- The paper introduces a novel cross-view localisation method combining domain-robust semantic segmentation with a dual-encoder network.
- It employs particle filtering to integrate visual cues over time, significantly improving performance over synthetic-only baselines.
- The approach enhances rover autonomy in GPS-denied planetary terrains by effectively bridging synthetic-real domain gaps.
Vision Foundation Models for Domain Generalisable Cross-View Localisation in Planetary Ground-Aerial Robotic Teams
Introduction
The relentless pursuit of autonomy in planetary exploration relies on accurate localisation of robotic agents, a stark challenge compounded in environments devoid of GPS signals. The integration of visual localisation techniques using ground-view images and pre-collected aerial maps presents a promising frontier, inspired by the successes of helicopter and orbiter deployments in prior missions. This paper explores map-based, cross-view localisation for rovers leveraging ground and aerial imagery, facilitated by vision foundation models and semantic segmentation to overcome data paucity and domain gaps.

Figure 1: Full rock segmentation pipeline using LLMDet and SAM~2.
Planetary Navigation and Localisation: Historically, planetary rover localisation has hinged on visual odometry and feature-based map matching. While effective, these methods grapple with cumulative drift. Recent paradigms involve matching ground imagery against broader maps for more stable localisation.
Deep-Learning-Based Cross-View Localisation: Cross-view localisation flourishes within both terrestrial and planetary domains, typically employing dual-encoder architectures that harmonise ground-level views with aerial insights. However, the scarcity of labelled space data necessitates reliance on synthetic imagery, undermining generalisation due to domain discrepancies.
Semantic Segmentation and Object Detection: Semantic segmentation, imperative for terrain analysis and localisation, is enhanced through vision foundation models like LLMDet for object detection and SAM~2 for segmentation, mitigating domain variability without bespoke training.
Methodology
The methodology pivots on three pivotal elements: semantic segmentation to bridge domain gaps, a dual-encoder neural architecture for cross-view localisation, and particle filtering for continuous state estimation.
Domain-Robust Input via Rock Segmentation: Semantic segmentation using foundation models LLMDet and SAM~2 (Figure 1) transforms ground-view images, segmenting rock features to counteract domain disparities. This pipeline ensures robust feature extraction across synthetic and real data.
Dual-Encoder Network for Cross-View Embedding: Drawing from TransGeo, a dual-encoder architecture encodes images into a unified feature space, facilitating localisation through similarity metrics (Figure 2). The model is trained using a triplet loss framework to enhance cross-domain adaptation.
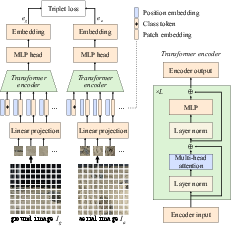
Figure 2: Dual-encoder cross-view localising network structure, adapted from \autocite{zhu.etal.2022_transgeo.
Particle Filtering for State Estimation: Integrating observations over time, the particle filter uses embeddings to update rover states within a geo-referenced aerial map. Bearing and positional changes are stochastically predicted, enabling precise trajectory tracking across complex paths (Figure 3).
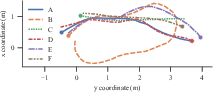
Figure 3: The six trajectories, A to F, used in the validation set for evaluating our particle filter. The start point of each is marked with a circle.
Dataset
A novel dataset juxtaposes real-world rover trajectories within a planetary analogue facility with synthetic imagery from PANGU. This dataset enriches AI training pipelines with high-resolution map associations.
Laboratory-Collected Data: Captured in controlled environments, the real dataset provides accurate localisation benchmarks, pairing rover trajectories with aerial images calibrated using OptiTrack systems.
Synthetic Data: PANGU-generated datasets mimic real-world scenes under variable lighting and terrain configurations, overcoming real data limitations with extensive synthetic pairings.

Figure 4: Examples of ground view (bottom) and rectified aerial view (top) images in our planetary analogue dataset.
Experiments
Evaluations underscore the efficacy of the cross-view localisation method across contrasting data regimes.
Domain-Robust Rock Segmentation: Automatic segmentation outpaces manual efforts, proving particularly adept at bridging synthetic-real disparities (Figure 5).

Figure 5: Qualitative examples showing the success of the LLMDet + SAM~2 segmentation on a real Mars image (top left), real planetary analogue image (top right), and synthetic image (bottom).
Dual-Encoder Cross-View Embeddings: Networks trained on synthetic images reveal limited generalisation, yet semantic segmentation augments real-data localisation, addressing domain gaps innovatively.
Particle Filtering for State Estimation: Performance metrics manifest stark improvements against synthetic-only baselines. Semantic segmentation bolsters localisation accuracy, outperforming naïve approaches—a testament to the method's robustness against domain variability (Figure 6).
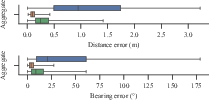
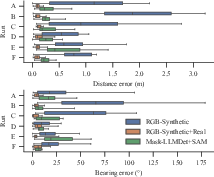
Figure 6: Comparison of the distribution of particle filter range and bearing errors at each timestep in aggregate and separated by run.
Conclusions
This paper affirms the viability of employing cross-view localisation for planetary rovers within constrained visual setups, leveraging domain-adapted segmentation to bypass data limitations. Enhanced localisational insights promise heightened autonomy, paving pathways for integrating traditional odometry with map-based corrections in future exploration missions. Continued innovation toward efficient network scaling—and the integration of more complex data fusion—could elevate these foundational insights into broader operational viability across heterogeneous mission terrains.
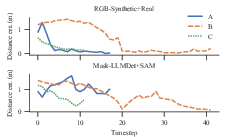
Figure 7: Distance error over time for known-bearing, unknown-location particle initiation across runs A to C.
Future directions may encompass network optimisations for inference on space-grade hardware and integrated navigation systems, marrying relative and absolute position approximations for unprecedented robotic autonomy.