Smoothing DiLoCo with Primal Averaging for Faster Training of LLMs
Published 18 Dec 2025 in cs.LG, cs.AI, and stat.ML | (2512.17131v2)
Abstract: We propose Generalized Primal Averaging (GPA), an extension of Nesterov's method that unifies and generalizes recent averaging-based optimizers like single-worker DiLoCo and Schedule-Free, within a non-distributed setting. While DiLoCo relies on a memory-intensive two-loop structure to periodically aggregate pseudo-gradients using Nesterov momentum, GPA eliminates this complexity by decoupling Nesterov's interpolation constants to enable smooth iterate averaging at every step. Structurally, GPA resembles Schedule-Free but replaces uniform averaging with exponential moving averaging. Empirically, GPA consistently outperforms single-worker DiLoCo and AdamW with reduced memory overhead. GPA achieves speedups of 8.71%, 10.13%, and 9.58% over the AdamW baseline in terms of steps to reach target validation loss for Llama-160M, 1B, and 8B models, respectively. Similarly, on the ImageNet ViT workload, GPA achieves speedups of 7% and 25.5% in the small and large batch settings respectively. Furthermore, we prove that for any base optimizer with $O(\sqrt{T})$ regret, where $T$ is the number of iterations, GPA matches or exceeds the original convergence guarantees depending on the interpolation constants.
The paper introduces GPA, a unified optimizer that subsumes DiLoCo and Schedule-Free, achieving faster convergence with lower memory complexity.
It decouples smoothing and information integration by independently adjusting interpolation coefficients, enhancing training stability and hyperparameter transferability.
Empirical results demonstrate speedups up to 10% on LLMs and significant convergence improvements on vision models like ImageNet ViT.
Smoothing DiLoCo with Primal Averaging for Faster Training of LLMs
Introduction and Motivation
Training LLMs demands both algorithmic scalability and robust convergence properties. The DiLoCo algorithm has emerged as a practical and empirically superior optimization framework for both distributed and single-worker pretraining, leveraging a two-loop structure with periodic aggregation of pseudo-gradients via Nesterov momentum. However, the design introduces memory overhead and additional hyperparameters, complicating deployment and limiting interpretability. Recent findings demonstrate DiLoCo’s efficacy even in the non-distributed regime, yet its architectural rigidities remain a bottleneck for practical scaling and hyperparameter transferability.
In parallel, primal averaging-based optimizers such as Schedule-Free have demonstrated strong empirical performance by interpolating iterates but lack the flexibility to fully capture DiLoCo’s convergence patterns. This work proposes Generalized Primal Averaging (GPA), an optimizer that unifies and extends the primal averaging perspective, subsumes both DiLoCo and Schedule-Free as special cases, and achieves superior convergence with reduced complexity.
From DiLoCo to Generalized Primal Averaging
DiLoCo’s performance gains with increased inner steps are reminiscent of meta-learning methods (e.g., Reptile, MAML), integrating gradients at delayed, periodic intervals. DiLoCo’s Step-K Nesterov formulation couples the inner optimization trajectory with periodic outer updates, creating discontinuous information flow and necessitating two copies of model weights and the maintenance of an explicit momentum buffer. Intriguingly, empirical results indicate that performance actually improves with increased inner steps, despite the apparent reduction in information flow frequency.
GPA is proposed as a strict generalization, re-expressing Nesterov acceleration in a fully decoupled primal averaging framework. GPA introduces two independent interpolation coefficients: μy for the sequence at which gradients are computed, and μx for the sequence governing the evaluation and exponential averaging of model weights. In contrast to Schedule-Free’s uniform averaging, GPA utilizes exponential moving averaging, dropping the need for a two-loop schedule and all associated state variables of DiLoCo aside from a single additional model copy. This mechanism yields smooth, on-the-fly iteration averaging at every step instead of periodic synchronization.
Algorithmic Structure
Given a standard expected risk minimization setup, GPA structures the optimizer as follows:
Model evaluation sequence x(t) is updated via exponential moving average of the auxiliary z(t) sequence with weight μx.
Gradients are evaluated at y(t), which interpolates between x(t) and z(t) with weight μy.
The update to z(t+1) takes a step in the base optimizer’s direction at y(t).
Tuning μx and μy independently decouples the smoothing and information integration dynamics. Notably, when μy=1, GPA collapses to LaProp—resembling Polyak’s heavy-ball momentum; when μx=0, it recovers standard SGD or AdamW.
Empirical Performance
Experiments span dense Llama architectures (160M/1B/8B) and ImageNet ViT models, using AdamW as the base optimizer. The key empirical findings are:
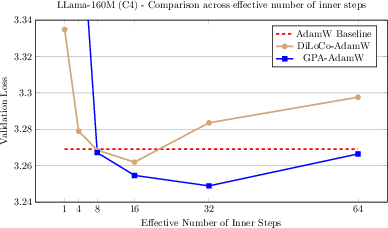
(GPA vs. DiLoCo and AdamW: Llama-160M)
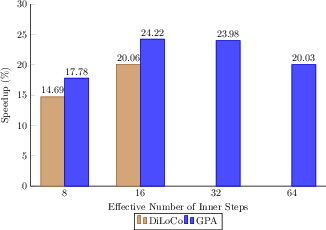
Figure 1: Both GPA and single-worker DiLoCo, using AdamW as their base, outperform the AdamW baseline for Llama-160M; GPA achieves highest speedup (8.71%) in terms of steps to reach AdamW's final validation loss.
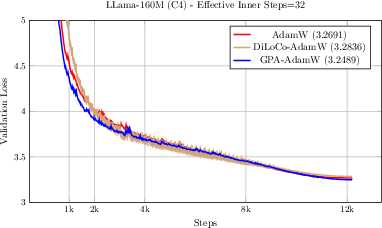
(GPA/DiLoCo/AdamW: Validation curves for fixed inner steps, Llama-160M)
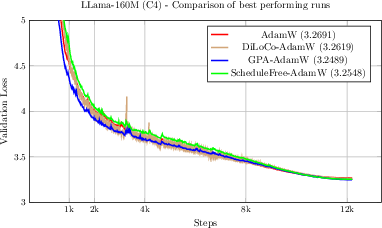
Figure 3: Validation loss for AdamW, DiLoCo, and GPA (fixed H=32) on Llama-160M, showing consistent improvement by GPA over the optimal baselines.
On Llama-160M, GPA accelerates convergence by 8.71% versus AdamW; on 1B and 8B scale models, this extends to 10.13% and 9.58%.
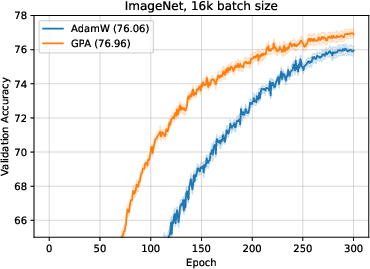
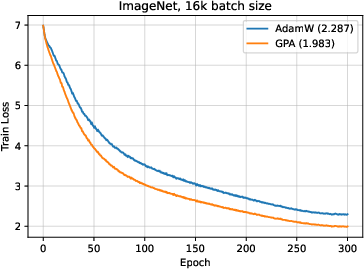
For ImageNet with ViT-S/16, GPA gives a 7% (batch size 4,096) and 25.5% (batch size 16,384) step reduction over AdamW.
(AdamW vs GPA: ImageNet ViT-S/16, large batch)
Figure 2: AdamW and GPA improvements on ImageNet ViT-S/16 (batch size 16,384); GPA converges significantly faster over all epochs.
Validation loss curves further indicate that GPA’s training paths are notably smoother and less oscillatory, evidencing stable gradient flow and more robust learning rate tolerance.
Theoretical Properties
GPA inherits and strengthens convergence guarantees from underlying base optimizers possessing O(T) regret, via an online-to-batch argument. The main result is that the average iterate achieves the same or superior asymptotic bounds as the base algorithm under convex stochastic optimization, with additional negative Bregman divergence terms that can accelerate convergence depending on parameter selection.
Crucially, GPA’s enhanced practical performance on non-convex neural objectives (e.g., LLMs, ViT-S/16) demonstrates that these theoretical properties extend to complex regimes, although a full non-convex analysis remains open.
Implementation and Resource Efficiency
GPA’s structure reduces per-iteration memory overhead relative to DiLoCo, as it avoids per-step pseudo-gradient buffers and the outer model state. Only one additional copy of the model weights is required (for z(t)), and modern memory-efficient implementations can reconstruct all necessary sequences on-the-fly, similar to running and evaluation averages in BatchNorm. Importantly, GPA subsumes DiLoCo’s effective smoothing (set by the number of inner steps) into the continuous, tunable parameter μx, supporting both discrete and continuous design spaces and facilitating better cross-architecture hyperparameter transfer.
Practical and Theoretical Implications
By generalizing the dynamics of primal averaging—and explicitly decoupling all averaging, smoothing, and information flow parameters—GPA provides a unifying theoretical lens linking DiLoCo, Schedule-Free, and classical momentum methods. This design allows for the systematic exploration of tradeoffs between step frequency, memory usage, and statistical efficiency. Practically, GPA eliminates several sources of hyperparameter interaction and obviates complicated two-loop parameter schedules, providing higher throughput, simpler deployment, and more robust transferability of optimizer settings.
For distributed and cross-regional training, GPA’s design suggests new possibilities for decoupling local step intervals from global synchronization, potentially sidestepping pathological DiLoCo behaviors where increasing inner steps unintuitively improves convergence. The decoupled smoothing regime can be tuned independently of communication intervals or local SGD epoch schedules, opening avenues for new distributed optimization algorithms better aligned with federated, asynchronous, or communication-constrained settings.
Conclusion
Generalized Primal Averaging (GPA) advances optimization for LLM and vision pretraining by subsuming and extending prior primal averaging optimizers (e.g., DiLoCo, Schedule-Free), achieving dominant empirical results with a simpler, memory-efficient, and better-theoretically-justified algorithmic core. Strong speedups on large-scale LLM and vision problems, along with decreased validation loss and increased training stability, attest to its efficacy. The theoretical analysis highlights how GPA capitalizes on negative Bregman divergence terms to surpass the base optimizer under suitable parameter choices.
Open directions include non-convex theory, broadening GPA’s compatibility with emerging base optimizers (Shampoo, SOAP, Muon), and leveraging GPA's decoupling in the design of next-generation distributed/federated optimizers. By providing a principled foundation for iterate smoothing and separation of evaluation and update dynamics, GPA represents an authoritative step in optimizing both the efficiency and scalability of deep learning pretraining.