- The paper presents a dynamic memory system that refines LLM outputs at test time without traditional gradient updates.
- It leverages a KL-constrained policy optimization to estimate advantages from retrieved experience trajectories, ensuring optimal logit adjustments.
- Experiments on WebArena and Jericho benchmarks show state-of-the-art performance with over 30x monetary efficiency compared to traditional RL approaches.
Just-In-Time Reinforcement Learning: A Paradigm Shift in Reinforcement Learning for LLMs
Introduction
Just-In-Time Reinforcement Learning (JitRL) represents a significant shift in the application of reinforcement learning within LLMs, centered on continual learning without traditional gradient-based updates. This paper introduces JitRL as a framework that circumvents the computational and adaptation challenges inherent in conventional reinforcement learning (RL) methods. By leveraging a dynamic, non-parametric memory system, JitRL performs policy optimization at test time, refining the LLM's output through just-in-time adjustments based on retrieved experience trajectories.
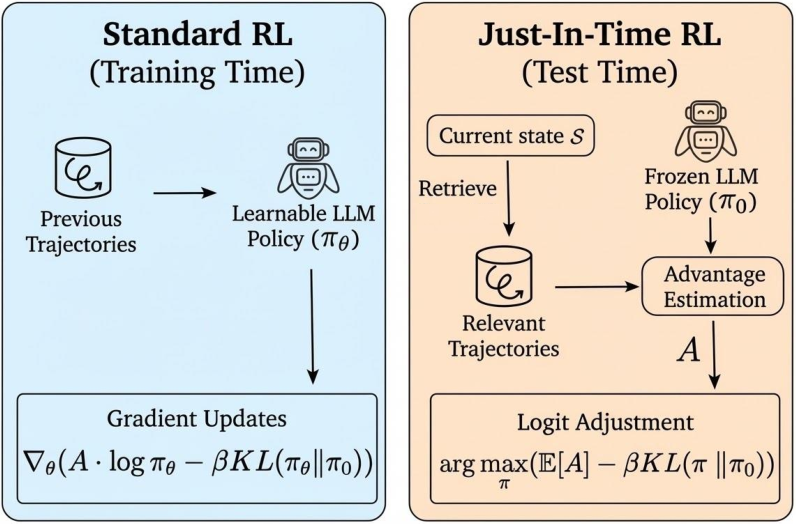
Figure 1: While standard RL performs policy gradient updates during training using previous trajectories, JitRL operates at test time. Specifically, it retrieves trajectories relevant to the current state to estimate advantages A, subsequently refining the output logits through a KL-regularized policy optimization objective.
Methodology
The core innovation of JitRL lies in its dynamic memory system that directly influences decision policies without altering model weights. This system retrieves state-relevant trajectories from a stored memory, estimates action advantages, and adjusts the LLM’s output logits by solving a KL-constrained optimization objective in closed form. This approach eliminates the need for gradient updates, offering results comparable to or exceeding those achieved through computationally intensive fine-tuning methods while significantly reducing costs.
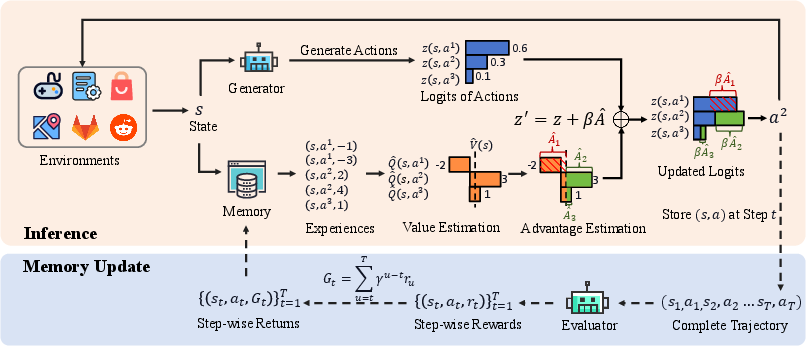
Figure 2: Overview of the Just-In-Time Reinforcement Learning (JitRL) framework. The system operates in a continuous loop: (1) In the Inference (top), the agent retrieves relevant past experiences.
Experimental Evaluation
Extensive experiments validate the efficacy of JitRL across the WebArena and Jericho benchmarks. JitRL consistently outperforms existing training-free and expensive gradient-based RL methods, achieving state-of-the-art performance in various task domains. Notably, it demonstrated a monetary efficiency advantage of over 30 times compared to traditional RL approaches.
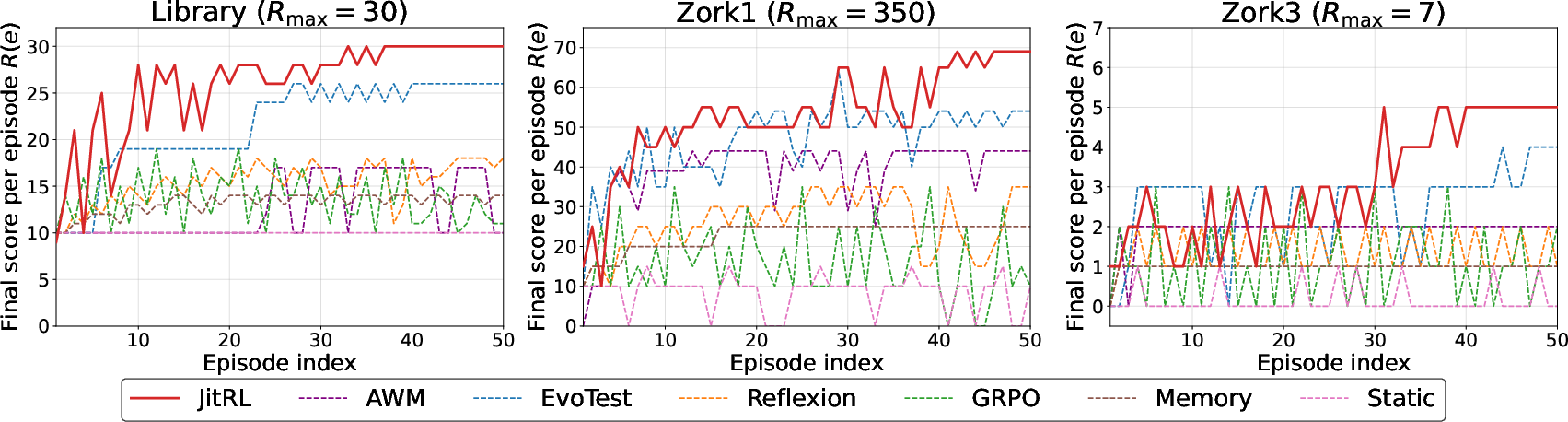
Figure 3: Learning curves on Jericho games. JitRL shows consistent improvement across episodes.
Theoretical Underpinnings
The paper provides a rigorous theoretical foundation, proving the optimality of JitRL’s logit update rule under a KL-divergence constraint. It establishes convergence guarantees for the value and policy updates, thereby ensuring that JitRL’s inference-time policy improvements consistently approximate the optimal policies seen in conventional reinforcement learning frameworks.
Implications and Future Work
The introduction of JitRL presents substantial implications for the deployment of LLMs in dynamic environments. Its ability to adapt continuously without re-training opens pathways for more scalable and versatile intelligent agents. Future work may explore the integration of JitRL with other learning paradigms to further enhance the adaptability of LLMs and expand the scope of its applications across diverse domains.
Conclusion
JitRL marks a notable advancement in reinforcement learning, providing an effective, efficient, and scalable solution for continual learning in LLMs without the traditional burdens of gradient updates. Its innovation holds the potential to redefine adaptive learning systems in AI, making significant strides toward more autonomous and intelligent systems.