Auditory Brain Passage Retrieval: Cross-Sensory EEG Training for Neural Information Retrieval
Abstract: Query formulation from internal information needs remains fundamentally challenging across all Information Retrieval paradigms due to cognitive complexity and physical impairments. Brain Passage Retrieval (BPR) addresses this by directly mapping EEG signals to passage representations without intermediate text translation. However, existing BPR research exclusively uses visual stimuli, leaving critical questions unanswered: Can auditory EEG enable effective retrieval for voice-based interfaces and visually impaired users? Can training on combined EEG datasets from different sensory modalities improve performance despite severe data scarcity? We present the first systematic investigation of auditory EEG for BPR and evaluate cross-sensory training benefits. Using dual encoder architectures with four pooling strategies (CLS, mean, max, multi-vector), we conduct controlled experiments comparing auditory-only, visual-only, and combined training on the Alice (auditory) and Nieuwland (visual) datasets. Results demonstrate that auditory EEG consistently outperforms visual EEG, and cross-sensory training with CLS pooling achieves substantial improvements over individual training: 31% in MRR (0.474), 43% in Hit@1 (0.314), and 28% in Hit@10 (0.858). Critically, combined auditory EEG models surpass BM25 text baselines (MRR: 0.474 vs 0.428), establishing neural queries as competitive with traditional retrieval whilst enabling accessible interfaces. These findings validate auditory neural interfaces for IR tasks and demonstrate that cross-sensory training addresses data scarcity whilst outperforming single-modality approaches Code: https://github.com/NiallMcguire/Audio_BPR

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Clear, Simple Summary of the Paper
What is this paper about? (Overview)
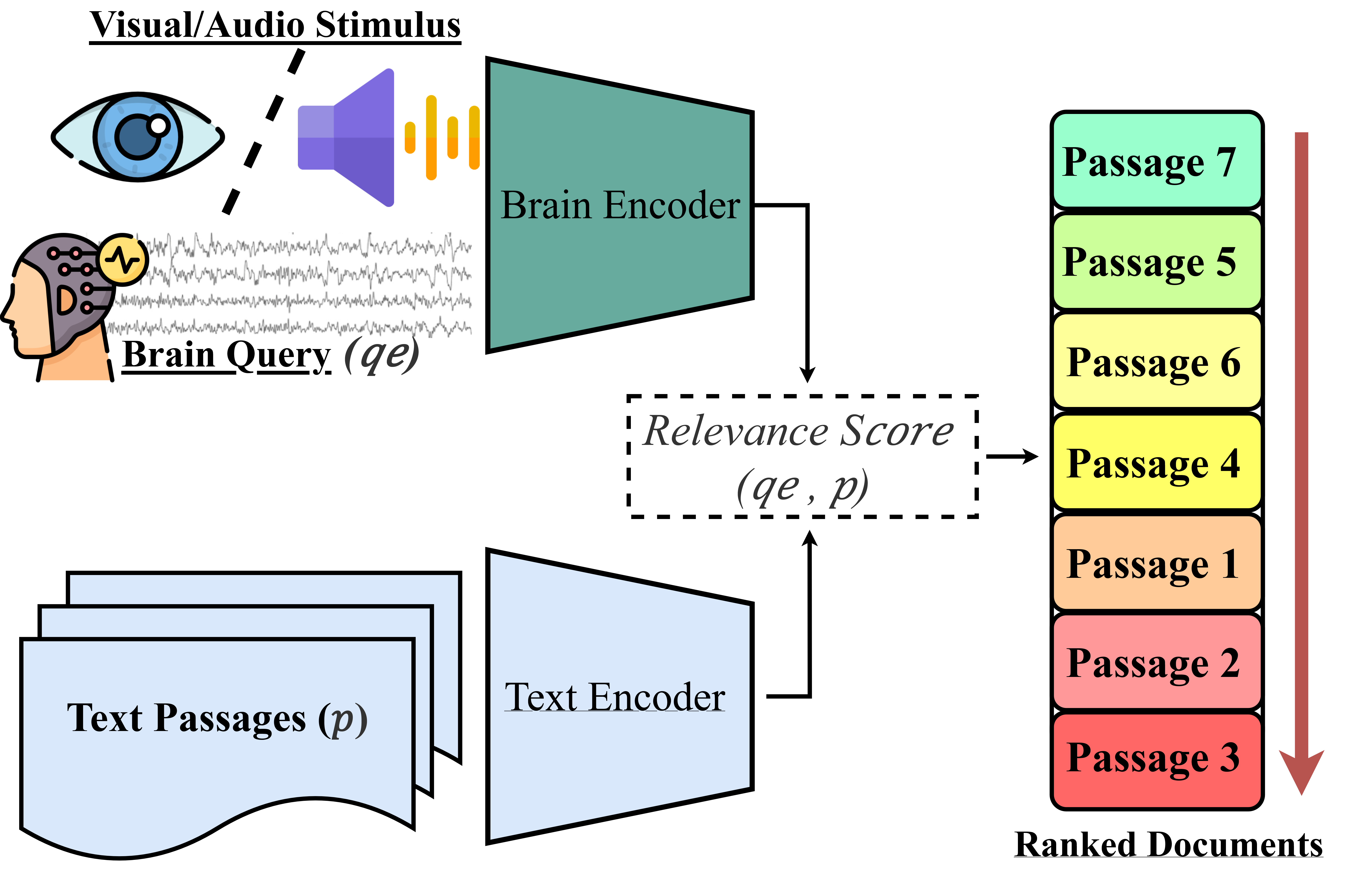
This paper explores a new way to search for information using brain signals instead of typed words. Normally, when you use a search engine, you have to think of the right words to type. That can be hard, especially if your thoughts are fuzzy or if you can’t easily type or see. The authors test a method called Brain Passage Retrieval (BPR), which tries to match a person’s brain activity to the most relevant text passages—without turning the brain activity into written words first.
Their big new idea is to use brain signals recorded while listening (auditory EEG), not just while reading (visual EEG). They also test whether training on both listening and reading brain data together makes the system better.
What did the researchers want to find out? (Objectives)
The study focuses on three simple questions:
- Can brain signals recorded while listening help a search system find the right text?
- If we train the system on both listening and reading brain data together, does it work better?
- Does the way the system summarizes brain signals (its “pooling” method) change how much combined training helps?
How did they do it? (Methods, in everyday language)
- EEG: The researchers used EEG, which is like putting a “microphone” on your head to record your brain’s electrical activity. It’s safe and non-invasive.
- Listening vs. Reading: They used two public datasets:
- Alice (auditory): People listened to a chapter of “Alice’s Adventures in Wonderland” while wearing EEG.
- Nieuwland (visual): People read stories word-by-word while wearing EEG.
- Turning signals into “searchable” numbers:
- Think of the system as having two “translators” (called encoders). One translator turns brain signals into numbers. The other turns text passages into numbers. The goal is to put both into the same “number language” so the system can measure how similar they are.
- If the brain numbers and passage numbers point in similar “directions” (like two arrows pointing the same way), the passage is likely relevant.
- Pooling (how to summarize a sequence into one signal):
- Mean: average all the parts.
- Max: take the strongest parts.
- CLS: use a special learned summary token (like letting one “spokesperson” summarize the whole sequence).
- Multi-vector: keep many parts instead of just one summary.
- Training trick (contrastive learning):
- The system learns by pulling together real brain–passage pairs and pushing apart mismatched ones. Think “make true pairs close, false pairs far.”
- Creating training examples (Inverse Cloze Task):
- They take a chunk of text as the “query” and use the surrounding text as the “answer.” Sometimes they remove the query text from the passage so the system can’t cheat by simply matching exact words.
- How they judged success:
- Hit@1: Did the right passage rank first?
- Hit@10: Was it in the top 10?
- MRR (Mean Reciprocal Rank): A score that rewards putting the right passage near the top.
What did they find, and why does it matter? (Main results)
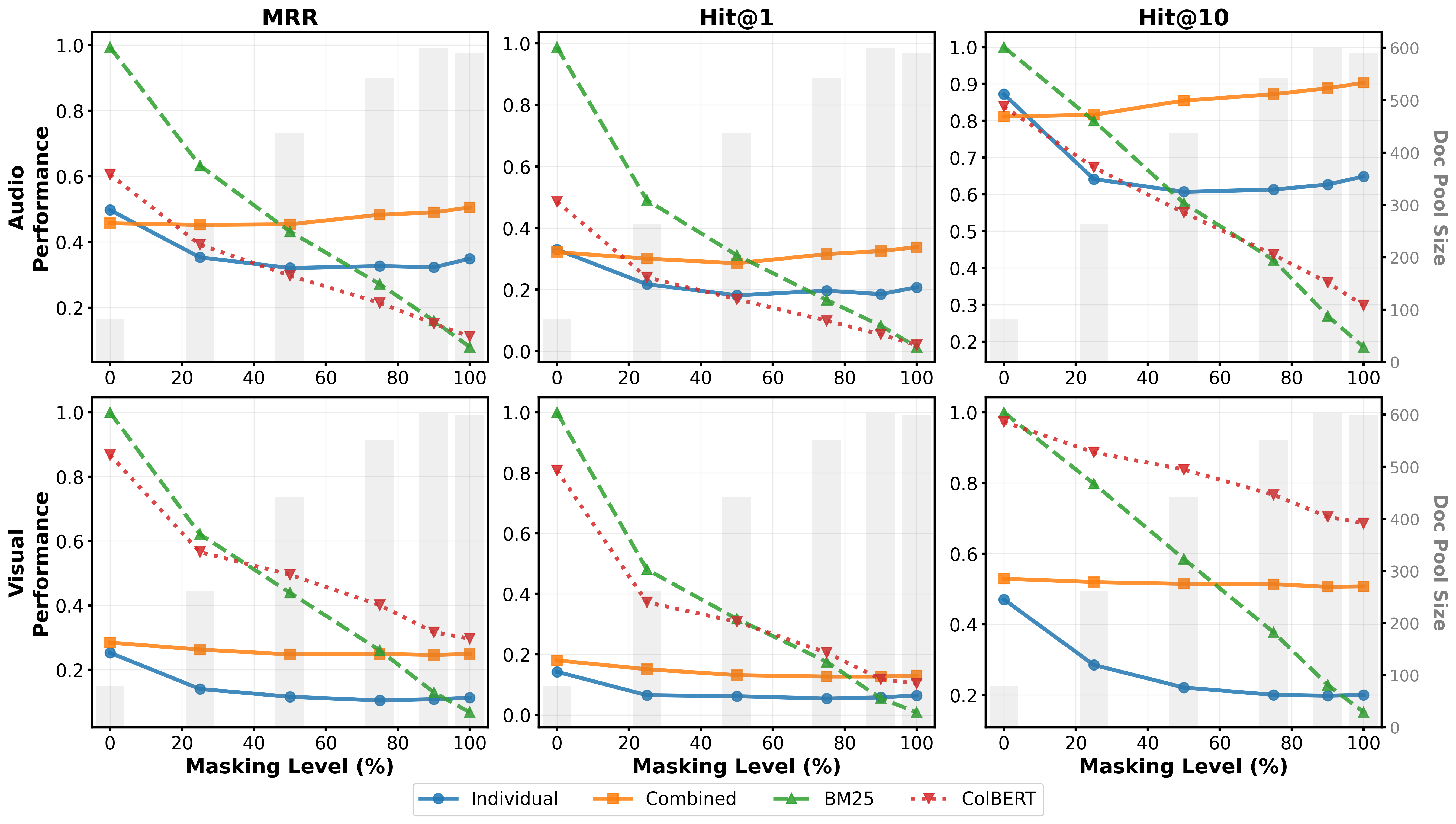
- Listening beats reading: Brain signals from listening consistently worked better than brain signals from reading for finding the right passages.
- Training on both listening and reading together helped a lot—especially with the CLS summary method:
- With CLS pooling and combined training, the system scored:
- MRR: 0.474
- Hit@1: 0.314
- Hit@10: 0.858
- It even beat a strong text-only baseline (BM25) on some scores:
- For example, MRR was 0.474 (brain) vs. 0.428 (BM25).
- This is surprising because the brain-based query doesn’t use typed words.
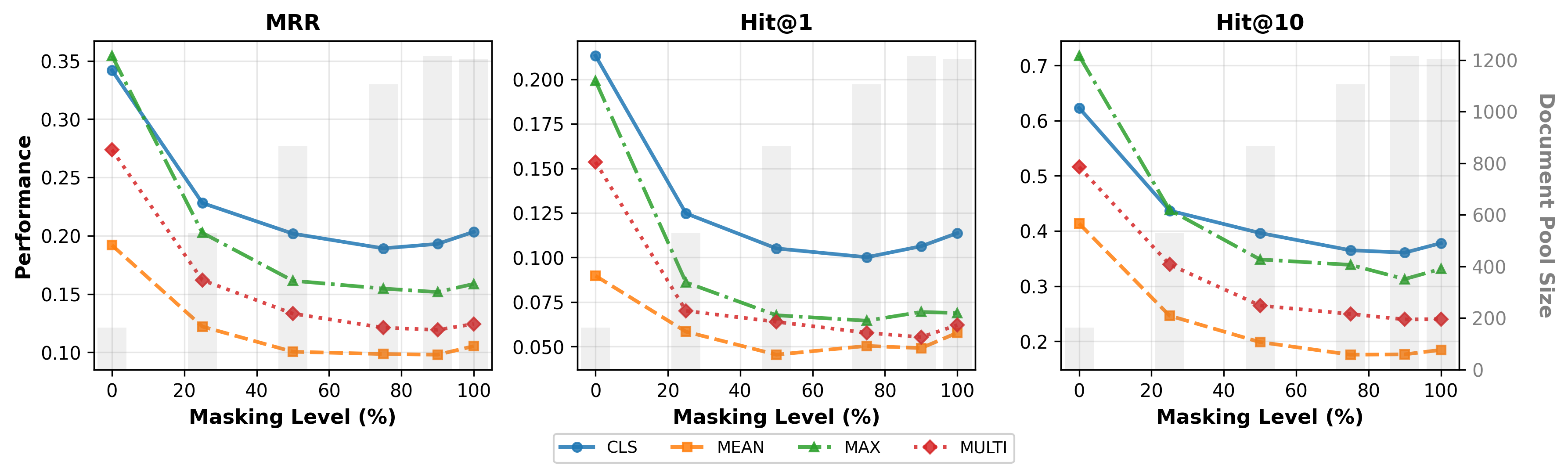
- The best way to summarize signals depends on the task:
- CLS pooling gave improvements for both listening and reading when trained together.
- Max pooling helped the reading data a lot but actually hurt the listening data when combined.
- Robust when words overlap less:
- Even when the system had less word overlap between query and passage (due to masking), the brain-based method stayed strong, suggesting it learned deeper meaning, not just word-matching.
Why this is important:
- It shows that brain signals while listening can guide search well. That’s a big deal for voice-based systems, podcast or audiobook search, and people who are visually impaired.
- Training on mixed brain data helps overcome the problem that EEG data is scarce and hard to collect.
What could this change in the real world? (Implications)
- More accessible search: People who can’t type easily or can’t see well might use brain-driven or voice+brain systems to find information.
- Better voice interfaces: Smart assistants could one day connect to brain signals to better understand what you’re looking for without needing perfect spoken or typed queries.
- Smarter training: Combining different kinds of brain data (listening + reading) can make systems stronger, but you must pick the right summarizing method (CLS worked best across both).
A quick note on limits and what’s next
- The brain data came from people passively listening and reading, not actively searching—future work should test real search tasks.
- Only two datasets were used and they came from different texts, so more diverse data would help confirm the results.
- Next steps: collect larger, more varied EEG datasets, test more tasks, and explore how to make such systems practical and reliable outside the lab.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research.
- Ecological validity: The study uses EEG from naturalistic reading/listening rather than active search or query formulation. It remains unknown whether BPR trained on comprehension generalizes to EEG recorded during real information need realization and interactive retrieval tasks.
- Dataset confound: Auditory (Alice) and visual (Nieuwland) datasets differ in source texts, protocols, and timing. Improvements attributed to “cross-sensory training” may be driven by dataset diversity rather than modality per se. Matched corpora presenting the same narrative in both audio and visual formats are needed to isolate modality effects.
- Data volume confound: Combined training doubles the number of EEG-query pairs. No control shows whether gains stem from more data (quantity) versus cross-sensory diversity (quality). Ablations with equal-sized single-modality datasets and subsampled combined datasets are needed.
- Cross-modality transfer: The paper does not test zero-shot transfer (train on auditory, test on visual and vice versa) to determine whether learned mappings generalize across modalities without joint training.
- Subject generalization: It is unclear whether models are subject-independent and robust across users. Explicit cross-subject splits, per-subject personalization, and evaluation of transfer across sessions and hardware are needed.
- Out-of-domain generalization: Retrieval is confined to the same corpus from which EEG was recorded. It remains unknown if EEG-derived queries can retrieve relevant passages from large external corpora (e.g., MS MARCO) not seen during EEG collection.
- Alignment fidelity in auditory EEG: Word-level alignment in the Alice dataset may be noisy. Sensitivity analyses to timing misalignment and phoneme/word segmentation errors are needed to quantify impact on retrieval.
- Preprocessing transparency and robustness: Artifact handling (e.g., ocular/muscle artifacts), referencing choices, filtering, and channel selection strategies are not fully specified or ablated. Robustness to preprocessing variations should be evaluated.
- Limited EEG encoder capacity: The EEG encoder is a shallow, 1-layer transformer with flattened inputs. Comparative studies with spatiotemporal CNNs, temporal convolution/transformer hybrids, RNNs, and architectures leveraging spatial electrode topology are missing.
- Pooling implementation details: The multi-vector late interaction (ColBERT-style) similarity function is not described (e.g., max-sim vs. sum over tokens, scaling). Alternative learned pooling (attention pooling, gated pooling) and token weighting remain unexplored.
- Loss and negatives: Training uses in-batch negatives only with InfoNCE. The benefits of hard negative mining, cross-batch memory banks, curriculum negatives, and alternative objectives (triplet, supervised contrastive, margin losses) are unknown.
- Frozen text encoder: BERT-base is frozen; joint fine-tuning or adapter-based alignment could improve EEG–text alignment. The impact of more powerful text encoders (e.g., domain-adapted LMs, multilingual LMs) remains untested.
- Realism of ICT evaluation: The inverse cloze task creates synthetic query–passage pairs; it is unclear whether performance transfers to realistic IR tasks with user-generated queries, ambiguous needs, and multi-document relevance.
- Masking-based evaluation bias: Document masking is non-standard for text baselines and may penalize them. A more realistic evaluation (no masking, or task-specific masking consistent across modalities) is needed to fairly compare EEG and text baselines.
- Baseline rigor: ColBERT and BM25 are not fine-tuned for ICT in this corpus. Stronger, task-aligned text baselines (e.g., DPR fine-tuned on ICT pairs, cross-encoder re-rankers) are needed to validate claims of EEG competitiveness.
- Interpretability and neuroscientific grounding: There is no analysis of which channels, frequency bands, or time windows contribute most to retrieval. Feature attribution, spectral analyses, and region-of-interest studies could validate neural plausibility.
- Real-time feasibility: Latency, computational footprint, sliding-window strategies, and the minimal EEG duration required for stable queries are not assessed, limiting deployment guidance for real-time BMIs.
- Robustness to noise and non-ideal conditions: Performance under motion, artifacts, fatigue, varying SNR, and consumer-grade EEG hardware is unknown. Stress tests and hardware-agnostic evaluations are needed.
- Privacy and security: EEG can be identifying; risks of subject re-identification, model inversion, and sensitive cognitive state leakage are not addressed. Protocols for anonymization, differential privacy, and secure model deployment are needed.
- Fairness and accessibility: The system’s performance across demographics (age, gender, cognitive differences, neurological conditions) is untested. Equity impacts for visually impaired and motor-disabled users require user-centered evaluations.
- Language and cultural generalization: The study uses English narratives only. It is unclear whether EEG–text mappings generalize across languages, speech rates, accents, and cultural content.
- Query granularity: Queries are fixed at 30% of passage length. The effect of query length, position, and semantic density on retrieval has not been systematically explored.
- Multimodal augmentation: The approach ignores concurrent acoustic features (e.g., prosody) and eye-tracking for visual stimuli. Joint modeling of EEG with stimulus-side features may improve alignment; this remains unexplored.
- Topic leakage risk: Because EEG and passages come from the same stimulus, models may learn passage-specific signatures. Evaluations on independent corpora with related topics but different texts are needed to test true semantic generalization.
- Sample efficiency and scaling laws: The minimum data requirements per user/session and how performance scales with hours of EEG (including large-scale pretraining) are not studied.
- Statistical rigor: Reported significance is based on paired t-tests across masking levels, not across multiple random seeds/runs. Variance across runs, confidence intervals, and standardized statistical protocols are needed for reproducibility.
- Efficiency and practicality: Memory/latency trade-offs for multi-vector late interaction, index sizes, and retrieval speed are not reported, hindering assessment of deployment feasibility.
- HCI and usability: User calibration needs, interaction flows, error recovery, and user trust/interpretability in BMI-based IR are not explored through user studies or prototyping.
- Why auditory > visual?: The cause of auditory superiority is unclear (SNR, task design, timing, cognitive load, or dataset differences). Controlled, matched-modality experiments are required to pinpoint the underlying mechanisms.
Practical Applications
Immediate Applications
The following applications can be prototyped or deployed today using the paper’s released code and off‑the‑shelf EEG hardware, with modest integration effort and standard governance controls.
- Accessible, hands‑free IR prototypes for visually impaired users
- Sector: healthcare/accessibility, software
- What: EEG‑driven “neural queries” that retrieve passages from audiobooks, podcasts, or knowledge bases while the user listens, reducing dependence on typed or spoken queries.
- Tools/workflows: consumer EEG headband → real‑time preprocessing → paper’s dual‑encoder (CLS pooling) → cosine similarity → top‑k ranking → screen reader/TTS playback. Integrate as a plugin to ElasticSearch/OpenSearch or as a microservice front‑end to BM25/ColBERT indexes.
- Assumptions/dependencies: per‑user calibration for EEG; acceptable SNR with consumer‑grade devices; focused, bounded corpora; privacy consent; performance aligned with reported auditory CLS gains (MRR ≈ 0.47 vs BM25 ≈ 0.43 in the study).
- Voice‑first neural search for spoken content platforms (podcasts, audiobooks)
- Sector: media, software
- What: Retrieve relevant segments based on listening‑evoked EEG rather than spoken queries—useful when formulating precise terms is hard.
- Tools/workflows: stream EEG during audio playback; apply ICT‑style pairing to build passage indexes; serve results via mobile app or web client.
- Assumptions/dependencies: platform support for EEG capture (mobile SDK); small latency budgets; curated content; adherence to local data protection laws.
- Hands‑free document retrieval in sterile or constrained environments
- Sector: healthcare (operating rooms), manufacturing labs
- What: Retrieve procedural steps or checklists while gloved or hands occupied.
- Tools/workflows: on‑prem EEG capture → local encoder inference → edge ranking service → display on heads‑up or wall monitors.
- Assumptions/dependencies: short, domain‑specific corpora; acceptance testing for workflow safety; device hygiene and interoperability standards.
- Cross‑sensory EEG training pipeline to overcome data scarcity
- Sector: academia, software R&D
- What: Use combined auditory+visual EEG datasets with CLS pooling to boost BPR performance under limited data.
- Tools/workflows: adopt paper’s training scripts, masking schedule, and InfoNCE objective; freeze text encoder; run A/B tests across pooling strategies.
- Assumptions/dependencies: availability of at least two EEG corpora; compute (GPU); reproducible preprocessing; consistent labeling via ICT.
- Evaluation and benchmarking add‑on for IR research labs
- Sector: academia
- What: Add EEG‑based query evaluation alongside text baselines, using masking regimes to probe semantic robustness.
- Tools/workflows: integrate paper’s metrics (MRR, Hit@k) and masking sweeps in lab pipelines; publish neural‑vs‑text comparisons.
- Assumptions/dependencies: ethics approval for EEG data reuse; dataset licensing; subject variability reporting.
- Learning analytics in audio‑based education
- Sector: education/EdTech
- What: Retrieve explanatory passages or examples aligned with neural signals during lectures or audio lessons.
- Tools/workflows: classroom EEG pilot → local retrieval on course material → “just‑in‑time” supplemental content surfaced on tablets.
- Assumptions/dependencies: parental/participant consent, IRB approval; constrained, pre‑indexed syllabi; teacher dashboards; calibration sessions.
- IR accessibility audits and guidelines for product teams
- Sector: policy within organizations, UX practice
- What: Use findings to justify adding alternative (neural) input paths to search, especially for visually/motor‑impaired users.
- Tools/workflows: internal accessibility review checklists; pilot protocols; risk/benefit documentation referencing EEG query competitiveness with BM25.
- Assumptions/dependencies: organizational buy‑in; legal counsel review; clear disclaimers on accuracy and consent.
- Developer toolkit for neural‑query microservices
- Sector: software
- What: Wrap the paper’s EEG encoder and CLS pooling into a containerized service exposing /encode and /search endpoints.
- Tools/workflows: container images, gRPC/REST APIs, observability hooks; plug‑ins for popular IR stacks.
- Assumptions/dependencies: stable preprocessing pipeline; rate‑limited streaming; model card and governance documentation.
Long‑Term Applications
The following applications require further research, scaling, hardware co‑design, governance frameworks, or clinical validation before broad deployment.
- Consumer EEG‑powered smart assistant for audio search
- Sector: consumer software, hardware
- What: Ambient voice assistant that leverages auditory EEG to retrieve passages or actions without explicit speech.
- Dependencies: robust performance on low‑channel, dry electrodes; on‑device inference; cross‑user generalization; battery life; UX research on adoption.
- Assistive communication for motor‑impaired patients
- Sector: healthcare/BCI
- What: Neural intent‑to‑retrieval interface to access information or augment AAC devices.
- Dependencies: clinical trials; medical device regulation; hospital IT integration; high reliability and low false positives.
- Cognitive‑state‑aware search UX
- Sector: software/UX, enterprise tools
- What: Adapt query reformulation, result summaries, or prompts based on detected cognitive load or satisfaction signals.
- Dependencies: validated cognitive markers in task contexts; latency budgets; privacy‑preserving on‑device analytics; user transparency.
- Enterprise knowledge retrieval by neural gist
- Sector: enterprise software
- What: Retrieve internal docs when employees cannot articulate queries during meetings or briefings.
- Dependencies: secure brain‑data governance; subject re‑identification risk controls; domain adaptation; multilingual support.
- Education: adaptive tutoring driven by neural signals during lectures
- Sector: education/EdTech
- What: System that detects comprehension gaps and fetches tailored explanations in real time.
- Dependencies: long‑term studies; standards for educational brain data; parent/guardian consent frameworks; equity/access safeguards.
- Standardization and governance for brain data in IR
- Sector: policy/regulation
- What: Data rights, consent, retention, and audit standards for EEG‑driven retrieval; threat modeling for subject re‑identification risk.
- Dependencies: cross‑stakeholder consortia; legal harmonization; certification schemes; independent oversight.
- Large‑scale cross‑sensory EEG dataset consortium for IR
- Sector: academia, industry consortia
- What: Shared, multimodal EEG/text corpora with ICT and task‑driven labels to enable reproducible BPR research.
- Dependencies: multi‑institution ethics approvals; standardized capture protocols; interoperable schemas; funding.
- Hardware co‑design: hearable/ear‑EEG for audio‑centric IR
- Sector: hardware
- What: Comfortable, low‑power, high‑SNR devices tailored to auditory BPR use (e.g., ear‑EEG integrated with headphones).
- Dependencies: signal quality and artifact mitigation; manufacturing; Bluetooth security; user comfort studies.
- AR/VR overlays powered by neural retrieval
- Sector: XR, industrial training
- What: Contextual overlays retrieved from neural queries during immersive experiences.
- Dependencies: robust streaming inference; low latency; XR safety standards; domain indexing.
- Public safety and emergency response
- Sector: public sector
- What: Hands‑free retrieval of protocols and maps for responders under stress when speech input is impractical.
- Dependencies: field‑grade hardware; ruggedization; training; evidence of reliability under high motion artifacts.
- Finance/compliance meeting assistance
- Sector: finance/legal
- What: Neural intent retrieval of regulations or precedents during briefings to avoid disclosure or interruption.
- Dependencies: strict privacy; auditable logs; regulatory approvals; domain‑specific tuning.
- Multilingual, cross‑domain BPR
- Sector: global software
- What: Extend cross‑sensory training to multilingual corpora and diverse domains.
- Dependencies: multilingual text encoders; culturally diverse EEG datasets; cross‑lingual evaluation; fairness audits.
Cross‑cutting assumptions and dependencies
- Generalization gap: The paper trains on naturalistic listening/reading (ICT) rather than active query formulation; real‑world performance in live search tasks needs validation.
- Subject variability: Calibration or personalization may be required; domain shift between datasets can impact robustness.
- Hardware constraints: Consumer EEG often has fewer channels and lower SNR than research‑grade systems; artifact handling (motion, EMG) is critical.
- Privacy and ethics: Brain data is sensitive; informed consent, secure storage, minimization, and transparency are non‑negotiable.
- Architecture choices matter: Reported cross‑sensory gains hinge on CLS pooling; deployments should re‑evaluate pooling strategies per modality and task.
- Index scope and masking: Performance is strongest on bounded corpora and benefits from document masking strategies that reduce lexical shortcuts; large open‑domain scaling will require additional work.
- Compliance and regulation: Medical/assistive and workplace deployments must meet local regulatory requirements and accessibility standards.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient-based update for better generalization in deep learning. "Training employs the AdamW optimiser"
- Alice EEG dataset: A corpus of EEG recordings collected while participants listened to a chapter of Alice’s Adventures in Wonderland, used as auditory-stimulus data. "we employ the Alice EEG dataset"
- auditory EEG: EEG signals recorded while participants process auditory (spoken) stimuli. "We present the first systematic investigation of auditory EEG for BPR"
- BERT-base-uncased: A pretrained transformer LLM variant used here as the frozen text encoder. "The text encoder employs BERT-base-uncased"
- BM25: A strong term-weighting retrieval function used as a lexical baseline in information retrieval. "BM25 text baselines"
- BM25Okapi: A specific implementation of the BM25 ranking function commonly used in practice. "BM25Okapi implementation from rank_bm25 Python package"
- Brain Passage Retrieval (BPR): A framework that maps EEG signals directly into passage embedding space to enable retrieval without intermediate text. "Brain Passage Retrieval (BPR) addresses this"
- Brain-Machine Interfaces (BMIs): Systems that translate neural activity into commands for computers or devices, enabling direct brain-based interaction. "Brain-Machine Interfaces (BMIs)"
- CLS pooling: An aggregation strategy that uses a special classification token representation as the sequence embedding for matching. "CLS pooling achieves substantial improvements"
- ColBERT: A late-interaction dense retrieval approach that maintains token-level representations for fine-grained matching. "ColBERT-style dense retrieval"
- ColBERTv2.0: An improved version of ColBERT providing stronger retrieval baselines. "ColBERTv2.0 from colbert-ir/colbertv2.0"
- contrastive learning: A training paradigm that pulls matched pairs together and pushes mismatched pairs apart in embedding space. "using a contrastive learning objective"
- contrastive loss: The objective function used in contrastive learning to maximize similarity of positive pairs while minimizing that of negatives. "The contrastive loss encourages"
- cosine similarity: A similarity measure between vectors based on the cosine of the angle between them, used for ranking. "Cosine similarity between encoded representations produces relevance scores"
- cross-sensory training: Training that combines data from different sensory modalities (e.g., auditory and visual) to improve performance. "cross-sensory training with CLS pooling achieves substantial improvements"
- dense passage retrieval: Retrieval that uses dense vector embeddings of passages and queries for nearest-neighbor matching. "commonly employed in dense passage retrieval"
- dense retrieval: Retrieval based on similarity in learned embedding spaces rather than sparse term matching. "dense retrieval architectures"
- dual-encoder architecture: A model design with separate encoders for queries and documents that map into a shared embedding space. "The approach employs a dual-encoder architecture"
- EEG: Electroencephalography; non-invasive recording of brain activity from the scalp, used here as neural queries. "EEG signals"
- EEG-to-Text (EEG2Text): Approaches that decode textual outputs directly from EEG signals, framed as translation. "EEG-to-Text (EEG2Text)"
- embedding space: A vector space where queries and passages are represented as learned embeddings for similarity computation. "shared embedding space"
- Hit@k: An evaluation metric indicating whether the relevant item appears within the top-k retrieved results. "Hit@k (k {1, 5, 10})"
- InfoNCE: A contrastive learning objective that maximizes agreement between positive pairs relative to negatives. "adapted from InfoNCE"
- in-batch negatives: Using other items within the same mini-batch as negative examples in contrastive training. "in-batch negatives with batchsize of 32"
- inverse cloze task (ICT): A self-supervised pretraining task that treats a text span as a query and its context as the relevant passage. "inverse cloze task (ICT) framework"
- Jaccard similarity: A set-based similarity metric used here to quantify lexical overlap between datasets. "Lexical overlap computed as Jaccard similarity."
- LLMs: High-capacity neural models trained on vast corpora, used for conversational search and related tasks. "LLMs"
- L2 normalisation: Scaling vectors to unit length to stabilize similarity comparisons in embedding space. "Final representations undergo L2 normalisation"
- magnetoencephalography (MEG): A neuroimaging technique measuring magnetic fields produced by neural activity. "MEG signals"
- masking ratios: Proportions of content removed from documents to test robustness against lexical overlap. "document masking ratios (0\%, 25\%, 50\%, 75\%, 90\%, 100\%)"
- max pooling: Aggregation by taking the element-wise maximum over token representations. "Max Pooling computes element-wise maximum values"
- mean pooling: Aggregation by averaging token representations across the sequence. "Mean Pooling averages representations"
- Mean Reciprocal Rank (MRR): A ranking metric computed as the average of the reciprocal of the rank of the first relevant result. "Mean Reciprocal Rank (MRR)"
- multi-vector representations: Using multiple token-level vectors (instead of a single pooled vector) for fine-grained matching. "Multi-vector preserves word-level granularity"
- paired t-test: A statistical test comparing means of paired observations, used here for significance testing. "paired t-test, p < 0.05"
- posterior cingulate cortex: A brain region implicated in information need formation and related cognitive processes. "posterior cingulate cortex"
- self-attention: A mechanism in transformers that computes dependencies between all token pairs in a sequence. "self-attention mechanisms"
- Steady-State Visually Evoked Potentials: Brain responses elicited by flickering visual stimuli at constant frequencies, used in early BCIs. "Steady-State Visually Evoked Potentials"
- teacher forcing: A training strategy that feeds ground-truth tokens to a decoder, which can cause memorization in sequence models. "rely on teacher forcing"
- temperature parameter τ: A scaling factor in softmax for contrastive objectives that controls distribution sharpness. "temperature parameter "
- transformer: A neural architecture leveraging self-attention for sequence modeling, used here for EEG encoding. "transformer-based EEG encoder"
Collections
Sign up for free to add this paper to one or more collections.