Why Pass@k Optimization Can Degrade Pass@1: Prompt Interference in LLM Post-training
Abstract: Pass@k is a widely used performance metric for verifiable LLM tasks, including mathematical reasoning, code generation, and short-answer reasoning. It defines success if any of $k$ independently sampled solutions passes a verifier. This multi-sample inference metric has motivated inference-aware fine-tuning methods that directly optimize pass@$k$. However, prior work reports a recurring trade-off: pass@k improves while pass@1 degrades under such methods. This trade-off is practically important because pass@1 often remains a hard operational constraint due to latency and cost budgets, imperfect verifier coverage, and the need for a reliable single-shot fallback. We study the origin of this trade-off and provide a theoretical characterization of when pass@k policy optimization can reduce pass@1 through gradient conflict induced by prompt interference. We show that pass@$k$ policy gradients can conflict with pass@1 gradients because pass@$k$ optimization implicitly reweights prompts toward low-success prompts; when these prompts are what we term negatively interfering, their upweighting can rotate the pass@k update direction away from the pass@1 direction. We illustrate our theoretical findings with LLM experiments on verifiable mathematical reasoning tasks.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of the paper
What is this paper about?
This paper looks at how we judge and train LLMs on tasks where we can automatically check if an answer is correct (like math problems or code). Two common scores are:
- pass@1: Did the model get it right on the first try?
- pass@k: If the model gets k tries, did any of those tries get it right?
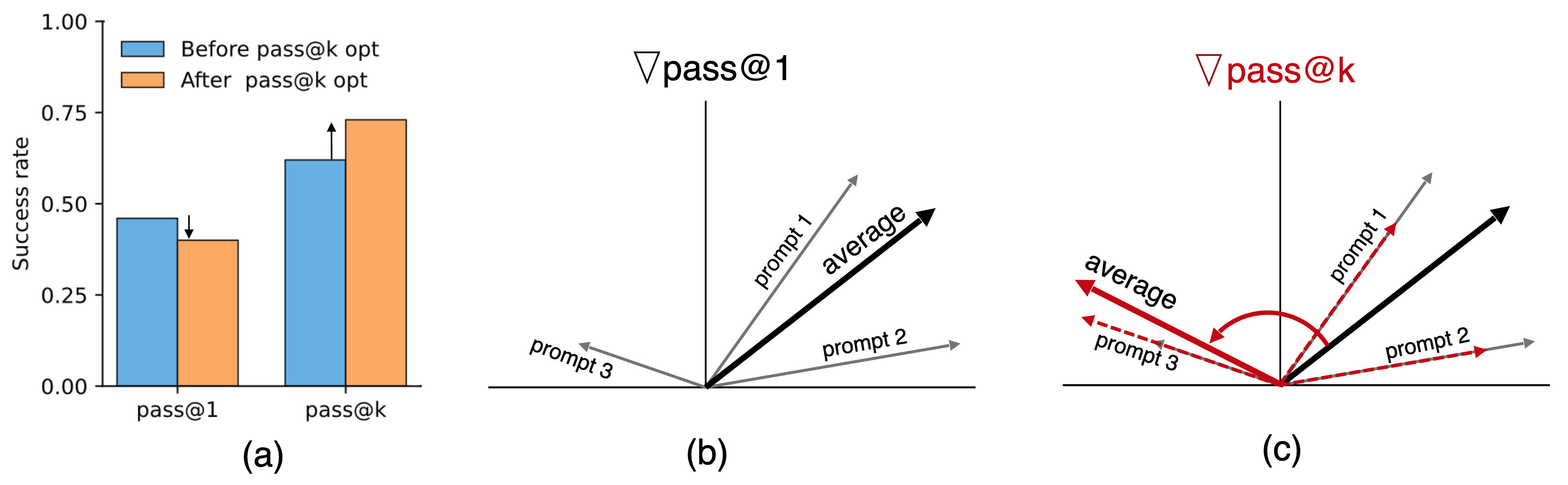
People have started training models to do better at pass@k (many tries). But there’s a recurring problem: when pass@k goes up, pass@1 sometimes goes down. This paper explains why that happens and when we should expect it.
What questions did the researchers ask?
- Why can training a model to be good with multiple tries (pass@k) make it worse on the first try (pass@1)?
- When does this trade-off happen, and what controls how strong it is?
How did they study it? (In plain language)
First, two quick ideas:
- pass@1 vs pass@k:
- pass@1 is like taking a test with one shot.
- pass@k is like having k “lives.” If any attempt is correct, you count it as a success.
- Shared settings (parameters):
- An LLM uses the same “knobs” (its parameters) to answer all kinds of questions. Turning a knob to help one question can accidentally hurt another.
The authors introduce a key idea called “prompt interference”:
- Think of two questions (prompts). If changing the model to do better on Question A also helps Question B, they “positively interfere.”
- If improving on A makes B worse, they “negatively interfere.”
- Because one model must answer everything using shared knobs, negative interference can happen when two prompts “want” opposite changes.
They then show how pass@k training changes which questions the model pays attention to:
- pass@k puts much more focus on “hard” questions the model usually gets wrong (because getting even one of k tries right matters most for those).
- pass@1 treats all questions more evenly.
In simple terms, pass@k training is like a coach who says, “Let’s spend most of our time on the questions we usually fail.” That’s good for succeeding in multiple tries, but risky if those “hard” questions are negatively interfering with the “easy” ones we already do well on. The model might shift so much to fix the hard stuff that its first-try answers on easy stuff get worse.
They back this up with:
- A toy example: Two very similar-looking questions, one easy and one hard, need opposite parameter tweaks. If training heavily prioritizes the hard one (as pass@k does), it pushes the model in a direction that helps the hard one but hurts the easy one—so pass@1 drops even while pass@k improves.
- Real experiments with math problems and two LLMs, showing this effect in practice.
A bit of gentle technical translation:
- The paper uses “gradients” to describe “which way to turn the knobs.” If the pass@k gradient (the direction that improves pass@k) points the opposite way from the pass@1 gradient, they say there is “gradient conflict.” That means a step that helps pass@k can harm pass@1.
- They prove that pass@k training effectively “reweights” prompts to focus on low-success prompts. If those are negatively interfering, this reweighting can flip the overall direction away from what would help pass@1.
What did they find, and why does it matter?
Here are the main takeaways, explained simply:
- Training for pass@k can conflict with training for pass@1:
- Because pass@k focuses on hard, low-success prompts, it can move the model in a direction that’s bad for first-try accuracy when those hard prompts negatively interfere with others.
- The size of k matters:
- Bigger k means even more focus on hard prompts. That makes the conflict more likely and stronger.
- They give conditions for when the clash happens:
- If many of the hard prompts negatively interfere with the rest, and the model puts big weight on them (which pass@k does), then the gradients point in opposite directions. In that case, a training step that helps pass@k can reduce pass@1.
- They prove a one-step effect:
- Under reasonable step sizes, a single pass@k training step can increase pass@k while decreasing pass@1 at the same time.
- Real LLM experiments confirm it:
- On math reasoning tasks, they measured how much pass@k training emphasizes hard prompts and showed that those prompts often have negative interference. The result: the direction that improves pass@k indeed pushes against the direction that improves pass@1.
Why this matters:
- In real systems, pass@1 is still crucial because trying multiple times costs time and money, and verifiers (the automatic checkers) aren’t perfect. You often need a strong single-shot answer.
- So a training plan that boosts pass@k but hurts pass@1 can make a model worse for practical use, even if the headline pass@k score looks great.
What does this mean for the future?
- Be careful when fine-tuning only for pass@k. It can silently weaken first-try performance.
- If you need good single-shot answers, consider training strategies that:
- balance pass@1 and pass@k,
- detect and downweight negatively interfering prompts,
- or limit how large k is during optimization.
- The paper’s theory provides a checklist: if many hard prompts conflict with easy ones, and you crank up k, expect pass@1 to suffer unless you counteract that.
In short: Optimizing for “getting it right in several tries” can come at the cost of “getting it right the first time,” especially when hard questions fight against easy ones inside the model’s shared settings. The authors explain why, show when it happens, and confirm it with real models—so builders can make smarter choices about how they train LLMs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of gaps and open questions that remain unresolved and could guide future research:
- Scope across tasks and domains: The theory and experiments are demonstrated primarily on math reasoning; it is unclear whether the same prompt interference dynamics and pass@k–pass@1 trade-offs hold for code generation, long-form reasoning, natural language QA, and other verifiable tasks.
- Full-training validation: Experiments assess gradient conflict (inner products) but do not run end-to-end pass@k fine-tuning on real LLMs to measure actual changes in pass@1 and pass@k over many training steps and datasets; the magnitude and stability of the trade-off during full training remains unquantified.
- Dependence on sampling strategy: The analysis assumes i.i.d. samples per prompt; in practice, decoding methods (temperature, top-p/top-k, beam search, reranking, self-consistency) induce dependencies and selection effects. How do correlated samples, reranking, or majority-vote objectives change the pass@k gradient and the interference conditions?
- Verifier imperfections: The theory assumes a perfect binary verifier. What changes when the verifier has false positives/negatives or partial/continuous rewards (e.g., partial credit in math or code coverage)? How do noise and mis-specification in rewards alter the implicit reweighting and the conflict conditions?
- Multi-step optimization dynamics: Results focus on one-step updates with small step sizes. How do pass@k and pass@1 evolve over many optimization steps with adaptive optimizers (Adam, momentum), learning-rate schedules, and regularization? Are there convergence regimes that avoid pass@1 degradation?
- Practical detection of negatively interfering prompts: The agreement score requires per-prompt gradient estimates that are expensive and noisy at LLM scale. Can we design reliable, low-cost estimators or proxies (e.g., influence functions, Fisher information, prompt features) to identify and control negatively interfering prompts in training?
- Estimating the k-threshold in practice: Proposition-derived thresholds depend on unknown quantities (e.g., ε, δ, q, m). How can practitioners estimate these from finite data to decide safe k values or detect phase transitions where pass@1 becomes vulnerable?
- Mitigation strategies: The paper characterizes the cause but offers no concrete remedies. Can gradient-surgery, constrained updates (e.g., projecting onto non-negative agreement subspace), multi-objective optimization (joint pass@1/pass@k), or curriculum/reweighting schemes reduce interference while preserving pass@k gains?
- Model architecture and parameter granularity: Empirical gradients are taken w.r.t. the final hidden layer only. Do interference patterns persist for full-parameter updates, LoRA adapters, Mixture-of-Experts, or prompt routing architectures that reduce cross-prompt coupling?
- Baselines and advantage shaping: Pass@k gradients are derived for the raw objective; practical RL fine-tuning uses baselines/advantages and variance reduction. How do these choices alter the effective reweighting and conflict, and can they be tuned to attenuate interference?
- Estimator variance and stability: Extreme weight disparities (e.g., ≈1028:1) imply very high variance in gradient estimates and potential instability. What normalization, clipping, or control-variates are needed to make pass@k optimization robust?
- Distribution shift and curation: The trade-off is analyzed under a fixed prompt distribution. How does dataset curation, domain shift, or hard-example mining affect the prevalence of negative interference and the pass@1/pass@k trade-off at deployment?
- Beyond binary success: Many tasks have graded correctness or multiple acceptable solutions. Extend the theoretical framework to non-binary, structured, or soft verifiers and characterize how the reweighting and conflict change.
- Semantic interpretability of interference: The kernel-based definition is gradient-centric. Can we connect negative interference to semantic or structural properties (topics, solution styles, reasoning steps) to build interpretable and cluster-aware training strategies?
- Operational objectives and constraints: Pass@1 often matters due to latency/cost constraints. How should training explicitly incorporate operational constraints (e.g., minimum pass@1) into pass@k optimization, and what are the Pareto frontiers?
- Validity of smoothness assumptions for LLMs: The theoretical results rely on Lipschitz/smoothness bounds typical for small policies; it is unclear if these hold or how to calibrate constants for transformer LLMs. Can we empirically validate or adapt these assumptions?
- Alternative inference objectives: Best-of-k with reranking, self-consistency, and verifier-guided search differ from pure pass@k. Do these objectives exhibit similar interference, and can they be designed to avoid pass@1 degradation?
- Heterogeneity beyond “hard prompts”: Negative interference may arise in subsets that are not simply low-success prompts. How prevalent is interference across subpopulations, and can we predict it without relying solely on pθ(x)?
- Covariance condition estimation: The key condition uses covariance of weights and agreement scores. How can we reliably estimate this covariance at scale with few samples and use it to trigger safeguards during training?
- Scalability of per-prompt gradients: Computing aθ(x) and κθ(x, x′) at scale is expensive. Develop scalable approximations or sampling strategies that preserve fidelity while making interference-aware training feasible for large datasets.
Glossary
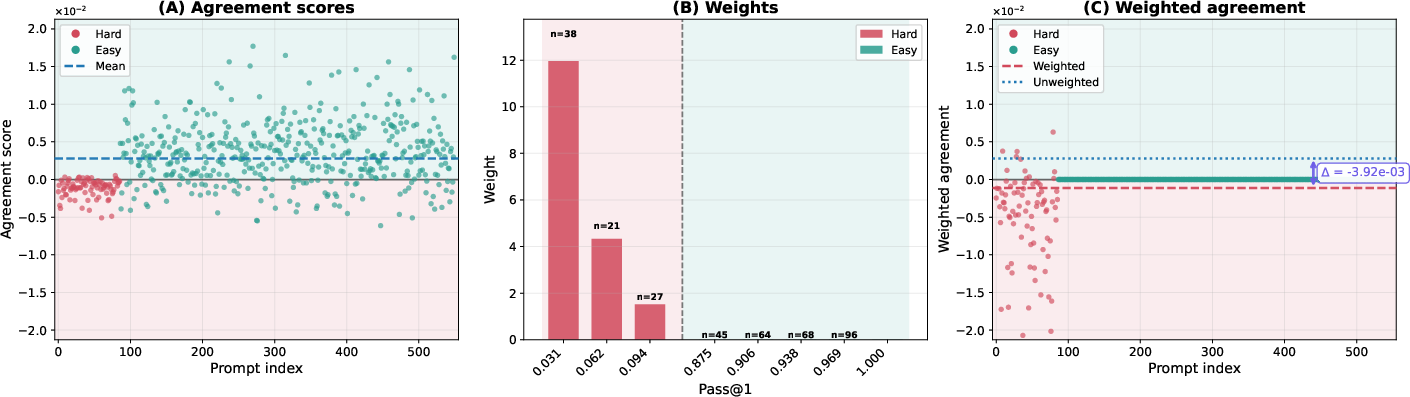
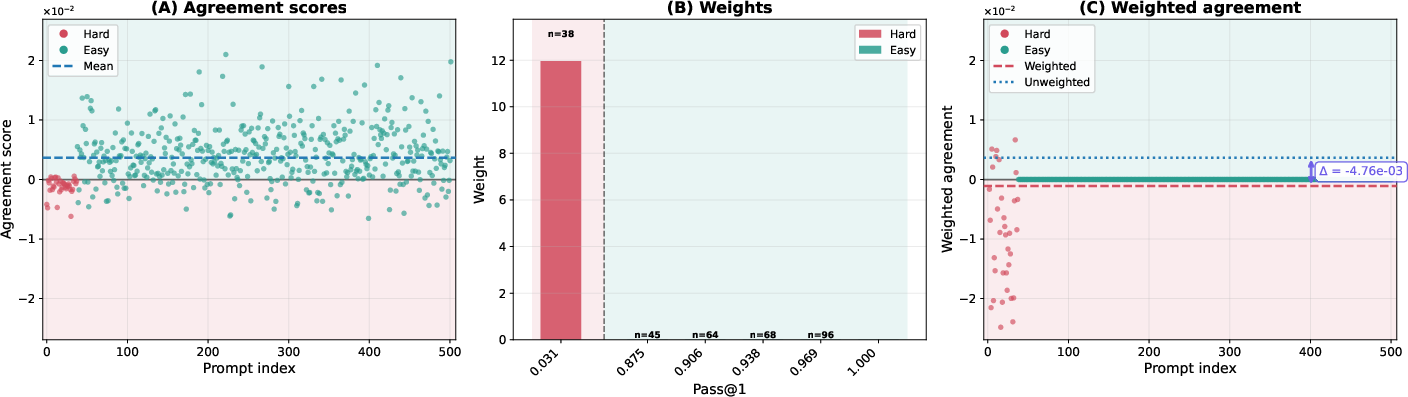
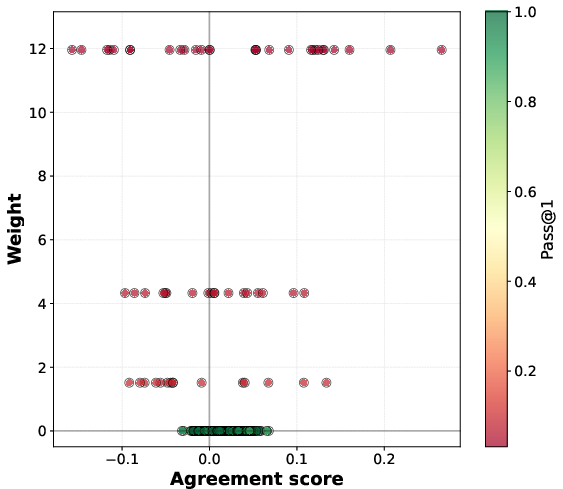
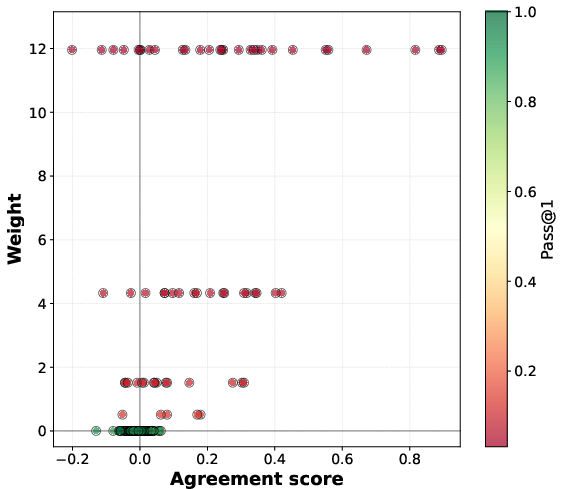
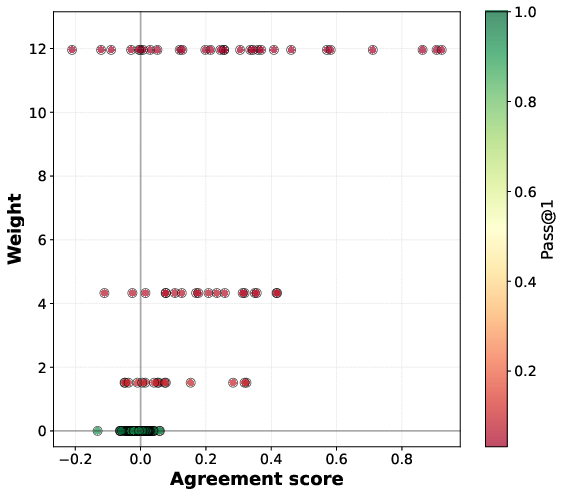
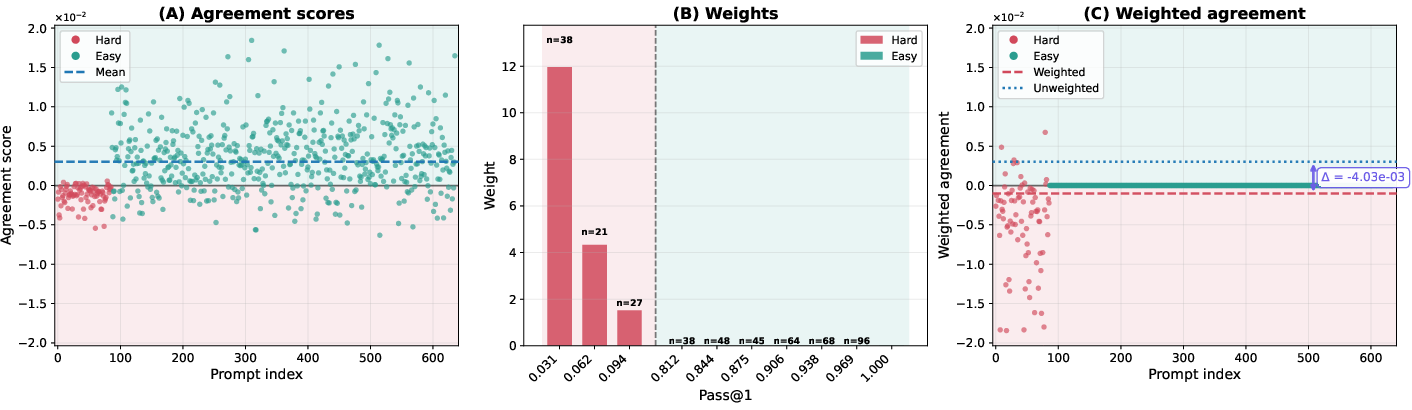
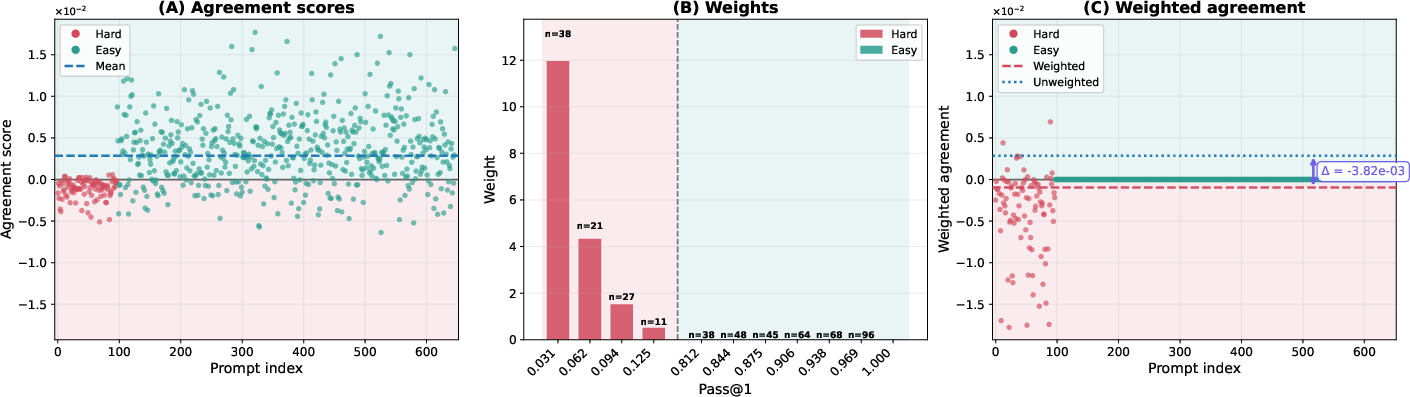
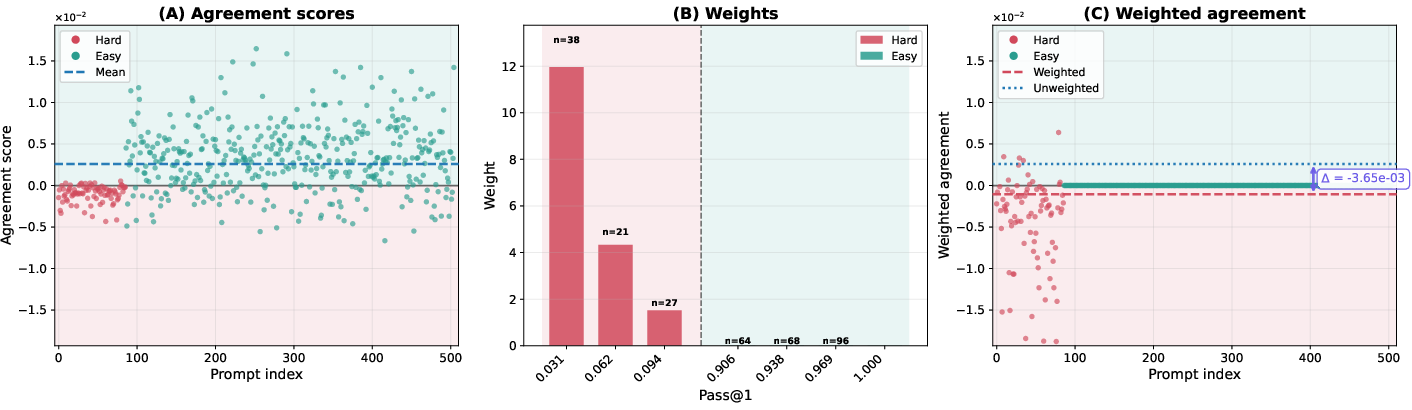
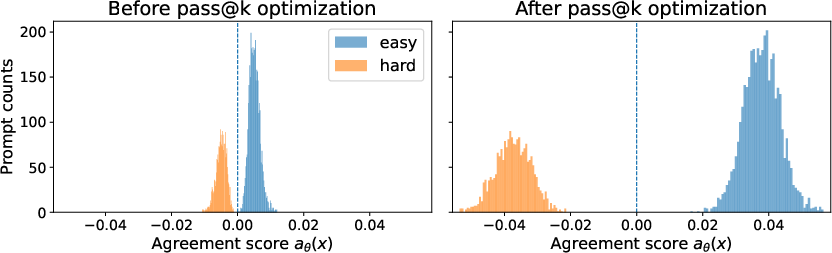
- Agreement score: A scalar that measures how a prompt’s pass@1 gradient aligns with the overall pass@1 gradient, indicating whether improving that prompt helps or hurts average performance. "This agreement score quantifies the prompt-level gradient interference with the average pass@1 objective."
- Binary reward verifier: An automatic checker that returns 1 for a correct response and 0 otherwise, enabling verifiable evaluation. "We suppose we have access to a binary reward verifier which encodes correctness of response~ for prompt ."
- Contextual-bandit abstraction: A simplified decision-making model with contexts (prompts), actions (completions), and rewards (verifier outcomes) used to analyze LLM behavior. "We consider a minimal contextual-bandit abstraction of verifier-based multi-sample LLM evaluation as a running example."
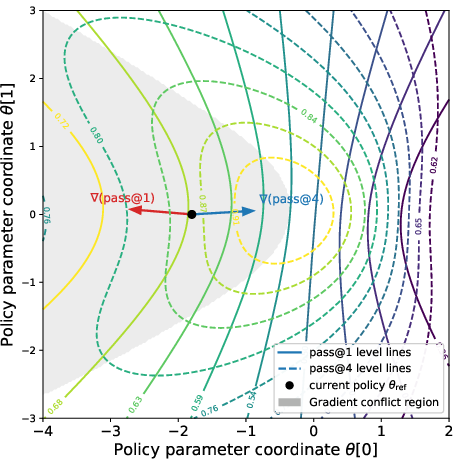
- Gradient conflict: A situation where two objective gradients (e.g., pass@k and pass@1) form an obtuse angle, so improving one can worsen the other. "We provide a characterization of this gradient conflict by establishing an interpretable expression for the inner product between pass@ and pass@1."
- Implicit prompt reweighting: The effective change in emphasis toward certain prompts induced by an objective (e.g., pass@k upweights hard prompts) during gradient computation or optimization. "pass@ policy optimization induces an implicit prompt reweighting, biased toward upweighting low-success prompts."
- Multi-sample inference: An evaluation regime that draws multiple samples per prompt and counts success if any sample is correct. "This multi-sample inference metric has motivated inference-aware fine-tuning methods that directly optimize pass@."
- Negatively interfering prompts: Prompts whose pass@1 gradients tend to decrease the overall pass@1 objective when they are improved, causing interference. "We identify the prompts that can lead to gradient conflict as negatively interfering using the concept of prompt interference we introduce in this work."
- Pass@1: The probability that a single sampled response solves the prompt; a single-shot success metric. "Empirically, some recent works report objective-dependent trade-offs where pass@ improves while pass@1 drops"
- Pass@k: The probability that at least one of k independently sampled responses is correct; a multi-attempt success metric. "Pass@k is a widely used performance metric for verifiable LLM tasks, including mathematical reasoning, code generation, and short-answer reasoning."
- Pass@k policy gradients: Gradients of the pass@k objective with respect to policy parameters, used to directly optimize multi-sample success. "Pass@ optimization can be performed using pass@ policy gradients."
- Pass@k weights: The per-prompt importance weights w.r.t. pass@k that emphasize low-success prompts in the gradient, typically w_k(p)=k(1−p){k−1}. "where the pass@$10$ weight whereas "
- Phase transition in k: A threshold behavior where increasing k beyond a certain point causes systematic gradient conflict (and potential pass@1 degradation). "This result shows there is a phase transition in :"
- Population pass@1 gradient: The average pass@1 gradient over the prompt distribution, as opposed to a per-prompt gradient. "Here, pass@$1$ denotes the population pass@$1$ gradient, given by the average (expectation over prompts; here under a uniform distribution) of the per-prompt pass@$1$ gradients."
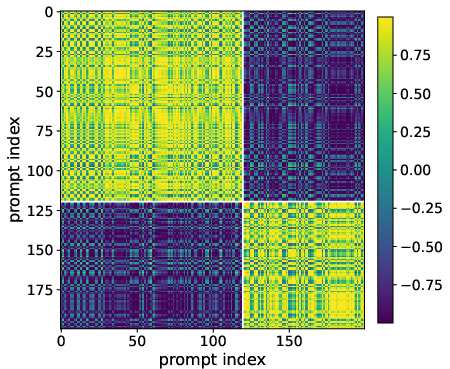
- Prompt interference: The phenomenon where updates that improve one prompt’s success probability can help (positive) or hurt (negative) another prompt under shared parameters. "We introduce the concept of prompt interference."
- Prompt similarity kernel: A kernel capturing similarity between prompts via the inner product of their pass@1 gradients, used to formalize interference. "we introduce a similarity kernel to define the concept of prompt interference mathematically."
- Reweighted prompt distribution: The distribution over prompts obtained by weighting the original distribution by pass@k weights, emphasizing harder prompts. "define the reweighted prompt distribution:"
- Score function: The gradient of the log-policy with respect to parameters, used in policy-gradient estimators. "where denotes the score function."
- Smoothness of the pass@k objective: A regularity property ensuring bounded curvature, enabling step-size conditions and performance guarantees. "we establish and use smoothness of the pass@ objective under a standard policy parameter regularity assumption."
- Softmax policy: A parametric policy that selects actions according to a softmax over linear scores of features. "We use a two-action softmax policy parameterized by a single vector "
- Stochastic policy: A probabilistic mapping from prompts to distributions over responses, parameterized by model weights. "a LLM is represented as a stochastic policy parameterized by weights "
- Strongly negatively interfering prompt set: The subset of prompts whose agreement scores are below a negative margin, used to quantify interference. "we define the -strongly negatively interfering prompt set with margin~:"
- Verifier coverage: The extent to which a verifier reliably checks correctness across prompts; limited coverage can constrain deployment. "due to latency and cost budgets, imperfect verifier coverage, and the need for a reliable single-shot fallback."
- Lipschitz and smooth policy: A policy class whose log-probability gradients and Hessians are bounded in expectation, ensuring well-behaved optimization. "Assumption [Lipschitz and smooth policy]"
- Ray interference: An interference notion from multi-task learning describing conflicts between gradient directions aligned as rays. "invoked ray interference as introduced in \citet{schaul-et-al19ray-interference} to explain why learning can be inhibited on heterogeneous prompt mixtures"
Practical Applications
Overview
This paper shows that directly optimizing pass@k (success with k independent samples) can worsen pass@1 due to “prompt interference”: pass@k reweights updates toward low-success prompts; if those prompts’ gradients are anti-aligned with the population pass@1 gradient, the resulting pass@k update moves in a direction that improves pass@k but harms pass@1. The authors formalize this with a prompt-gradient similarity kernel κθ, an agreement score aθ(x), and a characterization of when the inner product ⟨∇Jk(θ), ∇J1(θ)⟩ becomes negative. They provide sufficient conditions, a k-dependent threshold for conflict, a stepsize condition guaranteeing simultaneous pass@k increase and pass@1 decrease, and LLM experiments (math reasoning) validating the mechanism.
Below are practical applications derived from these findings.
Immediate Applications
The following can be deployed with today’s models and tooling.
- Bold: pass@k–pass@1 conflict diagnostics in training (software/ML platforms)
- Sectors: software, code generation, education, platform ML.
- Tools/Workflows: compute per-prompt agreement scores aθ(x), pass@k weights wk,θ(x), and the gradient inner product ⟨∇Jk, ∇J1⟩ (last-layer gradient estimators are sufficient); add dashboards to track weighted vs unweighted agreement means, covariance cov(wk,θ, aθ); trigger early-stopping or schedule changes when inner product turns negative.
- Assumptions/Dependencies: availability of a verifier r(x, y) (even partial); extra compute for gradient estimation; enough Monte Carlo samples for stable estimates.
- Bold: constrained fine-tuning recipes that preserve pass@1 (software, code-generation products)
- Sectors: software engineering, AI assistants, enterprise ML.
- Tools/Workflows: multi-objective loss Jk + λJ1; pass@1 floor constraints (maximize Jk subject to J1 ≥ baseline); angle-alignment regularizers to keep ⟨∇Jk, ∇J1⟩ ≥ 0; reuse multi-task techniques (e.g., gradient surgery like PCGrad) on prompt groups.
- Assumptions/Dependencies: access to per-prompt gradients or good approximations; hyperparameter tuning for λ/constraints; potential throughput hit.
- Bold: prompt clustering and batch scheduling to reduce negative interference (data and training ops)
- Sectors: software, education (math/code tutors), data operations.
- Tools/Workflows: cluster prompts by κθ or gradient embeddings; form batches within clusters to avoid mixing strongly negatively interfering prompts; alternate cluster-focused updates; optional adapters/LoRA per cluster.
- Assumptions/Dependencies: stable clustering; sufficient data per cluster; drift monitoring.
- Bold: curriculum/k scheduling with conflict monitoring (training strategy)
- Sectors: software, education, platform ML.
- Tools/Workflows: start with k=1 optimization, then gradually increase k while monitoring ⟨∇Jk, ∇J1⟩ and cov(wk,θ, aθ); tune sampling temperature and diversity; roll back if conflict intensifies.
- Assumptions/Dependencies: reliable diagnostics; modest training overhead.
- Bold: deployment-time dynamic k allocation and fallback (product engineering)
- Sectors: code assistants, customer support chatbots, search/citation tools.
- Tools/Workflows: estimate hardness pθ(x) or use proxy signals to decide k adaptively; ensure single-shot fallback path when verifiers are weak or latency budgets are tight; use reranking/verification when available.
- Assumptions/Dependencies: calibrated hardness estimates; verifier coverage; latency/cost budgets.
- Bold: model selection and SLOs that include conflict-aware reporting (policy/enterprise IT governance)
- Sectors: procurement, compliance, enterprise AI governance.
- Tools/Workflows: require vendors to report pass@1, pass@k, and conflict metrics (e.g., ⟨∇Jk, ∇J1⟩, weighted agreement mean); enforce SLOs that protect single-shot accuracy even when k>1 is used.
- Assumptions/Dependencies: vendor cooperation; standardized measurement protocols.
- Bold: code generation pipelines with dual-model routing (developer tools)
- Sectors: software, DevEx.
- Tools/Workflows: maintain a pass@1-optimized model for single-shot tasks and a pass@k-optimized model for batch/test-verified workflows; route by task type and hardness; monitor unit-test coverage to avoid over-trusting pass@k when coverage is low.
- Assumptions/Dependencies: accurate routing; unit-test coverage estimation.
- Bold: active data selection to mitigate harmful interference (data curation)
- Sectors: data engineering, evaluation.
- Tools/Workflows: identify hard prompts with negative aθ(x); curate/augment data that makes them positively aligned (e.g., additional contexts, structured templates); downweight or separate training on prompts that consistently induce anti-alignment.
- Assumptions/Dependencies: stable estimation of aθ(x); quality augmentation strategies.
- Bold: academic teaching/benchmarking of interference (education/research)
- Sectors: academia.
- Tools/Workflows: use the paper’s toy example and agreement/weight metrics to teach interference; create small-scale labs that reproduce gradient conflict and mitigation.
- Assumptions/Dependencies: minimal; accessible datasets/verifiers.
Long-Term Applications
These require further research, scaling, or development.
- Bold: new objectives that align pass@k without harming pass@1 (algorithm design)
- Sectors: software, platform ML.
- Tools/Workflows: constrained optimization (maximize Jk subject to J1 ≥ τ); explicit covariance penalties (e.g., minimize −cov(wk,θ, aθ)); angle-constrained policy gradient (keep ⟨∇Jk, ∇J1⟩ non-negative); trust-region updates on J1 while ascending Jk.
- Assumptions/Dependencies: efficient solvers; reliable gradient estimates; theory–practice calibration.
- Bold: interference-aware routing architectures (systems/architecture)
- Sectors: software, robotics, education.
- Tools/Workflows: mixture-of-experts or adapter stacks per prompt cluster; learned gate using κθ/aθ(x) features; reduce cross-cluster negative transfer; shared backbone with specialized heads for hard clusters.
- Assumptions/Dependencies: infra complexity; latency/memory overhead; robust gates.
- Bold: verifier-aware training under imperfect verifiers (safety-critical AI)
- Sectors: healthcare, finance, legal, compliance.
- Tools/Workflows: jointly model verifier coverage and uncertainty; robust objectives that don’t overfit to verifier blind spots; decide k with safety margins; calibrate reliance on pass@k where verifiers are strong.
- Assumptions/Dependencies: domain-validated verifiers; privacy/approval for data; robust calibration.
- Bold: standardization of interference metrics and reporting (policy/standards)
- Sectors: public policy, procurement standards, benchmarking orgs.
- Tools/Workflows: define reporting requirements for pass@1 vs pass@k, gradient-conflict indicators, and verifier coverage; update benchmarks to include interference-sensitive suites and mixed-difficulty distributions.
- Assumptions/Dependencies: multi-stakeholder consensus; open tooling.
- Bold: automated controllers for k, temperature, and sampling diversity (inference optimization)
- Sectors: platform ML, MLOps.
- Tools/Workflows: per-prompt controllers that trade off latency, cost, and reliability using pθ(x) and error bars; adaptive diversity sampling to improve pass@k without rotating away from pass@1.
- Assumptions/Dependencies: accurate calibration; fast uncertainty estimates; online learning loop.
- Bold: interference-aware data generation and augmentation (data-centric AI)
- Sectors: education, software, tutoring.
- Tools/Workflows: synthesize or rewrite prompts to increase positive alignment (e.g., structured reasoning templates, added hints); targeted augmentation for negatively interfering hard prompts to flip aθ(x) to positive.
- Assumptions/Dependencies: reliable identification of causal features; evaluation at scale.
- Bold: certification pathways for “pass@1-safe” multi-attempt AI (regulatory)
- Sectors: healthcare, autonomous systems, finance.
- Tools/Workflows: develop audit protocols proving maintenance of pass@1 under pass@k improvements; require conflict monitoring in deployment; mandate fallbacks for unverifiable prompts.
- Assumptions/Dependencies: regulatory uptake; domain-specific test suites.
- Bold: sampling schemes that increase pass@k without hurting pass@1 (generation research)
- Sectors: software, research platforms.
- Tools/Workflows: decorrelated/diversified sampling (e.g., determinantal point processes, guided temperature schedules) coupled with training that preserves single-shot gradients; correlation-aware pass@k training.
- Assumptions/Dependencies: tractable diversity estimators; integration with decoding stacks.
- Bold: visual analytics and libraries for interference mapping (tooling)
- Sectors: platform ML, research.
- Tools/Workflows: open-source libraries to compute κθ, aθ(x), wk,θ(x), and ⟨∇Jk, ∇J1⟩ at scale; “interference heatmaps” by domain, cluster, and time; drift alerts when conflict regions grow.
- Assumptions/Dependencies: scalable gradient instrumentation; privacy constraints on logs.
- Bold: extending interference analysis beyond LLMs (cross-domain ML/RL)
- Sectors: robotics, multi-task RL, recommendation systems.
- Tools/Workflows: apply kernel-based interference and gradient-conflict diagnostics to shared-parameter policies; design controllers that avoid sacrificing single-shot safety-critical performance while benefiting from retries.
- Assumptions/Dependencies: domain-specific verifiers or proxies; safe exploration limits.
Notes on feasibility: Many immediate applications rely on existing verifiers (unit tests, exact-match checkers) and last-layer gradient estimates to approximate aθ(x) and conflict metrics at reasonable cost. Where verifiers are weak or absent, proxy rewards or human-in-the-loop labels are needed, and estimates will be noisier. Productionizing long-term applications (e.g., constrained objectives, routing architectures) will require robust, scalable gradient instrumentation, stable clustering under distribution shift, and standardized reporting to be broadly adopted.
Collections
Sign up for free to add this paper to one or more collections.