How Far Can Unsupervised RLVR Scale LLM Training?
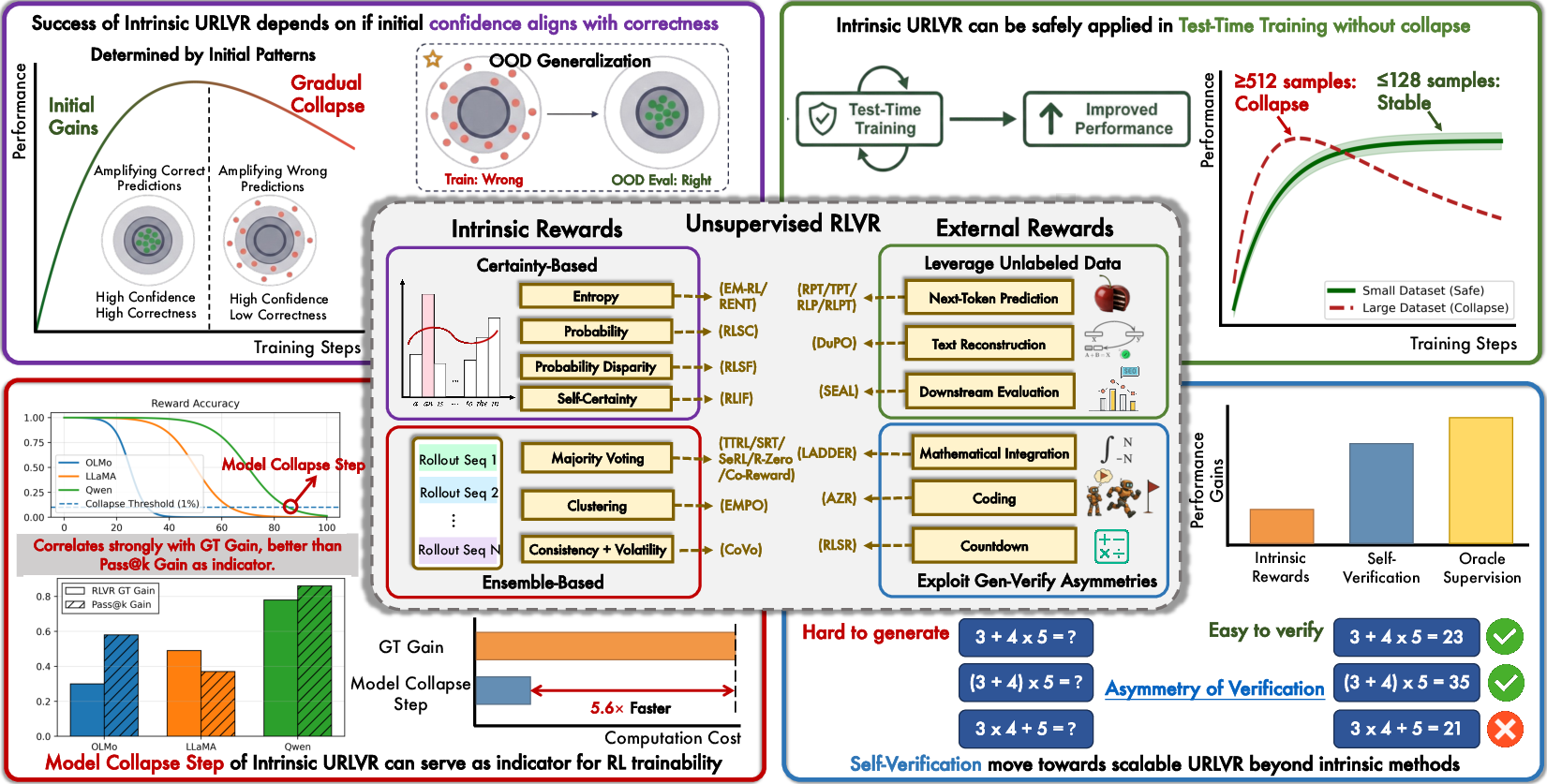
Abstract: Unsupervised reinforcement learning with verifiable rewards (URLVR) offers a pathway to scale LLM training beyond the supervision bottleneck by deriving rewards without ground truth labels. Recent works leverage model intrinsic signals, showing promising early gains, yet their potential and limitations remain unclear. In this work, we revisit URLVR and provide a comprehensive analysis spanning taxonomy, theory and extensive experiments. We first classify URLVR methods into intrinsic versus external based on reward sources, then establish a unified theoretical framework revealing that all intrinsic methods converge toward sharpening the model's initial distribution This sharpening mechanism succeeds when initial confidence aligns with correctness but fails catastrophically when misaligned. Through systematic experiments, we show intrinsic rewards consistently follow a rise-then-fall pattern across methods, with collapse timing determined by model prior rather than engineering choices. Despite these scaling limits, we find intrinsic rewards remain valuable in test-time training on small datasets, and propose Model Collapse Step to measure model prior, serving as a practical indicator for RL trainability. Finally, we explore external reward methods that ground verification in computational asymmetries, showing preliminary evidence they may escape the confidence-correctness ceiling. Our findings chart boundaries for intrinsic URLVR while motivating paths toward scalable alternatives.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a big question: Can we keep improving LLMs without relying on tons of human-made labels? The authors study a family of methods called “Unsupervised Reinforcement Learning with Verifiable Rewards” (URLVR). These methods give models rewards for correct behavior even when we don’t have official answers, by using signals we can check automatically. The paper builds a clear map of these methods, explains the core theory behind them, runs large experiments, and shows both where they work and where they break. It also points to better ways forward.
What the paper is trying to find out
The authors focus on five simple questions:
- Can “intrinsic” rewards (signals from the model itself) really scale up LLM training?
- Why do these methods often show early improvements, then suddenly fail or “collapse”?
- Under what conditions do intrinsic rewards help, and when do they hurt?
- Is there a quick way to predict if training will go well before spending lots of compute?
- Are there alternative “external” reward methods that avoid these limits and keep improving?
How they studied the problem
To make everything easy to understand, the authors split URLVR methods into two main types.
Intrinsic rewards (signals from the model itself)
These methods don’t look at the world to judge the model; they look at the model’s own behavior:
- Certainty-based: Reward the model when it is very confident in its next words. Think of this like “cheering” when the model sounds sure, because we hope confidence means correctness.
- Technical terms like “entropy” and “KL divergence” are just different ways to measure how peaked or spread-out the model’s word choices are. Lower entropy = more confidence.
- Ensemble-based: Generate multiple answers and give reward when many agree (majority voting). This is like asking a crowd for opinions and trusting the most common answer.
The authors develop a unified theory showing that, despite different formulas, all intrinsic methods do the same fundamental thing: they “sharpen” the model’s initial preferences. Sharpening means making the model more certain about whatever it already tends to choose.
External rewards (signals outside the model)
These methods get rewards from the task or the data itself, not from the model’s confidence:
- Unlabeled data rewards: Use massive text without labels. The model gets rewarded for predicting the next token correctly, or for reconstructing text well. The data provides the “ground truth” through the natural structure of language.
- Generation–verification asymmetry: Some tasks are hard to solve but easy to check. For example:
- Math: It’s hard to find the right formula, but easy to check a proposed formula by plugging in numbers.
- Code: It’s hard to write a program, but easy to run tests to see if it works.
- Theorem proving: Hard to invent proofs, easy to verify them with a proof checker.
- In these cases, the reward comes from an external checker, like a calculator, a compiler, or a proof assistant.
Experiments and measurements
The authors:
- Test many intrinsic methods across different models, datasets, and settings.
- Track training signals like “reward accuracy” (does the pseudo-reward match the real answer?), “entropy” (how confident the model is), and “collapse” patterns.
- Propose a practical indicator called the “Model Collapse Step” that estimates how far training can go before things go wrong.
- Compare intrinsic methods with external methods to see who keeps improving.
What they discovered and why it matters
The “sharpening” mechanism explains both success and failure
- If the model’s initial confidence lines up with the correct answer, sharpening helps: the model becomes more certain and more accurate.
- If confidence does not match correctness, sharpening hurts: it amplifies wrong answers, leading to “model collapse.”
Think of it like turning up the volume. If you’re playing the right song, louder is great. If it’s the wrong song, louder just makes the noise worse.
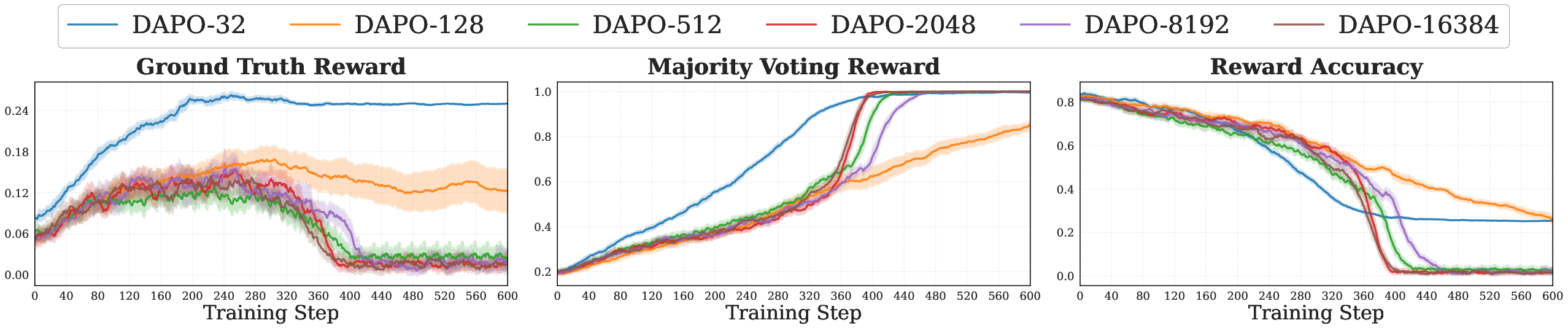
Intrinsic methods show a “rise-then-fall” pattern
- Early on, performance goes up. Later, it often collapses.
- This happens across many intrinsic methods and settings. The methods differ in how they fail:
- Gradual degradation: Some keep label accuracy for a while then fade.
- Length collapse: When the reward favors short answers, the model becomes confident but too brief.
- Repetition collapse: When average confidence is rewarded, the model may repeat high-probability tokens, sounding certain but not correct.
This shows that optimizing “confidence” is not the same as optimizing “correctness.”
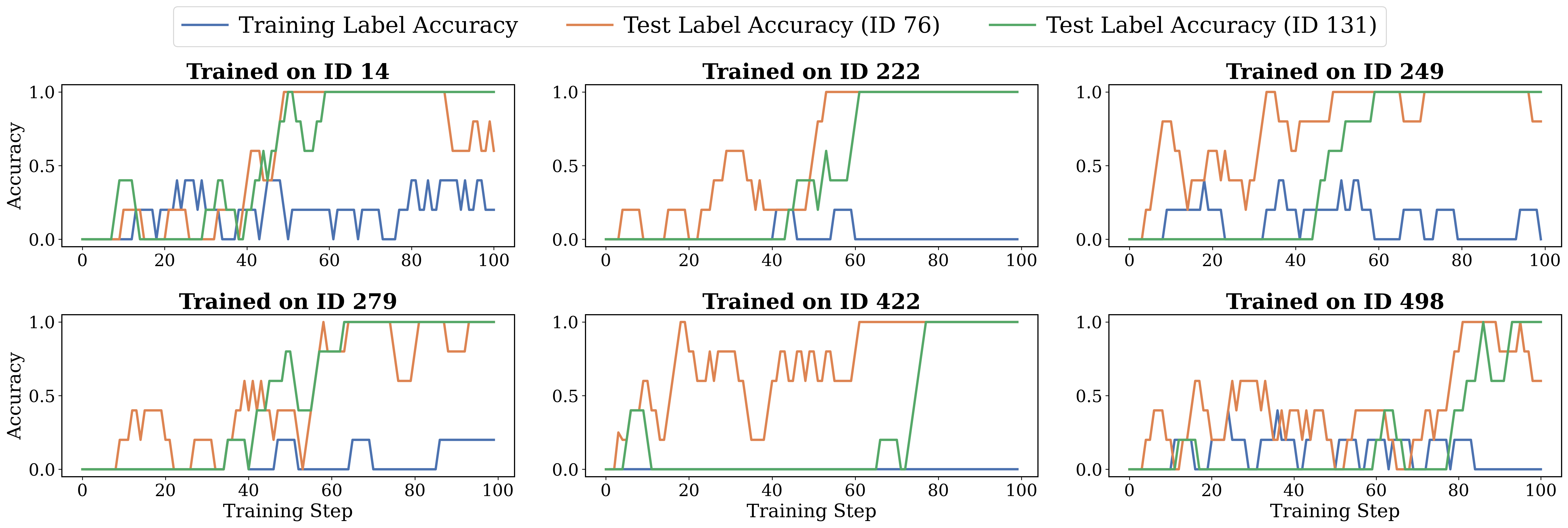
Small, focused training avoids collapse and is useful at test time
- Training on small, domain-specific sets can be safe: the model improves without collapsing.
- Even if training examples are wrong, sharpening can still help on new problems where confidence aligns better with correctness.
- This makes intrinsic rewards a good fit for “test-time training” on small batches, right when the model is being used.
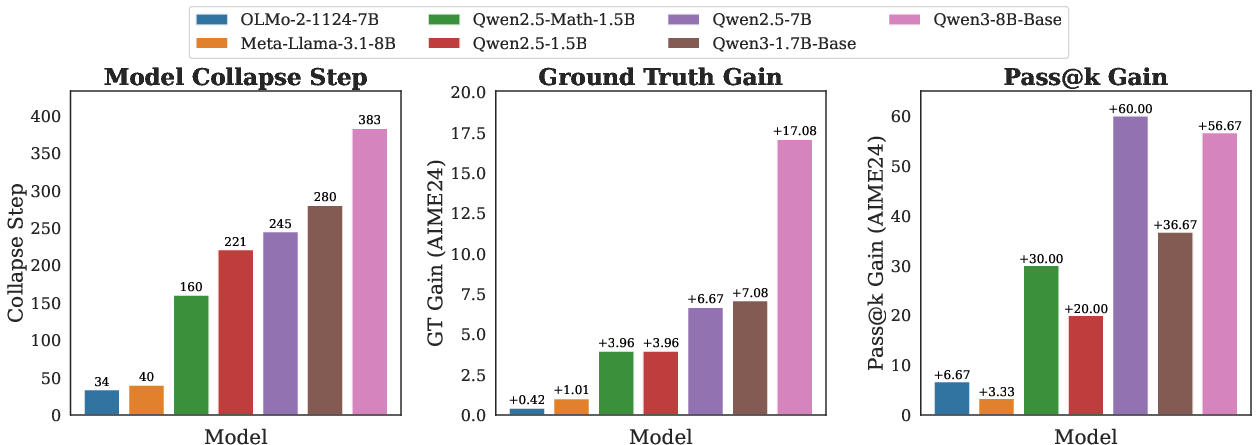
Model Collapse Step: a practical indicator
- By watching how fast training starts to go wrong, you can estimate the “Model Collapse Step.”
- This gives a quick way to judge whether intrinsic RL will train well for a given model and dataset, without running long, expensive training jobs.
External rewards can escape the confidence–correctness ceiling
- Because they rely on the data or a verifier, not on the model’s own confidence, external methods don’t hit the same limits.
- Using unlabeled data scales with the size of the corpus.
- Using generation–verification asymmetry gives stable, reliable rewards that don’t degrade as models get better. A compiler or proof checker doesn’t “get confused” when a model improves.
What this means going forward
- Intrinsic rewards have clear boundaries. They’re great for small, targeted improvements, especially at test time, but they tend to collapse when pushed too far because they only amplify what the model already believes.
- To scale LLM training in the long run, external rewards are more promising. Investing in automatic verifiers, leveraging huge unlabeled datasets, and building more domains with easy-to-check solutions can provide strong, stable rewards without human labels.
- The paper gives the field a roadmap: understand why intrinsic methods fail, use them safely where they shine, and focus future effort on external reward designs that can scale reliably.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that the paper surfaces, framed to guide concrete follow-up research.
- Formal conditions for “sharpening” convergence: The theory assumes majority stability and effective learning, but lacks finite-sample guarantees that link rollout count N, KL strength β, and sampling noise to collapse timing and convergence rates for practical RL updates.
- Generality of the sharpening analysis: The unified framework is asserted for many intrinsic rewards, but precise mappings, optimal policies, and convergence proofs for each listed method (e.g., probability disparity, self-consistency–weighted voting) are incomplete or not explicitly derived.
- Predicting collapse ex ante: “Model Collapse Step” is proposed as an indicator of model prior and RL trainability, but the paper does not operationalize how to estimate it cheaply, validate it across models/tasks/scales, or quantify its predictive power versus standard calibration metrics.
- Quantifying confidence–correctness alignment: No concrete, general-purpose metric is provided to measure alignment per problem/domain prior to training; the paper leaves open how to compute this alignment robustly and use it to gate or modulate intrinsic RL.
- RL algorithm dependence: Results focus primarily on REINFORCE-style updates with KL regularization; it remains unknown how DPO/GRPO/PPO-style algorithms, off-policy methods, or different reference-policy schedules affect sharpening, collapse timing, and stability.
- Model-size and capability scaling: Experiments center on a 1.7B model; it is unclear whether larger (or smaller) models sharpen differently, collapse later/earlier, or exhibit different failure modes as capability and calibration improve.
- Task and domain breadth: Most analyses target math-style problems with extractable answers; applicability to open-ended reasoning, tool use, multimodal tasks, and domains lacking clear extractors or verifiers is not established.
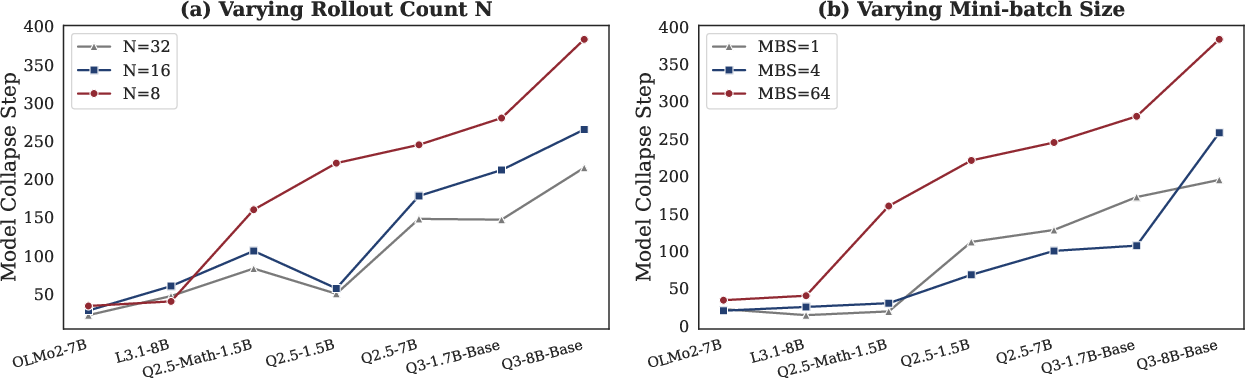
- Hyperparameter regimes and compute–performance tradeoffs: While some hyperparameters are tuned, systematic characterization of rollout count (N), batch size, temperature/top-p schedules, KL annealing, and optimizer settings versus stability and compute cost is incomplete.
- Mitigating failure modes: The paper diagnoses length-collapse (probability reward) and repetition-collapse (entropy rewards) but does not test concrete mitigations (e.g., length normalization, anti-repetition penalties, diversity regularizers, reward shaping, or adaptive entropy targets).
- Early-stopping and monitoring: Criteria to detect and halt intrinsic-RL collapse in practice are not specified; how to set robust, generalizable stopping rules based on reward accuracy, entropy trends, or proxy divergence remains open.
- Safe application boundaries: The “small, domain-specific datasets” claim lacks a principled threshold—what dataset sizes or entropy/prior conditions are safe, and how does safety depend on task complexity and model calibration?
- Cross-problem generalization: OOD generalization experiments are narrow (few problems); it is unclear when sharpening on wrong in-distribution items improves or harms OOD tasks across broader benchmarks and domains.
- Semi-/weak supervision hybrids: Whether small amounts of labeled data or occasional verifiable anchors can prevent collapse while preserving scalability is not investigated (e.g., mixing intrinsic and sparse ground-truth rewards).
- External rewards at scale: Evidence for external methods escaping the ceiling is preliminary; rigorous, head-to-head comparisons with intrinsic methods under matched compute, across multiple domains and verification mechanisms, are missing.
- Verification robustness and exploitability: For external methods, the paper does not analyze adversarial reward hacking (e.g., overfitting to incomplete test suites, exploiting numerical quirks, nondeterministic simulators) or propose robustness tests and defenses.
- Cost models for external verification: The compute/latency/throughput tradeoffs for verification (e.g., program execution, proof checking, simulation) versus reward quality are not quantified; scaling curves and bottlenecks remain unclear.
- Relationship to standard pretraining: For unlabeled-corpus-based external rewards (e.g., RPT/TPT/RLPT), the incremental benefit over next-token pretraining (and when RL credit assignment provides additional gains) is not disentangled.
- Proposer–solver ecosystems: Dynamics, stability, and bias in asymmetric proposer–solver/coaching systems (e.g., mode collapse in tasks, difficulty drift, curriculum quality) are not analyzed theoretically or empirically over long horizons.
- Safety and alignment risks: Beyond “reward hacking,” broader risks—catastrophic forgetting, degraded calibration, spurious certainty, and interaction with deployment-time safety—are acknowledged but not systematically measured or mitigated.
- Evaluation completeness: Heavy reliance on avg@32 and a few math benchmarks leaves open how conclusions change under single-sample evaluation, strict budgeted inference, varying CoT verbosity, and broader reasoning metrics (e.g., calibration, step correctness).
- Data and benchmark diversity: The study’s datasets are limited; reproducibility and robustness across multiple public corpora, varied difficulty distributions, and multilingual/multimodal settings are not established.
- Formalizing computational asymmetry: The paper motivates generation–verification asymmetries but lacks a formal taxonomy and metrics to quantify asymmetry strength and predict which tasks benefit most from external verification.
- Practical guidance for deployment: Concrete recipes (e.g., how to choose intrinsic vs. external rewards, when to switch, how to set N, β, and stopping rules) are not distilled into actionable protocols for practitioners.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the paper’s findings about intrinsic and external URLVR, the rise-then-fall behavior, and the proposed “Model Collapse Step” (MCS) indicator.
- Industry (Software): Test-time training (TTT) on small, domain-specific batches
- What: Use certainty-based (entropy minimization) or ensemble-based (majority vote) intrinsic rewards to adapt an LLM on 10–100 task instances at inference time.
- Tools/workflows: A lightweight TTT library that samples a few rollouts per prompt, performs majority-vote pseudo-labeling, and updates only LoRA/adapters; optional early-stopping on proxy-vs-checker divergence.
- Assumptions/dependencies: Tasks must be verifiable (extractable answers, unit tests, parsers); small batches localized to a domain; guardrails to prevent reward hacking; compute budget for extra rollouts.
- Industry (MLOps across sectors): Early-gain schedules and guardrails for intrinsic URLVR
- What: Exploit the documented rise-then-fall pattern by scheduling short intrinsic-RL phases that stop when proxy reward diverges from ground-truth checks or entropy plunges.
- Tools/workflows: Monitoring of Proxy Reward, Reward Accuracy on a tiny holdout with labels/tests, Actor Entropy, and Mean Response Length; automatic early-stop/rollback.
- Assumptions/dependencies: Availability of a small, verifiable holdout; robust logging; clear thresholds for divergence.
- Industry/Academia (ML platforms): Trainability screening with Model Collapse Step (MCS)
- What: Use MCS as a fast model-prior indicator to predict whether intrinsic URLVR will help or collapse before committing to full RL runs.
- Tools/workflows: An “MCS dashboard” that measures the step at which collapse signals emerge (e.g., reward–accuracy divergence) for a given model-task pair; budget gating and method selection.
- Assumptions/dependencies: Calibrated collapse criteria; reproducible sampling; standardized measurement protocol.
- Industry (Software, EdTech): Ensemble-based pseudo-labeling in verifiable tasks
- What: Majority voting across multiple generations to create proxy labels for math/code tasks lacking human labels; train briefly with KL-regularized RL.
- Tools/workflows: Answer extractors, canonicalizers, unit-test harnesses; batched rollout and aggregation.
- Assumptions/dependencies: Clear extraction rules or test suites; compute for small ensembles; awareness of consensus bias when model prior is weak.
- Industry (Software Engineering): External-verifier RL in CI for code generation/repair
- What: Use test execution as a reward signal for reinforcing code synthesis and patching in a sandboxed CI loop.
- Tools/workflows: Unit/functional test runners, containerized sandboxes, coverage analysis, patch generation loops.
- Assumptions/dependencies: Reliable test suites; security sandboxing; policies to gate auto-commit; avoid overfitting to tests.
- Academia (ML research): Reward design debugging and normalization
- What: Mitigate length and repetition collapse identified in certainty-based rewards by using length-normalized log-probability, top-2 margin penalties, and repetition deterrents.
- Tools/workflows: Reward wrappers that normalize sequence length, apply anti-repetition regularizers, and track mean response length.
- Assumptions/dependencies: Access to model logits; careful balancing with KL to reference policy.
- Academia/EdTech: Self-verifiable math and puzzle training loops
- What: Use numerical checkers or canonical solvers to provide external rewards for problem solving without human labels.
- Tools/workflows: CAS wrappers (e.g., SymPy), numeric verification scripts, puzzle evaluators.
- Assumptions/dependencies: Robust extractors; numerical stability; defenses against spurious formatting hacks.
- Industry/Content Ops: Dataset conversion pipelines to verifiable formats
- What: Convert open QA into multiple-choice or structured formats to enable automated checking and unsupervised RL.
- Tools/workflows: MCQ generators, distractor synthesis, answer canonicalization, quality filters.
- Assumptions/dependencies: Quality and bias control; evaluation against leakage/label noise; licensing compliance.
- Academia/Industry (Pretraining teams): Unlabeled-text reinforcement from next-token prediction
- What: Apply token/segment-level rewards (RPT/RLPT-style) to large unlabeled corpora to reinforce predictive skill with scalable signals.
- Tools/workflows: NTP-as-reward loops, information-gain signals from chain-of-thought, segment-level scoring.
- Assumptions/dependencies: Compute scale; data curation and licensing; risk of over-optimizing for surface-level predictability.
- Policy & Governance (All sectors): Deployment guardrails for self-improving systems
- What: Require verifiable held-out checks, MCS-based gating, and audit trails when enabling URLVR or TTT in production.
- Tools/workflows: Compliance checklists, logging of adaptation deltas, rollback mechanisms, change approval workflows.
- Assumptions/dependencies: Organizational buy-in; defined thresholds for disabling self-training; privacy constraints for on-device adaptation.
Long-Term Applications
The following opportunities require further research, scaling, or ecosystem development (e.g., robust verifiers, simulators, or broader task coverage).
- General AI (cross-industry): Scaling URLVR via external verification across domains
- What: Make external verifiers (compilers, proof checkers, numerical validators, simulators) the backbone of post-training to avoid confidence–correctness ceilings.
- Tools/products: “Asymmetry RL Kit” integrating test runners, theorem provers (Lean/Coq), CAS, scientific simulators; task-specific sandboxes.
- Assumptions/dependencies: Mature, domain-coverage verifiers; API and sandbox standardization; compute-efficient batching.
- Academia/Industry (AI research): Self-supervised RL over unlabeled corpora with structured objectives
- What: Move beyond NTP to dual-objective and meta-learning signals (e.g., DuPO, SEAL) that reward reconstruction fidelity, information gain, and downstream performance.
- Tools/workflows: Pipelines for automatic QA pair generation, evaluation harnesses for self-supervised objectives, scalable reward computation.
- Assumptions/dependencies: Reliable proxies that correlate with reasoning quality; large-scale compute; safeguards against reward hacking at scale.
- Software Engineering: Autonomous program synthesis and repair at scale
- What: Continuous RL loops where models generate patches/programs and receive dense rewards from expansive test suites and fuzzers.
- Tools/products: LLM–CI copilot with differential testing, fuzzing feedback, coverage-based rewards; approval gates for production merges.
- Assumptions/dependencies: Comprehensive tests; security isolation; controls against test overfitting and regression risks.
- Formal Sciences (Math/Theorem Proving): Proof-generation RL with proof checkers
- What: Train on auto-formalized corpora with proof checkers as ground-truth verifiers, enabling unsupervised reasoning improvements.
- Tools/workflows: Proof mining pipelines, formalization tools, replay buffers of verified proofs.
- Assumptions/dependencies: High-quality auto-formalization; scalable proof search; community acceptance of machine-generated proofs.
- Science & Engineering (Energy, Materials, Pharma): Simulator-verified optimization
- What: Use physics/chemistry/biomedical simulators as verifiers to reward candidate designs (e.g., catalysts, battery materials, protein ligands).
- Tools/products: RLVR orchestration over domain simulators (CFD, DFT, docking), surrogate models to reduce cost.
- Assumptions/dependencies: Simulator fidelity and calibration; domain-specific constraints and interpretability; compute expense.
- Robotics & Automation: Sim-to-real RLVR with cheap verification in simulation
- What: Train policies using simulator-based verifiers (goal attainment, safety constraints), then distill for real-world deployment.
- Tools/workflows: High-throughput simulators, safety verifiers, domain randomization and transfer learning pipelines.
- Assumptions/dependencies: Sim-real gap mitigation; safety assurance; task instrumentation for automatic checking.
- Finance/Operations Research: Verifier-backed decision pipelines
- What: Reinforce strategies against backtesting/constraint solvers as verifiers (portfolio constraints, routing feasibility).
- Tools/products: Optimization-verifier wrappers, scenario generators, risk-aware reward shaping.
- Assumptions/dependencies: Non-stationarity and overfitting risks; regulatory compliance; robust stress tests.
- Healthcare (High-stakes): Verifier-centered clinical assistants
- What: Use rule engines, ontologies, and validators (e.g., coding standards, order checks) as external verifiers to reinforce safe behaviors.
- Tools/products: Clinical decision sandboxes, coding verifiers, guideline conformance checkers, human-in-the-loop approval.
- Assumptions/dependencies: Strict governance and auditing; validated medical knowledge bases; liability and safety constraints.
- Education: Autonomous proposer–solver ecosystems for curriculum generation
- What: Co-evolving systems where a proposer generates tasks and a solver improves from verifiable rewards, building adaptive curricula and tutors.
- Tools/products: Task markets with difficulty targeting, paraphrasing for robustness, semantic clustering for soft voting.
- Assumptions/dependencies: Reliable difficulty estimation; prevention of mode collapse or “teaching to the test”; bias and content safety.
- Policy & Standards: Governance for verifiable reward pipelines
- What: Standards that require external verification for self-improving models, MCS thresholds for enabling/pausing self-training, and transparent audit trails.
- Tools/workflows: Certification frameworks for verifiers and sandboxes, sector-specific guidance (e.g., healthcare, finance), incident reporting.
- Assumptions/dependencies: Cross-industry consensus; evolving regulations (AI Act, sectoral laws); interoperability of verification tooling.
- Consumer/Daily Life: Safe, personalized on-device adaptation with ephemeral adapters
- What: Short-burst intrinsic TTT under guardrails for personal tasks (email sorting templates, spreadsheet macros) with local verifiers (unit tests, pattern checks).
- Tools/products: On-device micro-adapters with automatic rollback, privacy-preserving training, UI to show gains and allow user consent.
- Assumptions/dependencies: Verifiable tasks at the edge; compute/energy limits; strong privacy policies.
These applications hinge on core assumptions highlighted in the paper: intrinsic URLVR primarily sharpens model priors (thus safer on small, domain-specific sets and risky for large-scale training without external checks), while external reward methods that leverage unlabeled data and generation–verification asymmetries show promise for sustained scaling without collapse.
Glossary
- Actor Entropy: The average uncertainty of the policy’s token predictions during generation, often used to track confidence. "We also observe that training with majority voting reward drives down Actor Entropy faster than ground-truth training, establishing a connection between reduced uncertainty and improved performance."
- Asymmetric proposer-solver architectures: Systems where one model proposes tasks and another solves them, enabling co-evolution without labeled data. "Another line of works involves the use of asymmetric proposer-solver architectures~\citep{kirchner2024prover}, where one model generates tasks and another solves them."
- Baseline estimation: In policy gradient RL, an estimate (baseline) used to reduce variance in advantage calculation during training. "with 8 rollouts for baseline estimation."
- Chain-of-thought: An explicit intermediate reasoning process generated before an answer to improve performance or provide additional training signal. "and rewards the model based on the information gain that its chain-of-thought provides for the prediction."
- Computational asymmetries: Situations where verifying a solution is much cheaper or easier than generating it, enabling scalable external reward signals. "Finally, we explore external reward methods that ground verification in computational asymmetries, showing preliminary evidence they may escape the confidence-correctness ceiling."
- Cross-entropy: A measure comparing two probability distributions, often used as a training objective; here, a unifying lens for intrinsic rewards. "showing that all intrinsic rewards can be understood through a single lens: manipulating cross-entropy between carefully chosen distributions."
- Deterministic policy: A policy that places all probability mass on a single outcome. "the policy converges geometrically toward a deterministic policy concentrated on the initial majority answer:"
- Entropy minimization: A technique that encourages confident predictions by reducing output distribution entropy. "This principle was implemented through techniques like entropy minimization~\citep{grandvalet2004semi} and high-confidence pseudo-labeling~\citep{lee2013pseudo} in classification tasks."
- Entropy-based tree search: A search strategy that leverages entropy signals to guide exploration or pruning. "ETTRL~\citep{liu2025ettrl} improves efficiency through entropy-based tree search,"
- External reward methods: URLVR approaches that derive rewards from outside the model’s internal states, such as data structure or verifiers. "we categorize URLVR methods into two main types: intrinsic reward methods and external reward methods."
- Generation-verification asymmetries: The property that generating solutions is hard but verifying them is cheap, enabling scalable RL signals. "which generate verifiable rewards through generation-verification asymmetries rather than internal model states,"
- Geometric convergence: Convergence toward a target at a rate proportional to the current distance, often exponential in iterations. "the policy converges geometrically toward a deterministic policy concentrated on the initial majority answer:"
- High-confidence pseudo-labeling: Assigning labels to unlabeled data when the model is sufficiently confident, used to train without ground truth. "This principle was implemented through techniques like entropy minimization~\citep{grandvalet2004semi} and high-confidence pseudo-labeling~\citep{lee2013pseudo} in classification tasks."
- Intrinsic reward methods: URLVR approaches where rewards come from the model’s own outputs or internal confidence signals. "we categorize URLVR methods into two main types: intrinsic reward methods and external reward methods."
- KL divergence: A measure of how one probability distribution diverges from another, used here as a certainty/reward signal. "Self-Certainty, defined as the average KL divergence between a uniform distribution over the vocabulary and the model's next-token distribution,"
- KL regularization: A regularization term pushing the learned policy to stay close to a reference policy via KL divergence. "we thoroughly tune four key hyperparameters across five intrinsic reward methods, including training temperature, mini-batch size, KL regularization and rollout number"
- KL-regularized RL objective: An RL objective augmented with a KL term to constrain deviation from a reference policy. "Consider the standard KL-regularized RL objective:"
- Low-density separation principle: The idea that decision boundaries should lie in low data-density regions to improve generalization. "the low-density separation principle~\citep{chapelle2005semi} suggests that decision boundaries should avoid high-density regions."
- Majority voting: An ensemble method that selects the most frequent answer among multiple model rollouts as a proxy label. "which uses majority voting on the final answers from multiple rollouts to create a pseudo-label."
- Model Collapse Step: A proposed metric indicating when intrinsic-RL training collapses, used to estimate model prior/trainability. "and propose Model Collapse Step to measure model prior, serving as a practical indicator for RL trainability."
- Model collapse: A failure mode where the model’s performance degrades (e.g., overconfident but wrong, repetitive, or too brief outputs). "as several studies highlight critical failure modes including reward hacking and model collapse~\citep{shafayat2025can,agarwal2025unreasonable,zhang2025no}."
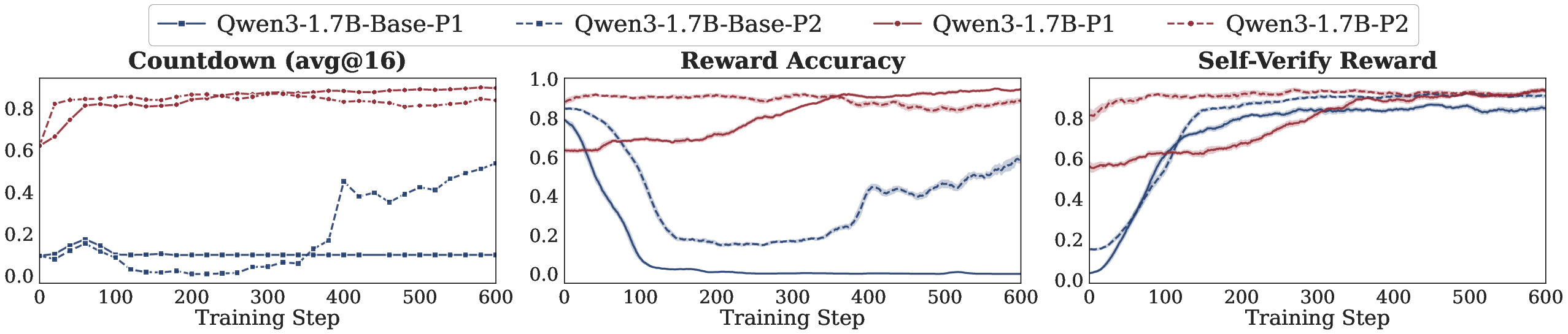
- Model prior: The model’s initial beliefs or confidence patterns before training, influencing whether sharpening helps or hurts. "This sharpening mechanism has both strengths and limitations, depending on the model prior: whether the model's initial confidence aligns with correctness."
- Partition function: The normalizing constant ensuring a probability distribution sums to one under an energy-based form. "where $Z(x) = \sum_y \pi_{\text{ref}(y|x)\exp\left(\frac{1}{\beta}r(x,y)\right)$ is the partition function."
- Policy gradient methods: RL algorithms that optimize policies by following gradients of expected rewards with respect to policy parameters. "a standard assumption in policy gradient methods"
- Probability Disparity: A certainty measure based on the gap between top token probabilities to capture distribution sharpness. "Besides, RLSF~\citep{van2025post} refines this by considering the Probability Disparity between top tokens,"
- Pseudo-label: A model-derived label used as a stand-in for ground truth in training. "which uses majority voting on the final answers from multiple rollouts to create a pseudo-label."
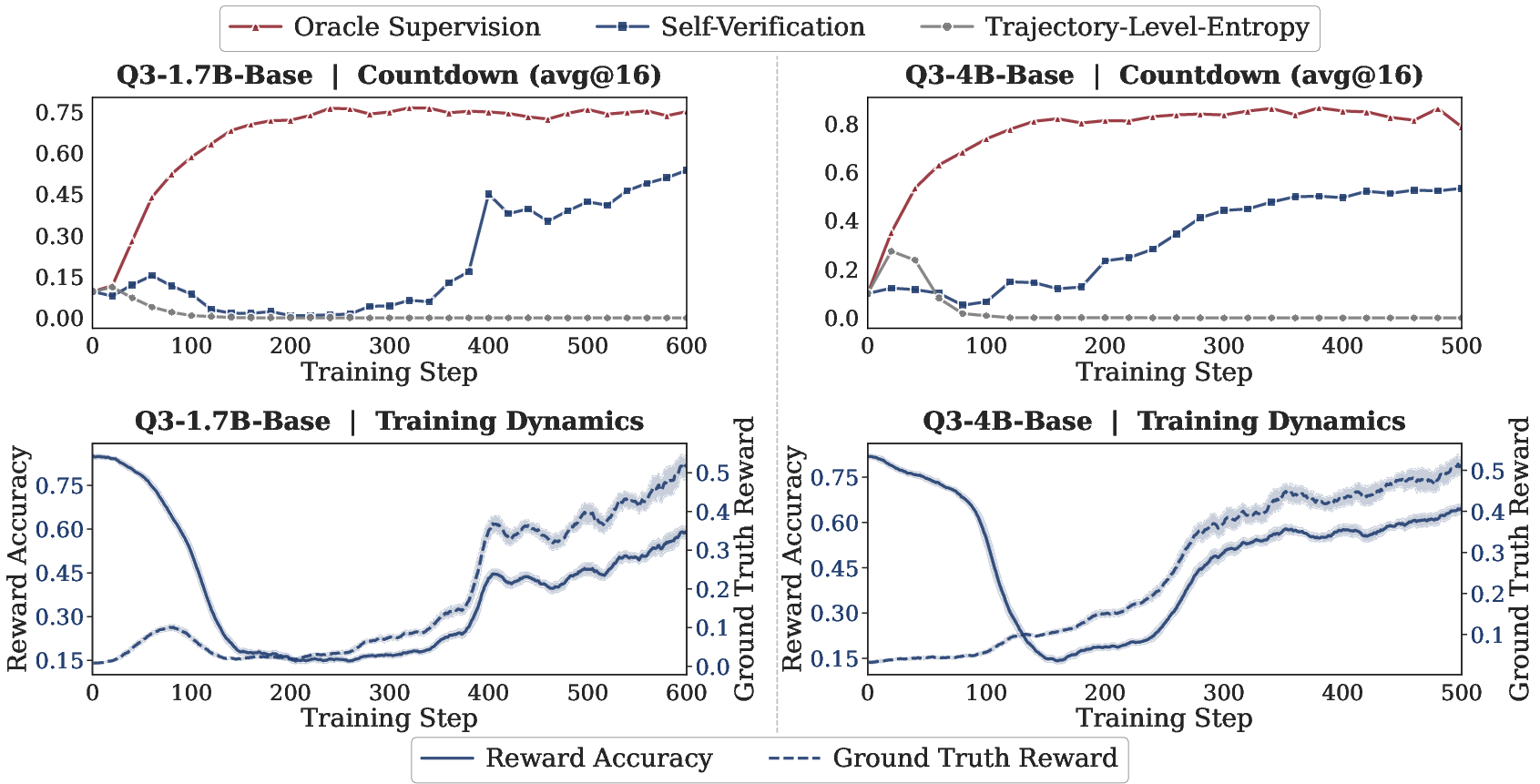
- REINFORCE: A classic policy gradient algorithm using sampled returns to estimate gradients of expected reward. "We train Qwen3-1.7B-Base on 25 randomly sampled individual problems from MATH500 using REINFORCE with Trajectory-Level Entropy as the intrinsic reward."
- Reference policy: The baseline policy used for regularization in KL-regularized RL. "where $\pi_{\text{ref}$ is the reference policy and controls the strength of regularization."
- Reward hacking: Optimizing the proxy reward in a way that degrades true task performance. "as several studies highlight critical failure modes including reward hacking and model collapse"
- Rise-then-fall pattern: A training dynamic where performance improves initially but later collapses under intrinsic rewards. "intrinsic rewards consistently follow a rise-then-fall pattern across methods,"
- Rollouts: Multiple sampled trajectories or outputs from a policy, often used for voting or estimating returns. "which uses majority voting on the final answers from multiple rollouts to create a pseudo-label."
- Self-certainty: An intrinsic reward measuring how peaked the model’s token distributions are (e.g., via KL to uniform). "RLIF~\citep{zhao2025learning} proposes Self-Certainty, defined as the average KL divergence between a uniform distribution over the vocabulary and the model's next-token distribution,"
- Self-consistency: An ensemble weighting scheme leveraging internal agreement to score answers. "RLCCF & \makecell[l]{Self-consistency \ Weighted Voting} &"
- Self-verification: A training setup where the model’s outputs are checked by an external procedure to yield rewards without labels. "we investigate the scalability of external URLVR methods, taking the self-verification as an example,"
- Semantic clustering: Grouping semantically similar outputs to implement soft voting or consensus. "EMPO~\citep{zhang2025right} using semantic clustering for soft majority voting"
- Sharpening mechanism: The intrinsic-RL dynamic that amplifies the model’s initial preferences, making distributions more peaked. "revealing that all intrinsic methods converge toward sharpening the model's initial distribution"
- Test-Time Adaptation (TTA): Adjusting a model at inference time using unsupervised objectives to improve robustness. "which aligns with the classic approaches in Test-Time Adaptation~(TTA)~\citep{wang2020tent},"
- Test-based verification: Using executable tests (e.g., unit tests) to verify outputs (like code) and provide reward signals. "using test-based verification as the sole reward signal,"
- Test-time training: Performing small-scale RL/adaptation on the test distribution to improve performance on-the-fly. "making it well-suited for test-time training"
- Token-Level Entropy: An intrinsic reward based on the per-step entropy of the model’s next-token distributions. "EM-RL~\citep{agarwal2025unreasonable} and RENT~\citep{prabhudesai2025maximizing} use negative Token-Level Entropy as a direct reward signal"
- Trajectory-Level Entropy: A sequence-level certainty measure equivalent to the log-probability of the entire generated sequence. "works including EM-RL~\citep{agarwal2025unreasonable} use the total Trajectory-Level Entropy (i.e., the sequence log-probability)"
- Unlabeled corpora: Large text datasets without annotations that can nonetheless yield verifiable reward signals. "Large-scale unlabeled corpora provide natural verification signals by converting language modeling into reward-based tasks."
- Unsupervised RLVR (URLVR): RL with verifiable rewards that does not rely on ground-truth labels. "Unsupervised RLVR (URLVR) offers a pathway to scale LLM training beyond the supervision bottleneck by deriving rewards without ground truth labels."
- Verifiable rewards: Rewards obtained by checking correctness against an objective criterion or procedure, not human judgment. "Reinforcement learning with verifiable rewards (RLVR) has been central to recent breakthroughs"
- Volatility: A measure related to variability in reasoning trajectories, used in consistency-based rewards. "CoVo & \makecell[l]{Trajectory Consistency\and Volatility} &"
- Weighted Voting: Ensemble scoring that weights votes (e.g., by internal consistency) instead of simple majority. "RLCCF & \makecell[l]{Self-consistency \ Weighted Voting} &"
Collections
Sign up for free to add this paper to one or more collections.