efficiency analysis. "Let be a baseline semiparametric model with tangent space "
- Targeted Minimum Loss Estimation (TMLE): Semiparametric estimator achieving efficiency via targeted updates. "For a small library of regular estimators (e.g., DR/TMLE/MRDR variants, capped IPS)"
- Teacher forcing (TF): Technique to compute sequence-level likelihoods/ratios by forcing the model to follow observed sequences. "computed via teacher forcing (TF)."
- Target-Typicality Coverage (TTC): Estimated logger mass in target-typical regions; key coverage diagnostic in CLE. "Measured by TTC (Target-Typicality Coverage) , the estimated logger mass on ."
- Variance guard: A cap limiting the variance of stabilized weights to improve finite-sample behavior. "Light variance guard (optional; $\rho{=1$ by default)."
- Variance-optimal stacking: Convex ensembling of estimators by minimizing the variance of their combined influence function. "IF-space stacking (variance-optimal convex ensembling)"
Collections
Sign up for free to add this paper to one or more collections.