- The paper presents TMRL, a novel fine-tuning method that integrates a dedicated temporal subspace into Matryoshka embeddings to significantly improve temporal retrieval performance.
- TMRL leverages LoRA adaptation, contrastive InfoNCE loss, and auxiliary self-distillation to ensure robust local and global semantic-temporal consistency.
- Empirical evaluations on TNP and TimeQA show TMRL outperforms full fine-tuning and multi-retriever baselines, achieving high nDCG@10 and Recall@100 at reduced embedding sizes.
Problem Formulation and Limitations of Prior Dense Retrieval in Temporal Contexts
Temporal Retrieval-Augmented Generation (RAG) systems require not only semantically relevant information but also temporally precise evidence for time-sensitive question answering. A central bottleneck in these pipelines is the retriever: semantically strong embedding models, including modern Matryoshka-based text embedding models (TEMs), exhibit poor discrimination of temporally relevant documents. Catastrophic interference arises when fine-tuning TEMs purely for temporal information, often leading to substantial degradation of general semantic retrieval capacity. Prior attempts to mitigate this—such as adopting separate temporal and semantic retrievers with query routing or external temporal signal extractors—incur significant complexity, computational overhead, and scaling limitations.
Temporal-aware Matryoshka Representation Learning (TMRL)
The central contribution, Temporal-aware Matryoshka Representation Learning (TMRL), is a parameter-efficient fine-tuning method for TEMs that introduces an explicit temporal subspace into the hierarchically nested structure of Matryoshka embeddings. TMRL employs LoRA-based adaptation and a temporal projector P operating over tokens determined to express temporal information. The first t dimensions of each embedding constitute a dedicated temporal subspace, with the remaining m−t dimensions reserved for semantic content at each truncation level—effectively yielding temporally-aware and truncatable Matryoshka embeddings.
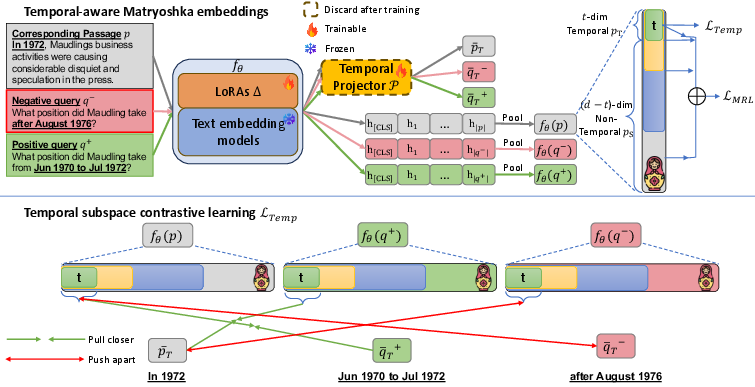
Figure 1: TMRL jointly optimizes a LoRA-adapted TEM and a temporal projector P to realize Matryoshka embeddings with dedicated temporal subspace.
A contrastive InfoNCE loss is used both on the overall embedding and on the temporal subspace. Auxiliary self-distillation objectives—pairwise similarity alignment and Centered Kernel Alignment (CKA)—ensure strong local and global structural consistency across truncation levels, boosting effectiveness at reduced embedding sizes and enforcing robust transfer of temporal signal.
Data Augmentation Pipeline for Clean Temporal Supervision
Effective temporal signal supervision in dense retrieval requires datasets where passages and queries manifest unambiguous, non-overlapping temporal expressions. The core benchmark, Temporal Nobel Prize (TNP), is substantially refined using a data augmentation pipeline: long passages are split into atomic units each with a single temporal expression, and positive/negative query pairs are generated using carefully constrained prompting of a moderate-size LLM. Allen Interval relations and a formal taxonomy of temporal question types are enforced, yielding high-fidelity temporal constraints and diverse but precise supervision.
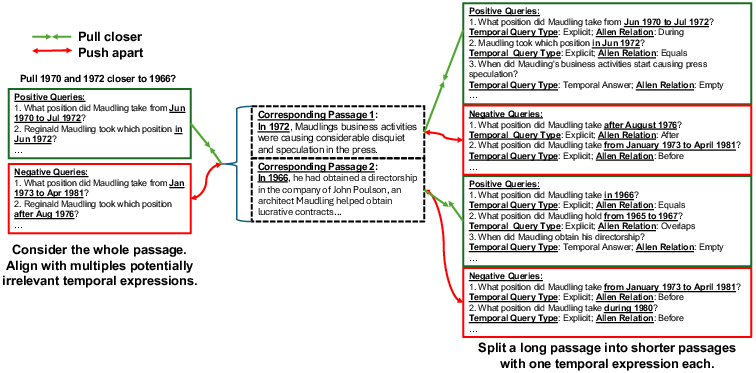
Figure 2: Comparison between original and augmented TNP datasets, enforcing single temporal expression per passage and resolving ambiguity for contrastive supervision.
Empirical Evaluation and Ablation
Evaluations are conducted on two leading temporal retrieval QA benchmarks: TNP and TimeQA. Across six widely adopted TEMs (Contriever, GTE, Nomic-Embed, BGE, etc.), TMRL consistently offers strong improvements in temporal retrieval effectiveness (measured by nDCG@10 and Recall@100), with marked robustness to truncation. Notably, TMRL embeddings demonstrate competitive or superior temporal retrieval compared to full fine-tuned temporal methods (e.g., Ts-Retriever, TempRetriever) even at substantially reduced embedding dimensions.
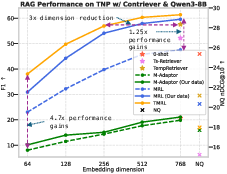
Figure 3: TMRL enables state-of-the-art RAG performance on TNP, overcoming poor retriever bottleneck irrespective of LLM reasoning capacity, with efficient storage and inference.
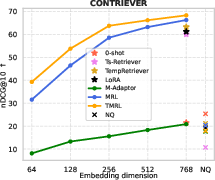
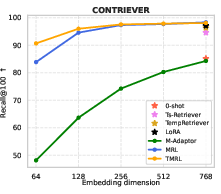
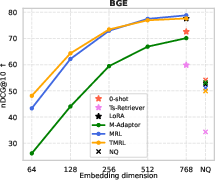
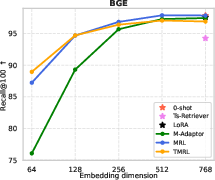
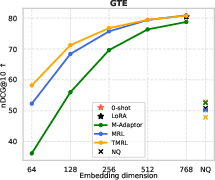
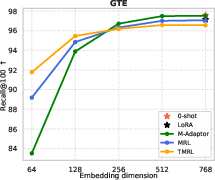
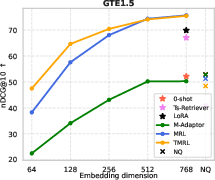
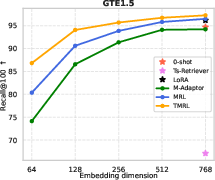
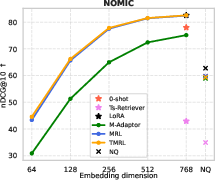
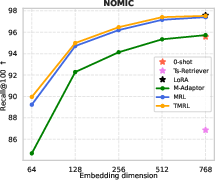
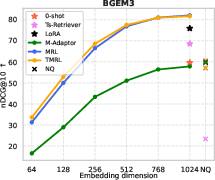
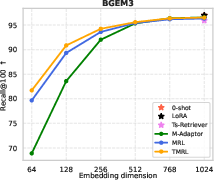
Figure 4: TMRL achieves significant improvements on TNP nDCG@10, outperforming LoRA-based MRL and other baselines, while maintaining general semantic retrieval.
Ablation studies reveal the sensitivity of temporal performance to the size of the temporal subspace t and the temporal contrastive weight α. Gains plateau beyond moderate subspace sizes (t=64 or t=128) and moderate α; excess temporal supervision can degrade general semantic retrieval. The auxiliary self-distillation terms consistently enhance local/global consistency across truncations, especially at smaller embedding sizes.
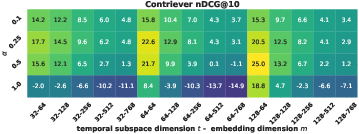
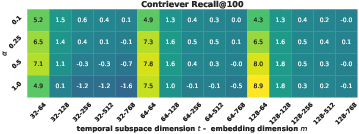
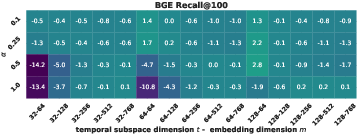
Figure 5: Ablation of t and α on TNP, highlighting efficiency/accuracy trade-off and semantic-temporal interplay.
Evaluations on TimeQA further substantiate the findings, with TMRL enabling high temporal retrieval and RAG performance at reduced embedding sizes with minimal recall degradation.
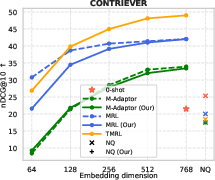
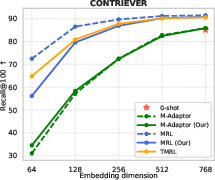
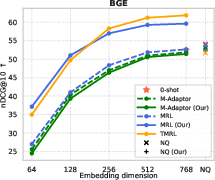
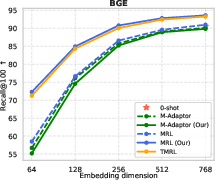
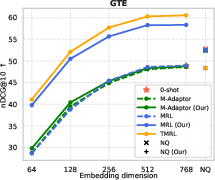
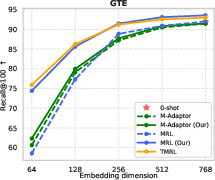
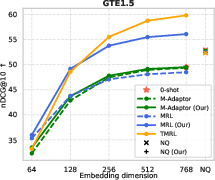
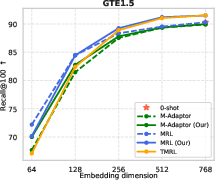
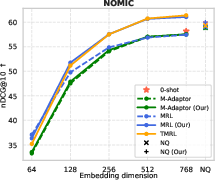
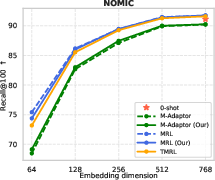
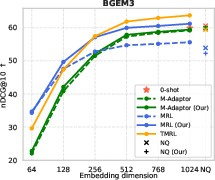
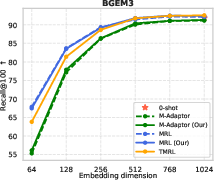
Figure 6: TMRL’s robust temporal-aware Matryoshka encoding generalizes to TimeQA, delivering strong nDCG@10 and Recall@100 across embedding scales.
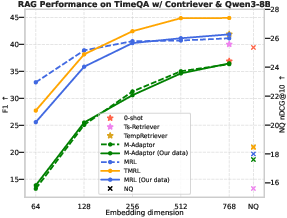
Figure 7: Temporal RAG performance trends reflect temporal retrieval improvements delivered by TMRL.
Implications, Broader Impact, and Future Developments
TMRL delivers a single, plug-and-play, parameter-efficient adaptation for temporal information retrieval, overcoming the inefficiency and practical limitations of prior multi-retriever or routing-based methods. The approach preserves performance trade-offs: it enables efficient adaptation of any Matryoshka-compatible TEM without architectural changes or increase in inference time. This is critical in real-world settings where retrieval corpora are growing, and storage/inference constraints are paramount.
Strong results on temporal benchmarks support the premise that retriever modeling—not LLM reasoning—is the principal bottleneck in temporal RAG. The explicit structuring of embeddings into a temporal and a general semantic subspace opens avenues for further subspace disentanglement, adaptive scaling of temporal capacity, and straightforward integration into broader multi-task IR/QA frameworks.
Key limitations involve dependence on high-fidelity temporal annotation (the data pipeline discards passages with multiple temporal expressions, so real deployment will require extensions to ambiguous/multi-expression cases). Extending TMRL to LLM-based embedding models and more heuristically variable datasets remains a critical future direction. Additionally, the explicit subspace allocation strategy may benefit from meta-learning or dynamic allocation based on query statistics.
Conclusion
Efficient Temporal-aware Matryoshka Adaptation for Temporal Information Retrieval introduces a robust, extensible, and efficient method for equipping state-of-the-art dense retrievers with strong temporal discrimination capacity. The method enables single-model, truncation-robust temporal retrieval, surpasses full fine-tuning and multi-retriever baselines, and facilitates scalable RAG systems resilient to temporal drift. The presented augmentation pipeline for clean supervision further strengthens practical deployment. TMRL establishes a foundation for future temporal-aware retrieval systems with extensibility to other verticals and subspaces (2601.05549).