Generated Reality: Human-centric World Simulation using Interactive Video Generation with Hand and Camera Control
Abstract: Extended reality (XR) demands generative models that respond to users' tracked real-world motion, yet current video world models accept only coarse control signals such as text or keyboard input, limiting their utility for embodied interaction. We introduce a human-centric video world model that is conditioned on both tracked head pose and joint-level hand poses. For this purpose, we evaluate existing diffusion transformer conditioning strategies and propose an effective mechanism for 3D head and hand control, enabling dexterous hand--object interactions. We train a bidirectional video diffusion model teacher using this strategy and distill it into a causal, interactive system that generates egocentric virtual environments. We evaluate this generated reality system with human subjects and demonstrate improved task performance as well as a significantly higher level of perceived amount of control over the performed actions compared with relevant baselines.
















































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What’s this paper about?
This paper introduces “Generated Reality,” a new way to make virtual worlds that react to your real movements—especially your head and hands—without needing to build detailed 3D game assets. Instead, an AI video generator creates the scene on the fly and updates it as you move, so you can see your own hands open a jar, push a button, or turn a steering wheel in a virtual world.
What questions are the researchers trying to answer?
- How can we give an AI video generator fine-grained control from a person’s real head and hand movements, not just simple text or keyboard inputs?
- What’s the best way to feed detailed hand information (like wrist and finger joint angles) into a video-generating model so the hands look correct and move realistically over time?
- Can this be made fast and interactive enough to feel responsive in a VR headset?
- Do people perform tasks better and feel more in control when their real hand motion drives the generated video?
How did they do it?
Think of the AI like a smart video “painter” that fills in each new frame based on what it has already drawn and the instructions it gets from you.
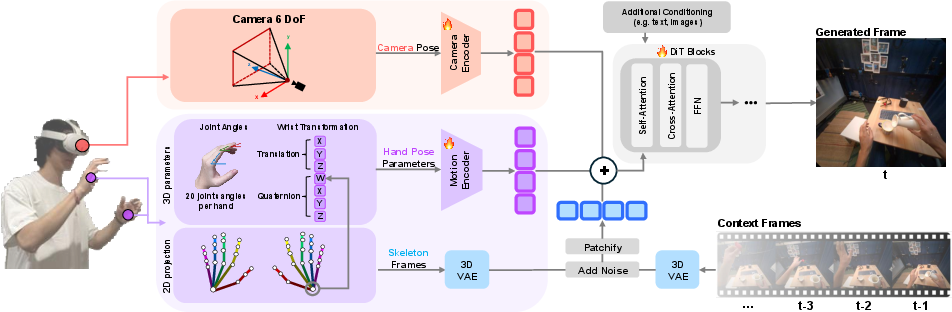
- Tracking your body: A VR headset captures where your head is pointing (your “camera”) and how your hands and fingers are positioned (every joint, not just the wrist).
- Giving the AI clear “control signals” (conditioning):
- A 2D “stick-figure” drawing of the hand (easy for the model to align with the image, but loses depth).
- A 3D description of the hand (exact wrist and finger angles, good for depth and shape).
- A hybrid that combines both the 2D stick-figure and the 3D joint angles (so the AI knows where the hand is on the screen and how it’s shaped in 3D).
- Testing how to feed signals in: They compared different “wiring methods” for getting hand information into the AI’s transformer model (you can think of these like different ways to plug a controller into a game console). They found that a method similar to “adding” the hand info to the AI’s internal tokens worked best, especially when used with the hybrid 2D–3D hand signals.
- Making it fast enough to use: Big video models are slow, so they trained a “teacher” model first (accurate but heavy), then taught a smaller “student” model (lighter and faster) to behave like the teacher. This process is called distillation. The result is an interactive system that can run around 11 frames per second with about 1.4 seconds of delay when streamed from a powerful server to a VR headset.
What did they find, and why does it matter?
- Best hand control: The hybrid approach (2D hand skeleton + 3D joint angles) gave the most accurate and stable hands—better finger positions, better depth, and fewer mistakes when hands are near the edge of the frame or partly hidden.
- Joint head + hand control: Combining head (camera) movement with hand control made the system more coherent. The video changed correctly as people looked around and used their hands to interact with objects.
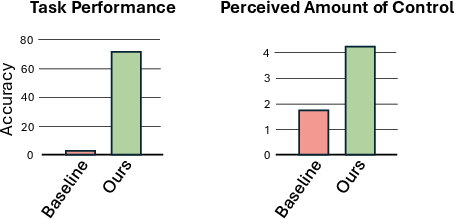
- Real-world testing with people: In a user study with three tasks—push a button, open a jar, and turn a steering wheel—people:
- Succeeded far more often when their real hand movements controlled the generated video (about 71% success) than when the system used text instructions only (about 3%).
- Felt much more in control (higher scores on a 7-point scale) when hand tracking was turned on.
- Why it matters: Today, making VR/AR content is slow and expensive because someone must build every 3D object and animation by hand. This system shows a path to “zero-shot” experiences—where the AI creates the world and its responses in real time from your motions—saving time and opening up more flexible, personalized training, learning, and entertainment experiences.
What’s the potential impact?
If improved and scaled up, this approach could:
- Make creating VR/AR content much easier by removing the need for handcrafted 3D assets.
- Enable realistic practice and training (e.g., learning hand skills) without prebuilt simulations.
- Support new forms of interactive media where your body movements directly shape the scene.
- Power smart eyewear that reacts to your hands and gaze to guide you through tasks in the real world.
The authors also note current limits—video quality can drift over time, the frame rate and latency aren’t yet as smooth as top VR standards, and stereo, high-resolution output is still challenging. But the core idea—AI-generated worlds that obey your head and hand movements—is a big step toward more natural, human-centered virtual experiences.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored, structured to be actionable for future research:
- Dataset scale and diversity: Results hinge on HOT3D (≈5.8k 5-second clips, limited scenes and motions) with a small held-out set (45 clips); it is unclear how the conditioning strategies generalize to diverse, cluttered, outdoor, or highly dynamic egocentric settings and object categories beyond the benchmarks used.
- Ground-truth evaluation limitations: Hand accuracy relies on WiLoR (pose estimator) and camera accuracy on GLOMAP (SfM from generated frames), both indirect and potentially biased by failures on synthetic content; there is no evaluation against synchronized ground-truth head/hand motion capture on generated sequences.
- Physical interaction realism: The system offers visual, not physical, hand–object interactions (no explicit physics, contact modeling, or stateful object dynamics); contact correctness, grasp stability, object affordance consistency, and physically plausible state changes are not measured.
- Long-horizon consistency and drift: Autoregressive rollouts degrade “after a few seconds” due to drift; strategies for maintaining scene continuity, memory, and state over long horizons (minutes) are not explored or benchmarked.
- Stereo rendering and depth comfort: The system’s stereo rendering is acknowledged as lagging; there is no evaluation of binocular disparity consistency, depth comfort, vertical disparity, IPD handling, vergence–accommodation conflict, or cybersickness outcomes.
- Latency and framerate constraints: Interactive performance (≈11 FPS, ≈1.4 s latency per 12-frame chunk) is far from XR comfort levels; the tradeoffs among chunk size, predictive buffering, speculative decoding, streaming protocol, and user performance are not characterized.
- On-device deployment: The approach requires a remotely streamed H100; feasibility on headset-class hardware (compute/energy budgets, model compression/quantization, distillation targets) remains open.
- Conditioning architecture scaling: Token addition outperforms other strategies on a small dataset, but it is unclear whether cross-attention, AdaLN, ControlNet variants, or gating mechanisms would surpass addition when trained at scale or with richer data.
- Disentangling camera vs hand motion: The paper notes ambiguity and training instability; principled methods for disentanglement (auxiliary losses, gradient surgery, causal masking, contrastive decorrelation) and their impact on control fidelity are not investigated.
- Hybrid 2D–3D hand representation limits: The proposed skeleton+HPP hybrid is effective in HOT3D, but its robustness under extreme occlusions, rapid motion, multi-object contact, gloves, different hand sizes, and tracking noise is not evaluated.
- Calibration and alignment: Procedures for aligning hand model parameters (UmeTrack/MANO variants), camera extrinsics, and coordinate frames across different headsets/sensors are not detailed or benchmarked for accuracy and robustness.
- Multimodal embodied control: Although the vision includes gaze, foot placement, full-body pose, and voice, the paper implements only head and hands; how to fuse and prioritize multiple inputs, resolve conflicts, and ensure coherent multimodal control is an open question.
- World geometry consistency: Generated frames lack an explicit 3D scene representation; how to enforce correct parallax, occlusion ordering, and view-dependent effects consistent with head motion remains unexplored.
- Objective measures of “task success”: For user studies (button press, jar opening, wheel turning), criteria for success are not fully specified (e.g., visual state change vs. contact/trajectory metrics), and automated evaluation protocols are lacking.
- User study scope: Small cohort (n=11), limited tasks, no statistical significance reporting, and no measurements of comfort/cybersickness, fatigue, or learning effects; generalization to diverse demographics, left-handed users, and prolonged usage is unknown.
- Personalization: There is no assessment of adapting hand shape/skin tone, articulation limits, or user-specific kinematics; how personalization impacts fidelity and control is left open.
- Robustness to tracker failures: Behavior under tracking noise, dropouts, latency spikes, miscalibration, and occlusions—common in XR—has not been systematically tested; fallback behaviors and smoothing/denoising strategies are unspecified.
- Safety and ethical considerations: The risks of hallucinated content in training/education contexts, misleading affordances, or over-trust in the generated guidance are not addressed; content safety filters, domain restrictions, and auditability remain open.
- Prompt augmentation effects: Text prompts are augmented by an LLM, consistent with pretraining, but the impact on controllability, bias, failure modes, and reproducibility is not analyzed.
- Comparative baselines fairness: CameraCtrl and other baselines differ architecturally; rigorous apples-to-apples comparisons (same backbone, training budget, data) are limited, leaving uncertainty about relative gains attributable to conditioning strategy vs. model capacity.
- Model access and reproducibility: Details on code, trained weights, datasets, and protocols needed to reproduce results (especially joint-conditioning distillation and VR integration) are incomplete or not specified.
- Metrics for egocentric manipulation: Beyond MPJPE/MPVPE and 2D L2 errors, there is a need for task-aligned metrics (contact timing, slip/penetration, object state transitions, grasp taxonomies) to better assess hand–object interaction fidelity.
- Multi-agent and collaborative XR: The framework is single-user and single-view; handling shared environments, multi-user coordination, and consistent scene state across clients is unexplored.
- Memory and state modeling: The student model generates 12-frame chunks without explicit state; incorporating recurrent memory, state-space models, or scene graphs for persistent object identities and states is an open direction.
- Failure mode analysis: Systematic characterization of typical failures (e.g., object selection errors, hand–object misalignment at frame edges, camera–hand conflict) and targeted mitigation strategies are missing.
Practical Applications
Immediate Applications
The following items outline practical uses that can be deployed now, given the paper’s demonstrated system (11 FPS, ~1.4 s latency, Quest 3 integration, hybrid 2D–3D hand conditioning, camera control, and user-study validation).
Healthcare and Rehabilitation
- Dexterity-focused VR rehab modules (e.g., opening jars, pushing buttons, turning knobs) for occupational therapy and post-stroke recovery. Sector: healthcare. Tools/workflows: a “generated reality” therapy builder that assembles task prompts and streams hand/head-conditioned video to a headset; built-in progress tracking via hand-pose metrics (MPJPE/MPVPE). Assumptions/dependencies: clinical oversight, safe task design; reliable hand tracking on consumer HMDs; adequate network and GPU access; short task durations due to drift.
- Remote tele-rehab demonstrations and patient assessment of fine motor skills (therapist designs tasks; patient completes from home with VR). Sector: healthcare. Tools/workflows: therapist-side authoring + cloud inference; patient-side guided sessions with checklists. Assumptions/dependencies: HIPAA-compliant data handling; latency tolerable for brief tasks; clinical validation for outcome use.
Education and Professional Training
- Rapid previsualization of micro-skill training scenarios without building 3D assets (lab instrument handling, simple assembly). Sector: education, industry. Tools/workflows: “training vignette generator” that turns textual task specs + tracked hands into short interactive clips; session logging integrated with LMS. Assumptions/dependencies: careful prompt design; alignment of generated visuals to real tool shapes may be approximate; limited rollout length.
- Corporate safety micro-drills (e.g., engage emergency stop, turn steering wheel) for ergonomic and situational practice. Sector: manufacturing/energy. Tools/workflows: scenario library driven by prompts and hand conditioning; objective completion metrics per task. Assumptions/dependencies: realism sufficient for recognition but not physics; safety content review.
Media, Gaming, and Creative Production
- Experience prototyping for VR titles with hand-level interaction before asset production. Sector: gaming/media. Tools/workflows: Unity plugin that streams head/hand telemetry to the autoregressive generator (“motion-to-video” overlay), with quick swapping of prompts and environments. Assumptions/dependencies: tolerance for visual drift over time; moderate latency acceptable for prototyping; rights to model outputs.
- User-generated interactive shorts with hand-driven actions (e.g., playful pet interactions, fantasy scenes). Sector: media. Tools/workflows: consumer app with curated prompts and session capture; LLM-assisted prompt augmentation for richness. Assumptions/dependencies: content moderation; compute costs; clarity that output is generative video (not true 3D).
Software and XR Tools
- SDK for hand-and-camera-conditioned I2V/T2V generation in XR stacks (Unity/Unreal) to bootstrap interaction without asset pipelines. Sector: software. Tools/workflows: “Generated Reality SDK” exposing: pose-stream APIs, hybrid conditioning, chunked inference, session metrics. Assumptions/dependencies: cloud GPU (H100-class) or local inference; headset support for 6-DoF camera + joint-level hands; integration with rendering pipelines.
- Rapid “experience storyboard” workflow for product UX teams (designing XR flows with real human motion input rather than static mockups). Sector: software/product design. Tools/workflows: capture tool + prompt library; review board with annotated hand/eye traces. Assumptions/dependencies: data privacy for tracked motion; storage of clips.
Academia and HCI Research
- Controlled studies on embodied interaction, perceived control, and hand-pose fidelity in generative XR. Sector: academia/HCI. Tools/workflows: standardized tasks (button press, jar open, steering), Likert-scale UX instruments, pose accuracy metrics (PA-MPJPE/PA-MPVPE/L2). Assumptions/dependencies: replicability with available datasets (HOT3D, GigaHands); comparable hardware and network setups.
- Dataset augmentation for egocentric perception (synthetic hand-object sequences conditioned on measured poses). Sector: computer vision. Tools/workflows: pipeline for generating labeled sequences for training pose estimators or segmentation models. Assumptions/dependencies: careful curation to avoid bias; labeling fidelity of synthetic frames.
Daily Life and Assistive Scenarios
- At-home VR “micro-tasks” for skill warmups (grip training, coordination exercises) and casual interactive experiences. Sector: consumer XR. Tools/workflows: simple prompt packs and daily streaks; optional gamified feedback based on pose accuracy. Assumptions/dependencies: consumer headset availability; acceptance of non-physical interactions; parental controls/content filters.
Policy and Governance Pilots
- Internal policy guidelines and procurement criteria for generative XR in training contexts (acceptable latency thresholds, pose accuracy targets, privacy of tracked motion). Sector: policy/compliance. Tools/workflows: checklists and governance templates; risk assessments for generative content. Assumptions/dependencies: alignment with existing digital training policies; stakeholder buy-in.
Long-Term Applications
The following opportunities require further research and engineering—e.g., higher resolution, stereo rendering, sub-20 ms latency, longer rollouts, on-device inference, physics integration, and task-specific validation.
Healthcare and Clinical Practice
- Surgical and interventional training with hand-level precision, realistic instruments, and haptics. Sector: healthcare. Potential products: “Generative OR simulator” blending real tool tracking, physics, and high-fidelity stereo video. Assumptions/dependencies: validated clinical outcomes; physics-based interaction; regulatory approvals; haptic integration.
- Smart eyewear for real-world generative guidance (fine-motor assistance for elderly or neurodivergent users). Sector: healthcare/assistive tech. Potential products: AR guidance overlays with hand-aware video augmentation. Assumptions/dependencies: on-device inference, minimal latency, robust hand tracking in-the-wild.
Education, Workforce, and Field Operations
- Vocational training in hazardous or remote environments (energy, construction) with realistic tool/object behavior and multi-step procedures. Sector: education/energy/construction. Potential products: “Generative field trainer” with task libraries and assessment analytics. Assumptions/dependencies: physics and persistence; domain-specific datasets; scenario validation with SMEs.
- Laboratory and STEM curricula that adaptively generate practice tasks aligned to student hand performance and gaze behavior. Sector: education. Potential products: adaptive XR lab companions. Assumptions/dependencies: learner modeling; accurate gaze tracking; robust metrics for skill mastery.
Robotics and Embodied AI
- Vision pretraining and policy learning using hand-conditioned egocentric world models (synthetic rollouts for in-hand manipulation, grasp planning). Sector: robotics. Potential products: “Sim2Vision” data generator for visuomotor learning; “interactive world model” for closed-loop training. Assumptions/dependencies: stable long-horizon rollouts, action semantics alignment, physics and state observability for transfer.
- Human-in-the-loop teleoperation rehearsal where operators prototype manipulation strategies in generated environments before real deployments. Sector: robotics/industry. Assumptions/dependencies: fidelity sufficient for strategy generalization; multimodal feedback (force/tactile).
Media, Gaming, and UGC Platforms
- Fully generative, assetless XR games with persistent environments and consistent object behavior, controlled by natural hand and body motions. Sector: gaming/media. Potential products: “Generative sandbox” platforms; creator tools for episodic content. Assumptions/dependencies: object permanence, memory, physics, safety moderation, high frame-rate stereo rendering.
Software, Platforms, and Hardware
- On-device generative XR engines achieving retinal stereo resolution and <20 ms motion-to-photon latency. Sector: software/hardware. Potential products: specialized chips, compressed diffusion-transformers, foveated rendering; “generative XR OS” services. Assumptions/dependencies: hardware acceleration, model distillation/quantization, energy efficiency, thermal constraints.
- Authoring platforms (“Generative Reality Studio”) offering workflows for designing tasks, testing usability, and exporting modules to enterprise LMS and game engines. Sector: software/tools. Assumptions/dependencies: standards for scenario description, metrics APIs, content governance.
Policy, Standards, and Ethics
- Standards for generative XR safety and comfort (latency, drift, motion sickness thresholds), labeling of generated content, and incident reporting. Sector: policy/regulation. Potential tools: certification programs and compliance test suites. Assumptions/dependencies: multi-stakeholder consensus; regulatory capacity.
- Privacy and IP frameworks for tracked motion data (hands, head, gaze) and zero-shot generative outputs in training and consumer apps. Sector: policy/legal. Assumptions/dependencies: legislation and case law; interoperable consent and data lifecycle policies.
Cross-Sector Training (Energy, Finance, Logistics)
- Assetless training vignettes for branch operations, customer interactions, and equipment handling (e.g., kiosk resets, ATM maintenance), emphasizing hand-level procedures. Sectors: finance/logistics/energy. Potential products: generative micro-training catalogs. Assumptions/dependencies: domain prompts and object consistency; realistic procedure scripting; compliance review.
Glossary
- Ablation study: A controlled experimental comparison of different design choices or methods to isolate their effects. "We conduct a comprehensive ablation study comparing four major hand motion conditioning strategies under identical settings, evaluating their impact on visual quality and hand motion fidelity."
- Adaptive layer normalization (AdaLN): A conditioning technique that modulates Transformer activations via learned scale and shift based on auxiliary inputs. "We compare four representative approaches: token concatenation, cross-attention, ControlNet-style branching, and adaptive layer normalization~(AdaLN) under controlled settings."
- Autoregressive: A generation approach that produces outputs sequentially, conditioning on previously generated frames. "To support causal prediction and long-horizon rollouts, autoregressive video models have been introduced~\cite{genie3, selfforcing, framePack, causVid}."
- Autoregressive distillation: Converting a non-causal teacher model into a causal student to enable sequential generation with lower latency. "Autoregressive Distillation."
- Bidirectional video diffusion model: A diffusion model that uses context from both past and future frames during training/inference. "We train a bidirectional video diffusion model teacher using this strategy and distill it into a causal, interactive system that generates egocentric virtual environments."
- Camera extrinsics: The external parameters (rotation and translation) defining a camera’s pose in world coordinates. "ReCamMaster~\cite{recammaster} injects camera extrinsic parameters through a dedicated camera encoder;"
- Causal prediction: Forecasting future frames strictly from past information without peeking ahead. "To support causal prediction and long-horizon rollouts, autoregressive video models have been introduced~\cite{genie3, selfforcing, framePack, causVid}."
- Conditional flow matching: A training objective for rectified flow models that learns a velocity field to map noise to data. "The model is trained using a conditional flow matching~\cite{lipman2023flowmatching}, with objective:"
- ControlNet: A conditioning architecture that injects structured control signals (e.g., edge maps, skeletons) into diffusion backbones. "ControlNet* represents the use of pixel-level image conditioning, but we do not copy the DiT blocks as done in the original ControlNet implementation."
- Cross-attention: An attention mechanism that fuses conditioning features (as keys/values) with main tokens (as queries). "Finally, for cross-attention fusion~(4), HPP embeddings serve as keys and values in motion-conditioned cross-attention layers injected after selected Transformer blocks, following the after-block cross-attention design of recent works~\cite{wans2v}:"
- Diffusion transformer (DiT): A Transformer-based backbone for diffusion models that operates over spatiotemporal tokens. "We explore diffusion transformer conditioning strategies for joint-level hand and head poses, identifying a hybrid 2D--3D strategy as the most effective approach."
- Egocentric: First-person perspective aligned with the user’s viewpoint. "We distill it into a causal, interactive system that generates egocentric virtual environments."
- Fréchet Video Distance (FVD): A distribution-level metric that measures realism and diversity of generated videos. "Fréchet Video Distance (FVD) for distribution-level realism."
- Forward kinematics: Computing joint positions from hierarchical rotations and translations along a kinematic chain. "Applying standard forward kinematics to the HPP analytically yields the full set of 3D poses for all joints."
- GLOMAP: A method for estimating camera trajectories from video, used to assess camera pose accuracy. "Camera pose accuracy is evaluated by extracting estimated trajectories from generated clips using GLOMAP~\cite{glomap} and computing rotation error (RotErr) and translation error (TransErr) following previous work~\cite{recammaster}."
- Hadamard product: Element-wise multiplication between tensors or vectors. "where and are learned from , and denotes the Hadamard product."
- Hand pose parameters (HPP): A parametric representation of hand articulation including wrist 6-DoF and finger joint angles. "We refer to the wrist pose and local joint rotations collectively as hand pose parameters~(HPP)."
- Head-mounted display (HMD): Wearable device with integrated display and sensors providing 6-DoF head pose. "In head-mounted display~(HMD) formats, visual content must be generated dynamically based on user interaction."
- HOT3D: A dataset of hand–object interactions with precise 3D hand and synchronized camera annotations. "Experiments are performed on the HOT3D dataset~\cite{hot3d}, which captures handâobject interactions with precise 3D hand annotations obtained via optical-marker motion capture and synchronized camera pose annotations."
- Latent video diffusion transformer: A diffusion Transformer that operates in a compressed latent space rather than pixels. "Our study builds upon the Wan family of video generation models~\cite{wan2025}, a latent video diffusion transformer capable of generating temporally coherent video from a single input image or text prompt."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning technique for large models. "For each of the conditioning strategies described in Sec.~\ref{sec:method:hands}, we train LoRA~\cite{hu2022lora} modules with rank~32 on both low-noise and high-noise experts..."
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual metric for visual similarity. "LPIPS~\cite{zhang2018unreasonableeffectivenessdeepfeatures} for perceptual similarity,"
- PA-MPJPE: Procrustes Aligned Mean Per-Joint Position Error; a 3D accuracy metric for joint positions. "we use WiLoR~\cite{wilor} to evaluate Procrustes Aligned Mean Per-Joint Position Error (PA-MPJPE) computed over 20 joints to measure 3D pose accuracy,"
- PA-MPVPE: Procrustes Aligned Mean Per-Vertex Position Error; a 3D accuracy metric for surface vertices. "and Procrustes Aligned Mean Per-Vertex Position Error (PA-MPVPE) computed over 778 vertices to measure 3D hand shape accuracy."
- Plücker embeddings: A ray representation derived from camera pose used to encode viewing geometry per pixel. "We transform the 6-DoF camera poses into per-frame Plücker embeddings ~\cite{sitzmann2022lightfieldnetworksneural}, which are then projected into the same shape as the patch tokens..."
- PSNR: Peak Signal-to-Noise Ratio; a pixel-level fidelity metric. "For video quality, we report PSNR for pixel-level accuracy,"
- Rectified flow formulation: A diffusion-like framework that linearly interpolates between data and noise and learns a velocity field. "the rectified flow formulation~\cite{esser2024scalingrectifiedflowtransformers}, where the noised latent is generated by linear interpolation:"
- Self-forcing: A distillation/training strategy to convert bidirectional diffusion models into causal autoregressive ones. "Following the self-forcing strategy, we distill a bidirectional Wan2.2 5B teacher model that is trained with our head- and hand-conditioning strategy into a causal 5B student model~\cite{selfforcing}."
- Skeleton video: A 2D visualization of joint locations and bones in pixel space used as a control signal. "In isolation, a 2D skeleton video exhibits depth ambiguity and suffers from self-occlusion..."
- SSIM: Structural Similarity Index; a metric for structural consistency between images/videos. "SSIM for structural consistency,"
- Stereo rendering: Generating distinct left/right-eye views for immersive 3D perception. "Finally, we demonstrate the downstream utility of our system by integrating it into a stereo rendering pipeline, supporting video streaming for immersive applications."
- Token addition: Conditioning by element-wise addition of embedded control features to patch tokens. "As shown in Sec.~\ref{sec:exp}, token addition yields the best performance among the evaluated pose injection approaches."
- Token concatenation: Conditioning by concatenating embedded control features with latent channels before patchification. "We compare several representative approaches, including token concatenation, addition, cross-attention, ControlNet-style conditioning, and adaptive layer normalization,"
- UmeTrack: A parametric hand model providing wrist 6-DoF and finger joint angles used to represent hand poses. "Hands are represented using the UmeTrack hand model~\cite{UmeTrack}, which includes translation and rotation of the wrist as well as rotation angles for 20 finger joints per hand."
- Variational autoencoder (VAE): A neural compression model with encoder/decoder used to map videos into latent space. "The model consists of a 3D variational autoencoder and a transformer-based diffusion model parameterized by ."
- Video diffusion models (VDMs): Diffusion-based generative models tailored to synthesize temporally coherent video. "Recent advances in video diffusion models~(VDMs) have made it possible to synthesize highly realistic and temporally coherent videos,"
- WiLoR: A hand pose estimation method used to evaluate 3D hand accuracy in generated frames. "For hand pose accuracy, we use WiLoR~\cite{wilor} to evaluate Procrustes Aligned Mean Per-Joint Position Error (PA-MPJPE)..."
- World simulators: Generative systems that predict visual outcomes given actions, enabling interactive environments. "These advances in video generation have motivated the development of world simulators, whose goal is to predict the visual consequences of actions given the current state~\cite{learninginteractiverealworldsimulators}."
Collections
Sign up for free to add this paper to one or more collections.