SkyReels-V4: Multi-modal Video-Audio Generation, Inpainting and Editing model
Abstract: SkyReels V4 is a unified multi modal video foundation model for joint video audio generation, inpainting, and editing. The model adopts a dual stream Multimodal Diffusion Transformer (MMDiT) architecture, where one branch synthesizes video and the other generates temporally aligned audio, while sharing a powerful text encoder based on the Multimodal LLMs (MMLM). SkyReels V4 accepts rich multi modal instructions, including text, images, video clips, masks, and audio references. By combining the MMLMs multi modal instruction following capability with in context learning in the video branch MMDiT, the model can inject fine grained visual guidance under complex conditioning, while the audio branch MMDiT simultaneously leverages audio references to guide sound generation. On the video side, we adopt a channel concatenation formulation that unifies a wide range of inpainting style tasks, such as image to video, video extension, and video editing under a single interface, and naturally extends to vision referenced inpainting and editing via multi modal prompts. SkyReels V4 supports up to 1080p resolution, 32 FPS, and 15 second duration, enabling high fidelity, multi shot, cinema level video generation with synchronized audio. To make such high resolution, long-duration generation computationally feasible, we introduce an efficiency strategy: Joint generation of low resolution full sequences and high-resolution keyframes, followed by dedicated super-resolution and frame interpolation models. To our knowledge, SkyReels V4 is the first video foundation model that simultaneously supports multi-modal input, joint video audio generation, and a unified treatment of generation, inpainting, and editing, while maintaining strong efficiency and quality at cinematic resolutions and durations.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
SkyReels‑V4: An easy-to-understand guide
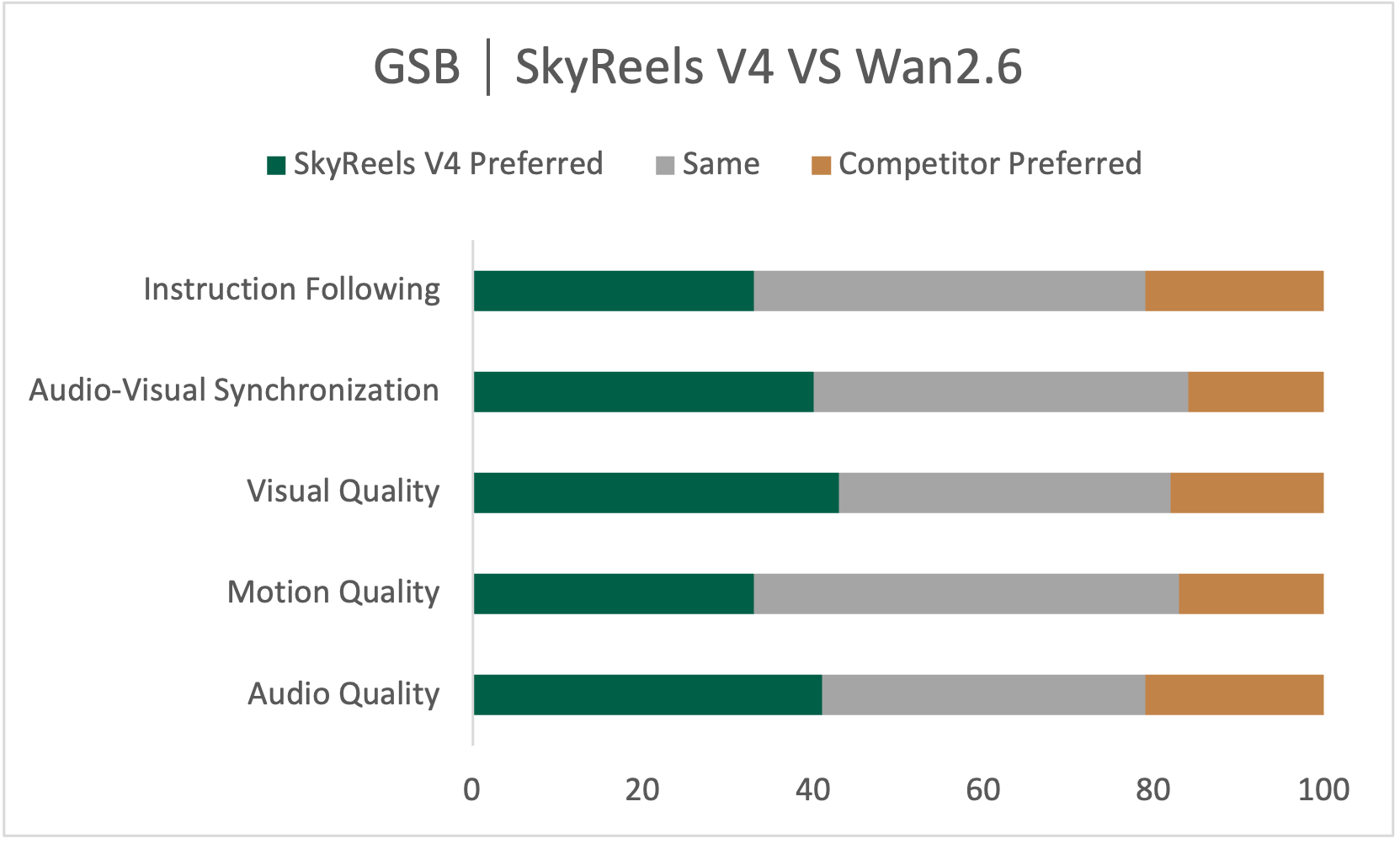
What is this paper about?
This paper introduces SkyReels‑V4, an AI model that can create complete videos with matching sound. It can also edit and fix parts of existing videos. What makes it special is that it understands and uses many kinds of inputs at once—text, images, short video clips, masks (to mark areas to keep or change), and even audio samples—so it can follow complex instructions like “Make this person from the photo walk into this scene and say this line, in the style of that example video.”
What questions are the researchers trying to answer?
The authors aim to solve four big challenges in one model:
- Can we build one AI that handles many inputs (text, images, video clips, masks, audio) instead of separate tools for each?
- Can it generate video and audio together so lips, actions, and sounds line up naturally?
- Can it treat different tasks—like creating new video, extending a video, or editing parts of a video—as one unified process?
- Can it do all this at high quality (1080p, 32 frames per second) for longer clips (up to 15 seconds) without taking forever to run?
How does the model work? (Explained with simple ideas)
Think of SkyReels‑V4 as a filmmaking team with two main specialists who constantly talk to each other:
- A “video artist” who paints the moving pictures.
- A “sound designer” who creates the matching audio (voices, effects, ambience).
They share the same “director,” a strong language-and-vision brain (a multimodal LLM) that understands the instructions and all the references you provide (text, images, clips, audio examples). This shared brain keeps everyone on the same page about what should happen.
Here are the key ideas behind the scenes:
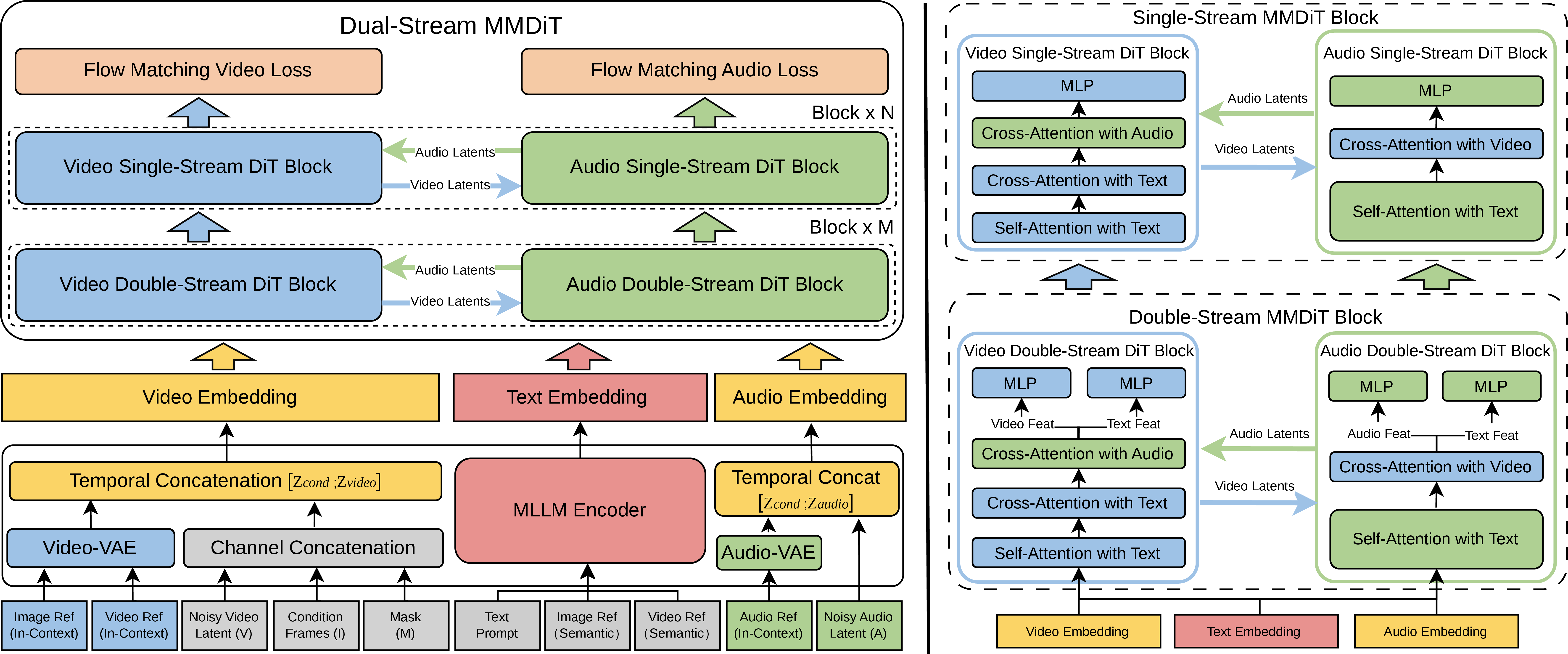
- Two synchronized streams: The video side and the audio side run in parallel and “look over each other’s shoulder” often. This constant back-and-forth helps keep sound and visuals in sync (like musicians listening to each other to stay on beat).
- Unified editing by masking: The model treats many tasks as “inpainting,” which means filling in the missing or changed parts. You provide:
- the noisy video to be generated,
- any frames you want to keep or use as reference,
- a mask that marks “keep this” vs. “generate/change this.”
- With the right mask, the same model can do text-to-video, image-to-video (animate a photo), extend a clip, interpolate between frames, or edit specific regions.
- In-context visual references: If you show the model example images or frames, it doesn’t just read them—it “looks at them” directly during generation, so it can copy fine details (like a person’s face or clothing style) while following your instructions.
- Keeping time aligned: Video and audio move at different speeds (fewer video frames vs. many tiny audio samples). The model uses a timing trick so both streams “feel” the same timeline and can match moments (like footsteps hitting the ground exactly when you see them).
- Efficiency for cinematic quality: Instead of making every 1080p frame from scratch (which is very expensive), the model:
- creates a full low‑resolution version of the whole video,
- also makes high‑resolution key moments (keyframes),
- then uses special tools to upscale and smoothly fill in the frames between.
- This is like sketching the whole scene, painting key shots in detail, and then polishing the rest.
What did they find, and why does it matter?
According to the authors’ tests:
- The model can produce up to 1080p resolution, 32 FPS, and 15‑second clips, with synchronized audio and support for multi-shot sequences (good for short film-like stories).
- It supports rich, mixed instructions (combine text, images, masks, and audio references) and handles many tasks—new generation, inpainting, and editing—within one system.
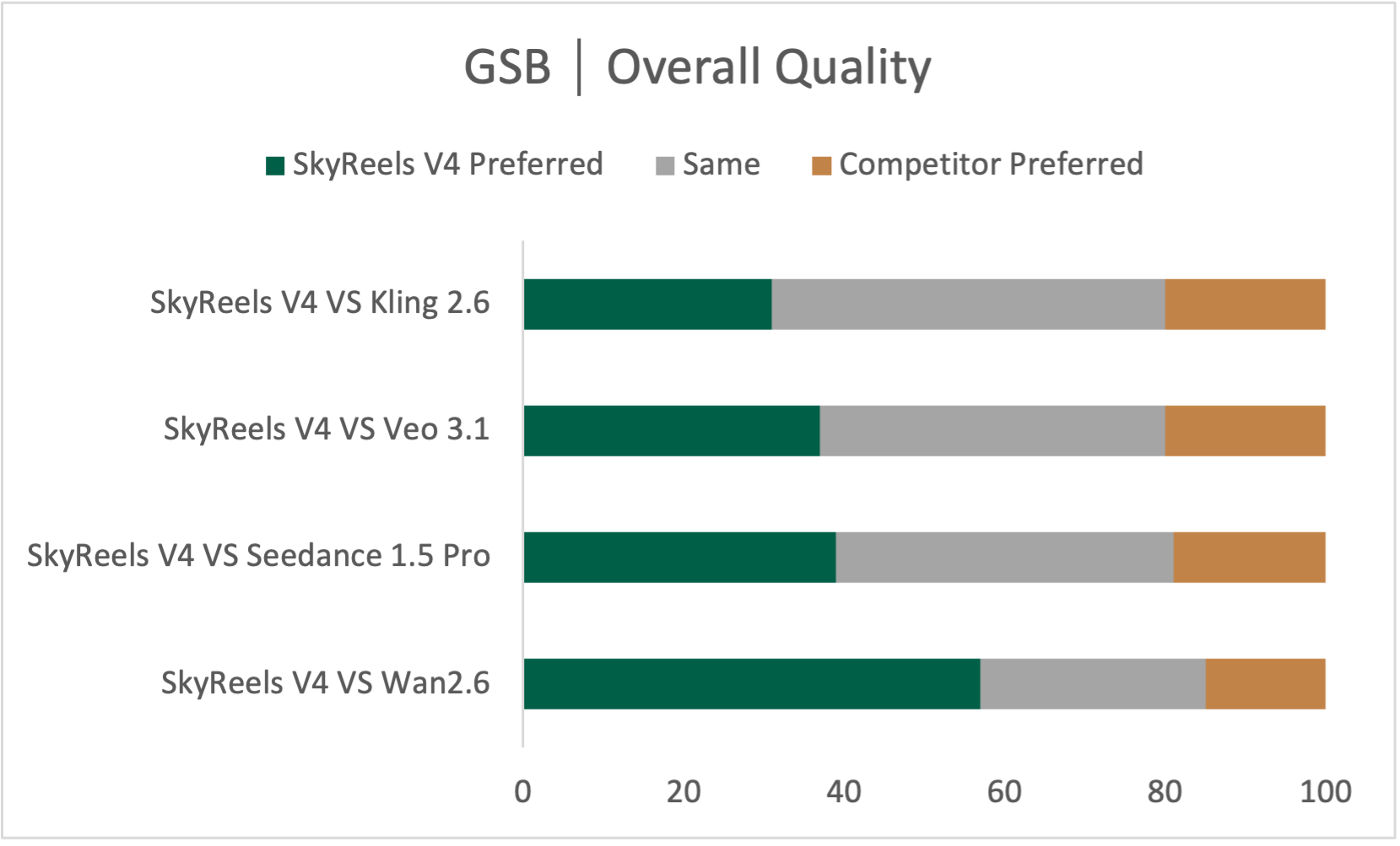
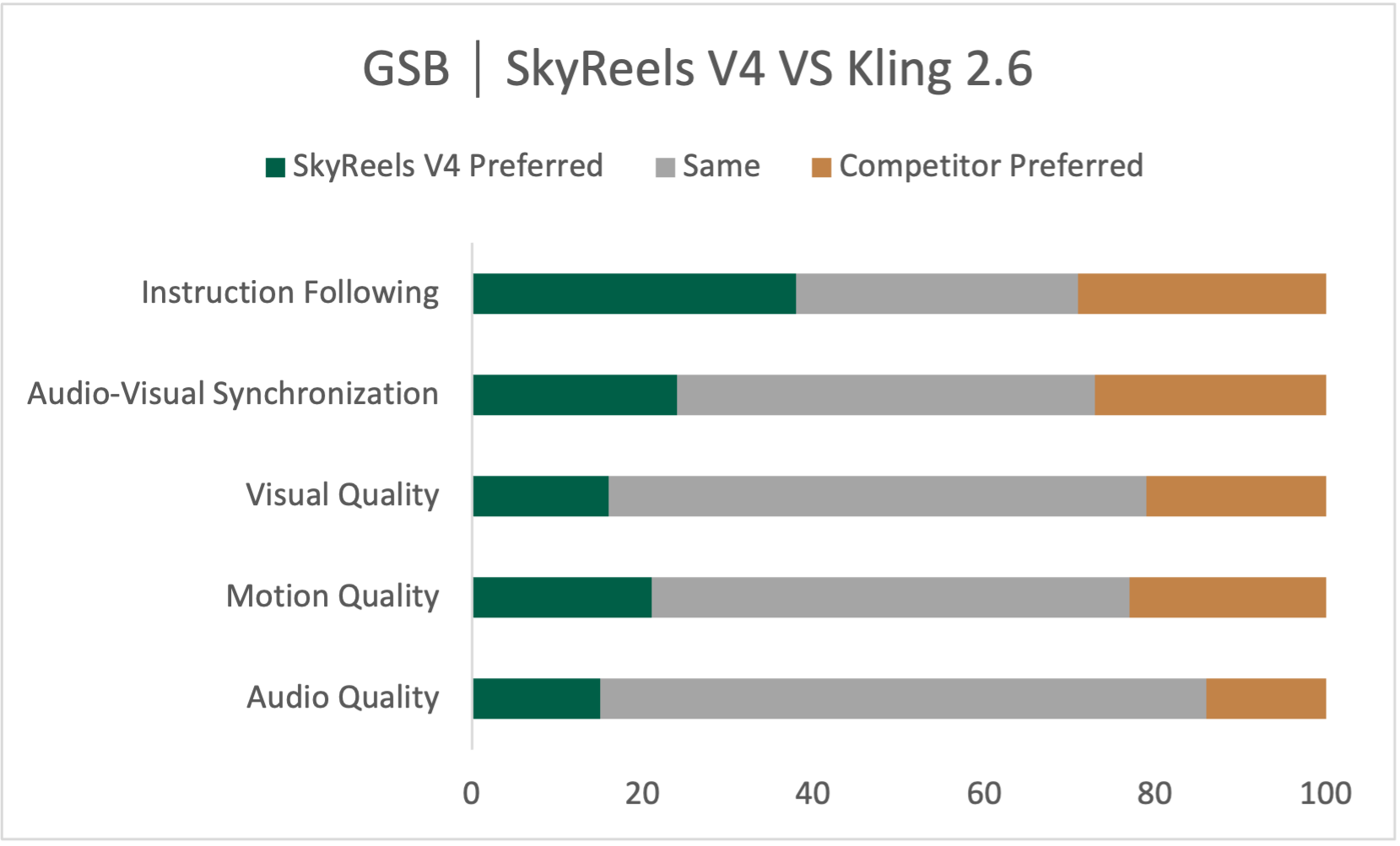
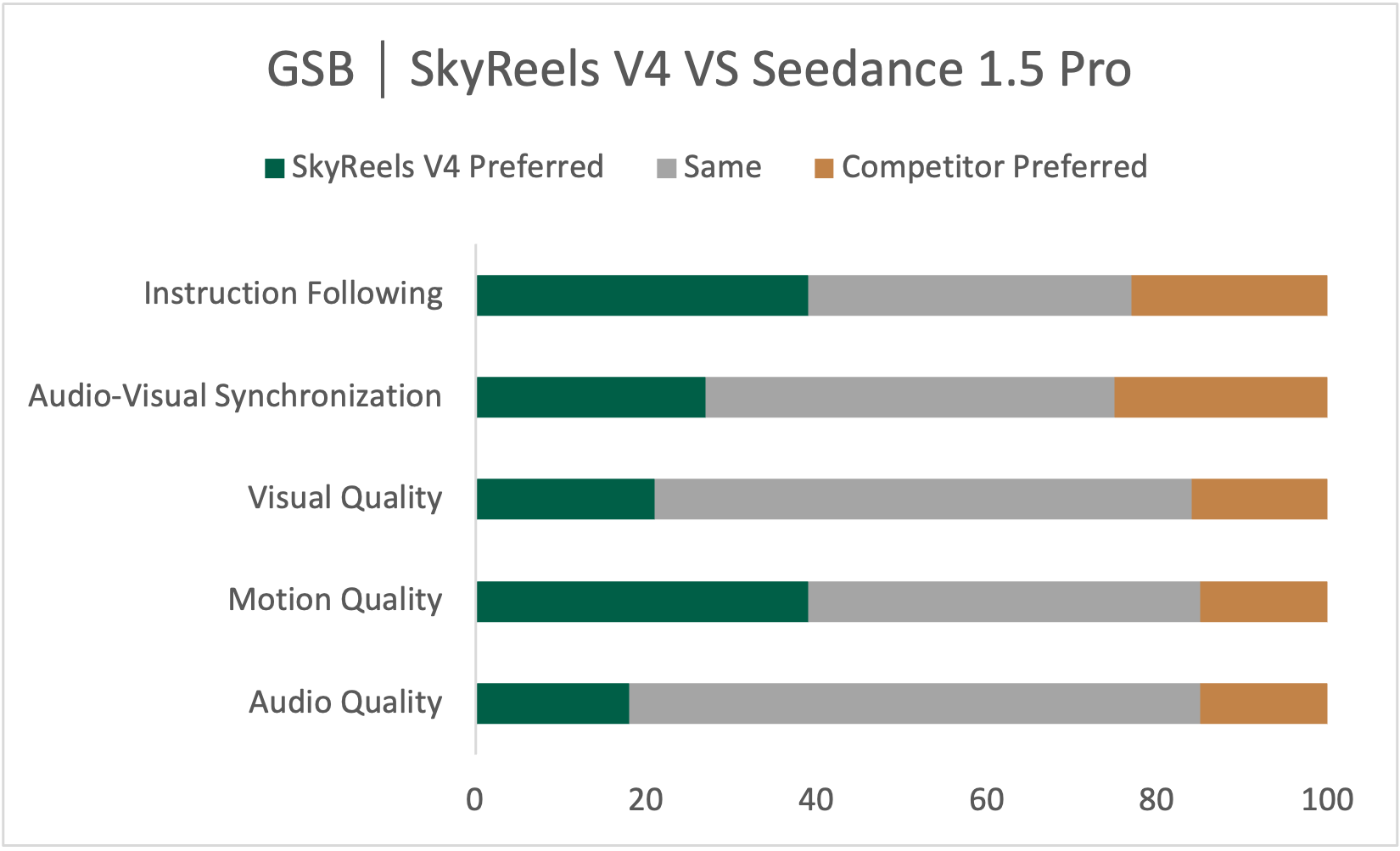
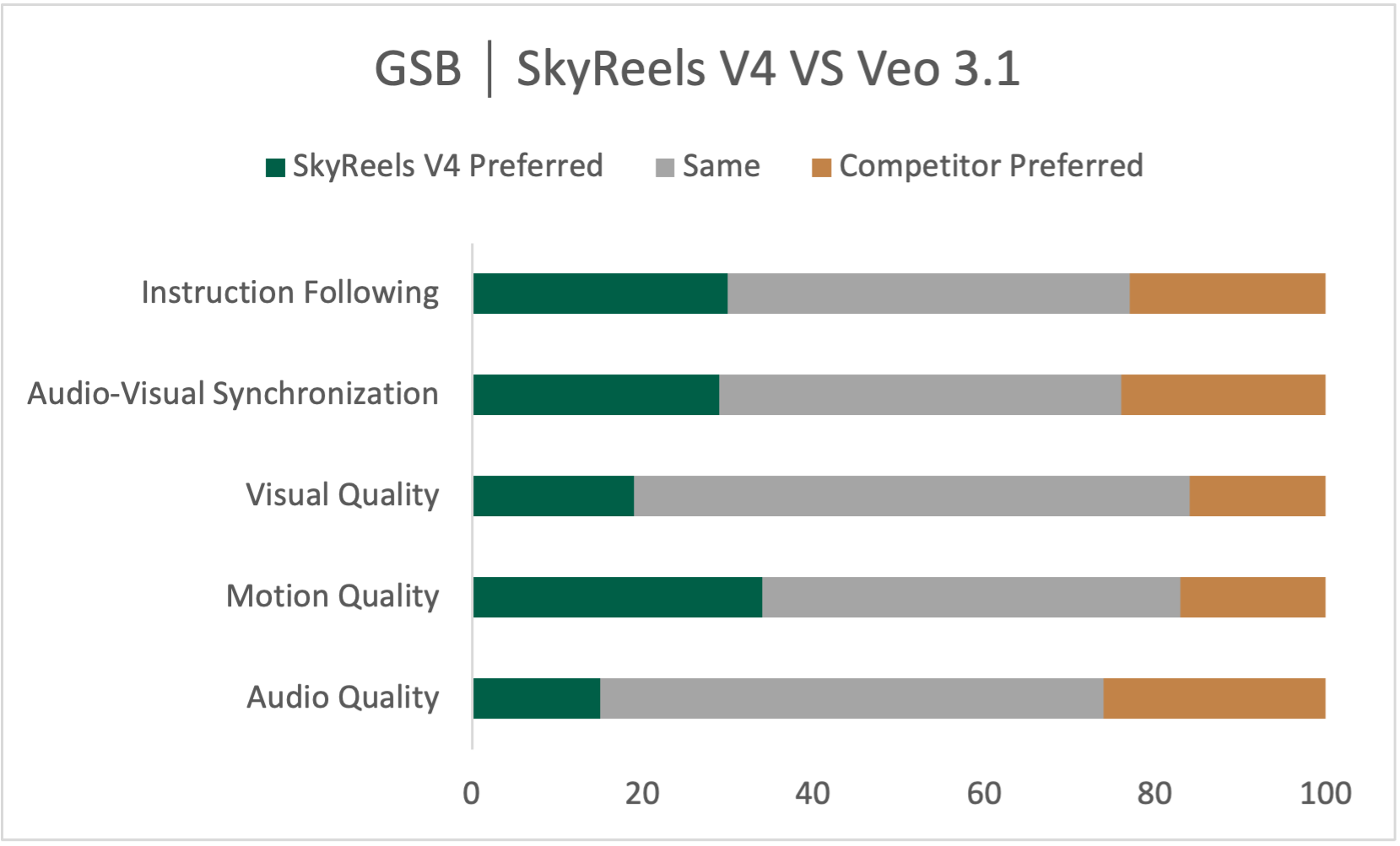
- In their evaluations, SkyReels‑V4 performs strongly, especially in following instructions accurately, creating smooth and believable motion, and handling complex multi-shot storytelling. It also works well on tasks like reference‑to‑video, motion‑to‑video, and detailed video editing.
Why this matters:
- One unified tool simplifies creative workflows. You don’t need to jump between separate apps to generate, fix, and edit audio‑video content.
- Better sync between sound and picture makes results feel more natural and professional.
- High quality at reasonable speed makes it more practical for real creators, not just labs.
What could this mean for the future?
If models like SkyReels‑V4 keep improving:
- Filmmakers, video editors, educators, and online creators could go from idea to polished video with sound much faster.
- Complex edits—like changing a costume, replacing a background, or adding a new shot that matches the style—could become as simple as giving clear instructions and a few reference images.
- More people could tell stories with professional quality, even without large budgets or teams.
Note: The authors present SkyReels‑V4 as, to their knowledge, the first system to combine all these abilities (multi‑modal inputs, joint video‑audio generation, and unified generation/inpainting/editing) at cinematic quality. As the field moves quickly, this sets a strong baseline others can build on.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps, limitations, and unresolved questions that, if addressed, could advance or replicate the work described.
- Architecture: The specific MMLM used as the “shared multi-modal text encoder” is not identified; unclear whether it natively ingests images, video, and audio or relies on separate modality encoders and how those are integrated into token space.
- Modality tokenization: Missing details on how images, video clips, and audio references are tokenized and fed to the MMLM (preprocessors, feature extractors, frame selection, sampling rates, normalization).
- Freezing vs fine-tuning: No ablation or guidance on freezing the MMLM vs fine-tuning for better instruction-following or alignment; unknown effects on stability and sample quality.
- Audio representation: The audio latent pipeline (codec/autoencoder choice, latent hop size, channels, bandwidth, vocoder) is unspecified; stereo/binaural/spatial audio support is unclear.
- Temporal alignment: The RoPE scaling heuristic (21 video frames vs 218 audio tokens) lacks validation across different durations, frame rates, or variable-length segments; unclear whether learned alignment layers or dynamic time warping could outperform static scaling.
- Lip-sync and sync metrics: No explicit evaluation methodology for audiovisual synchronization (e.g., SyncNet/LSE-C, human lip-readers) or how interpolation/SR affect sync.
- Bidirectional AV attention cost: The compute/memory footprint of per-layer bidirectional cross-attention at cinematic scales is not quantified; no profiling versus single-direction or sparse schemes.
- Hybrid dual-/single-stream choice: Lack of ablation isolating benefits of the hybrid MMDiT layout (early dual-stream, later single-stream) and the added text cross-attention on quality, controllability, and convergence speed.
- Projection-free symmetry: It is unclear whether omitting projection layers between modalities constrains representation capacity; comparison to learned projections or MoE interfaces is missing.
- Training objective/sampler: Flow matching is adopted, but details on noise schedule, loss weighting between audio/video, sampler steps, and inference-time guidance (e.g., modality-specific CFG) are absent.
- Pretraining dynamics: The video branch is initialized from a T2V model while the audio branch is trained from scratch; no curriculum, optimization scheduling, or balancing strategy is provided to prevent modality dominance or collapse.
- Data scale and composition: No disclosure of dataset size, sources, licenses, audio-video pairing quality, language distribution, speech vs SFX/music proportions, and domain diversity; curation/filtering and deduplication are unspecified.
- Mask/inpainting training: The distribution and generation of spatiotemporal masks used during training (static vs dynamic, sizes, frequencies) are not described; robustness to imperfect user masks and temporal seams is unevaluated.
- Channel-concatenation specifics: The exact VAE latent channel dimensions, normalization, and concatenation scheme (including broadcasted mask channels across latent hierarchies) are not given; interactions with in-context reference tokens are unclear.
- Vision-referenced in-context setup: Limits on the number/length of reference visuals, memory scaling, and strategies for selecting reference frames (uniform vs key events) are not discussed; no robustness tests for noisy/off-domain references.
- Negative temporal indices (offset 3D RoPE): The stability and efficacy of assigning negative temporal indices to reference tokens are not validated; potential interference with learned temporal patterns is unexplored.
- Keyframe strategy: Criteria for choosing high-resolution keyframes (uniform, motion-/shot-boundary-aware, learned scoring) and their count per second are unspecified; sensitivity analysis is absent.
- SR and interpolation modules: Architectures, training data, and failure modes (temporal flicker, texture boiling, hallucinated detail) for super-resolution and frame interpolation are not described; how edits/keyframe identities propagate is unclear.
- AV consistency post-interpolation: The impact of frame interpolation on AV sync, perceived motion rhythm, and beat alignment is not quantified; no re-timing or adaptive audio alignment mechanism is described.
- Editing/audio handling: For video editing/inpainting, the paper always regenerates audio; lacking a mode to preserve or selectively mix original audio (and associated alignment tools) for non-destructive workflows.
- Conflict resolution: No policy or controllable weighting is provided for resolving conflicts between text, visual, and audio references (e.g., which modality dominates when instructions disagree).
- Long-form and streaming: The approach is capped at ~15 seconds; strategies for streaming, autoregressive chunking, scene transitions, character continuity across shots, and memory across segments remain open.
- Control interfaces: Absent mechanisms for precise control (phoneme-level lip control, beat/meter alignment, camera path, motion trajectories, sound localization, loudness/dynamics); no API for per-modality guidance strengths.
- Conversational/multi-speaker scenes: Handling of diarization, turn-taking, and spatial separation in multi-person dialogue videos is not documented; no evidence for 3D/spatial audio or microphone perspective modeling.
- Non-speech audio: The system’s capability to produce causal Foley/SFX synchronized to visual events and coherent ambient soundscapes/music is not benchmarked; control over music style/copyright-safe generation is unspecified.
- Multilingual coverage: Language diversity, accent robustness, code-switching behavior, and language-specific lip-phoneme alignment fidelity are not evaluated.
- Robustness: Behavior under low-quality inputs (noisy audio refs, compressed videos, ambiguous text), fast motion, extreme lighting, and out-of-distribution content is unreported; failure case taxonomy is missing.
- Evaluation protocol: Objective metrics for audio (FAD, PESQ/ViSQOL), video (FVD, CLIPScore), and AV synchronization, plus detailed human evaluation protocols (prompt sets, raters, inter-rater agreement, significance tests) are missing.
- Fair comparisons: Reproducible prompts, seeds, and settings for comparisons to proprietary systems are not provided, risking confounds; statistical rigor and effect sizes are not reported.
- Personalization and PEFT: No mechanism for parameter-efficient fine-tuning (e.g., LoRA) for identities/voices/styles is proposed; privacy-preserving on-device adaptation remains open.
- Variable formats: Support for variable frame rates, aspect ratios (vertical/portrait), and non-1080p targets, including letterboxing vs content-aware reframing, is not discussed.
- Safety and ethics: Dataset consent, face/voice rights, deepfake misuse mitigation, watermarking/provenance, detection tools, and red-teaming are not addressed.
- Security: Potential vulnerabilities to adversarial or prompt-injected multimodal references (e.g., images or audio designed to subvert instructions) are not explored.
- Compute and carbon footprint: Training/inference compute, memory requirements, throughput/latency at target settings, and environmental impact are not reported.
- Reproducibility: Code, weights, training recipes, datasets, and an open benchmark (SkyReels-VABench) are not released or specified, limiting independent verification and extension.
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed now, leveraging SkyReels-V4’s dual-stream (video–audio) generation, unified inpainting/editing, multi-modal instruction following, and the efficiency scheme (low-res sequence + high-res keyframes + super-resolution + interpolation).
- Industry — Entertainment/Post-Production: Rapid previsualization and storyboard clips with temp sound
- Workflow/product: “Previz AV Generator” plugin for Premiere/DaVinci that turns text + reference images into 10–15s multi-shot clips with synchronized ambient audio/music.
- Assumptions/dependencies: 1080p/32 FPS/15s cap; requires the super-res/interpolation modules; rights for any referenced visuals and audio style.
- Industry — Film/TV: Shot extension, start–end interpolation, continuity repairs with auto-foley
- Workflow/product: “Shot Extender” that uses masks to preserve regions, extends scenes, and generates matching footsteps/room tone.
- Assumptions/dependencies: High-quality masks/segmentation; consistent style conditioning; compute budget for high-res outputs.
- Industry — Localization/ADR: Lip-synced dialogue replacement or video re-synthesis to match recorded lines
- Workflow/product: “Smart ADR” tool that aligns speech prosody with mouth motion or vice versa, using bidirectional audio–video cross-attention.
- Assumptions/dependencies: Voice-IP licenses; multilingual phoneme coverage; accurate timing constraints; bias control for accents.
- Industry — Advertising/Marketing: Prompt-to-commercial from product shots and copy with coherent soundscapes
- Workflow/product: “Prompt-to-Commercial” that composes multi-modal inputs (product shots, brand tone, jingle references) into 15s ad clips.
- Assumptions/dependencies: Brand safety review; disclosure of synthetic media; music/jingle licensing; prompt governance.
- Industry — Social Media/Creator Economy: Object removal/addition, style edits, identity-preserving transformations with synchronized audio
- Workflow/product: “Clean Plate + Auto Foley” for fast edits that re-synthesize believable ambient sounds and effects.
- Assumptions/dependencies: Reliable detection/inpainting at 1080p; risk of identity misuse; watermark/provenance embedding.
- Software — NLE/Creative Tools: Unified inpainting/editing interface via channel-concatenation masks
- Workflow/product: “Mask-to-Edit” panel that treats all operations (I2V, video extension, region edits) as one interface.
- Assumptions/dependencies: Tight integration with VAE encoders/decoders; UX for multi-modal prompts; GPU/TPU inference.
- Gaming — Engine-integrated content: Placeholder cutscenes, animated portraits, audio-driven talking heads
- Workflow/product: Unreal/Unity plugin that turns script + reference character packs into short cutscenes with coherent sound.
- Assumptions/dependencies: Domain style adapters; runtime budgets; IP constraints for character likeness.
- Education — Courseware production: Slide + script → short lecture segments with synced narration and visuals
- Workflow/product: LMS add-on for rapid course snippet generation (math demos, lab overviews) with ambient sound cues.
- Assumptions/dependencies: Pedagogical review; voice selection for accessibility; institutional content policies.
- Accessibility — Enhanced audio for visual content: Auto-generation of ambient audio and effects consistent with scenes
- Workflow/product: “Ambient Assist” that adds soundscapes (e.g., traffic, nature) aligned with visual events for low-audio videos.
- Assumptions/dependencies: Coverage of audio event taxonomy; user controls to avoid overwhelming soundscapes; compliance with accessibility standards.
- Academia — Synthetic multimodal datasets: Balanced audio–video samples for evaluation of lip-sync, AV alignment, event grounding
- Workflow/product: “AV Data Generator” to produce controlled benchmarks for AV synchronization metrics and multimodal retrieval.
- Assumptions/dependencies: Domain gap analysis; labeling protocols; dataset licensing and ethical review; documented bias mitigation.
- Media — Newsrooms/Docs: B‑roll generation with natural ambient audio to fill gaps
- Workflow/product: “B‑roll Composer” that takes text briefs and reference frames to create filler visuals with consistent sound.
- Assumptions/dependencies: Editorial standards; provenance/watermarking; disclosure of synthetic footage.
- Enterprise — Training/Customer Support: Scenario simulations (short AV scenes) from playbooks and policy text
- Workflow/product: “Scenario Generator” creating role-play clips with synchronized speech and environment sounds.
- Assumptions/dependencies: Legal review; sensitive content filters; consent controls for identity references.
- Policy/Governance — Provenance and watermark integration for generative AV
- Workflow/product: “Provenance Layer” embedding audio–visual watermarks and producing structured metadata for disclosure.
- Assumptions/dependencies: Watermarking tech that survives platform transcodes; ecosystem adoption; standards alignment (e.g., C2PA).
- Policy/Enterprise — Consent and identity protection gates
- Workflow/product: “Consent Gate” that detects identity-referenced inpainting/editing and enforces consent/workflow checks.
- Assumptions/dependencies: Reliable identity detection; legal frameworks; audit logging; red-team testing for bypass risks.
- Healthcare — Patient education micro-clips (procedures, prep steps) with clear narration and visual demonstrations
- Workflow/product: “Clinic Content Generator” for 15s explainer segments.
- Assumptions/dependencies: Clinical accuracy validation; medical IP compliance; accessibility and readability standards.
Long-Term Applications
The following use cases require further research, scaling beyond current durations/resolution, deeper safety tooling, or broader ecosystem adoption.
- Entertainment — Feature-length generative production with coherent multi-shot narratives and full sound design
- Workflow/product: “AI Director” pipeline handling scene blocking, cinematics, dialogue, foley, music.
- Assumptions/dependencies: Scaling beyond 15s; robust story control; legal/IP clarity; large compute budgets; multi‑scene continuity modeling.
- Software — Real-time co-creative editing in NLEs
- Workflow/product: “AV CoPilot” offering live mask edits, prompt tweaks, and instant re-sync of audio/visual.
- Assumptions/dependencies: Low-latency inference; streaming keyframe generation; hardware acceleration; UI for interactive prompts.
- Localization — Universal multilingual dubbing with perfect lip-sync and voice preservation
- Workflow/product: “Universal Dubbing” that maps speech across languages while preserving speaker identity and mouth motion.
- Assumptions/dependencies: Multilingual phoneme alignment; consent/voice rights; cultural prosody calibration; quality assurance at scale.
- Digital Humans/Telepresence — Persistent, cognitively guided avatars for teaching, support, entertainment
- Workflow/product: “Live Instructor Avatar” integrating MMLM instruction following and AV generation for multi-person dialogue.
- Assumptions/dependencies: Safety alignment; long-horizon memory; personality/ethics controls; continuous identity ownership and consent.
- Virtual Production — Generative set extension and soundstage design integrated with camera/lighting tracking
- Workflow/product: “Virtual Stage” composing visuals and immersive sound that respond to on-set signals.
- Assumptions/dependencies: Sensor fusion; physically grounded AV simulation; latency and fidelity constraints.
- Robotics/Autonomous Systems — Audio–visual simulators for training perception and event detection
- Workflow/product: “AV Sim Toolkit” creating synthetic urban scenarios (sirens, engine noise, pedestrian gestures).
- Assumptions/dependencies: High-fidelity physics; domain randomization; sim-to-real transfer validation; annotation at scale.
- Smart Cities/Urban Planning — Audio–visual impact studies (traffic noise, crowd density) from proposed designs
- Workflow/product: “Urban AV Simulator” producing scenario clips for stakeholder review.
- Assumptions/dependencies: Environmental modeling; regulatory context; stakeholder acceptance; integration with CAD/BIM.
- Education/Science — Generative lab simulations and multimodal demonstrations
- Workflow/product: “AV Lab” crafting safety demos (e.g., chemical reactions with sound cues) and interactive lessons.
- Assumptions/dependencies: Domain-accurate physics and visuals; assessment alignment; curricular integration.
- Cybersecurity/Forensics — AV deepfake detection and provenance validation trained on generative outputs
- Workflow/product: “AV Forensics Suite” using multimodal cues to flag tampering and validate watermarks.
- Assumptions/dependencies: Access to diverse synthetic/real corpora; robust watermark standards; adversarial robustness.
- Healthcare/Therapy — Personalized therapeutic content via empathetic avatars with synchronized speech and gesture
- Workflow/product: “Therapy Coach Avatar” delivering exercises and encouragement with natural AV cues.
- Assumptions/dependencies: Clinical trials; safety guardrails; personalization without harmful biases; privacy-preserving logs.
- Live Events/Streaming — On-the-fly generative segments with synchronized music/effects reacting to audience input
- Workflow/product: “Live AV Reactor” for concerts and esports.
- Assumptions/dependencies: Real-time generation; content moderation; rights for music/style emulation.
- Policy/Standards — Global synthetic media disclosure, licensing, and carbon accounting frameworks
- Workflow/product: “Synthetic Media Compliance Stack” covering watermarking, consent tracking, dataset licensing, and emissions reporting.
- Assumptions/dependencies: International standards convergence (e.g., ISO/C2PA); enforcement mechanisms; buy-in from platforms and studios.
Cross-cutting assumptions and dependencies
- Compute and latency: Cinematic quality at scale requires substantial GPU/TPU resources; real-time use needs hardware acceleration.
- Data and rights: Training/conditioning on images, videos, voices, and music mandates clear licensing and consent; identity-preserving edits must be governed.
- Safety and governance: Robust watermarking/provenance, content filters, and disclosure practices are essential to mitigate deepfake risks.
- Ecosystem integration: Practical deployment relies on plugins/APIs for NLEs, game engines, LMSs, and enterprise systems.
- Quality controls: Domain-specific evaluators (AV sync metrics, narrative coherence, audio event coverage) and human review loops are needed to ensure reliability and reduce bias.
Glossary
- 2D+1D architectures: Early video model architectures that factor spatial and temporal processing into separate 2D and 1D components. "evolving from early 2D+1D architectures like Video Diffusion Models"
- 3D RoPE (3D Rotary Positional Embeddings): An extension of rotary positional embeddings to three dimensions (e.g., time and 2D space) to encode positions for attention. "we employ 3D Rotary Positional Embeddings"
- Adaptive layer normalization: A layer norm variant whose parameters adapt per modality or condition to improve conditioning. "adaptive layer normalization, QKV projections, and MLPs"
- Asymmetric streams: Using different architectures or capacities for audio and video branches to improve efficiency. "LTX-2 proposes asymmetric streams for efficiency."
- Audio-visual asynchrony: A mismatch in timing between audio and visual events in generated media. "and often suffered from audio-visual asynchrony"
- Bidirectional Audio-Video Cross-Attention: Mutual attention layers where audio attends to video features and vice versa to synchronize modalities. "Bidirectional Audio-Video Cross-Attention."
- Channel-concatenation formulation: Conditioning strategy that concatenates inputs (e.g., latents, references, masks) along channels to unify tasks like inpainting/editing. "we adopt a channel-concatenation formulation that unifies a wide range of inpainting-style tasks"
- Coupled U-Nets: Architectures with multiple U-Nets linked or conditioned on each other, used for joint audio-video generation. "evolved from coupled U-Nets to DiT-based methods"
- Cross-attention: Attention mechanism where queries from one stream attend to keys/values from another to inject conditioning. "an additional text cross-attention layer"
- DiT (Diffusion Transformer): A class of diffusion models that replace U-Nets with transformer blocks for denoising. "DiT-based frameworks"
- Dual-Stream design: Architecture with separate, parallel branches (e.g., audio and video) that interact via attention. "The initial layers employ a Dual-Stream design"
- Expert-orchestration: Combining outputs of specialized “expert” models or modules under a controller for multimodal generation. "expert-orchestration"
- Flow matching: A generative training objective that learns a velocity field transporting noise to data across continuous time. "We adopt a flow matching framework for training."
- In-context learning: Conditioning a model by inserting reference examples or tokens directly into its attention context, without finetuning. "with in-context learning in the video-branch MMDiT"
- Inpainting: Filling in or synthesizing masked regions while keeping unmasked content unchanged. "inpainting-style tasks"
- Latent: A compressed representation (often VAE or diffusion latent) in which denoising or generation is performed. "video latent and audio latent "
- MMDiT (Multimodal Diffusion Transformer): A diffusion transformer that processes multiple modalities (e.g., text, audio, video) jointly or in coordinated streams. "dual-stream MMDiT (Multi-Modal Diffusion Transformer) design"
- MMLM (Multimodal LLM): A large model that understands and integrates inputs across modalities like text, images, video, and audio. "based on the Multimodal LLMs (MMLM)"
- Omni-Full Attention: An attention scheme that jointly attends across all audio-video tokens to tightly couple modalities. "process audio-video tokens jointly via Omni-Full Attention"
- QKV projections: The learned linear mappings that produce queries, keys, and values for transformer attention. "QKV projections"
- RoPE (Rotary Positional Embeddings): A method for encoding relative positional information in attention via complex rotations. "Rotary Positional Embeddings (RoPE)"
- Semantic dilution: Weakening of semantic (e.g., text) signals as they propagate through layers, potentially reducing conditioning strength. "potential semantic dilution of text features"
- Single-Stream architecture: A design that concatenates modalities into a single token stream processed with shared parameters. "transition to a Single-Stream architecture"
- Single-tower models: Architectures that process all modalities within a single network tower rather than separate branches. "Unified single-tower models like Apollo"
- Spatio-temporal alignment: Ensuring that spatial and temporal elements across modalities (e.g., lip motion and speech) are precisely synchronized. "precise spatio-temporal alignment an open challenge."
- Spatiotemporal attention: Attention mechanisms that jointly model spatial and temporal relationships in video. "spatiotemporal attention"
- Start-End Frame Interpolation: Generating intermediate frames between given start and end frames within a sequence. "Start-End Frame Interpolation"
- Super-resolution: Post-processing step that upsamples low-resolution outputs to higher resolution with enhanced detail. "super-resolution and frame interpolation modules"
- Symmetric twin backbone: Two mirrored branches (e.g., audio and video) with aligned dimensions to facilitate cross-modal attention. "a symmetric twin backbone design"
- T2AV (text-to-audio+video): Generating synchronized audio and video content from textual prompts. "Joint text-to-audio+video (T2AV) generation"
- Temporal index offsets: Assigning offset indices to reference and generated tokens to disambiguate their positions in temporal RoPE. "with temporal index offsets"
- VAE (Variational Autoencoder): A generative encoder-decoder that maps data to a latent space and reconstructs it, used here for video/image encoding. "VAE-encoded conditional frames"
- Velocity field: The vector field predicted in flow matching that guides noise toward data over continuous time. "predicts the velocity field "
Collections
Sign up for free to add this paper to one or more collections.