Pro-HOI: Perceptive Root-guided Humanoid-Object Interaction
Abstract: Executing reliable Humanoid-Object Interaction (HOI) tasks for humanoid robots is hindered by the lack of generalized control interfaces and robust closed-loop perception mechanisms. In this work, we introduce Perceptive Root-guided Humanoid-Object Interaction, Pro-HOI, a generalizable framework for robust humanoid loco-manipulation. First, we collect box-carrying motions that are suitable for real-world deployment and optimize penetration artifacts through a Signed Distance Field loss. Second, we propose a novel training framework that conditions the policy on a desired root-trajectory while utilizing reference motion exclusively as a reward. This design not only eliminates the need for intricate reward tuning but also establishes root trajectory as a universal interface for high-level planners, enabling simultaneous navigation and loco-manipulation. Furthermore, to ensure operational reliability, we incorporate a persistent object estimation module. By fusing real-time detection with Digital Twin, this module allows the robot to autonomously detect slippage and trigger re-grasping maneuvers. Empirical validation on a Unitree G1 robot demonstrates that Pro-HOI significantly outperforms baselines in generalization and robustness, achieving reliable long-horizon execution in complex real-world scenarios.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Pro-HOI: Easy-to-understand summary
1) What is this paper about?
This paper shows a new way to let a human-shaped robot pick up, carry, and place objects (like boxes) safely and reliably in the real world. The system is called Pro-HOI. It helps the robot move its whole body while handling things, avoid obstacles, and even recover if it drops the object—all using only the robot’s own sensors and computer.
2) What questions were the researchers trying to answer?
They focused on a few simple questions:
- How can a humanoid robot learn to carry objects in many different situations, not just the ones it trained on?
- Can we give the robot easy-to-understand “commands” so it can both walk and manipulate objects at the same time?
- How can the robot notice when it drops something and pick it up again without help?
- Will the same system work well in the real world, not just in simulation?
3) How did they do it?
They built a full system that combines learning, planning, and perception. Here are the main ideas, explained in everyday language:
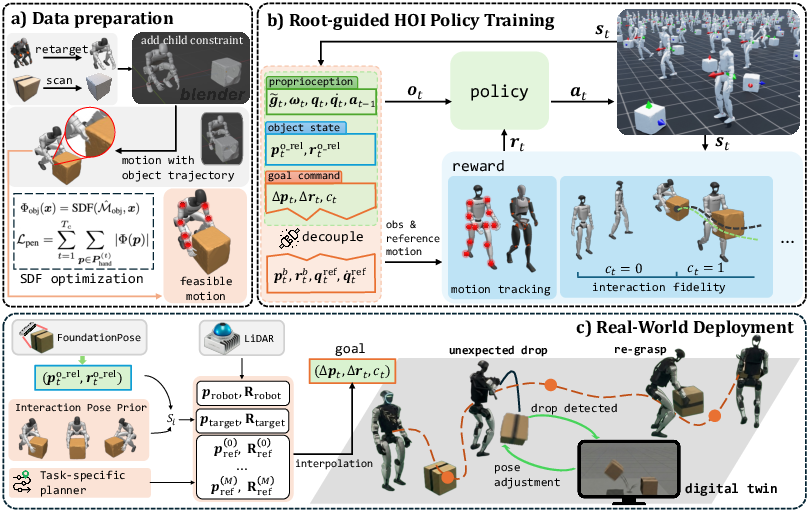
- A simple “path” command for the whole body: Instead of telling the robot exactly how every arm and leg should move, the robot is guided by a simple path for its “root” (think of the robot’s hip or body center—the place the rest of the body moves around). If you picture a “belly-button path” moving through space, the robot learns how to coordinate arms, legs, and balance to follow that path while handling an object. This path acts like a universal command that a higher-level planner (like a navigation tool) can set.
- Learning by practice with a teacher: The robot learns using reinforcement learning (practice with feedback). The “teacher” is a set of example motions (like how a person picks up and carries a box) captured from humans. But the robot does not copy every joint exactly. Instead, those examples are used mainly as “rewards” to encourage natural, human-like movement while still letting the robot figure out how to handle new box positions. This avoids lots of tricky, hand-tuned rules.
- Fixing “ghost” collisions in example motions: Sometimes, when you convert human motion to a robot, the hand might look like it goes slightly through the box (an animation glitch). They fix this with something called a Signed Distance Field (SDF), which is like a 3D heat map that tells how far a point is from the surface of an object. Using this, they adjust the motion so the robot’s hands really stay on the surface of the box—no “ghost” overlaps.
- Seeing and remembering objects: The robot uses its own camera and a small on-board computer to figure out where the box is in 3D. If the box falls and moves out of the camera’s view, the robot runs a “digital twin”—a physics simulation of the scene—to predict where the box likely landed. That’s like having a video-game clone of the real world that updates in real time, so the robot knows where to look and re-grasp.
- Planning safe paths: A standard path planner gives the robot a safe route around obstacles. The planner outputs a simple path for the robot’s root (the “belly-button path”), which the learned controller then follows while keeping the box steady.
- Making it work in the real world: During training in simulation, they randomize things like friction and object mass so the robot learns to handle surprises. This makes it more likely to work in real life (this trick is often called domain randomization). They run everything on a real humanoid robot (Unitree G1) with only on-board sensors and a small computer.
4) What did they find, and why is it important?
They tested the system a lot, both in simulation and on a real robot. Here’s what happened:
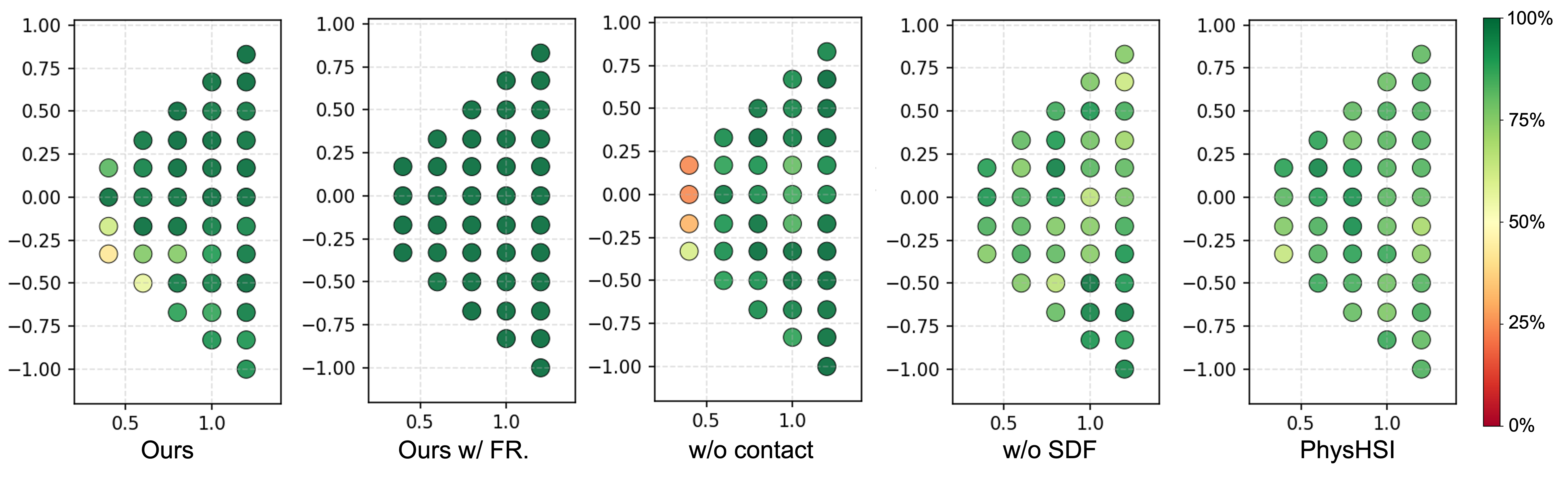
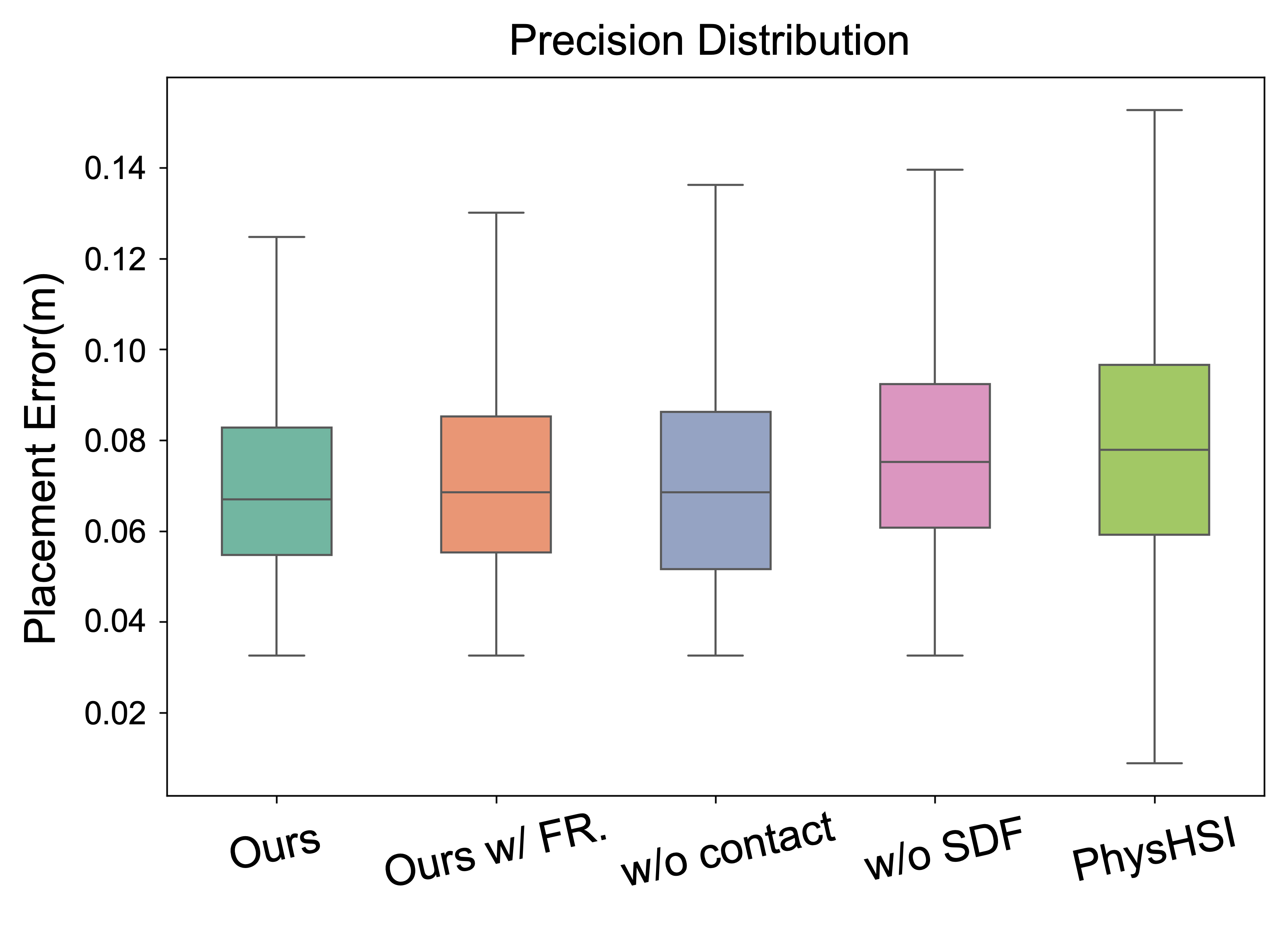
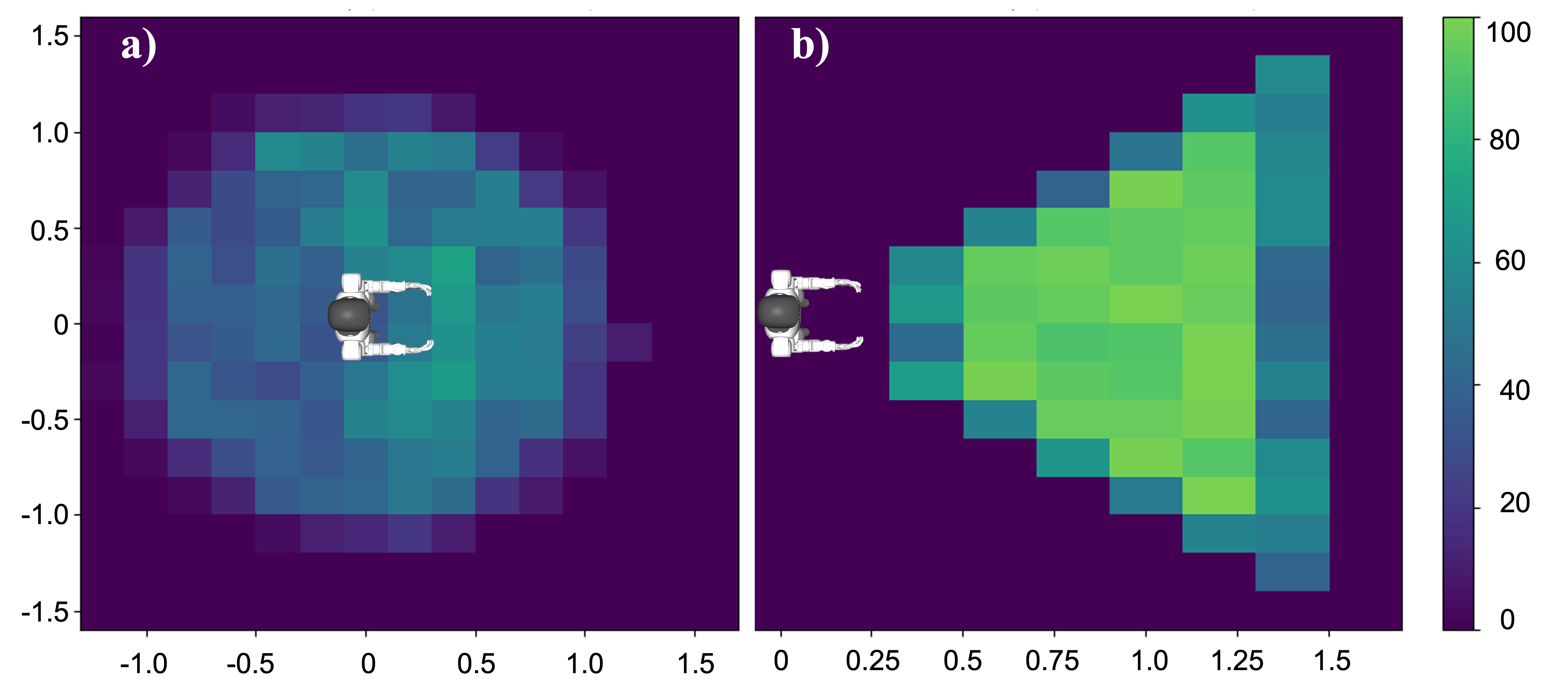
- It generalizes well: The robot could pick up and carry boxes from many different starting positions it hadn’t seen before. In big test sets, it had very high grasp success (nearly perfect in some tough tests) and placed boxes accurately.
- It’s robust over long tasks: The robot completed more than 15 carrying cycles in a row, showing it can work for a long time without failing.
- It avoids obstacles while carrying: By feeding the system a safe path, the robot could carry the box and move around obstacles at the same time.
- It recovers from mistakes: If the box slipped or fell, the robot noticed the problem, predicted where the box would end up using the digital twin, looked back toward it, and picked it up again.
- It works on real hardware: They ran all parts on the robot’s on-board computer. The system handled slow, medium, and faster walking speeds, kept decent grasp success, and placed the box close to the target spot.
Why this matters: Most older methods either needed outside equipment (like external motion-capture systems), lots of hand-tuned rules, or they struggled when something unexpected happened (like dropping the box). Pro-HOI shows a single, practical system that’s more general and more reliable.
5) What could this mean for the future?
- Easier robot control: A simple “root path” gives a clean interface for higher-level planners or even voice/goal commands. This could make it much easier to tell a robot what to do in factories, warehouses, hospitals, or homes.
- Fewer gadgets and setup: Because it uses only the robot’s own sensors and computer, it’s cheaper and easier to deploy in real places.
- Safer and more helpful robots: A robot that can notice mistakes and fix them (like re-grasping a dropped box) is safer and more useful around people.
- A reusable recipe: The same ideas—root-guided control, learning from motion examples as rewards, and digital-twin recovery—could be adapted to other tasks such as opening doors, carrying trays, or helping with deliveries.
In short, Pro-HOI gives humanoid robots a simple “language” for moving and handling objects, plus the smarts to keep going when things go wrong—bringing us closer to robots that can help in everyday environments.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to help guide future research.
- Task scope and object diversity: Evaluation is limited to box-carrying; generalization to other shapes (cylinders, mugs, handles), sizes, surface frictions, deformable or fragile objects, and articulated objects remains untested.
- Platform generality: All results are on Unitree G1; it is unclear how the approach transfers to humanoids with different morphology, DoFs, actuation, and sensor suites.
- Dependence on object CAD meshes: FoundationPose requires object meshes; handling truly unknown objects (no mesh, partial priors) and robustness to texture/lighting/occlusion is not characterized (no 6D pose accuracy/latency benchmarks).
- Digital Twin compute and latency: The paper inconsistently claims “exclusively onboard” compute yet states the Digital Twin runs on an external unit; the compute budget, synchronization, and latency impact on recovery are not quantified.
- Physics-model mismatch in failure recovery: No analysis of how simulator parameter errors (friction, restitution, contact modeling) affect drop-landing prediction accuracy and recovery success in real settings.
- Recovery scope: The recovery pipeline focuses on re-acquisition via gaze reorientation; the end-to-end closed-loop re-grasp strategy (approach, grasp planning, force closure under pose uncertainty) is not detailed or evaluated.
- Root-trajectory interface limits: It is unknown whether root-only commands plus a binary contact flag are sufficient for tasks requiring precise hand/tool trajectories (e.g., door opening, tool use, assembly, multi-point contacts).
- Contact scheduling at deployment: How the system reliably generates and times the contact command c_t online for novel scenarios (beyond imitation-derived priors) is under-specified and unevaluated.
- Interaction pose prior scalability: The nearest-neighbor prior from the dataset may not work for unseen geometries or poses; lack of learned, uncertainty-aware priors or adaptation mechanisms.
- Training data pipeline scalability: Manual object-hand association in Blender and SDF-based optimization may not scale to large datasets or many objects; no automation strategy or throughput/coverage analysis is provided.
- Data efficiency and coverage: The number/diversity of demonstrations, coverage of object poses/orientations, and how performance scales with data size/quality are not reported.
- Reward sensitivity: Although reward “engineering” is reduced, tracking rewards and weights still exist; there is no sensitivity analysis or evidence of cross-task portability without retuning.
- Sim-to-real randomization: DR parameter ranges (friction, CoM, restitution, masses) and their individual impact on transfer are not disclosed; no ablation on which randomizations matter most.
- Real-world rigor: Real-world trials are small (e.g., 10–28 runs), report limited metrics, and lack confidence intervals or significance tests; no real-world baseline comparison is provided.
- Moderate real-world grasp success: Grasp success rates (~60–70%) indicate room for improvement; failure mode taxonomy (slippage, misalignment, perception error, controller lag) is not analyzed.
- Proactive failure prevention: The system detects drops post hoc; strategies for proactively mitigating incipient slip (tactile, force/impedance adaptation) are not explored.
- Force/impedance control and tactile sensing: Control is PD in joint space without tactile feedback; safe, compliant manipulation under unknown loads, dynamic contacts, and human proximity is not addressed.
- Dynamic and 3D obstacle interaction: Obstacle avoidance uses a 2D TEB planner with static obstacles; handling dynamic agents, 3D obstacles (ducking, stepping), and tight spaces is not evaluated.
- Terrain variability: Performance on uneven, compliant, or sloped terrain while carrying loads is untested (foot slippage, CoM stability, step adaptation).
- State estimation robustness: FAST-LIO2 mapping drift, initialization, loop closure, and degraded geometries (e.g., corridors, glass) are not analyzed for long-horizon tasks.
- Payload and hardware limits: Maximum payload, effect of payload inertia on stability, actuator saturation, overheating, and energy consumption over long operations are not characterized.
- End-to-end latency and throughput: Frame rates and latency budgets for perception, planning, and control on Jetson NX (and any external compute) are not reported or profiled.
- Safety and human-aware behavior: No discussion of safety envelopes, force limits, near-human operation, or reactive behaviors that ensure safe HOI in human-centric environments.
- Reproducibility: Custom motion datasets, retargeting scripts, SDF optimization settings, full hyperparameters, DR ranges, and calibration procedures are not fully specified for replication.
- Theoretical guarantees: There is no analysis of observability or stability with root-guided observations; no formal guarantees on closed-loop stability/robustness under disturbances.
- Binary contact signal expressiveness: A binary c_t may be insufficient for nuanced contact phases (preload, force ramping, multi-contact sequencing); richer contact representations or force targets are not explored.
- Evaluation breadth: Additional metrics (CoM/foot slippage, contact forces, energy, task time, recovery time, perception error distributions) and stress tests (lighting, occlusion, sensor failures) are missing.
- Multi-object and multi-task scaling: Handling cluttered scenes, sequential tasks, object reorientation, stacking, and multi-goal scheduling is not studied.
- Portability to other planners and generators: While TEB is integrated, experiments with other high-level planners or generative motion models (and failure cases where root guidance conflicts with interaction feasibility) are absent.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with minimal adaptation based on the paper’s validated stack (Unitree G1, onboard Jetson NX, D435i camera, Mid-360 LiDAR, FAST-LIO2, FoundationPose, TEB planner, MuJoCo Digital Twin). Each bullet notes sector(s), potential tools/products/workflows, and key dependencies/assumptions.
- Humanoid tote/box transport in back-of-house logistics and retail
- Sectors: logistics, retail, hospitality
- What: Carry boxes/totes between storage and shelves; restocking; backroom inventory relocation; navigating narrow aisles with obstacle avoidance; autonomous re-grasp if dropped
- Tools/workflows: “Pro-HOI Carry Kit” (pretrained policy + ROS2 nodes), FoundationPose for 6D object tracking, TEB/Nav2 for local trajectory, FAST-LIO2 for base pose, Digital Twin failure recovery; schedule-based pick/place cycles
- Assumptions/dependencies: Known object meshes (or approximations) for FoundationPose; payload within G1 limits; mostly flat floors; acceptable lighting; safety perimeter and operational SOPs; map for planner; tuned gripper-hand geometry
- Intra-facility material movement in manufacturing cells
- Sectors: manufacturing, electronics, light assembly
- What: Move bins/fixtures between stations; multi-cycle operations; flexible cell reconfiguration without infrastructure changes
- Tools/workflows: Root-trajectory interface to connect with factory MES/WMS; reusable grasp priors for standard totes; Digital Twin for recovery
- Assumptions/dependencies: Stable totes/fixtures with meshes; process integration to provide waypoints; limited human traffic or collaborative safety safeguards
- Hospital portering and supply runs (non-patient-facing)
- Sectors: healthcare
- What: Deliver linens/consumables between storage and nursing stations; on-device sensing reduces privacy risk; failure recovery in busy corridors
- Tools/workflows: Route scheduling via hospital logistics system; on-device perception-only pipeline; drop detection and re-grasp
- Assumptions/dependencies: Hospital safety policies; conservative speed limits; stairs/ramps handling may require additional training; hygiene protocols; known container geometries
- Facilities and campus services (mailrooms, libraries, IT equipment moves)
- Sectors: corporate services, education
- What: Repetitive, long-horizon transport tasks with obstacle avoidance and multi-cycle autonomy
- Tools/workflows: Timed planners for off-peak hours; waypoint-based missions; integrated failure recovery
- Assumptions/dependencies: Route maps; mesh approximations for common boxes; safe human-robot interaction policies
- On-device, privacy-preserving perception workflows for humanoids
- Sectors: software, robotics, privacy-sensitive deployments
- What: Full onboard compute for perception and control; deploy in environments with strict data policies (no cloud)
- Tools/workflows: Jetson NX deployment guide; ROS2 nodes for FoundationPose/FAST-LIO2; logging and monitoring tools
- Assumptions/dependencies: Sufficient GPU budget on target hardware; thermal/power management; lighting conditions suitable for RGB-D
- Developer middleware: Root-trajectory command interface for planners
- Sectors: software, robotics
- What: Standardized API to accept 6-DoF root trajectories and binary contact flags; drop-in integration with TEB/Nav2/MoveIt
- Tools/products: “RootTrajectory Bridge” ROS2 package; examples for waypoint, lattice, and learned planners
- Assumptions/dependencies: Platform-specific adapters for different humanoids; synchronization with controller frequency
- Digital Twin–based failure detection and recovery as a standalone module
- Sectors: robotics software, quality assurance
- What: “DropGuard” module that predicts post-drop resting pose and orients sensors/robot to reacquire objects
- Tools/workflows: MuJoCo-backed simulation synchronized with real-time state; heuristics for contact-state consistency; gaze-control interface
- Assumptions/dependencies: Physics parameters (mass/friction) calibrated; communication latency bounded; may require separate compute if on-device resources are tight
- Motion retargeting and SDF-based contact optimization toolkit
- Sectors: robotics R&D, content creation
- What: Reduce hand–object penetration in HOI demos; produce physically feasible reference motion for training
- Tools/products: “SDF-Retarget Studio” Blender plugin and scripts; integration with GMR retargeting
- Assumptions/dependencies: Clean meshes; SDF generation pipeline; retargeting quality affects downstream RL sample efficiency
- Academic benchmarking for generalizable HOI with minimal observation
- Sectors: academia, education
- What: Reproducible stack to study sim-to-real HOI, root-guided RL, and failure recovery; evaluate in ID/OOD regimes
- Tools/workflows: Public training scripts, MuJoCo sim harness, evaluation grids, ablation templates
- Assumptions/dependencies: Access to humanoid or high-fidelity simulator; MuJoCo license; curated HOI motion clips
- Policy pilots for “on-device-only sensing” deployments
- Sectors: policy, governance, compliance
- What: Immediate governance templates for robots that process perception on-device; reduced data exposure footprint
- Tools/workflows: Risk assessment checklists; logs and audit trails demonstrating no external streaming
- Assumptions/dependencies: Organizational buy-in; alignment with existing privacy standards; robust on-device cybersecurity
Long-Term Applications
These use cases require further research, scaling, or productization (e.g., broader object coverage, heavier loads, unstructured terrain, tighter human-robot collaboration, regulatory alignment).
- General household assistance with multi-object, diverse grasps
- Sectors: consumer robotics, eldercare
- What: Move groceries, laundry baskets, small furniture; robustly handle unknown objects beyond boxes
- Needed advances: Object-agnostic pose estimation (no mesh), tactile/force sensing for grasp adaptation, bimanual dexterity and compliance, better perception in clutter
- Dependencies/assumptions: Safer hands and contact compliance; household safety certification; reliable HRI interfaces
- High-throughput humanoid handlers in e-commerce fulfillment
- Sectors: logistics, warehousing
- What: End-to-end picking/transport flows; integration with WMS; long shifts; high velocity while carrying
- Needed advances: Endurance (thermal, battery), stronger arms/grippers, global planning + local root guidance at scale, fleet coordination
- Dependencies/assumptions: Comprehensive safety and throughput validation; standardized totes; floor variability handling
- Public-space last-meter delivery and concierge services
- Sectors: retail, hospitality, smart cities
- What: Navigate lobbies, elevators, sidewalks to deliver packages; interact with public safely
- Needed advances: Multi-modal perception under weather/lighting; social navigation; policy/regulatory approvals for public operation
- Dependencies/assumptions: Insurance frameworks, speed/zone restrictions, robust connectivity
- Search-and-rescue supply carriage in disaster zones
- Sectors: public safety, defense
- What: Carry equipment through rubble/clutter; maintain grasp under shocks; recover from drops on uneven terrain
- Needed advances: Terrain-aware root planning, ruggedized sensors, stronger failure recovery under unknown physics, teleoperation fallback
- Dependencies/assumptions: Harsh environment survivability; specialized locomotion skills; operator training
- Standardization of a cross-platform “root-guided” command API
- Sectors: robotics platforms, standards bodies
- What: Vendor-agnostic interface defining 6-DoF root trajectory + contact schedule as a control contract
- Needed advances: Industry consortium, reference implementations across humanoids, compliance test suites
- Dependencies/assumptions: Vendor cooperation; mappings to proprietary controllers
- Cloud–edge hybrid Digital Twin services for predictive recovery
- Sectors: robotics software, AIOps
- What: Centralized twin simulations for fleets to predict failures (drops, slips) and suggest recovery
- Needed advances: Real-time synchronization at scale, robust parameter identification, safety guarantees for suggested actions
- Dependencies/assumptions: Reliable low-latency networks; data security; standardized telemetry
- Force-adaptive HOI and safe physical collaboration
- Sectors: manufacturing, healthcare
- What: Co-carry tasks with humans; compliant handing-over; variable loads and deformable items
- Needed advances: Integrated force/torque sensing, learning impedance control, richer contact-state inference, human intent prediction
- Dependencies/assumptions: HRC safety standards; certification for physical contact
- Energy- and time-optimal root trajectory planning under load
- Sectors: energy efficiency, operations research
- What: Optimize paths and motions to minimize energy while meeting deadlines under varying payloads
- Needed advances: Accurate energy models; online optimization coupled to RL policy; learning planners with constraints
- Dependencies/assumptions: Battery and actuator telemetry; policy–planner co-design
- Learning without object meshes (category- or shape-agnostic HOI)
- Sectors: general-purpose robotics
- What: Foundation models or category-level pose estimation to manipulate novel items
- Needed advances: Self-supervised 6D pose estimation, grasp synthesis without CAD, tactile-driven state estimation
- Dependencies/assumptions: Diverse training data; robust tactile hardware; domain generalization
- Regulatory and insurance frameworks for autonomous humanoid load handling
- Sectors: policy, insurance
- What: Standards for speed limits, load limits, safe operating envelopes, black-box logging for incident review
- Needed advances: Industry benchmarks, third-party validation protocols, incident taxonomy and risk models
- Dependencies/assumptions: Multi-stakeholder engagement (manufacturers, insurers, regulators, unions)
Notes on Cross-Cutting Assumptions and Dependencies
- Object modeling: Many immediate workflows assume access to object meshes or accurate approximations for FoundationPose; long-term viability requires mesh-free or category-level methods.
- Hardware: Results were validated on Unitree G1 with specific sensors and Jetson NX; other platforms will need controller retargeting and tuning.
- Environment: Demonstrations emphasize indoor, generally flat environments; uneven terrain, stairs, and outdoor conditions require additional locomotion skills and perception robustness.
- Compute: Digital Twin can run onboard for light loads but may require external or cloud resources for complex scenes/fleets; latency and synchronization constraints apply.
- Safety/compliance: Physical HRI, speed/payload policies, and fail-safes are mandatory for commercial deployments; certification pathways are still maturing.
- Generalization envelope: Current policies are trained on box-carrying; extending to varied objects, grasp strategies, and heavy loads requires further data, sensing (including tactile), and training.
Glossary
- 6-DoF interpolation: Interpolating both position and orientation over time to produce a continuous six-degree-of-freedom trajectory. "we apply 6-DoF interpolation to the constructed waypoint sequence."
- 6D pose tracking: Estimating and following an object’s full 3D position and 3D orientation over time. "To ensure robust 6D pose tracking under partial occlusion during interaction"
- Adam optimizer: A stochastic gradient-based optimization algorithm that adapts learning rates for each parameter. "We minimize using the Adam optimizer~\cite{kingma2015adam} to keep the hands in contact with the object's surface."
- Adversarial Motion Priors (AMP): A learning technique that uses adversarially learned priors over motion to encourage naturalistic behavior. "incorporating Adversarial Motion Priors (AMP) \cite{amp}"
- Asymmetric Actor-Critic: An RL setup where the critic has access to privileged information that the actor does not, improving learning while keeping the policy deployable. "in an asymmetric Actor-Critic architecture \cite{pinto2017asymmetric}"
- Center of Mass (CoM): The point representing the average location of mass in a robot, important for balance and dynamics. "the agent's center of mass (CoM)"
- Child Of constraint (Blender): A rigging constraint that attaches one object’s transform to another’s in Blender. "using the `Child Of' constraint in Blender"
- Contact Phase Lag (CPL): The temporal delay between commanded and actual contact events during interaction. "Contact Phase Lag (CPL)"
- Degrees of Freedom (DoF): The number of independent joint or body movements a robot can control. "29 degrees of freedom (DoF)"
- Digital Twin: A physics-simulated replica of a real system used for state estimation and prediction. "we propose a Digital Twin module powered by the MuJoCo simulator \cite{todorov2012mujoco}."
- Domain Randomization (DR): Training with randomized simulation parameters to improve robustness and transfer to the real world. "we employ Domain Randomization (DR) \cite{peng2018sim} during training"
- FAST-LIO2: A lidar-inertial odometry algorithm for fast, robust state estimation. "FAST-LIO2 \cite{xu2022fast} for root pose estimation"
- Field of View (FoV): The observable area captured by a sensor or camera. "limited FoV"
- FoundationPose: A foundation model for 6D object pose estimation and tracking without task-specific fine-tuning. "FoundationPose for 6D object pose estimation"
- General Motion Retargeting (GMR): A method to adapt human motion data to different robot morphologies. "General Motion Retargeting (GMR) \cite{joao2025gmr}"
- Humanoid-Object Interaction (HOI): Interactions where a humanoid robot manipulates or engages with objects. "Humanoid-object interaction (HOI) \cite{pan2025tokenhsi, wang2025sims}"
- Interaction Pose Prior: Stored relative robot–object configurations used to guide reliable grasping and interaction. "combined with the Interaction Pose Prior and a task specific planner to generate target root trajectories."
- Loco-manipulation: Simultaneous locomotion and manipulation by a robot’s whole body. "a generalizable framework for robust humanoid loco-manipulation."
- MuJoCo: A physics engine commonly used for accurate and efficient robot simulation. "MuJoCo simulator \cite{todorov2012mujoco}"
- Motion Capture (MoCap): Systems that record human or object motion, often used for imitation learning. "Motion Capture (MoCap) systems for deployment"
- Penetration loss: A loss term penalizing interpenetration between meshes to enforce physically plausible contact. "a penetration loss based on SDF"
- Phase variable: A normalized scalar indicating progress through a motion or task cycle. "scalar phase variables (e.g., )"
- Proportional–Derivative (PD) controller: A feedback controller that computes motor torques from joint position and velocity errors. "subsequently converted into motor torques via a PD controller."
- Privileged information: States available to the critic during training but not to the deployed policy. "the critic has access to privileged information (e.g., base velocity)"
- Proprioceptive state: Internal robot sensing such as joint positions and velocities. "the proprioceptive state"
- Proximal Policy Optimization (PPO): A popular on-policy RL algorithm using clipped objective updates for stability. "Proximal Policy Optimization (PPO) \cite{schulman2017proximal}"
- Root Orientation Error (ROE): The angular discrepancy between reference and executed base orientations. "Root Orientation Error (ROE)"
- Root Position Error (RPE): The positional discrepancy between reference and executed base positions. "Root Position Error (RPE)"
- Root trajectory: The desired time sequence of the robot base’s pose guiding whole-body behavior. "conditioning the policy solely on the desired root trajectory"
- Signed Distance Field (SDF): A representation storing distances to the nearest surface, used for collision and contact reasoning. "Signed Distance Field loss"
- Sim-to-real transfer: Methods enabling policies trained in simulation to work reliably on real hardware. "sim-to-real transfer techniques"
- Timed Elastic Band (TEB): A local planner that optimizes time-parameterized trajectories under kinematic and dynamic constraints. "the Timed Elastic Band (TEB) \cite{rosmann2017teb} local planner"
- Trajectory Optimization (TO): Formulating motion generation as an optimization over trajectories subject to dynamics and constraints. "Trajectory Optimization (TO) \cite{ruscelli2020multi, figueroa2020dynamical, liu2025opt2skill}"
- Voxel-based downsampling: Reducing mesh complexity by aggregating points into voxel cells. "we utilize voxel-based downsampling to obtain simplified meshes"
- Xsens inertial motion capture: An IMU-based MoCap system capturing human motion without external cameras. "using an Xsens inertial motion capture system."
Collections
Sign up for free to add this paper to one or more collections.