OmniLottie: Generating Vector Animations via Parameterized Lottie Tokens
Abstract: OmniLottie is a versatile framework that generates high quality vector animations from multi-modal instructions. For flexible motion and visual content control, we focus on Lottie, a light weight JSON formatting for both shapes and animation behaviors representation. However, the raw Lottie JSON files contain extensive invariant structural metadata and formatting tokens, posing significant challenges for learning vector animation generation. Therefore, we introduce a well designed Lottie tokenizer that transforms JSON files into structured sequences of commands and parameters representing shapes, animation functions and control parameters. Such tokenizer enables us to build OmniLottie upon pretrained vision LLMs to follow multi-modal interleaved instructions and generate high quality vector animations. To further advance research in vector animation generation, we curate MMLottie-2M, a large scale dataset of professionally designed vector animations paired with textual and visual annotations. With extensive experiments, we validate that OmniLottie can produce vivid and semantically aligned vector animations that adhere closely to multi modal human instructions.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces OmniLottie, a smart system that can create high-quality vector animations (the kind that stay sharp when you zoom in) from different kinds of inputs—like text, images, and videos. It focuses on the Lottie format, which stores animations in a lightweight text file called JSON. The team also built a huge dataset (MMLottie-2M) and a fair test benchmark (MMLottie-Bench) to train and evaluate the system.
What questions did the researchers ask?
The researchers wanted to find out:
- How can we automatically generate editable, scalable vector animations from text, images, or videos?
- How do we make these animations follow the user’s instructions closely (for example, “a red rocket flies up and fades out”)?
- Can we simplify Lottie’s complex JSON files so a model learns the important parts (shapes and motion) instead of wasting effort on formatting?
- Can a single model handle multiple tasks (text-to-animation, image+text-to-animation, and video-to-animation) reliably?
How did they do it?
Lottie and why it matters
Think of “vector animations” like drawing instructions: “draw a circle at this position, move it to the right, change its color,” and so on. This is different from normal videos (called raster videos), which are like a big grid of colored dots. Vector animations:
- Stay sharp at any size (no blurriness when you zoom in),
- Are easy to edit (change color, motion, timing),
- Work well across different apps and devices.
Lottie is a popular vector animation format that stores all shapes and animation steps in a single JSON file. But Lottie JSON can be very long and full of technical details, which makes it hard for a model to learn from directly.
Turning Lottie into simple tokens (the tokenizer)
To solve the “too much messy text” problem, the authors created a Lottie tokenizer. A tokenizer turns complicated files into short, meaningful codes (tokens). Imagine replacing a long recipe with neat instructions like:
- “Start layer: shape”
- “Position: x=120, y=80”
- “Scale: 100%”
- “Opacity: 100”
- “Animate: move up, 2 seconds, ease-out”
This tokenizer:
- Removes repetitive or unimportant formatting,
- Keeps only the useful commands (shapes, effects, keyframes, positions),
- Converts numbers to discrete tokens using a simple formula (scale and offset), so the model can predict them more easily,
- Makes a clean sequence the model can read and write like a sentence.
In short: instead of making the model write long, fragile JSON text, it teaches the model to write a compact “command list” that can be turned back into a valid Lottie file.
The model that writes animations
OmniLottie uses a pretrained vision–LLM (VLM) as its “brain” (specifically Qwen2.5-VL). A VLM can understand text, images, and videos together (this is called “multi-modal”). The model then generates the animation tokens step by step—like writing one word at a time in a sentence (this is called “auto-regressive” generation).
Analogy:
- You give the model a prompt (text) and possibly an image or video.
- The model “thinks,” then writes a sequence of animation commands.
- Those commands are turned back into a valid Lottie JSON file.
- The JSON file plays as a vector animation.
Building a big training set: MMLottie-2M
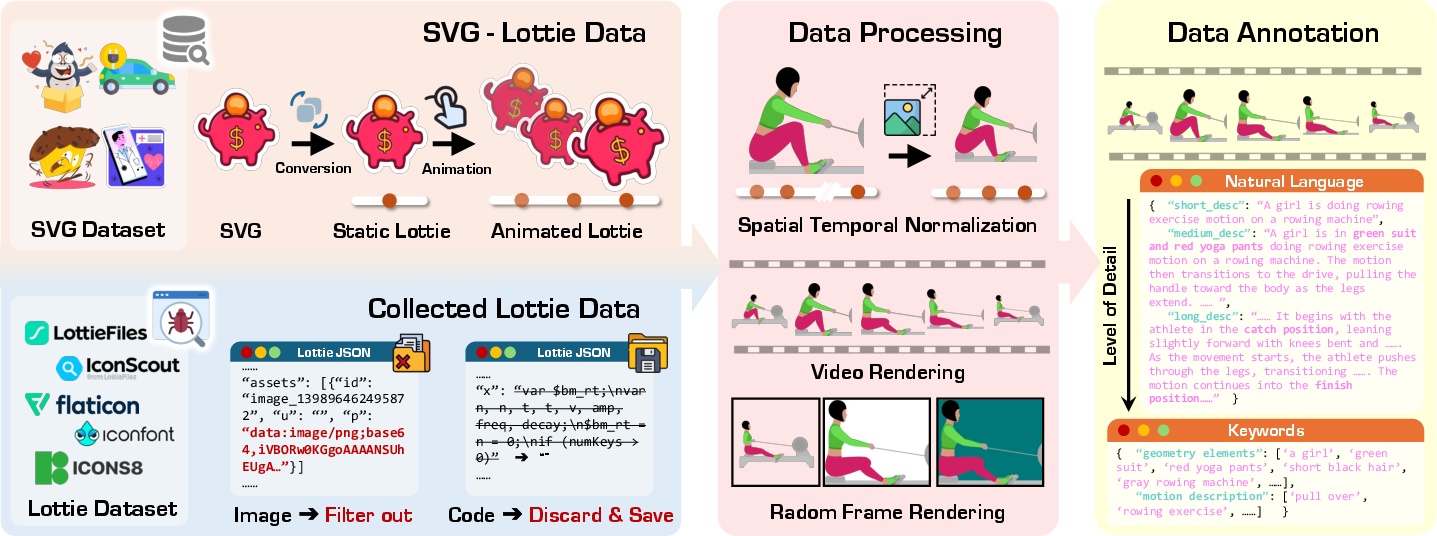
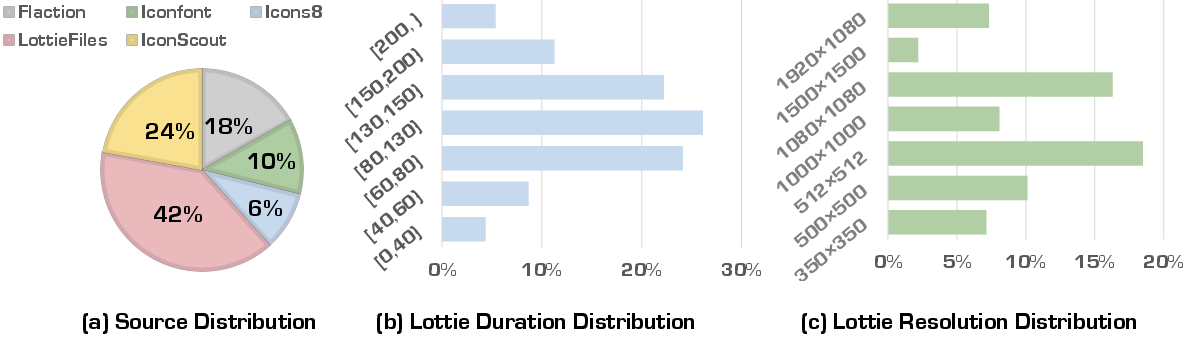
Good models need lots of good examples. The team built MMLottie-2M, a dataset with 2 million vector animations. They:
- Collected professional Lottie files from several websites,
- Cleaned and standardized them to a common canvas size and time range,
- Generated extra animated examples by adding motion templates to static SVG graphics (like “spin,” “zoom,” “fade,” “slide”),
- Added helpful captions and annotations for what’s in the animation and how it moves,
- Rendered preview videos and keyframes to help the model learn connections between text, image, video, and vector commands.
Testing with a fair benchmark: MMLottie-Bench
To measure progress, they created MMLottie-Bench, a test set with “real” examples (not seen during training) and “synthetic” ones (carefully generated with other tools). They measured:
- Visual quality (does the animation look smooth and natural?),
- Instruction following (does it contain the right objects and move the right way?),
- Reliability (does it produce a valid animation file often and quickly?).
They used metrics like:
- FVD (how natural the motion looks across frames),
- CLIP similarity (how well images/frames match the text prompt),
- Object Alignment and Motion Alignment (LLM judge scores: did the animation include the right stuff, moving in the right way?),
- PSNR/SSIM/DINO (measures for matching videos, clarity, and structure).
What did they find?
Here are the main results explained simply:
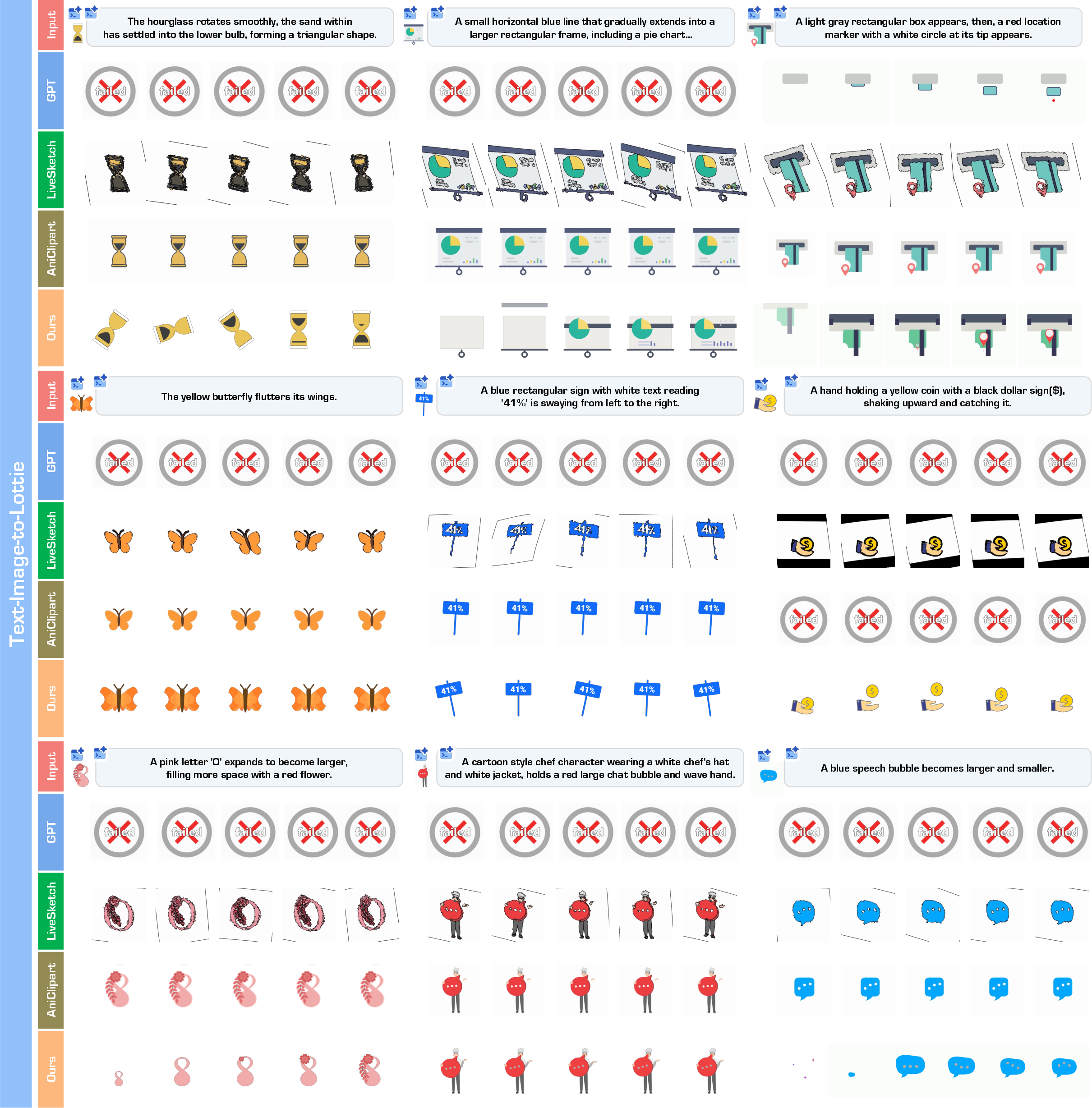
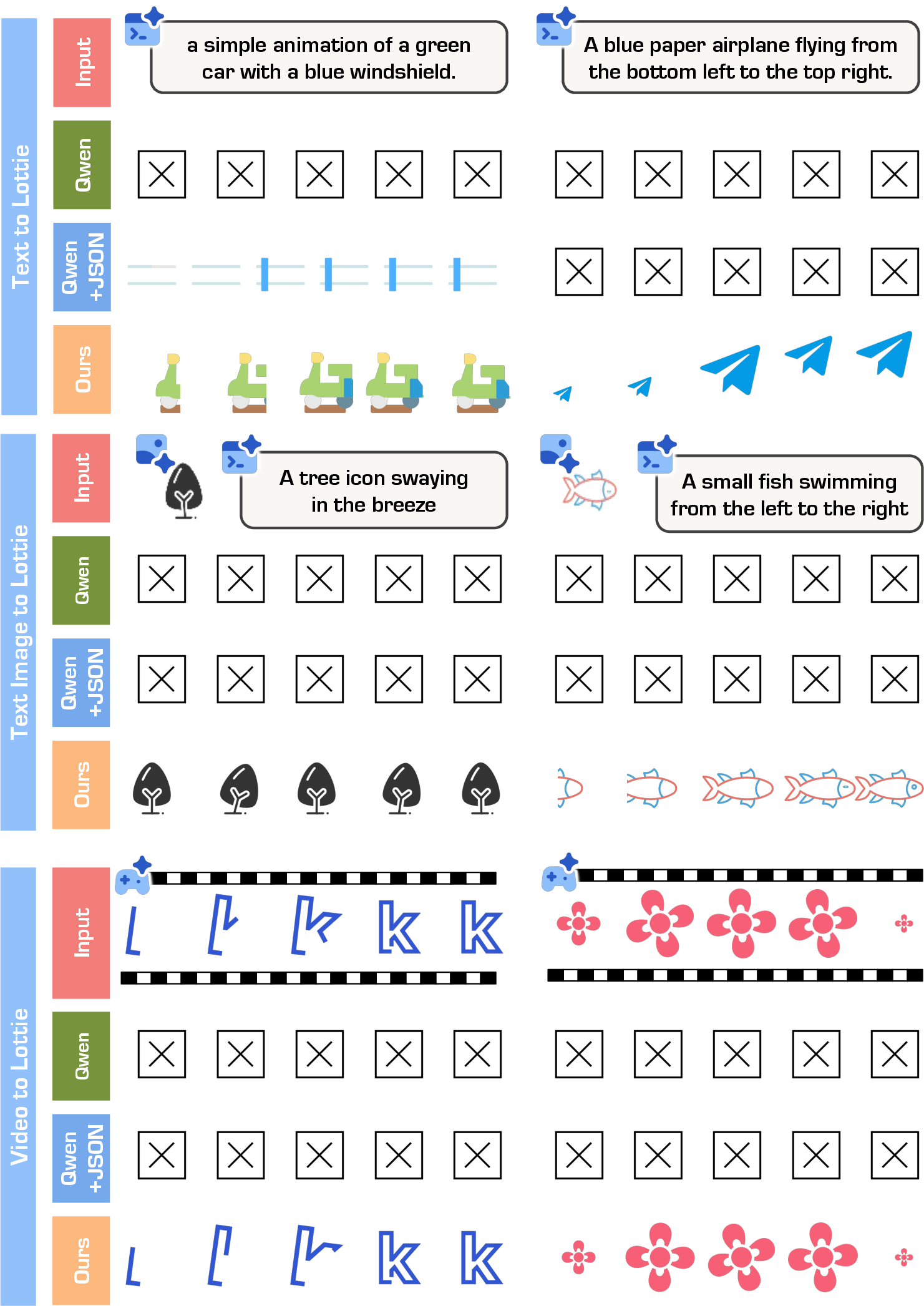
- OmniLottie generated valid, high-quality vector animations more often than other methods and commercial tools.
- It followed instructions more accurately: the right objects appeared and moved in the right direction, speed, and style.
- It achieved the best or near-best scores on most metrics (FVD, alignment, PSNR/SSIM/DINO), meaning smoother motion, clearer visuals, and better match to the inputs.
- The Lottie tokenizer made a big difference. Training on raw Lottie JSON was much less reliable. With the tokenizer, success rates and quality jumped.
- Mixing training data worked best when they combined mostly real Lottie animations with some animated SVGs. Too many SVGs made motions too simple; a balanced mix improved both shapes and motion.
- Compared to models that tried to write raw JSON directly, OmniLottie was both more robust and more efficient—because it focused on meaningful tokens rather than formatting.
Why does this matter?
This work helps make animation creation faster, easier, and more accessible:
- For students and hobbyists: you could describe an idea (“a paper plane glides upward while fading in”) and get a clean, editable vector animation.
- For designers and developers: it speeds up workflows, produces cross-platform animations, and keeps everything editable and scalable.
- For creative tools: it enables smarter “co-pilot” features that understand text, example images, or even short videos, then output native vector animations.
The research also shows a general strategy: when a format is too complex (like Lottie JSON), designing the right tokenizer can unlock strong models. It reduces confusion and lets the model learn the important parts—shapes, effects, and motion.
Limitations and future ideas:
- Sometimes the model still writes invalid or empty sequences. The team suggests adding safety checks (“constrained decoding”), training with rewards for files that render correctly, or combining the model with pro tools (like After Effects) to fix mistakes.
- Extremely long or complex animations remain challenging (context length limits). Future work could handle longer timelines or more layers more reliably.
Overall, OmniLottie shows that multi-modal, token-based generation is a powerful way to create editable, high-quality vector animations from simple instructions.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise list of concrete gaps and unresolved questions that emerge from the paper, intended to guide future research.
- Formal validity guarantees: No grammar-constrained or schema-aware decoding is implemented to prevent invalid token sequences; explore constrained/typed decoding, finite-state automata, or structured decoders to guarantee renderable Lottie output.
- Quantization fidelity: The impact of the offset/scale quantization on geometric accuracy, timing, easing curves, and render equivalence is not analyzed; determine error bounds, adaptive precision schemes, and trade-offs between token budget and fidelity.
- Round-trip integrity: Despite claims of lossless structural compression, numerical round-trips after quantization may alter renders; quantify visual and semantic drift after tokenization–detokenization cycles.
- Tokenizer coverage gaps: The tokenizer supports only five layer types (ty ∈ {0,1,3,4,5}); handling of image (ty=2), camera, audio layers, gradient fills, track mattes, masks, blend modes, and advanced effects is incompletely specified and not benchmarked.
- Expressions and procedural logic: After Effects expressions and other non-parameterizable behaviors are excluded during data curation; investigate representing, constraining, or compiling expressions into parameter sequences.
- 3D support: The ddd flag and camera-like behaviors are acknowledged but not supported or evaluated; assess feasibility of 3D/transformed layers and camera animations within the tokenizer and model.
- Cross-engine robustness: Outputs are evaluated with a single rendering stack; test cross-platform consistency and failure rates across Lottie players (Web, iOS, Android) and AE import.
- Success rate definition and diagnostics: “Success rate” lacks a formal, standardized validity protocol; define and publish schema checks, renderer logs, and multi-engine validation criteria.
- Vector-native metrics: Evaluation relies on raster proxies (FVD, CLIP) and LLM-as-judge; develop vector-specific metrics for path topology similarity, boolean ops, hierarchy/parenting accuracy, keyframe timing, easing curve matching, and parameter distribution alignment.
- LLM-as-judge reliability: Object/motion alignment is scored by a single closed-source LLM; quantify inter-judge reliability, calibration, and robustness to prompt phrasing, and release gold-standard human annotations for a subset.
- Dataset bias and coverage: Web-sourced assets may overrepresent certain styles/regions and underrepresent enterprise UI/UX or scientific visuals; audit style/content/motion diversity, language coverage, and introduce balancing/long-tail splits.
- Potential train–test contamination: Real subset is sourced from similar platforms as training data; provide near-duplicate and stylistic similarity checks, with leakage reports and de-duplication thresholds.
- Annotation noise: Multimodal captions generated by VLMs may be noisy or biased; measure caption accuracy, release human-verified subsets, and study the effect of annotation noise on instruction following.
- Motion template dependence: The motion library synthesized from clustering may bias the model toward canonical patterns; quantify diversity/novelty, coverage of non-templated motions, and mitigation strategies against template overuse.
- Variable duration and timing control: Training normalizes time to 0–16; study conditioning and generation for arbitrary timelines, fps, looping behaviors, and multi-scene sequences.
- Controllability and editability: Fine-grained controls (easing types, motion paths, color palettes, z-order, layer parenting, complexity budgets) are not exposed; design controllable tokens or constraint interfaces for professional workflows.
- Editing existing Lotties: The framework does not support instruction-conditioned editing or partial preservation of given layers; add masked/anchored generation and diff-style Lottie editing.
- Complexity scaling and context limits: The model’s maximum scene complexity vs. context length is not characterized; provide scaling laws for token length, memory use, and performance, and explore hierarchical or chunked generation.
- Efficiency and decoding strategy: Inference times are high and decoding strategies are not optimized; evaluate grammar-guided pruning, speculative decoding, cache-based prompting, and parallelized sampling to reduce latency.
- Reliability under stress: Failure taxonomy is provided, but robustness under adversarial/OOD prompts, unusually long sequences, or extreme parameter ranges is not quantified; benchmark stress tests and fallback generation strategies.
- Video-to-Lottie generalization: Video inputs used for supervision are renders of Lotties; assess performance on real-world raster videos (camera footage, motion graphics) and define conversion quality metrics beyond PSNR/SSIM.
- Fonts and multilingual text: Support for fonts, glyphs, kerning, and non-Latin scripts is not evaluated; measure multilingual prompt following, font substitution strategies, and text layout fidelity.
- File size and performance constraints: Effects of generation choices on file weight, runtime performance, and mobile playback are not analyzed; introduce metrics and constraints for deployability.
- Comparative structured baselines: No baseline with schema-constrained JSON/function-calling LLMs is included; compare against grammar-constrained JSON generation to isolate tokenizer benefits from structural constraints.
- Training details and reproducibility: Compute budgets, optimization schedules, and full hyperparameters are not disclosed; publish training recipes and seeds to enable faithful replication.
- Differentiable render feedback or RL: Training optimizes token likelihood only; investigate differentiable vector rendering and reinforcement learning with renderability and perceptual rewards.
- Safety/IP filtering: The dataset disclaimer notes third-party rights, but pipelines for license classification, brand/logo filtering, and takedown are not described; formalize compliance workflows.
- Audio/beat-synchronous animation: Audio layers and synchronization are out of scope; explore audio-conditioned Lottie generation and alignment metrics.
Practical Applications
Overview
OmniLottie introduces three core innovations with direct practical impact: (1) a Lottie tokenizer that converts complex JSON animations into compact, structured command–parameter tokens; (2) OmniLottie, an autoregressive VLM-based generator that creates Lottie vector animations from text, image, and video instructions; and (3) the MMLottie-2M dataset and MMLottie-Bench for training and benchmarking. Together, they enable editable, resolution-independent, cross-platform animations that can be generated and iterated far faster than traditional workflows.
Below are concrete applications, grouped by deployment horizon. Each item includes sectors, likely tools/products/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Text-to-animation copilot for designers (software, creative tools, advertising/marketing, product)
- What: Prompt-based generation of microinteractions, icon animations, loaders, banners, and branded motion assets as native Lottie.
- Tools/workflows: Plugins/extensions for Figma, Adobe After Effects, LottieFiles; “Prompt → Generate → Preview → Edit parameters → Export” flows; batch generation for A/B tests.
- Assumptions/dependencies: Stable integration via LottieFiles/AE scripting; human-in-the-loop review for brand/quality; model and base VLM licenses compatible with commercial deployment.
- Auto-animating static icon/SVG libraries (software, product design, e-commerce)
- What: Apply learned motion templates to static vector icon sets for consistent, on-brand motion systems.
- Tools/workflows: Ingest SVG library → text or preset motion prompts → Lottie output per icon → asset library publish.
- Assumptions/dependencies: SVG-to-Lottie conversion quality; motion template selection aligned with brand guidelines.
- Rapid onboarding and tutorial animation from UI captures (software, education, SaaS)
- What: Video-to-Lottie converts screen recordings or annotated screenshots into step-by-step vector animations for user onboarding or help centers.
- Tools/workflows: Product teams upload short screen capture clips → automatic Lottie tutorials → embed in in-app help.
- Assumptions/dependencies: Works best with clean UI footage and vector-friendly content; human QA to refine steps.
- Marketing and growth content at scale (advertising/marketing, social media)
- What: Generate campaign-specific animations (text-to-Lottie) for social posts, ads, emails; variant generation for personalization and A/B testing.
- Tools/workflows: Campaign brief → prompt templates → batch generation → automated CLIP/LLM checks for prompt adherence → deploy.
- Assumptions/dependencies: Brand governance rules layered on top; content moderation/safety filters; compute budget for batch runs.
- Localization and theming of motion assets (software, media localization)
- What: Adjust text layers, directionality (LTR/RTL), colors, and pacing across locales via parameter editing rather than re-animating.
- Tools/workflows: Tokenized Lottie → scripted updates to text/font/color/transform tokens → localized builds.
- Assumptions/dependencies: Font availability and layout policies per locale; UI integration pipelines.
- Accessibility variants for reduced motion and safety (software, public sector, education, healthcare apps)
- What: Produce reduced-motion or high-contrast versions by editing opacity, speed, and effect parameters; avoid flashing patterns.
- Tools/workflows: Accessibility profile presets → batch adjustments via tokenizer (e.g., lower amplitude/speed, disable flicker).
- Assumptions/dependencies: Rule sets aligned to WCAG; QA for edge cases; constrained decoding or rule-based post-processing.
- Lottie linting, validation, and minification in CI/CD (software tooling)
- What: Use the tokenizer for schema validation, renderability checks, parameter normalization, and diff/merge-friendly representations.
- Tools/workflows: Git pre-commit hooks; CI tasks that validate token sequences, normalize timelines/canvas; minify to reduce payload size.
- Assumptions/dependencies: Stable tokenizer API; coverage for common AE/Lottie features used by team.
- Classroom and MOOC content creation (education)
- What: Teachers generate vector animations of diagrams, processes, and concepts from prompts for lectures and slides.
- Tools/workflows: Text/image prompts → render Lottie → export to presentation or web player.
- Assumptions/dependencies: Educator prompts well-specified; optional human edits for accuracy; institution policy on generative assets.
- Documentation and internal training animations (enterprise, finance, software)
- What: Convert SOPs, release notes, and internal guides into short vector explainers (text-to-/image-to-Lottie).
- Tools/workflows: Docs → prompt templates → Lottie embeds in wikis/portals.
- Assumptions/dependencies: Review for compliance (especially in regulated industries); keep visuals abstract to avoid sensitive data.
- Research and benchmarking (academia, open-source)
- What: Use MMLottie-2M and MMLottie-Bench to study multimodal instruction following, tokenization for structured graphics, and evaluation protocols.
- Tools/workflows: Train/fine-tune models; reproduce benchmarks; ablation studies on tokenization and data mixing.
- Assumptions/dependencies: Dataset is research-only; respect IP and usage restrictions; compute resources for training.
Long-Term Applications
- End-to-end “brief-to-production” motion design pipeline (software, creative tools, enterprise)
- What: Agents that turn creative briefs and style guides into production-ready Lottie with constrained decoding and brand rules enforcement.
- Tools/workflows: Design system + brand tokens → generative agent → reviewer loop → shipment to web/mobile.
- Assumptions/dependencies: Robust constrained decoding; rule engines for brand/accessibility; integration with design systems.
- Cross-format generative motion (SVG/CSS, Rive, After Effects) from a unified token space (software ecosystem)
- What: Extend tokenization to other vector animation formats for multi-target exports.
- Tools/workflows: Abstract token spec → exporters for Lottie/SVG-CSS/Rive/AE → multi-platform distribution.
- Assumptions/dependencies: Formalized mappings between specs; vendor cooperation; performance testing across players.
- Real-time or on-device generative motion (mobile, gaming, AR/VR)
- What: Context-aware microinteractions generated at runtime to match user state/theme.
- Tools/workflows: Distilled/lightweight models → on-device inference or low-latency edge services → dynamic Lottie injection.
- Assumptions/dependencies: Significant model compression; latency budgets; privacy and energy constraints.
- Automated conversion of legacy raster motion to vector (media production, education)
- What: Video-to-Lottie for explainer videos, infographics, and training clips, preserving motion while vectorizing look.
- Tools/workflows: Batch “raster to vector motion” pipelines → human cleanup → re-usable vector libraries.
- Assumptions/dependencies: Best for stylized or flat-motion sources; complex photorealistic footage remains challenging.
- Personalized learning animations (education, healthcare)
- What: Generate tailored vector animations explaining medical procedures, benefits, or coursework from patient/student profiles and prompts.
- Tools/workflows: Template prompts + structured data → animation variants → deliver via portals/apps.
- Assumptions/dependencies: Privacy-preserving data pipelines; clinical/pedagogical review; alignment with accessibility needs.
- Financial and enterprise explainers at scale (finance, enterprise L&D)
- What: Turn research notes, policy changes, or compliance updates into branded micro-animations for employees or customers.
- Tools/workflows: Prompt templates with risk keywords → generation → automated compliance checks → distribution.
- Assumptions/dependencies: Strong governance for factuality and compliance; content approval workflows.
- Data-driven motion graphics from telemetry (IoT, robotics, operations)
- What: Animate device or robot logs and trajectories as vector dashboards for debugging and executive reporting.
- Tools/workflows: Telemetry parsers → tokenized motion templates → Lottie dashboards.
- Assumptions/dependencies: Stable mapping from numeric streams to motion grammar; domain customization.
- Motion accessibility policy auditors (public sector, large enterprises)
- What: Static analysis of Lottie token sequences to flag violations (e.g., excessive flicker, speed, opacity changes).
- Tools/workflows: CI policies → reports and autofixes → certification gates.
- Assumptions/dependencies: Standardized policy definitions; buy-in from accessibility teams; robust heuristics.
- Interactive co-creation agents with RL for renderability (software, creative tools)
- What: Agents that iteratively propose, render-check, and fix animations using “renderability rewards,” improving reliability without heavy manual QA.
- Tools/workflows: RL fine-tuning + sandbox renderer → constrained decoding → user feedback loops.
- Assumptions/dependencies: Efficient render-in-the-loop training; scalable evaluation metrics.
- Sector-specific motion libraries and generators (healthcare, education, fintech, e-commerce)
- What: Curated, domain-tuned motion packs (e.g., anatomy, lab workflows, fintech icons) with specialized prompts and safety filters.
- Tools/workflows: Domain curation → fine-tuned models → governed generation portals/APIs.
- Assumptions/dependencies: Licensed, domain-specific datasets; SME review; ongoing maintenance.
- Standards and procurement guidance for vector animation generation (policy, industry consortia)
- What: Use MMLottie-Bench-like protocols to set evaluation standards for generative motion quality, safety, and compliance in RFPs.
- Tools/workflows: Public benchmarks; certification suites; disclosure and reproducibility checklists.
- Assumptions/dependencies: Consensus among stakeholders; updates as models evolve; transparency requirements.
Notes on feasibility across applications:
- Licensing: MMLottie-2M is research-only; commercial systems may require re-training on licensed assets or rights-cleared subsets.
- Reliability: Although OmniLottie improves success rates, production use benefits from constrained decoding, validators, and human review.
- Performance: Current generation times (tens of seconds) and token lengths may need optimization for real-time or large-scale personalization.
- Content safety and brand alignment: Additional filters, rule-based post-processing, and style-token constraints are advisable for enterprise deployments.
- Format coverage: Some After Effects/Lottie edge features may remain unsupported without further tokenizer/decoder extensions.
Glossary
- After Effects expressions: scripting expressions in Adobe After Effects that dynamically modify layer properties during rendering. "After Effects expressions that dynamically modify properties."
- Autoregressive models: sequence models that generate content by predicting each next token conditioned on previously generated tokens. "Autoregressive models treat visual content as token sequences"
- Blend mode: a rendering control that determines how a layer’s pixels are composited with layers beneath it. "blend mode (bm)"
- CLIP similarity: a text–image embedding metric from CLIP used to assess semantic alignment between prompts and visuals. "CLIP similarity"
- Collapse transformations (ct flag): a Lottie setting that determines whether grouped transformations are collapsed for rendering. "The ct flag controls transformation collapsing."
- Cross-entropy loss: a standard training objective for probabilistic sequence prediction that penalizes divergence from the target token distribution. "with the standard cross-entropy loss."
- Detokenize: convert discrete tokens or command sequences back into structured Lottie JSON. "detokenized to Lottie JSONs"
- DINO: a self-supervised visual representation metric/model used to measure structural similarity. "and DINO"
- Diffusion-based video generation models: generative models that synthesize videos via iterative denoising (diffusion) processes. "the diffusion-based video generation models"
- FVD (Fréchet Video Distance): a metric that evaluates video quality by measuring distributional distance between generated and reference features. "We report FVD"
- Hierarchical representation: a nested data organization with parent–child relations used to structure layers and effects. "Lottie is a complex hierarchical representation"
- Keyframe: a frame marking a change in animation parameters (e.g., position, scale), enabling interpolation across time. "random keyframe extraction."
- LLMs: very large neural LLMs trained on massive corpora and capable of complex reasoning and generation. "With the rapid advancement of LLMs"
- LLM judge: using an LLM to automatically assess output quality or alignment as part of evaluation. "LLM judge"
- Lottie: a JSON-based vector animation format that stores shape, effect, and motion parameters in a single file. "we focus on Lottie, a light-weight JSON formatting for both shapes and animation behaviors representation."
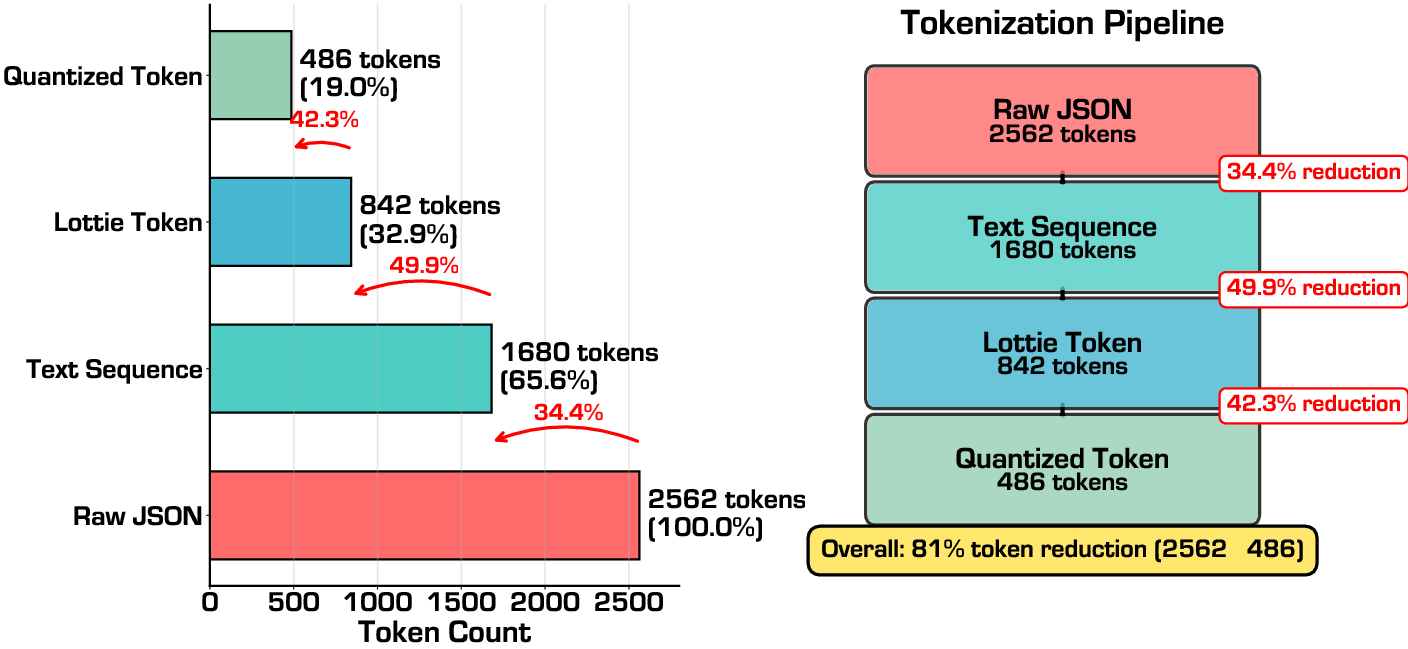
- Lottie tokenizer: a converter that serializes Lottie JSON into compact command–parameter sequences for efficient generation. "we propose a Lottie tokenizer that converts raw JSON into concise command sequences"
- Matte relations: layer masking relationships that define how one layer reveals or hides another (tt, tp, td). "matte relations (tt, tp, td)"
- MMLottie-2M: a large-scale dataset of professionally designed vector animations with textual and visual annotations. "MMLottie-2M"
- Motion Alignment: an evaluation metric (0–10) measuring how well generated motion matches type, direction, magnitude, targets, and smoothness. "Motion Alignment (Motion Align) (0â10)"
- Motion priors: pre-existing motion patterns derived from sources like reference GIFs or text-to-video models to guide animation. "applying motion priors derived from either a reference GIF"
- Motion signatures: encoded transform trajectories summarizing temporal motion patterns for clustering and transfer. "generating motion signatures that encode temporal patterns"
- Motion templates: canonical motion patterns extracted via clustering and applied to assets for augmentation. "extract numerous canonical motion templates."
- Null layer: a non-visual Lottie layer type used for transforms or hierarchy without rendering. "Null (ty=3)"
- Object Alignment: an evaluation metric (0–10) measuring correctness of object presence, type, count, visual traits, and spatial relations. "Object Alignment (Obj. Align) (0â10)"
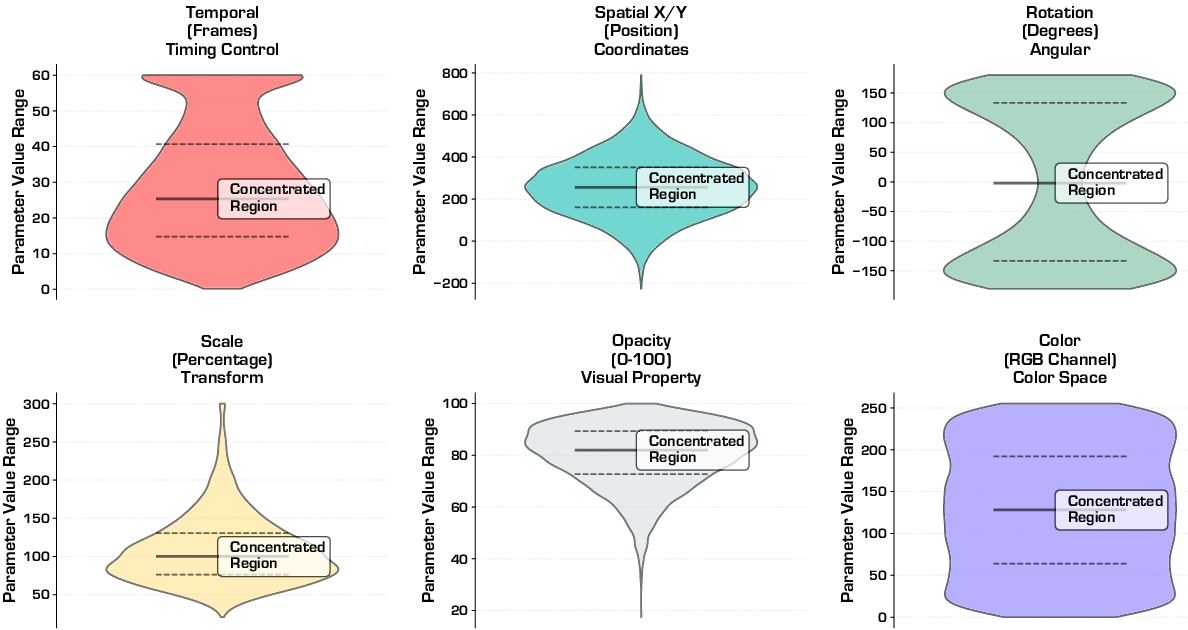
- Offset-based tokenization: mapping continuous parameters to discrete tokens using type-specific scales and vocabulary offsets. "Our offset-based tokenization maps continuous Lottie parameters to discrete tokens:"
- Opacity: the transparency level of a layer (0–100 in Lottie) affecting visibility. "rotation, scale, position, opacity"
- Parent-child relationships: hierarchical links that reconstruct the scene structure and inheritance among layers. "through parent-child relationships"
- Precomposition: a Lottie layer type referencing nested compositions (sub-scenes) used for grouping and reuse. "Precomposition (ty=0)"
- PSNR (Peak Signal-to-Noise Ratio): a reconstruction fidelity metric comparing generated frames to references. "PSNR"
- Raster videos: pixel-based video representations that lack editability and resolution scalability compared to vector formats. "Compared to raster videos"
- Resolution-independent representation: graphics that can be scaled to different sizes without loss of quality. "resolution-independent representation"
- Sequence modeling: treating complex content (images, animations) as token sequences for autoregressive generation. "amenable to sequence modeling"
- Shape layer: a Lottie layer type containing vector shapes and paths for rendering geometry. "Shape (ty=4)"
- Solid layer: a Lottie layer type representing a solid-color rectangle used as a background or element. "Solid (ty=1)"
- Spatio-temporal normalization: standardizing animations to fixed spatial (canvas) and temporal (timeline) ranges. "spatio-temporal normalization"
- SSIM (Structural Similarity Index Measure): a perceptual quality metric assessing structural similarity between images/videos. "SSIM"
- SVG (Scalable Vector Graphics): a vector image format that stacks shapes and paths and can embed CSS animations. "SVG stacks rects, circles, and paths for shapes and embeds CSS codes for animation."
- Text layer: a Lottie layer type containing textual content with style and animation parameters. "Text (ty=5)"
- Time remapping: altering a layer’s playback timing by remapping frames to different timestamps. "tm for time remapping"
- Token efficiency: an efficiency measure based on average token length of generated outputs. "token efficiency average token length of generated Lottie JSON"
- Transform trajectories: time-series of transforms (rotation, scale, position, opacity) across keyframes describing motion. "extract transform trajectories (rotation, scale, position, opacity) across keyframes"
- Vector animation: animation created using vector graphics rather than rasterized video frames. "Vector animation is a type of computer animation"
- Vision-LLM (VLM): models that jointly process visual and textual inputs for multimodal understanding and generation. "we adopt a pre-trained VLM, specifically Qwen2.5-VL"
- Video-to-Lottie: the task of converting input videos into vector animations in the Lottie format. "For Video-to-Lottie, we report FVD, PSNR, SSIM, and DINO"
Collections
Sign up for free to add this paper to one or more collections.