tttLRM: Test-Time Training for Long Context and Autoregressive 3D Reconstruction
Abstract: We propose tttLRM, a novel large 3D reconstruction model that leverages a Test-Time Training (TTT) layer to enable long-context, autoregressive 3D reconstruction with linear computational complexity, further scaling the model's capability. Our framework efficiently compresses multiple image observations into the fast weights of the TTT layer, forming an implicit 3D representation in the latent space that can be decoded into various explicit formats, such as Gaussian Splats (GS) for downstream applications. The online learning variant of our model supports progressive 3D reconstruction and refinement from streaming observations. We demonstrate that pretraining on novel view synthesis tasks effectively transfers to explicit 3D modeling, resulting in improved reconstruction quality and faster convergence. Extensive experiments show that our method achieves superior performance in feedforward 3D Gaussian reconstruction compared to state-of-the-art approaches on both objects and scenes.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces tttLRM, a new AI system that can quickly build 3D models from photos or video frames. It’s designed to handle many images at once, improve the 3D model as more pictures arrive, and still render results fast. It does this by storing what it learns “on the fly” in a smart temporary memory, then turning that memory into a clear 3D format that computers can render in real time.
What is the paper trying to figure out?
The researchers focus on three simple questions:
- How can we turn lots of images into a good 3D model quickly, without slow per-scene training?
- How can the system keep improving as new images arrive, like a live video stream?
- How can we keep the results fast to render, so the 3D model is practical for games, AR/VR, robots, and more?
How did they do it? (Methods in simple terms)
Think of building a 3D model like building a LEGO set from many pictures of the same object or scene. If you get all the pictures at once, that’s easy. But what if pictures arrive over time? You’ll want a notebook to remember what you’ve already figured out, so you can add new pieces as new photos come in. tttLRM works a lot like that.
Here are the main ideas, explained with everyday language:
- Test-Time Training (TTT) and “fast weights” = smart note-taking
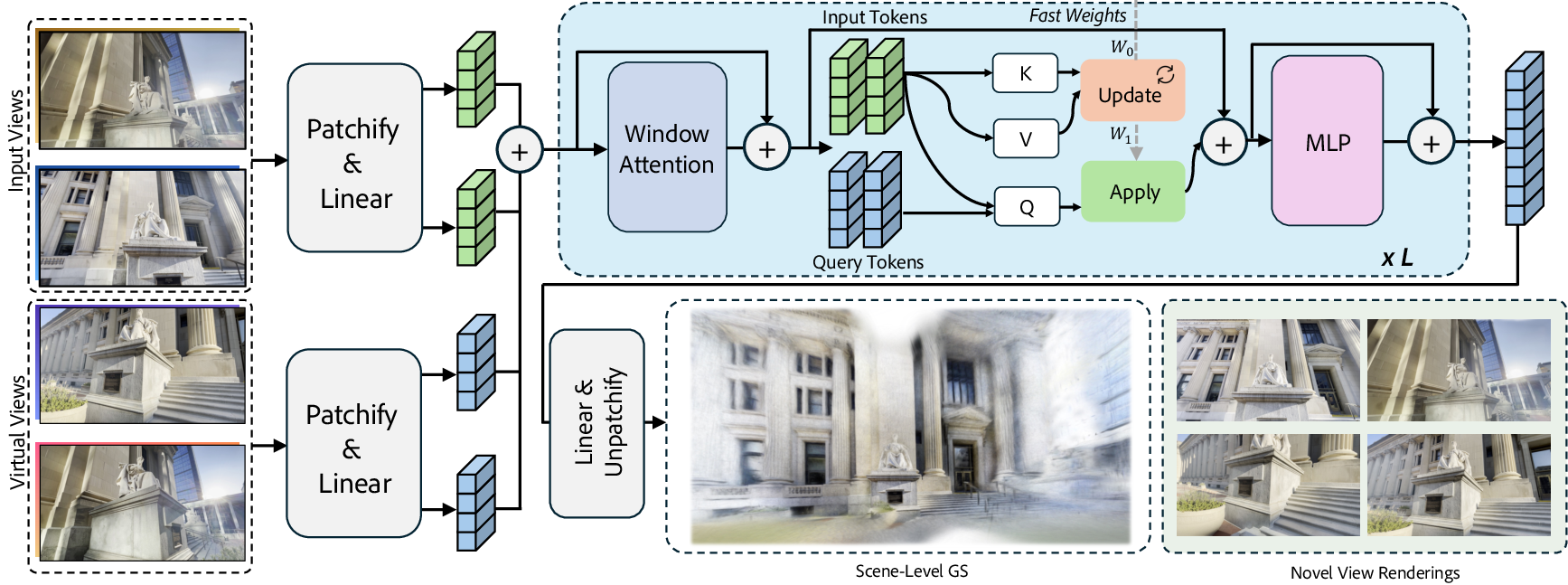
- Most AI models “learn” during training and then stop learning. With TTT, the model keeps learning a little bit while it’s being used. It stores what it learns in a small, fast-changing memory called “fast weights.” You can think of fast weights like a whiteboard where the model writes down reminders about what it’s seeing right now.
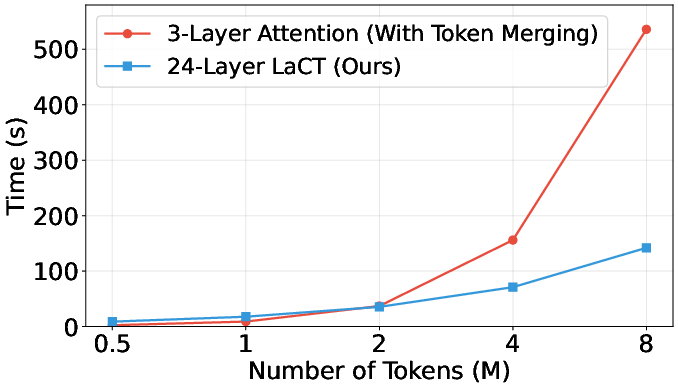
- This lets the model understand long sequences of images without getting overwhelmed, because it doesn’t try to compare every image with every other image directly. That keeps the work “linear,” meaning the time grows roughly with the number of images—not squared.
- Turning memory into 3D you can use
- The model compresses what it learns from many images into its fast-weights memory (an “implicit” 3D understanding).
- Then it “queries” that memory with virtual requests (like pretend camera views or simple feature grids) to create an “explicit” 3D model. Explicit means it’s a concrete structure the computer can render quickly.
- One of the main explicit formats they use is 3D Gaussian Splatting (3DGS): imagine a cloud of tiny, colored, blurry points that, together, form a realistic 3D scene. These are very fast to render.
- Long context and streaming (autoregressive) updates
- The model can handle long contexts (up to 64 input views and beyond) and doesn’t slow down too much as you add more images.
- It can also work like a live builder: as new images arrive, it updates its memory and refines the 3D model step by step—no need to start over.
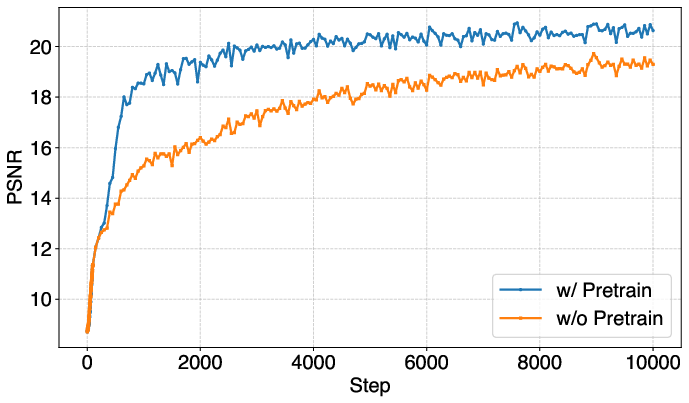
- Pretraining to learn good habits
- The model starts from a strong “base” learned on a related task called novel view synthesis (making new views of a scene). This gives it good instincts about how 3D scenes look and speeds up training, making final results better.
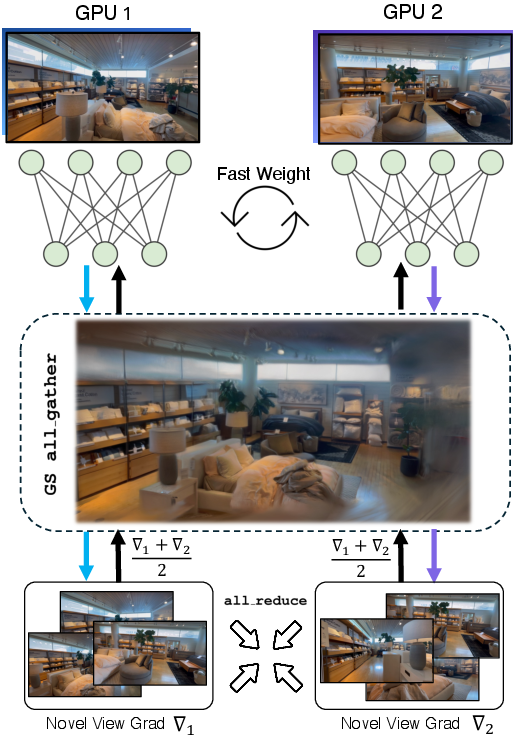
- Scaling up with multiple computers
- To handle lots of images or high-resolution pictures, they split the work across multiple GPUs (graphics cards). Each one does part of the job, and they share the memory updates. This speeds things up without losing quality.
What did they find?
The researchers tested tttLRM on individual objects and full scenes and compared it with other methods.
Here are the main takeaways:
- It handles lots of images and high resolution
- It works well with long sequences of images (e.g., 64 views) and supports high-resolution 3D reconstructions (up to 1024×1024 pixels).
- It’s fast and practical
- It builds 3D models in seconds in a feedforward pass, whereas older optimization-based methods may take many minutes per scene.
- It renders quickly because the output is an explicit 3D representation (like 3D Gaussian splats), which is efficient for real-time use.
- It improves as more images arrive
- In streaming mode, the model refines the 3D result as new views come in, so coverage and quality keep getting better.
- It makes sharper and more consistent results
- Compared with recent feedforward methods, it generally produces cleaner, sharper views of new camera angles with fewer visual glitches.
- It’s flexible
- The same approach can produce different types of 3D outputs, not just Gaussian splats. For example, it can also produce “triplanes” for NeRF-style rendering when needed.
Why is that important? Because it combines the strengths of two worlds:
- The quality and learned knowledge from neural networks.
- The speed and control of explicit 3D models that can be used in real-time systems.
What could this be used for, and what’s next?
- Practical uses
- AR/VR: build and update 3D environments quickly from a phone or headset.
- Robotics: robots can build a 3D map as they move, improving their understanding of the world.
- Movies and games: faster and easier 3D scene capture and editing.
- 3D content creation: turn a few photos (even a single one, with a helper tool) into detailed 3D assets.
- Big idea
- tttLRM shows that “learning while running” (test-time training) can act like a memory for long sequences, making 3D reconstruction both scalable and fast. It also bridges implicit understanding (neural memory) and explicit 3D models you can render instantly.
- Limitations and future work
- The fast-weights memory is a fixed size, so extremely large or very complex scenes might push its limits.
- There’s a trade-off between the absolute best image quality from heavy neural rendering and the speed of explicit 3D. Future research can improve memory, quality, and speed further—especially for real-time streaming.
In short, tttLRM is a step toward 3D systems that are smart, fast, and always improving as they see more of the world—much like how people learn from what they see.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, formulated to guide follow-up research.
- Fast-weight capacity: How does a fixed-size fast-weight memory scale with scene complexity and very long sequences (e.g., >64 or >128 views)? Characterize capacity limits and failure modes as input length grows.
- Scaling laws: No empirical scaling curves for quality, latency, and memory vs. number of input views or image resolution; provide FLOPs/memory scaling and constant-factor comparisons against attention/Mamba baselines.
- Multi-GPU sequence parallelism: Lack of quantitative analysis of throughput, latency, and communication overhead when sharding tokens and gathering Gaussians across devices; investigate scalability and bottlenecks with increasing GPUs and scene size.
- Kernel efficiency: Runtime is constrained by unoptimized TTT/LaCT kernels; quantify where time is spent and whether custom kernels or fusion can close the gap with Mamba/Transformer implementations.
- Autoregressive stability and drift: The streaming variant re-predicts full GS each step but lacks a systematic study of drift, catastrophic forgetting, or accumulation of errors under different update rules, step sizes, and batch orders.
- Update-rule ablations: Only Muon is used; no comparison with SGD/Adam/Adafactor, DeltaNet/MesaNet-style updates, or learning-rate schedules for fast-weight updates; open question which optimizer dynamics best support long-context 3D memory.
- Latency for streaming: Per-step latency, memory growth, and quality–latency trade-offs in online reconstruction are not reported; unclear if the method meets real-time constraints under modest GPU budgets.
- Virtual-token design: The effect of the number/placement of virtual views (e.g., “10 V.”) on reconstruction quality, #Gaussians, and compute is not explored; need principled strategies for virtual-view selection and budgeting.
- Representation trade-offs: The quality gap between implicit LVSM and explicit GS outputs is acknowledged but not quantified; study conditions where explicit decoding causes degradation and how to mitigate it.
- Output format generality: Triplane-based decoding is shown qualitatively; no quantitative evaluation or training details (e.g., speed, memory, NVS metrics) for alternative outputs (NeRF, triplanes, meshes).
- Mesh reconstruction: Although claimed as supported, there is no method description or quantitative mesh evaluation (e.g., Chamfer distance, normal consistency); pipeline and metrics for mesh decoding remain unspecified.
- Geometry metrics: Evaluation emphasizes NVS (PSNR/SSIM/LPIPS) without geometry accuracy (depth error, completeness, Chamfer, pose drift); future work should report geometric fidelity.
- Depth supervision choice: Monocular depth (MoGe) is used for regularization without a quantitative comparison to multi-view depth or GT depth; assess how pseudo-depth biases shape geometry and artifacts.
- Scale and depth ambiguity: The depth-to-position conversion uses “object-centric” or “linear” ranges; there’s no analysis of metric-scale consistency, bias across datasets, or failure under miscalibrated ranges.
- Camera-pose robustness: Assumes accurate, fixed poses; no study of sensitivity to pose noise, drift, or online pose refinement—critical for real-world streaming/SLAM integration.
- Dynamic or non-rigid scenes: The model assumes static scenes; behavior with moving objects, changing illumination, or non-rigid deformation is untested.
- Challenging materials and lighting: No analysis on reflective/transparent surfaces, specular highlights, low light, or exposure changes, especially given uniform lighting in object training.
- Very large scenes: Although long-context is claimed, experiments cap at 64 views and indoor-scale scenes; scalability to city-scale or outdoor scans with thousands of frames is unverified.
- Gaussian budget control: The paper suggests a trade-off between GS size and quality but does not provide methods for budgeted reconstruction (e.g., adaptive pruning, quality–size curves).
- Densification and artifact control: No mechanisms for classic GS issues (floaters, over-opaqueness) beyond simple opacity/depth regularization; explore learned densification/splitting/merging policies.
- Robustness to image quality: Tolerance to compression, noise, motion blur, or exposure variation is not evaluated; identify failure modes and augmentation strategies.
- Pretraining transferability: While LVSM pretraining helps, cross-domain generalization (e.g., synthetic → real, indoor → outdoor) and sensitivity to pretraining data are not systematically tested.
- Single-image 1024px pipeline: High-res results rely on an external multi-view generator; the impact of generator inconsistency on reconstruction quality and how to robustify the pipeline remain open.
- Autoregressive “predict & merge” alternatives: Only one merging strategy is evaluated and found suboptimal; explore hybrid strategies (e.g., confidence-weighted updates, local refinement, learned merging) to reduce recomputation while correcting errors.
- Memory interpretability: Fast weights are treated as an “implicit 3D memory,” but their content is not analyzed; is the memory view-agnostic, what spatial priors are captured, and how does it evolve over time?
- Reproducibility details: Critical hyperparameters are missing or delegated to supplemental (chunk sizes, learning rates, update frequency, fast-weight dimensions); full disclosure would aid replication.
- Downstream tasks: Claims about controllability and interpretability are not validated on downstream tasks (e.g., editing, relighting, AR/VR constraints); evaluate how explicit outputs enable these use cases.
- Comprehensive efficiency reporting: No reporting of memory footprint, #Gaussians, GS render FPS, or end-to-end throughput; provide benchmarks for both reconstruction and rendering phases under standardized hardware.
Practical Applications
Overview
Below are actionable, real-world applications derived from the paper’s findings, methods, and innovations. They are grouped into immediate (deployable now) and long-term (requiring further research, scaling, or development) applications. Each item highlights sectors, potential tools/products/workflows, and assumptions or dependencies that affect feasibility.
Immediate Applications
These can be built or integrated with existing systems today, assuming access to posed images or videos, modern GPUs, and standard photogrammetry/visual-inertial pipelines.
- High-speed content creation for games, film, and visualization [Media/Entertainment, Software]
- Tools/products/workflows:
- “tttLRM 3DGS Studio” plugin for Blender/Unreal/Unity to turn 8–64 posed images into real-time 3D Gaussian Splats (GS) assets in seconds.
- “Video-to-3D” pipeline: extract frames, estimate camera poses (e.g., COLMAP or VIO), run tttLRM to produce GS or triplane NeRF, optionally export to mesh for DCC.
- Assumptions/dependencies: Accurate camera intrinsics/extrinsics; mostly static scenes; GPU availability; integration with a 3DGS renderer; handling of large assets via sequence parallelism.
- Rapid e-commerce product digitization from photos [Retail, Marketing, Software]
- Tools/products/workflows:
- Web service/API that ingests a small set of product shots or a short turntable video and outputs a lightweight 3DGS model for interactive product viewers.
- Single-image-to-3D flow using a multi-view generator + tttLRM for high-res (up to 1024 px) reconstruction of fine detail (hair, fur, text).
- Assumptions/dependencies: Multi-view generator availability for single-image cases; consistent lighting; consumer-grade pose estimation; privacy/compliance for user uploads.
- Live AR/VR scene capture with progressive refinement [XR, Software]
- Tools/products/workflows:
- “Autoregressive 3D capture app” on mobile: as the user pans, fast weights update and the 3DGS improves in real-time; supports 16–64 views with linear complexity.
- Remote assistance AR workflows where a technician streams views and gets progressively better 3D context for guidance.
- Assumptions/dependencies: On-device or edge GPU; robust VIO/SLAM to provide poses; mostly static or slowly changing scenes; memory limits for very large spaces.
- Warehouse and indoor robotics world modeling [Robotics, Logistics]
- Tools/products/workflows:
- Perception module that converts streaming camera input into explicit 3DGS for fast planning, obstacle avoidance, and inventory visualization.
- Integration into ROS pipelines as a feedforward reconstruction node with autoregressive updates.
- Assumptions/dependencies: Reliable pose from VIO/IMU/camera; static background preferred; domain-specific fine-tuning for industrial lighting and textures.
- AEC site capture and previsualization [Architecture/Engineering/Construction]
- Tools/products/workflows:
- “Scan-to-3DGS” walkthrough workflow: capture a site with a phone or 360 camera; tttLRM generates a navigable 3DGS for quick design review before full Scan-to-BIM.
- Draft-quality reconstructions for rapid progress reporting or clash pre-checks.
- Assumptions/dependencies: Indoor/outdoor domain adaptation; robust pose estimation for long corridors and repetitive structures; export bridges to CAD/mesh as needed.
- Cultural heritage and museum digitization [Cultural Heritage, Education]
- Tools/products/workflows:
- Artifact digitization from curated photo sets; export 3DGS for real-time web viewers and optional mesh conversion for archival.
- Assumptions/dependencies: Controlled capture for reflective materials; licensing and provenance tracking; fixed memory size may limit very large exhibits.
- Insurance and property documentation [Finance/Insurance, Real Estate]
- Tools/products/workflows:
- Rapid claim documentation: reconstruct damaged areas from user video; deliver navigable 3D to adjusters.
- Rental/property tour digitization for listings.
- Assumptions/dependencies: Static scenes; privacy-safe data handling; pose estimation reliability; acceptance of GS assets by insurers and platforms.
- Academic research and benchmarking [Academia]
- Tools/products/workflows:
- Use tttLRM as a baseline for feedforward, long-context reconstruction; study test-time training memory (fast weights) and autoregressive inference.
- Extend decoding to other formats (e.g., triplane NeRFs), compare quality vs speed trade-offs; evaluate sequence parallel scaling.
- Assumptions/dependencies: Access to datasets like DL3DV-10K, Objaverse; reproducible preprocessing; GPU clusters for sequence-parallel experiments.
- Developer SDKs and cloud services [Software]
- Tools/products/workflows:
- “tttLRM SDK” for Python/C++ with exporters (3DGS, triplane, mesh).
- Cloud inference service using sequence parallelism to batch user jobs, accelerating 64-view reconstructions.
- Assumptions/dependencies: Optimized kernels for LaCT/TTT; orchestration for multi-GPU scaling; cost management for high-resolution jobs.
- Emergency response mapping (rapid situational awareness) [Public Safety, Government]
- Tools/products/workflows:
- Drone/body-cam footage to quick 3DGS of an affected area for responders.
- Assumptions/dependencies: Stable poses from aerial platforms; static/dominant static content; safety and privacy policies for captured environments.
Long-Term Applications
These will benefit from further research, domain adaptation, hardware optimization, and broader ecosystem support (pose estimation, dynamic scene handling, semantics, compliance).
- Real-time AR on headsets with on-device reconstruction [XR, Hardware]
- Tools/products/workflows:
- On-headset autoregressive tttLRM reconstructing rooms and objects on the fly; progressive 3DGS streamed to collaborative apps.
- Assumptions/dependencies: Efficient kernels and power-constrained inference; robust SLAM; memory mechanisms beyond fixed fast weights for very large areas; dynamic scene modeling.
- Autonomous driving and city-scale mapping [Robotics/Autonomous Vehicles, Smart Cities]
- Tools/products/workflows:
- Incremental city meshes and GS built from fleets; digital twins updated continuously for simulation and planning.
- Fusion with LiDAR/radar; semantic layers for drivable surfaces and hazards.
- Assumptions/dependencies: Multi-sensor calibration; domain-specific training for outdoor, dynamic objects; scalability of fast-weight memory and distributed mapping; regulatory compliance for data collection.
- Medical 3D reconstruction (endoscopy, arthroscopy, ultrasound) [Healthcare]
- Tools/products/workflows:
- Clinical tools that reconstruct anatomy from multi-view medical video for navigation and documentation.
- Assumptions/dependencies: Specialized training on medical domains; camera calibration in minimally invasive devices; handling specular fluids/tissue; clinical validation, safety, and regulatory approval (FDA/CE).
- Utility and infrastructure digital twins [Energy, Utilities]
- Tools/products/workflows:
- Drone-based inspection pipelines that output GS/mesh for power lines, substations, pipelines; condition monitoring over time.
- Assumptions/dependencies: Outdoor robustness; integration with asset management; temporal consistency across inspections; environmental constraints (wind, lighting).
- Agriculture field modeling from drone captures [Agriculture]
- Tools/products/workflows:
- Field-scale 3D reconstructions for yield estimation and irrigation planning; integration with multispectral imagery.
- Assumptions/dependencies: Domain adaptation for vegetation; dynamic elements (wind) and seasonal changes; large-scene memory scaling.
- Telepresence and volumetric communications [Media/Telecom]
- Tools/products/workflows:
- Live volumetric capture streams that improve with additional viewpoints; progressive 3D assets for remote collaboration and training.
- Assumptions/dependencies: Low-latency edge inference; dynamic scene modeling; compression and streaming standards for GS-like assets.
- Insurance automation and risk modeling at scale [Finance/Insurance]
- Tools/products/workflows:
- Automated appraisals from user walkthroughs; 3D-based risk scoring for underwriting; audit trails and explainability.
- Assumptions/dependencies: Standardized capture protocols; fair models across property types; privacy, security, and governance for 3D data.
- Policy frameworks and standards for 3D recon data [Policy/Government]
- Tools/products/workflows:
- Guidelines for privacy, consent, and data retention in large-scale 3D reconstruction; watermarking/traceability for AI-generated reconstructions.
- Procurement standards for public-sector digitization (disaster response, urban planning).
- Assumptions/dependencies: Multi-stakeholder input; formal compliance regimes; interoperability standards across formats (GS, meshes, NeRF).
- 3D memory middleware and active view planning agents [Software, Robotics]
- Tools/products/workflows:
- “Fast-weight 3D memory” services that multiple applications can query for different representation needs (GS/NeRF/mesh) without retraining.
- Agents that select next-best-views to optimize coverage and quality, closing the loop between capture and reconstruction.
- Assumptions/dependencies: Robust APIs for decoding multiple formats; integration with planners/LLMs; metrics for quality improvement and stopping criteria.
- Semantic and dynamic scene extensions [Academia, Software]
- Tools/products/workflows:
- tttLRM variants that attach semantics (materials, instance labels) and handle non-rigid motion, enabling richer downstream tasks (AR occlusion, robot manipulation).
- Assumptions/dependencies: New training regimes and losses; multi-modal data (depth, IMU); memory designs that accommodate changes over time.
- XR asset streaming and CDNs for progressive 3D [Software/Cloud]
- Tools/products/workflows:
- “Autostream 3D” services that distribute progressively refined GS assets over networks, adapting fidelity to bandwidth and device capabilities.
- Assumptions/dependencies: Streaming formats for GS/triplane; client decoders on mobile; caching and versioning of progressive reconstructions.
Cross-cutting assumptions and dependencies
- Camera pose availability: The method assumes accurate intrinsics/extrinsics; pipelines must include VIO/SLAM or structure-from-motion.
- Scene characteristics: Best for predominantly static scenes; dynamic objects and strong specularities may require additional modeling.
- Compute: Modern GPUs (edge or cloud) are needed; performance benefits increase with optimized LaCT/TTT kernels and multi-GPU sequence parallelism.
- Representation choices: Downstream tasks may prefer GS for real-time rendering; conversions to meshes/NeRFs are possible but may add steps.
- Domain adaptation: Quality may degrade on unseen domains; pretraining and fine-tuning (e.g., LVSM initialization) improve convergence and fidelity.
- Memory limits: Fixed fast-weight memory can constrain extremely large or complex scenes; future work may extend memory capacity or hierarchical models.
- Compliance and data governance: Privacy, consent, and security are necessary in consumer, medical, and public-sector deployments.
Glossary
- 3D Gaussian Splatting (3DGS): An explicit neural scene representation that models scenes as sets of anisotropic 3D Gaussians rendered in real time by splatting. "3D Gaussian Splatting~\cite{kerbl20233d, huang20242d} has become the state-of-the-art neural scene representation."
- attenuation factors: Coefficients in state-space or recurrent models that down-weight older information during state updates. "incorporate attenuation factors into the state updates"
- autoregressive: A causal sequence modeling approach where predictions condition on prior inputs/outputs in order. "enabling high-resolution, long-context, autoregressive 3D reconstruction."
- bidirectional attention: An attention mechanism where tokens attend to both past and future positions, increasing context but often at higher cost. "its use of bidirectional attention layers hinders further scalability"
- COLMAP: A popular structure-from-motion and multi-view stereo pipeline for estimating camera poses and sparse/dense 3D. "with camera pose annotation obtained from COLMAP~\cite{pan2024global}."
- coordinate-based MLP: A neural network that maps continuous spatial coordinates (and view direction) to radiance/density for neural fields. "leverages a coordinate-based MLP to predict per-point color and density"
- cost volumes: 3D tensors aggregating matching costs across candidate depths to facilitate multi-view stereo depth estimation. "builds cost volumes using plane sweep for per-view depth estimation."
- Distributed Data Parallel (DDP): A parallel training paradigm that synchronizes gradients across devices for consistent updates. "through PyTorch Distributed Data Parallel (DDP)"
- fast weights: In-test-time-learned parameters that act as a short-term memory updated from input data to capture current-context relationships. "fast weights of the TTT layer"
- feedforward reconstruction: One-shot inference of 3D representations from inputs without per-scene optimization loops. "our method achieves superior performance in feedforward 3D Gaussian reconstruction"
- Gaussian primitives: Basic Gaussian elements (position, scale, rotation, opacity, color) used to explicitly represent 3D scenes. "represents the scene with simple Gaussian primitives"
- Gaussian Splats (GS): The per-element 2D projection/rendering of 3D Gaussian primitives used in 3DGS. "such as Gaussian Splats (GS) for downstream applications."
- hash grids: Multi-resolution hashed feature grids that efficiently encode spatial fields for fast neural field queries. "including voxels~\cite{liu2020neural, sun2022direct}, points~\cite{xu2022point}, hash grids~\cite{muller2022instant}, and triplanes~\cite{gao2023strivec, chan2022efficient, chen2022tensorf}."
- K-means clustering: An unsupervised method used here to select diverse input views based on camera positions and directions. "selected based on K-means clustering based on camera positions and view directions."
- key–value (KV) cache: A compressed memory of key–value pairs enabling efficient sequence querying in attention-like mechanisms. "encode the keyâvalue (KV) cache of the input sequence into a fixed-size neural memory."
- LaCT (Large Chunk Test-Time Training): A TTT variant that updates fast weights using large token chunks for high throughput on long sequences. "Large Chunk Test-Time Training (LaCT) layer"
- linear attention: An attention approximation that reduces quadratic complexity by using kernelizable feature maps for keys/queries. "Linear attention models~\cite{katharopoulos2020transformers, shen2021efficient, schlag2021linear} approximate the softmax kernel with linearized feature maps to achieve linear complexity"
- LPIPS: A perceptual distance metric comparing deep feature differences between images. "we report three metrics to evaluate novel view synthesis quality: PSNR, SSIM, and LPIPS~\cite{zhang2018perceptual}."
- mean-square error (MSE): A regression loss measuring average squared difference between predictions and targets. "using mean-square error:"
- Mamba: A state-space-model-based sequence architecture with continuous-time dynamics and decay mechanisms. "Mamba~\cite{gu2021efficiently, dao2024transformers, liu2024vmamba} proposes ``date-dependent decay" to model sequences as continuous-time dynamical systems"
- monocular depth estimator: A model predicting per-pixel depth from a single image, used here as pseudo ground truth. "We opt for using the monocular depth estimator~\cite{wang2025moge} for pseudo ground truth"
- Muon optimizer: An optimization algorithm used to update model parameters (and fast weights) stably and robustly. "using Muon~\cite{jordan6muon} optimizer"
- NeRF (Neural Radiance Fields): A continuous neural representation mapping 3D+view direction to color/density with volumetric rendering. "NeRF~\cite{mildenhall2021nerf} represents the scene as a continuous field"
- novel view synthesis (NVS): Rendering unseen viewpoints from learned scene representations. "novel view synthesis quality"
- opacity regularization: A loss term that encourages sparsity by penalizing unnecessary opacity in Gaussians. "we also use opacity regularization to reduce the number of Gaussians."
- Patchify: The operation of dividing images into non-overlapping patches before tokenization. "After dividing each image into non-overlapping patches of size "
- perceptual loss: A loss computed on deep features (e.g., VGG-19) to align perceptual similarity of images. "perceptual loss based on VGG-19 features~\cite{simonyan2014very}"
- photometric reconstruction losses: Image-space losses comparing rendered and ground-truth pixels for supervision. "computes photometric reconstruction losses against the ground truth"
- plane sweep: A technique that hypothesizes depths by sweeping planes through space to build matching costs. "using plane sweep for per-view depth estimation"
- PSNR: Peak Signal-to-Noise Ratio, a fidelity metric for image reconstruction quality. "we report three metrics to evaluate novel view synthesis quality: PSNR, SSIM, and LPIPS"
- QK-normalization: Normalization applied to queries/keys in attention for numerical stability. "with QK-normalization for stability."
- ray embeddings: Encodings of per-pixel camera ray origin/direction concatenated with image features. "concatenate them channel-wise with their ray embeddings"
- RNN-like inference process: An online, stateful inference regime where internal memory evolves with streamed inputs. "This design effectively transforms the model into an RNN-like inference process"
- scale-invariant depth loss: A depth supervision that ignores global scale to focus on relative depth consistency. "scale-invariant depth loss \cite{ziwen2025long}"
- sequence parallelism: Distributing tokens across devices to parallelize long-sequence processing and training. "we introduce sequence parallelism for training feedforward reconstruction models"
- SSIM: Structural Similarity Index Measure, a perceptual metric assessing structural similarity between images. "we report three metrics to evaluate novel view synthesis quality: PSNR, SSIM, and LPIPS"
- State Space Models (SSMs): Sequence models that evolve a hidden state over time to capture history efficiently. "State Space Models (SSMs) introduce a state variable to represent historical information"
- structure-from-motion: A geometric pipeline reconstructing camera motion and 3D structure from image sequences. "structure-from-motion~\cite{schonberger2016structure}"
- Test-Time Training (TTT): Updating a subset of model parameters (fast weights) at inference using self-supervised objectives to adapt to current inputs. "Test-Time Training (TTT) layer"
- triplane: A compact 3D feature representation using three axis-aligned feature planes queried for rendering or reconstruction. "a triplane feature grid for NeRF-based reconstruction"
- virtual tokens: Learnable or constructed query tokens used to probe fast weights for output representations. "we introduce a set of virtual tokens that serve as queries"
- virtual views: Synthetic camera views used as queries to decode explicit 3D parameters (e.g., Gaussians). "In 3DGS reconstruction, these virtual tokens are virtual views"
- volumetric rendering: Rendering technique that integrates color and density along camera rays through a continuous field. "enabling differential volumetric rendering"
- window attention: Local attention computed within spatial windows to capture intra-view locality efficiently. "Each LaCT layer includes a window attention module"
Collections
Sign up for free to add this paper to one or more collections.