On Surprising Effectiveness of Masking Updates in Adaptive Optimizers
Abstract: Training LLMs relies almost exclusively on dense adaptive optimizers with increasingly sophisticated preconditioners. We challenge this by showing that randomly masking parameter updates can be highly effective, with a masked variant of RMSProp consistently outperforming recent state-of-the-art optimizers. Our analysis reveals that the random masking induces a curvature-dependent geometric regularization that smooths the optimization trajectory. Motivated by this finding, we introduce Momentum-aligned gradient masking (Magma), which modulates the masked updates using momentum-gradient alignment. Extensive LLM pre-training experiments show that Magma is a simple drop-in replacement for adaptive optimizers with consistent gains and negligible computational overhead. Notably, for the 1B model size, Magma reduces perplexity by over 19\% and 9\% compared to Adam and Muon, respectively.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a surprising idea for training LLMs like ChatGPT: instead of updating every part of the model at every step, you randomly “skip” updates for some parts. Even though that sounds wasteful, the authors show it can make training smoother and lead to better results. They introduce a simple add-on called Magma that decides which parts to skip more carefully, and it beats popular optimizers like Adam and Muon on several LLM training tests.
What questions does the paper ask?
The authors focus on three simple questions:
- What happens if we randomly skip half of the model’s updates during training?
- Why can skipping updates actually help, even though it sounds worse?
- Can we improve this idea by using information the optimizer already has (like momentum) to skip in a smarter way?
How did they approach it?
To make the ideas easy to understand, think of training as hiking down a mountain (the “loss landscape”) to reach the lowest point (best performance):
- “Curvature” tells you how sharp or flat the terrain is. Sharp ridges and steep slopes are risky; flat areas are safer and tend to generalize better.
- “Gradient” is the direction downhill from where you are.
- “Momentum” is like remembering your recent downhill directions to avoid jittery zig‑zagging.
Here’s what they did:
1) SkipUpdate: Randomly skipping updates
- The model’s parameters are grouped into blocks (like sections of the model).
- At each training step, they flip a coin for every block. If it’s heads, they update it; if tails, they skip it this time.
- They scale the updates of the blocks they do change so that, on average, the total update isn’t biased. This keeps the training fair overall.
Analogy: Imagine you’re tightening lots of screws on a bike. Instead of tightening every screw every time, you randomly skip half, but tighten the ones you do touch a tiny bit more so the average effort stays similar. Surprisingly, this can prevent over-tightening the wrong screws and gives the bike a smoother ride.
Why this helps: The math shows that skipping acts like an “implicit regularizer” that avoids sharp, risky directions (steep ridges) and nudges training toward flatter, safer paths. It smooths the journey down the mountain.
2) Magma: Skipping updates in a smarter way
- Magma looks at how well the current gradient matches the “momentum” direction (how consistent the direction is over time).
- If the gradient agrees with momentum (they point in similar directions), Magma strengthens the update; if they disagree, it weakens it.
- It uses a simple score based on cosine similarity (a standard way to measure angle agreement) and a smooth “sigmoid” function to keep the score between 0 and 1. The score is averaged over time to stay stable.
- Magma still uses random skipping, but now the strength of each update is scaled by this alignment score.
Analogy: You’re steering a boat downriver. If the current and your steering agree, you go faster. If they fight each other, you slow down. You still occasionally pause paddling to avoid overreacting, but you choose how hard to paddle based on how well your moves match the river’s flow.
Technical terms explained briefly:
- Bernoulli mask: a coin flip that decides whether to skip a block’s update.
- Cosine similarity: a number between −1 and 1 that shows how similar two directions are; 1 means same direction, −1 means opposite.
- Sigmoid: a smooth S‑shaped function that squashes a number into a value between 0 and 1.
- Curvature/Hessian: measurements of how “sharp” the loss landscape is around you; high curvature means sharp, low curvature means flat.
What did they find?
Here are the main results the authors report:
- Randomly skipping half of the updates (SkipUpdate) often beats standard, dense optimizers, including modern ones like Muon, when training LLMs.
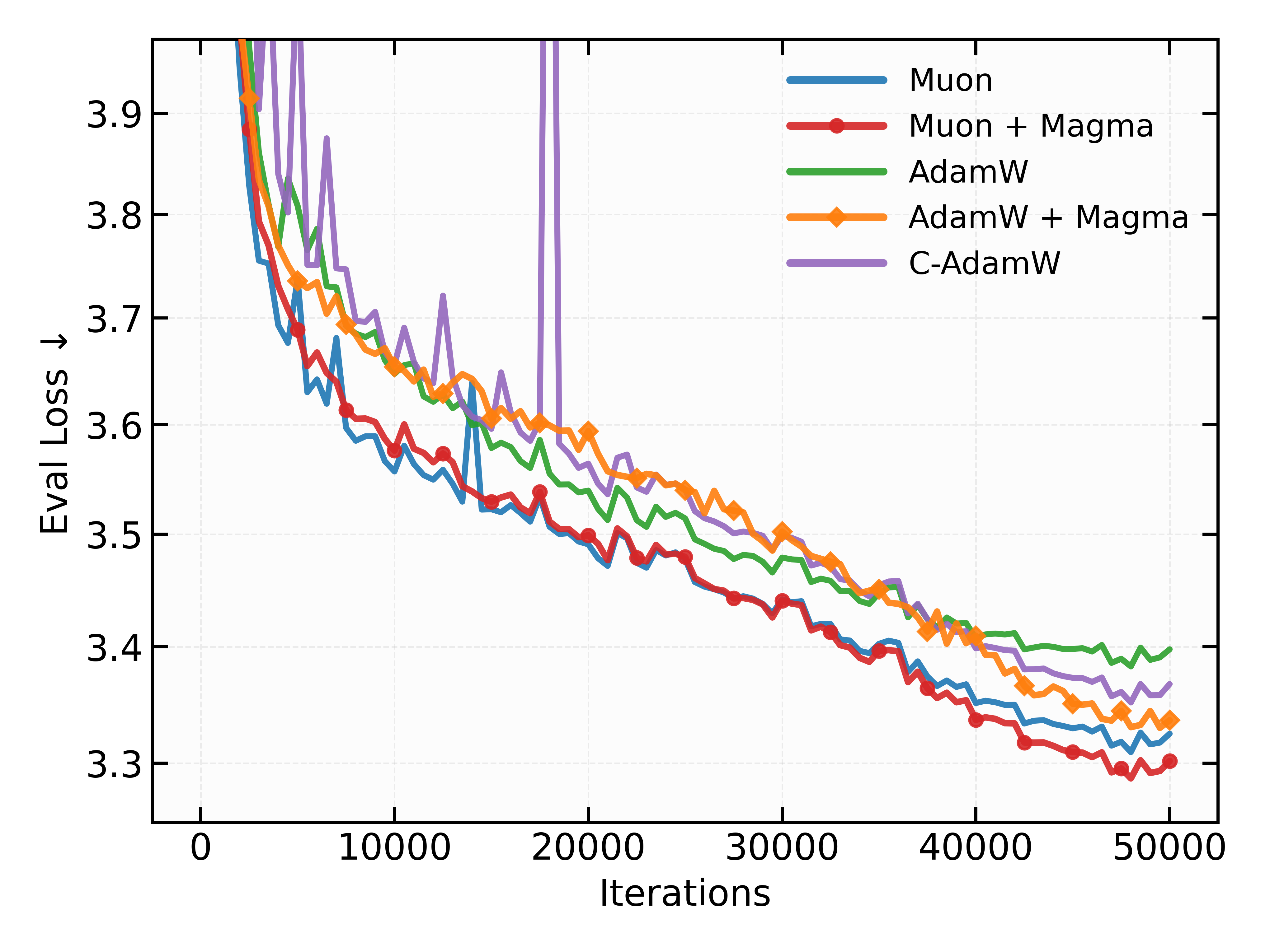
- Magma, which uses momentum‑aligned masking, consistently improves over both SkipUpdate and popular optimizers like Adam, RMSProp, and Muon, with almost no extra computation or memory.
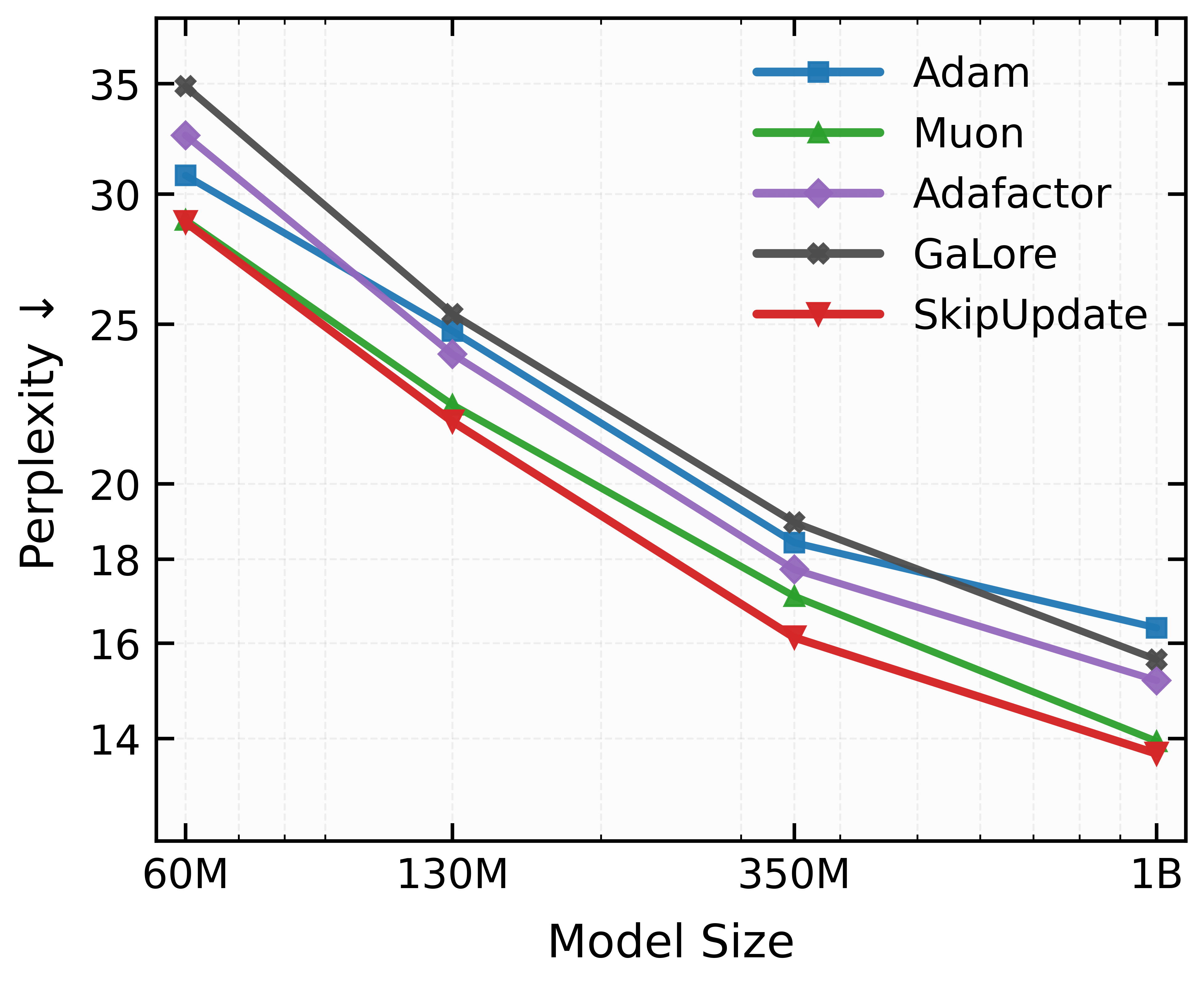
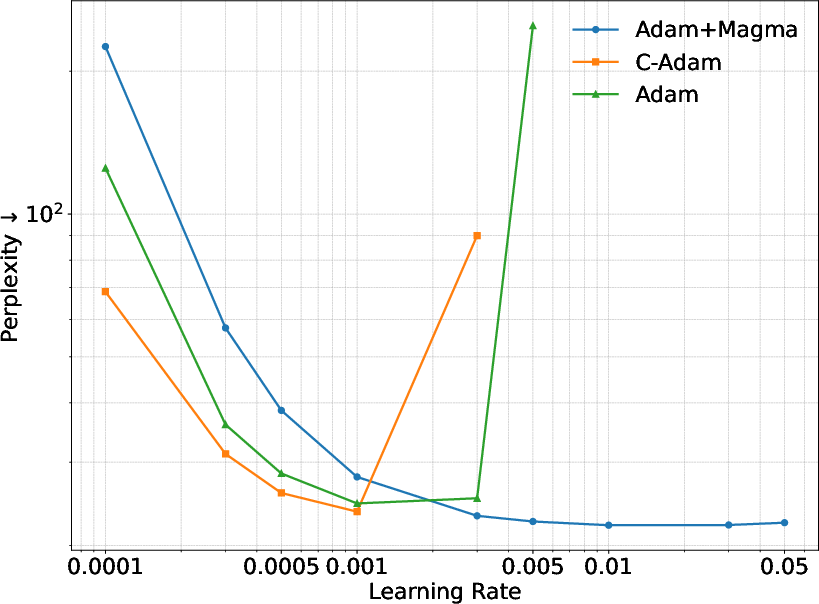
- On a 1‑billion‑parameter model, Magma reduces “perplexity” (a measure of how confused a LLM is; lower is better) by over 19% compared to Adam and by about 9% compared to Muon.
- Magma works well across different model sizes and even in trickier setups like mixture‑of‑experts (MoE) models, which have more complicated and noisy training.
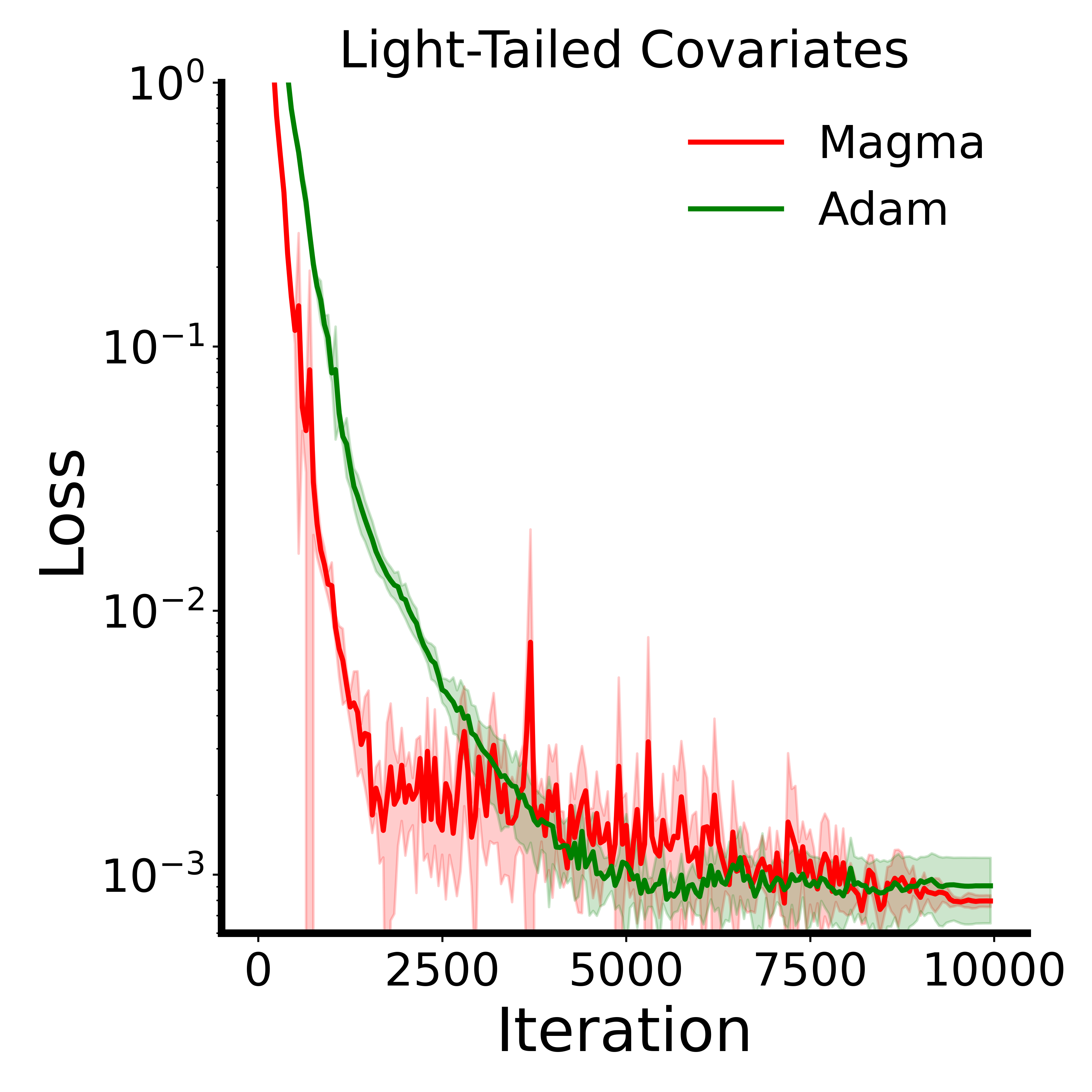
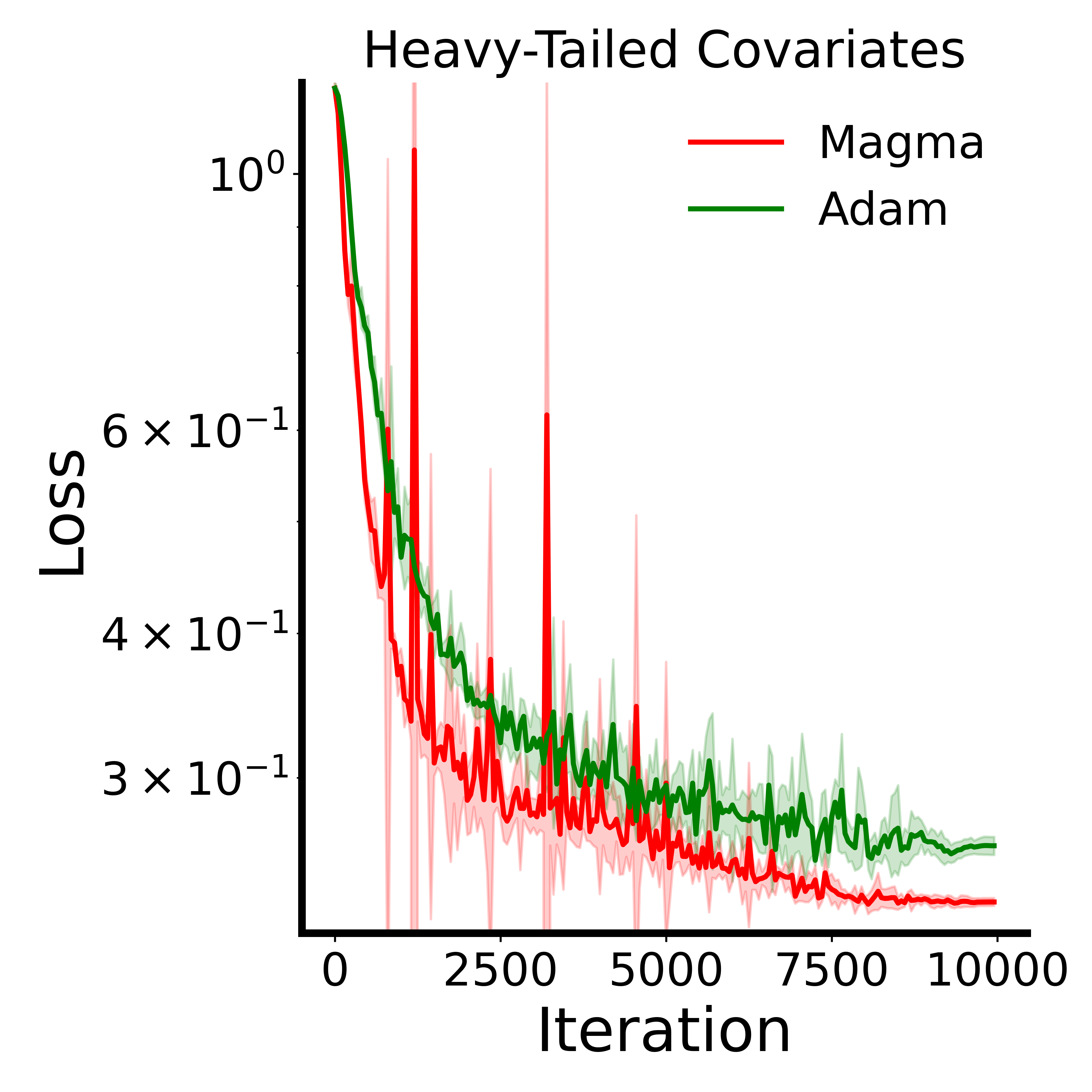
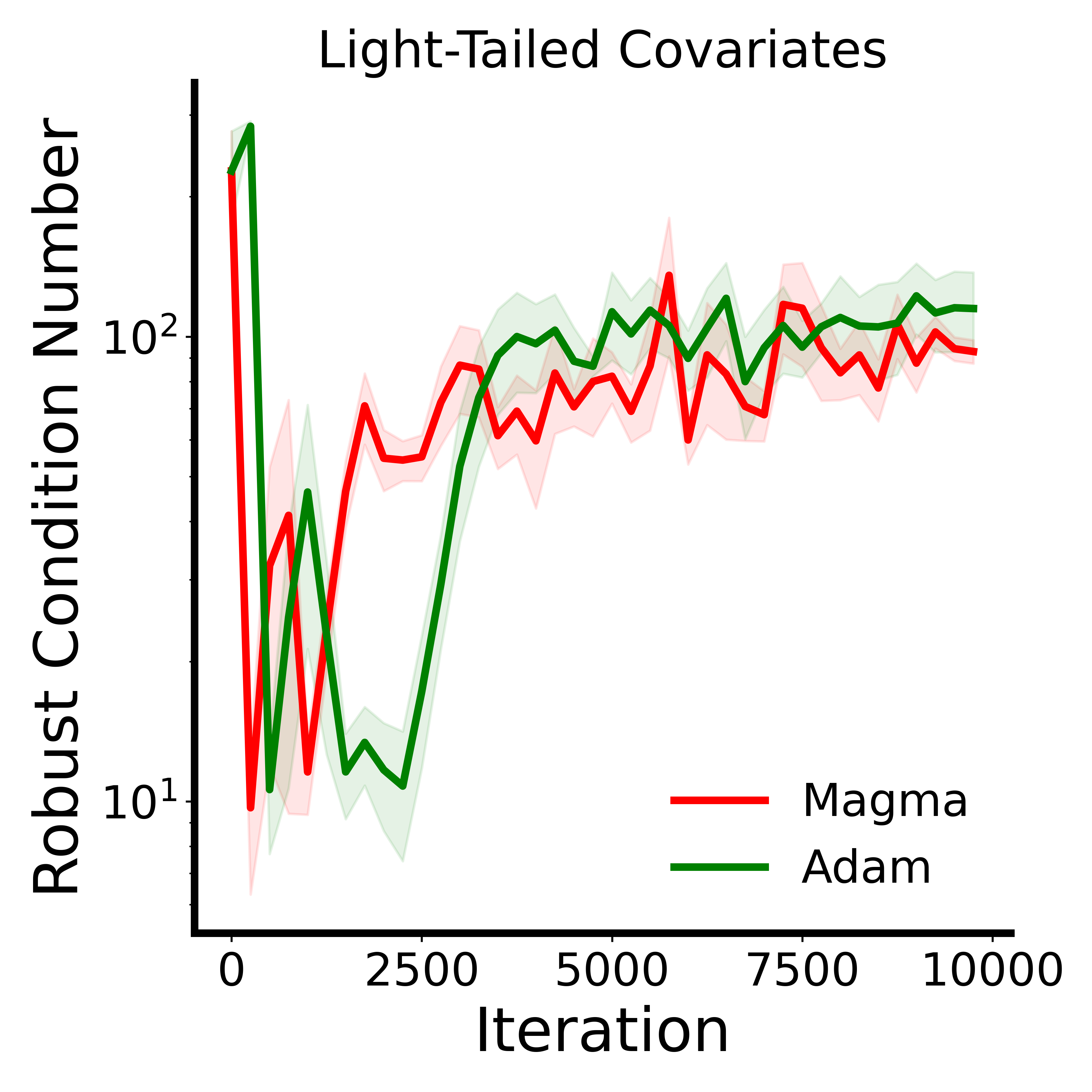
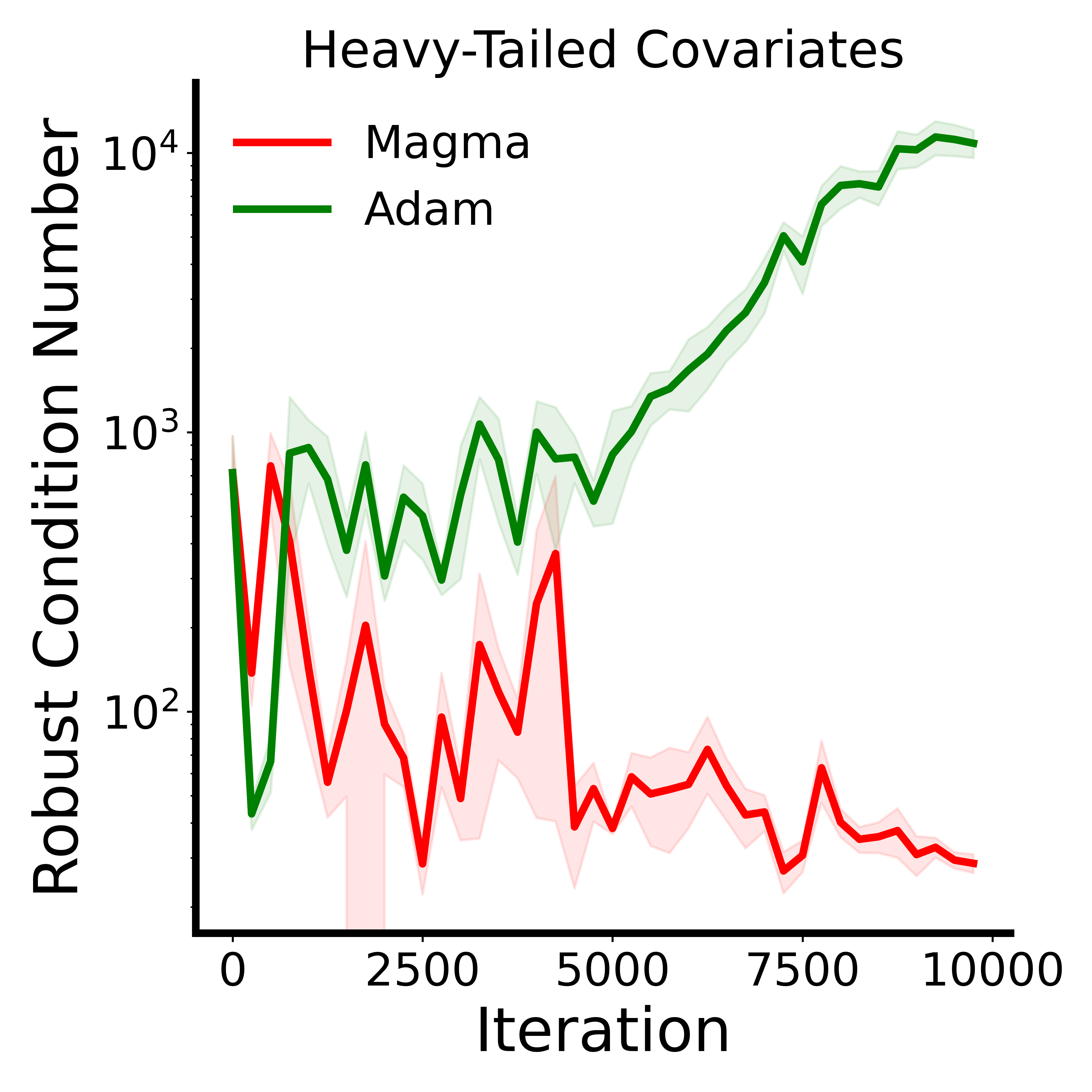
- In tests designed to mimic the tough “heavy‑tailed” noise common in language data, Magma stays in better‑conditioned, safer regions of the loss landscape and outperforms Adam.
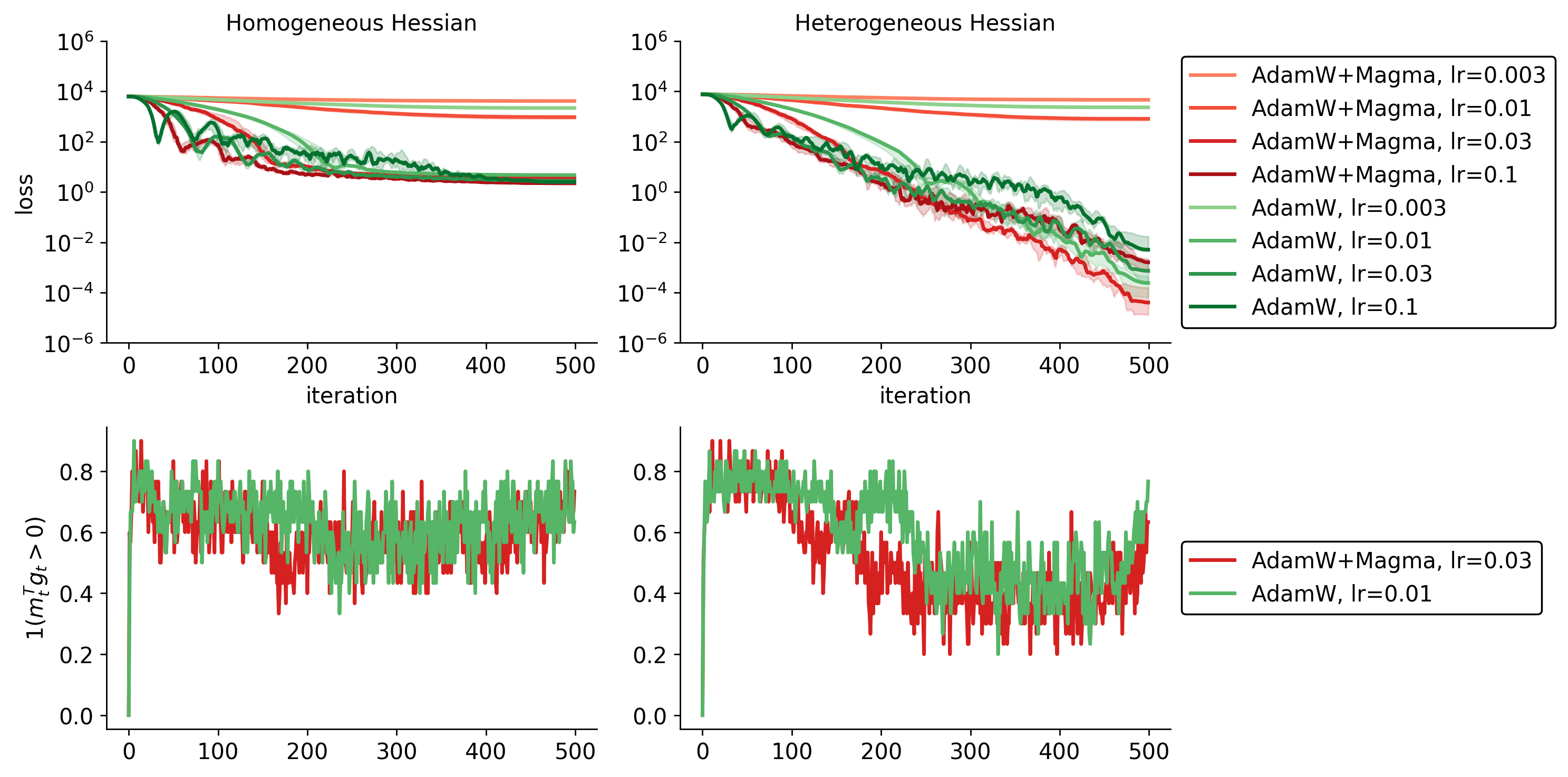
- In controlled math experiments with “heterogeneous” curvature (some blocks are sharp and others are flat), Magma converges faster and to a better final point than AdamW. In “homogeneous” cases (more even curvature, like typical CNNs), the benefits are smaller or neutral.
Why this is important:
- The random masking acts like a built‑in safety feature that avoids sharp, dangerous directions without having to compute expensive curvature information.
- Magma’s momentum‑alignment further filters out noisy, inconsistent updates, making training steadier and more reliable.
- Together, they provide a simple “wrapper” you can plug into existing training code, leading to better results with minimal changes.
What does it mean for the future?
- This challenges the common belief that “updating everything, every time” is always best. Sometimes, doing less (but smarter) leads to more stable and better training.
- Magma is easy to add on top of widely used optimizers and costs almost nothing extra, making it practical for big models.
- The idea of using structured randomness and alignment signals could inspire new optimizers that are both simple and powerful, especially for models with tricky, uneven training landscapes like transformers.
- While Magma shines in LLMs and MoE models, its benefits are smaller in vision models with smoother geometry, suggesting that future work can tailor similar ideas to different architectures.
In short, the paper shows that skipping updates in a smart, momentum‑aware way can guide training toward flatter, safer solutions and improve performance, especially for large, complex LLMs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of concrete gaps the paper leaves unresolved, intended to guide future research:
- Theoretical coverage for Magma is incomplete: the curvature-dependent regularization (Proposition 1) is proved only for unbiased SkipUpdate with fixed survival probability, not for Magma’s stateful, biased scaling based on momentum–gradient alignment. A formal analysis of Magma’s induced regularizer and stability conditions is missing.
- Stable yet unbiased masking remains unresolved: the authors note that using alignment scores as survival probabilities with 1/p rescaling was unstable. Designing unbiased variants with provable stability and competitive performance is an open problem.
- Lack of convergence guarantees for adaptive optimizers: the theory is developed for constant-step SGD and only sketched to “extend” to Adam-type methods. Formal convergence results (and rates) for RMSProp/Adam/LaProp under masking and alignment are not provided.
- Interaction between masking and momentum not fully characterized: the claim that dense momentum updates yield a variance-reduced estimator is not quantified. A rigorous analysis of momentum state dynamics under masked parameter updates (including bias/variance trade-offs) is absent.
- Optimal survival probability and scheduling are unknown: experiments default to p≈0.5 but do not map performance across p, nor explore schedules (e.g., warming up p, annealing, or adaptive p per block based on SNR).
- Alignment score design is heuristic: the choice of cosine similarity, temperature τ=2, EMA coefficient (0.1), and sigmoid mapping lacks principled calibration. How τ, EMA half-life, or alternative alignment metrics (e.g., sign-consistency thresholds, SNR-based gating) impact stability and performance remains unstudied.
- Block definition and granularity are underexplored at scale: results at 130M show similar performance for element-/column-/block-wise masking, but there is no systematic study at larger scales (350M–1B+) or with different blockings (e.g., per-matrix vs per-layer vs per-submodule).
- Scope of application across layers is narrow: Magma is only applied to attention and MLP layers. Whether embeddings, layer norms, or output heads should be masked (and with which hyperparameters) is unexplored.
- Generality beyond LLM pre-training is limited: Magma does not improve ResNet-50 on CIFAR-10, suggesting architecture- and landscape-specific benefits. Its effectiveness on ViTs, diffusion models, reinforcement learning, instruction tuning, and RLHF remains untested.
- Scaling to modern model sizes is unverified: evaluations stop at 1B parameters. Behavior at 7B–70B+ scales (and on contemporary pre-training corpora and token budgets) is unknown.
- Compute and systems impact is not measured: authors claim “negligible overhead,” but there are no wall-clock, throughput, memory, or energy measurements. Effects on kernel fusion, register pressure, and distributed synchronization (e.g., mask RNG across ranks) are not reported.
- No savings in backprop compute despite masking: gradients are computed densely but many parameter updates are skipped. Whether operation pruning from block-wise masking yields real accelerator-level gains (or branch divergence penalties) is unquantified.
- Robustness to hyperparameters and training regimes is underreported: sensitivity to learning rates, warmup, weight decay, gradient clipping, batch size, and mixed precision is not systematically evaluated (beyond an appendix mention of widened LR stability).
- Limited evaluation breadth and reproducibility: results lack error bars/seed variance, and there is no report of run-to-run variability or code release. Robustness across different datasets (beyond C4/OpenWebText), token budgets, and data mixtures is not shown.
- Interaction with other stabilizers is not explored: how Magma composes with gradient clipping strategies, momentum reset, SAM/ASAM, trust-region methods, label smoothing, or norm-based regularizers remains unclear.
- Synergy/competition with matrix preconditioners needs mapping: while Magma + Muon shows gains on Nano-MoE, a broader grid across Muon/SOAP/Shampoo variants and masking settings is missing, as well as analysis on when structured preconditioning and masking are complementary vs redundant.
- Heavy-tailed noise findings are limited to a toy benchmark: the linear transformer benchmark indicates benefits under heavy-tailed noise, but evidence from real LLM training (e.g., measuring tail indices of gradient distributions and correlating with gains) is absent.
- Assumptions on block-diagonal Hessian structure are unvalidated: the regularizer interpretation leans on block-wise curvature dominance, but the degree of block diagonality across transformer components and training phases is not quantified.
- Off-diagonal curvature effects under masking are not analyzed: Proposition 1 focuses on within-block terms; how cross-block Hessian interactions behave under masking (especially with stateful, data-dependent s_t) is unaddressed.
- Early vs late training trade-offs are not optimized: on Nano-MoE, Magma slows intermediate convergence but improves final loss. Policies to mitigate early slowdowns (e.g., adaptive τ/p schedules across phases) are not explored.
- Mask randomness and determinism in distributed training are unspecified: per-step/per-rank mask synchronization, reproducibility, and potential interactions with data-parallel/ZeRO sharding are not discussed.
- Numerical precision interactions are unknown: effects with bf16/fp8 training, gradient scaling, and optimizer state quantization are not evaluated.
- Downstream generalization beyond perplexity is unmeasured: the link between induced flatness (e.g., top Hessian eigenvalues, sharpness metrics) and downstream tasks (reasoning, code, multilingual) is not empirically established.
- Failure modes and safety are not cataloged: conditions that cause divergence or collapse (e.g., extreme p, misaligned momentum, nonstationary data) and safeguards (e.g., clipping of s_t, fallback rules) are not provided.
- Adaptive, SNR-aware masking is an open direction: the paper cites an SNR interpretation but does not operationalize per-block SNR estimates to set survival probabilities or damping magnitudes. Designing estimators and control policies is an actionable gap.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now based on the paper’s findings and methods.
- Software/AI Infrastructure — Drop-in optimizer wrapper for transformer training
- Replace Adam/RMSProp/LaProp/Muon updates with the Magma wrapper in PyTorch, JAX, or TensorFlow pipelines to stabilize and improve LLM pre-training and fine-tuning; set p≈0.5, τ≈2, and apply to attention + MLP blocks while keeping dense momentum updates.
- Potential tools/products: “Magma” optimizer plugin for popular DL frameworks; HuggingFace Trainer callback; MLOps recipe for “Magma+Adam/Muon”.
- Assumptions/dependencies: Strongest benefits in transformer-like, block-heterogeneous landscapes with heavy-tailed noise; negligible runtime/memory overhead but no backward-pass savings; not shown to help CNNs; requires high-quality randomness and deterministic seeding for reproducibility.
- Cloud Cost Optimization — Fewer failed runs and faster path to target perplexity
- Use Magma to widen the stable learning-rate regime and reduce divergence/restarts, cutting hyperparameter sweep and retraining costs; exploit observed perplexity reductions (e.g., 9–19% vs Adam/Muon at 1B) to reach quality targets with fewer tokens/steps.
- Potential workflows: Budget-aware LR sweeps; “stability-first” training templates; cost dashboards tracking loss spikes and effective LR range.
- Assumptions/dependencies: Benefits must be confirmed per dataset/model scale; savings accrue from stability (fewer restarts) and faster convergence, not from fewer gradient computations per step.
- Sparse MoE Training — Robust optimization under expert routing variability
- Integrate Magma into MoE frameworks (e.g., Nano MoE) to stabilize training with dynamic load balancing and non-uniform gradients; use as a complementary enhancer to Muon/SOAP preconditioners.
- Potential tools/products: “Magma for MoE” recipe; gating-aware masking policies; autoscaling of τ by expert gradient variance.
- Assumptions/dependencies: Maintain dense momentum updates; apply masking primarily to attention/MLP/expert blocks; validate on production MoE routing/load regimes.
- Academia/Research — Benchmarks and theory for geometric regularization via masking
- Leverage heavy-tailed linear transformer benchmarks to study Magma’s curvature-dependent regularization and stability; use the descent lemma framework to analyze effective smoothness and noise coupling.
- Potential tools/products: Open benchmark suites; visualization dashboards for momentum–gradient cosine similarity; teaching materials on structured stochasticity in optimization.
- Assumptions/dependencies: Requires reproducible setups, standardized data regimes (light vs heavy-tailed), and careful logging of Hessian proxies and alignment metrics.
- Sector model training on noisy text data (Healthcare, Education, Finance) — Stability on heavy-tailed corpora
- Apply Magma during domain LLM pre-training/fine-tuning on clinical notes, student interaction logs, or financial news/filings to mitigate instability from heavy-tailed gradient noise and heterogeneous curvature.
- Potential products/workflows: “Magma-enabled” domain-specific LLM training pipelines; stability SLAs in regulated settings where retraining waste is costly.
- Assumptions/dependencies: Benefits are strongest with transformer architectures and text-heavy corpora; validate downstream task gains beyond perplexity; ensure compliance/governance for stochastic training artifacts.
- Policy and Sustainability — Optimizer selection as an energy-efficiency lever
- Update internal training guidelines to include Magma as a default option for large transformers; track energy/carbon savings from reduced restarts and faster convergence to target metrics.
- Potential tools/products: Energy reporting modules that attribute savings to optimizer choice; procurement criteria emphasizing stability-first training.
- Assumptions/dependencies: Realized savings depend on operational practices (A/B validation, stability metrics) and workload mix; not a direct reduction in per-step compute.
- Product Quality-of-Service — Better LLMs for end-user applications
- Train or refresh production LLMs (chat, search, summarization) with Magma-enhanced optimization to improve generalization and reduce training instabilities that delay releases.
- Potential workflows: Regular retrain cycles with Magma; quality monitoring that ties perplexity improvements to downstream task metrics.
- Assumptions/dependencies: Perplexity-to-task-quality correlation must be validated; gains may be model-size dependent.
Long-Term Applications
The following use cases will benefit from further research, scaling, or engineering integration before broad deployment.
- Hardware-/Compiler-Aware Update Pruning — Real compute savings from masked blocks
- Propagate block masks to fused optimizer kernels to skip memory writes/reads and math on masked blocks; integrate with XLA, PyTorch Dynamo/Inductor, and custom CUDA kernels to realize bandwidth/Flop reductions when updates are skipped.
- Potential tools/products: “Magma-accelerated” optimizer kernels; compiler passes that elide masked updates; block-aware parameter partitioners.
- Assumptions/dependencies: Requires tight coupling between autograd, optimizer, and compiler; block boundaries must map cleanly to kernels; must preserve numerics and determinism; savings depend on mask density and hardware.
- Stable Unbiased Masking Schemes — Preserving expectation without losing stability
- Develop unbiased survival-probability scaling (e.g., using s̃ as survival probability with provably stable rescaling) that retains Magma’s stability while meeting unbiasedness desiderata for theory and certain applications.
- Potential products: “Magma-U” variants with formal guarantees; certification for sensitive domains demanding unbiased estimators.
- Assumptions/dependencies: Requires new control of noise amplification and robust temperature schedules; careful treatment of momentum-state updates.
- Automated Optimizer Configuration — AutoML for masking granularity and alignment
- Build auto-tuners that learn p, τ, block granularity (block-/column-/element-wise) and layer selection policies from telemetry (alignment histograms, variance-by-block).
- Potential tools/products: “Optimizer Auto-Tuner” services; closed-loop MLOps that adapt masking based on online signals.
- Assumptions/dependencies: Needs rich logging, safe exploration budgets, and guardrails against destabilizing configurations; objective functions must reflect real training cost-quality trade-offs.
- Cross-Architecture Extensions — Beyond LLMs to ViTs, graph transformers, and RL
- Adapt Magma to transformer-based vision/graph models and on-policy RL training where gradients are highly variable; assess benefits for robotics (policy networks), energy forecasting (sequence models), and finance (market modeling).
- Potential products/workflows: Sector-specific training stacks (e.g., “Magma for ViT/GRU-Transformer”); RL optimizer guards for spike mitigation.
- Assumptions/dependencies: Requires transformer-like block heterogeneity and heavy-tailed noise; benefits not observed for CNN benchmarks; task-specific tuning and validation.
- Hybrid Trust-Region/Second-Order Methods — Complementary geometry handling
- Combine Magma with Muon/SOAP or SAM/ASAM-style trust-region updates to target both curvature-aware preconditioning and flatness-seeking regularization.
- Potential products: “Magma+Muon/SOAP” recipes; geometry-aware training libraries.
- Assumptions/dependencies: Nontrivial hyperparameter coupling; potential interactions between damping and preconditioning must be characterized; compute overhead of second-order methods remains.
- Safety/Reliability Guardrails — Loss-spike prevention in large-scale training
- Use alignment signals to automatically suppress destabilizing blocks when early indicators (negative alignment spikes, sharp Hessian proxies) arise; formalize “optimizer guardrails” for foundation model training.
- Potential tools/products: Spike-aware optimizer wrappers; policy-based suppressors triggered by telemetry anomalies.
- Assumptions/dependencies: Requires reliable online diagnostics (e.g., cossim distributions) and thresholds; must balance suppression with progress to avoid under-training.
- Standardization and Policy — Optimizer-efficiency benchmarks and certification
- Establish community benchmarks attributing convergence stability and energy efficiency to optimizer design; create vendor-neutral certifications that recognize structured stochasticity techniques.
- Potential products: Optimizer-efficiency scorecards; sustainability labels for training pipelines.
- Assumptions/dependencies: Broad community participation; consistent measurement protocols; working groups aligning on meaningful metrics.
- Theory-Guided Training Curricula — Schedules informed by effective smoothness/noise
- Use the paper’s descent lemma and effective smoothness analysis to design curricula (e.g., masking intensity schedules by block curvature/variance) that optimize early-stage stability and late-stage generalization.
- Potential workflows: Curriculum schedulers that adapt p and τ over training phases; block-aware annealing strategies.
- Assumptions/dependencies: Needs reliable curvature/noise proxies; may interact with LR/weight-decay schedules; verification across diverse datasets/scales.
Glossary
- Adaptive optimizer: A training algorithm that adjusts parameter updates using statistics of past gradients to improve convergence. "dense adaptive optimizers like Adam"
- Alignment score: A scalar that measures how well the current gradient aligns with momentum, used to modulate masked updates. "Magma computes an alignment score "
- Bernoulli distribution: A probability distribution over binary outcomes (0 or 1) used to randomly mask updates. "randomly masked at each iteration following a Bernoulli distribution."
- Block-diagonal structure: A matrix structure where off-diagonal blocks are near-zero, indicating weak interactions across parameter blocks. "transformers, whose Hessians empirically exhibit pronounced block-diagonal structure"
- Block-wise masking: Randomly skipping updates for entire parameter blocks to alter optimization dynamics. "block-wise masking induces a curvature-dependent geometric regularization"
- Block-wise smoothness bound: A per-block Lipschitz-like condition bounding the loss change under small block-specific parameter shifts. "the block-wise smoothness bound naturally captures heterogeneous nature of the transformer loss landscape."
- Coordinate descent: An optimization method that updates one coordinate or block at a time rather than full gradients. "such as coordinate descent"
- Cosine similarity: A scale-invariant measure of directional alignment between two vectors, here momentum and gradient. "Cosine similarity is adopted for its scale-invariant property"
- Curvature-dependent geometric regularization: An implicit penalty induced by masking that discourages steps along high-curvature directions. "random masking induces a curvature-dependent geometric regularization"
- Diagonal preconditioning: Scaling updates per-parameter using diagonal matrices derived from gradient statistics. "limited ability of diagonal preconditioning to exploit dense within-block curvature"
- Eigenspectra: The set of eigenvalues of a matrix describing curvature or conditioning of the objective. "quadratic objectives with identical eigenspectra"
- Filtration: A growing sequence of sigma-algebras modeling the information available over iterations in stochastic processes. "We let be a filtration such that is -measurable and ."
- First-moment estimate: The exponential moving average of gradients, commonly referred to as momentum. "The first-moment estimate is a moving average of the gradients"
- Heavy-tailed stochastic gradient noise: Gradient noise with fat-tailed distributions that produce frequent large deviations. "A salient feature of training autoregressive LLMs is the presence of heavy-tailed stochastic gradient noise"
- Hessian: The matrix of second derivatives of the loss, capturing local curvature. " denotes the block of the Hessian ."
- Kronecker product: A matrix operation that forms block matrices by multiplying elements of two matrices. "where is the Kronecker product"
- Loss landscape: The geometric structure of the loss function over parameter space, including flat and sharp regions. "biases the algorithm toward flatter regions of the loss landscape"
- Mixture-of-Experts (MoE): A sparse model architecture that routes inputs to specialized expert subnetworks. "sparse mixture-of-experts (MoE) architecture"
- Momentum-gradient alignment: The consistency between the direction of momentum and the current gradient used to modulate updates. "which modulates the masked updates using momentum-gradient alignment."
- Nonconvex stationarity guarantee: A theoretical bound ensuring convergence to points with small gradient norm for nonconvex objectives. "provides the standard constant-step nonconvex stationarity guarantee"
- Perplexity: A language-model evaluation metric measuring uncertainty; lower is better. "Magma reduces perplexity by over 19\% and 9\% compared to Adam and Muon, respectively."
- Preconditioner: A transformation applied to gradients or updates to account for curvature, improving optimization stability. "dense adaptive optimizers with increasingly sophisticated preconditioners."
- Robust condition number: A conditioning metric defined via extreme and central eigenvalues of the Hessian to assess optimization difficulty. "Robust condition number defined as the ratio between the maximum and median eigenvalues of the loss Hessian."
- RPROP: A sign-based optimizer that adapts step sizes according to gradient sign consistency. "RPROP \citep{riedmiller1993direct} adapts step sizes based on the temporal consistency of gradient signs."
- Sharpness-aware optimization: Methods that explicitly target flatter minima by regularizing against sharp curvature. "sharpness-aware optimization methods"
- Signal-to-noise ratio: The magnitude of the momentum signal relative to gradient noise, governing abnormal alignment events. "decays exponentially in the signal-to-noise ratio ."
- Subspace optimization: Updating parameters within selected low-dimensional subspaces to reduce memory or improve stability. "recent subspace optimization methods"
- Survival probability: The probability that a masked update is applied in stochastic masking schemes. "with survival probability ."
- Temperature parameter: A scaling factor in a sigmoid that controls sensitivity of alignment-based modulation. " is a temperature parameter"
- Trust-region constraints: Optimization techniques that restrict update steps to regions where local approximations are reliable. "or trust-region constraints"
- Variance-reduced estimator: An estimator constructed to have lower variance than naive estimates, improving stability. "SkipUpdate effectively yields a variance-reduced estimator of the true momentum"
Collections
Sign up for free to add this paper to one or more collections.