- The paper introduces a unified framework leveraging a 109M audio-text pair corpus to process variable-duration audio up to 30 seconds using multi-objective training.
- It employs a redesigned transformer-based audio encoder with hybrid local and global attention mechanisms, ensuring dense and robust audio representations.
- Experimental results show SOTA performance in retrieval, classification, captioning, and tagging tasks, setting a new standard in language-audio pretraining.
Scalable Language-Audio Pretraining with Variable-Duration Audio and Multi-Objective Training: An Expert Review
Introduction and Motivation
SLAP (Scalable Language-Audio Pretraining) presents a substantial evolution over prior CLAP architectures, primarily by overcoming limitations in dataset scale, audio duration flexibility, and training objective granularity. Existing CLAP variants often operate on restricted datasets (millions of samples, compared to CLIP's billion-scale), employ audio encoders pretrained on limited-duration inputs, and are confined to global contrastive loss, thus impeding fine-grained feature representation. SLAP addresses these deficiencies by leveraging a 109M audio-text pair corpus, supporting variable-duration audio up to 30 seconds, and integrating a unified single-stage multi-objective regime. This results in robust, dense, generalizable audio representations suitable for both unimodal and multimodal tasks.
SLAP Model Architecture and Training Framework
The audio encoder in SLAP is built upon ViT but is extensively reengineered for audio modality. Salient modifications include 2D Rotary Positional Embedding (RoPE) for temporal-spectral structuring, RMSNorm, bias-free linear layers, and the stabilizing SwiGLU activation. To efficiently process long sequences, SLAP incorporates an alternating attention block paradigm—interleaving sliding-window local attention (for computational efficiency and local feature capture) with periodic global attention blocks (to model cross-segment dependencies and capture global context). This hybrid mechanism enables support for variable durations while maintaining fidelity in both micro and macro representation spaces.
Efficient Handling of Variable-Duration Audio
SLAP deploys a sequence packing strategy where mel-spectrograms are partitioned into non-overlapping patches, subsequently concatenated while omitting padding, to produce packed batch inputs. This is processed as a unified long sequence via Flash Attention, circumventing quadratic attention scaling issues and minimizing inter-sample padding. Compared to approaches such as ElasticAST, this yields improved flexibility, computational efficiency, and scale.
Multi-Objective Unified Training
Unlike prior multi-stage pipelines, SLAP unifies contrastive, self-supervised, and captioning objectives in a single training stage (illustrated in Figure 1).
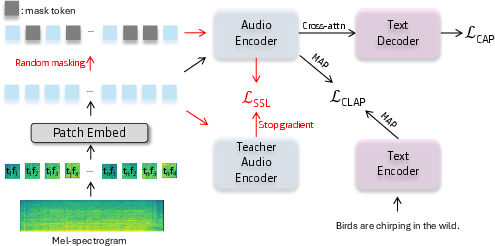
Figure 1: High-level overview of the unified SLAP framework, with explicit annotation of the self-supervised learning flow (in red).
- Contrastive Loss: Adopts CLAP’s bidirectional global representation alignment, using multi-head attention pooling for more expressive aggregation versus class token pooling.
- Self-Supervised Loss: Implements masked audio modeling with an EMA-updated teacher-student architecture. Random patches are masked; student features are matched to teacher prototypes via cross-entropy on softmax-normalized outputs, supporting dense representation learning.
- Captioning Loss: Utilizes a shallow Transformer decoder, trained from scratch, using teacher-forcing to maximize the conditional likelihood of each caption token based on the audio encoder output. This auxiliary loss further semanticizes patch-level features.
- Loss weights (α,β,γ) are empirically selected for optimal trade-off.
Experimental Results
Audio-Text Retrieval
SLAP attains SOTA retrieval scores on AudioCaps (R@1: 47.5%, R@5: 79.8%, R@10: 89.2%) and Clotho (R@1: 27.2%, R@5: 55.9%, R@10: 68.3% for text-to-audio; audio-to-text scores are even higher), outperforming prior CLAP and multi-objective methods. Gains are attributed to both dataset scale and the model’s ability to ingest variable-length audio without truncation/cropping, preserving contextual integrity.
Zero-Shot Audio Classification
Performance is benchmarked on ESC-50, UrbanSound8K, CREMA-D, RAVDESS, and GTZAN. After fine-tuning on WavCaps, SLAPWavcaps achieves top-1 accuracy of 95.5% (ESC-50), 83.5% (US8K), 32.2% (CREMA-D), 29.8% (RAVDESS), and 80.5% (GTZAN), demonstrating superior transferability, especially when additional weakly-labeled data is available for finetuning. Notably, raw SLAP pretraining underperforms slightly compared to models trained on cleaner captions, highlighting the impact of annotation quality in pretraining data.
Audio Captioning
Even with a lightweight decoder and low captioning loss weight, SLAP matches or overtakes previous CLAP-based models in METEOR, CIDEr, and SPICE metrics. On AudioCaps, SLAP scores 24.9 (METEOR), 75.1 (CIDEr), and 18.1 (SPICE); on Clotho, 18.1, 43.7, 13.1, respectively. This validates the efficacy of multi-objective training for semantic feature enrichment.
Audio Tagging
SLAP achieves competitive results in mean average precision and accuracy across AudioSet, ESC-50, and SPC-2, surpassing BLAT and closely rivaling M2D2 (with minor variation due to self-supervised pretraining differences).
Ablation Analysis
Removal of self-supervised or captioning losses significantly degrades performance on retrieval benchmarks, confirming that dense and semantic objectives are crucial. Excluding local attention causes a modest drop, validating the attention mechanism choices.
Practical and Theoretical Implications
SLAP’s architecture sets a precedent for highly scalable multimodal pretraining in the audio domain, comparable to advances in vision-LLMs. The ability to process variable-length inputs removes a longstanding barrier to real-world deployment, especially for applications involving unstructured audio streams. Dense, unified representations offer improved performance for retrieval, classification, tagging, and captioning tasks, and simplify downstream adaptation. The results highlight the necessity of large-scale, flexible, and multi-objective pretraining—suggesting that further gains may be realized by scaling both dataset size and annotation quality.
Future Directions
Possible avenues for extension include:
- Incorporating external knowledge or domain-specific metadata during pretraining, potentially via joint training with expert-labeled subsets.
- Developing more sophisticated annotation pipelines (e.g., leveraging generative LLMs with audio context for higher caption fidelity).
- Exploring hierarchical temporal modeling to better capture long-range dependencies in audio.
- Adapting the framework for other modalities (e.g., video-audio-language triple alignment).
- Investigating robustness to noisy or adversarial inputs, given the scale and diversity of pretraining data.
Conclusion
SLAP holistically advances the state-of-the-art in scalable language-audio representation learning by combining dataset magnitude, variable-duration flexibility, and unified multi-objective training. Its empirical performance on diverse benchmarks demonstrates its efficacy and broad transferability, establishing new standards for multimodal audio understanding architectures and serving as a strong foundation for future research and practical adoption.