Lost in Backpropagation: The LM Head is a Gradient Bottleneck
Abstract: The last layer of neural LMs projects output features of dimension $D$ to logits in dimension $V$, the size of the vocabulary, where usually $D \ll V$. This mismatch is known to raise risks of limited expressivity in neural LMs, creating a so-called softmax bottleneck. We show the softmax bottleneck is not only an expressivity bottleneck but also an optimization bottleneck. Backpropagating $V$-dimensional gradients through a rank-$D$ linear layer induces unavoidable compression, which alters the training feedback provided to the vast majority of the parameters. We present a theoretical analysis of this phenomenon and measure empirically that 95-99% of the gradient norm is suppressed by the output layer, resulting in vastly suboptimal update directions. We conduct controlled pretraining experiments showing that the gradient bottleneck makes trivial patterns unlearnable, and drastically affects the training dynamics of LLMs. We argue that this inherent flaw contributes to training inefficiencies at scale independently of the model architecture, and raises the need for new LM head designs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at the very last part of a LLM—the “LM head,” which turns the model’s internal features into scores for each possible next token (word or piece of a word). The authors argue that this last step acts like a narrow funnel that squashes the training signal. Because of that, most of the useful information that should flow backward during learning gets lost. They call this a “gradient bottleneck.”
What questions did the researchers ask?
They focus on simple, practical questions:
- Is the common LM head (a single linear layer + softmax) not just a limit on what the model can represent, but also a limit on how well it can learn?
- How much of the training signal (the “gradient”) gets lost when it flows back through this LM head?
- Does this signal loss actually slow down training or make simple patterns hard to learn?
- Do common fixes that make the output more expressive also fix the learning problem?
How did they study it?
Think of a LLM as a big feature extractor that turns a context (previous words) into a feature vector of size D (the “hidden size”). The LM head then maps those D features to scores for V possible next tokens (the “vocabulary size”), and applies softmax to convert scores into probabilities.
- Everyday analogy: Imagine you have a huge to-do list with V items (one for each token), but only D slots to pass feedback through a mail slot. If D is much smaller than V (which it usually is), most of your feedback can’t fit through. That’s the bottleneck.
- “Gradient” in plain words: During training, the model gets a “correction signal” (the gradient) that says how to change its numbers to do better next time. This signal flows backward from the output to earlier layers (backpropagation).
- What they analyzed:
- Theory: They show that when the LM head maps from D features to V tokens (with D ≪ V), the backward signal is forced into at most D directions. But the ideal correction signal often needs many more than D directions. So, a lot of it gets discarded.
- Experiments: They measured how much gradient is lost in real models, and they trained large models while deliberately shrinking the LM head’s effective size to see how it affects learning speed. They also built a tiny “toy language” (SpamLang) where learning should be easy, to test if training still struggles when expressivity isn’t the problem.
What did they find?
Here are the key results and why they matter:
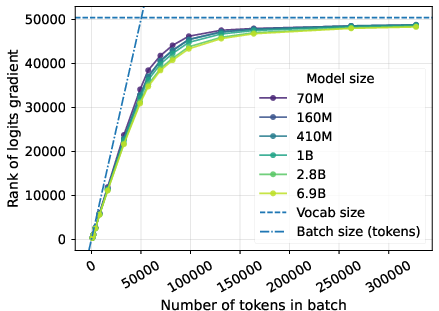
- Most of the training signal gets squashed.
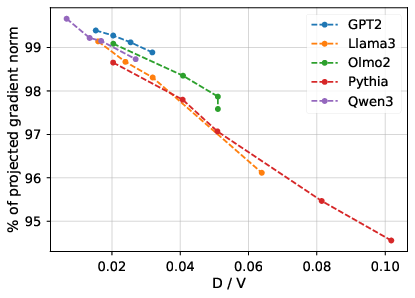
- They measured that about 95–99% of the gradient’s size is lost at the LM head in popular model families (GPT-2, Pythia, Llama 3, Qwen). In other words, only 1–5% of the information that should update earlier layers survives.
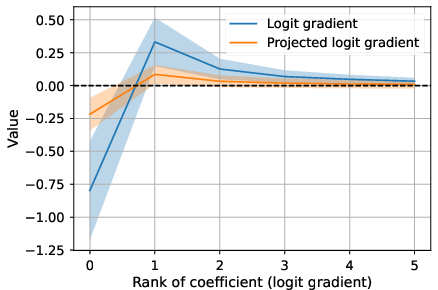
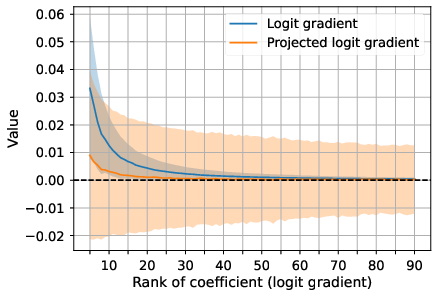
- The gradient that survives is misdirected and noisy.
- The useful parts of the signal (related to the most likely tokens) get weakened, and more of the “energy” shows up in less important parts, acting like noise. That makes updates less effective.
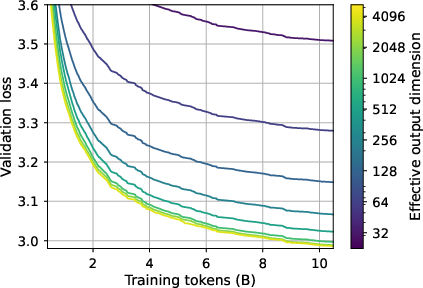
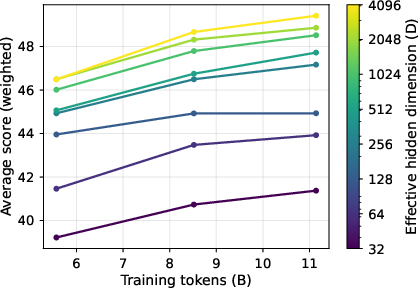
- Training becomes much slower when the bottleneck is tighter.
- With the same Transformer backbone (same “body”), but different LM head sizes, models with bigger D (wider funnel) learned much faster. In their 2B-parameter experiments, the largest LM head reached a target quality up to 16× sooner than the smallest head.
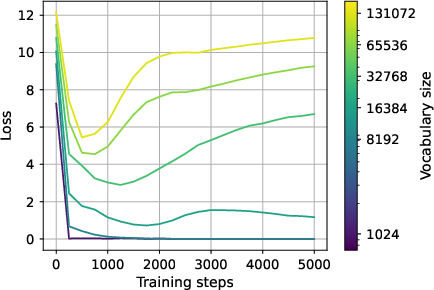
- Even trivial patterns can become hard to learn.
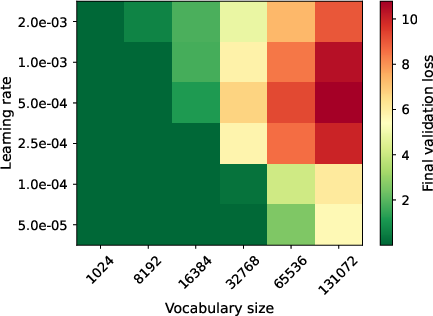
- In a toy language where each sequence is just the same symbol repeated, a Transformer should learn perfectly. But as the vocabulary V grows (more possible symbols) and D stays small, the model struggles to learn this simple rule. That shows the issue isn’t only about “expressivity” (what the model can represent), but about the learning signal getting crushed.
- Mini-batches don’t fix it, and “expressive” output layers aren’t enough.
- Using stochastic training (mini-batches) doesn’t make the bottleneck go away, especially as the model gets better. Also, previous ideas that make the output more expressive (to beat the classic “softmax bottleneck”) still send gradients through a D-wide path, so they don’t solve the gradient bottleneck problem.
Why does this matter?
- Practical impact on training efficiency: If most of the correction signal is thrown away at the output, we waste compute and data. That can mean slower training, higher cost, and sometimes failure to learn simple patterns when vocabularies are large.
- Rethinking LM heads: The paper suggests we need new designs for the output layer that preserve more of the backward signal. Possibilities include better conditioning, different mappings, or optimization tricks that avoid crushing the gradient.
- Better scaling laws and expectations: When people plan bigger models, they often focus on total parameters and data size. This work says we should also care about the hidden size D relative to the vocabulary size V, because it directly affects how well gradients flow.
Key terms in plain words
- Vocabulary size (V): How many different tokens the model can choose from next (like the size of the word list).
- Hidden size (D): How many features the model uses to summarize what it has read so far.
- LM head: The last layer that maps D features to V token scores, then softmax turns those scores into probabilities.
- Softmax: A function that turns scores into probabilities that add up to 1.
- Gradient/backpropagation: The “correction signal” that flows backward during training to adjust the model’s numbers.
- Bottleneck: A narrow passage that limits how much information can pass through (here, D is the narrow passage compared to V).
Bottom line
The paper shows that today’s standard LM head acts like a narrow funnel for training feedback. Because the model must map a small number of features (D) to a large number of possible tokens (V), most of the backward signal gets lost. This hurts learning speed and stability—even on simple tasks—and isn’t fixed by common “more expressive softmax” tricks. The authors argue it’s time to design new LM heads that keep more of the gradient intact, which could make training LLMs faster, cheaper, and better.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide follow-up research:
- Quantify assumption validity in practice: How often do the paper’s “unique continuation” and batch-connectivity conditions hold across languages, domains, sequence lengths, tokenizer choices, and training stages? Provide empirical estimates of and batch-wise analogs throughout training.
- Estimate the spectrum of the logit-gradient matrix at scale: Develop memory-efficient methods (e.g., randomized SVD/sketching/Hutchinson trace) to approximate singular values of for realistic batch sizes, enabling tighter, data-driven bounds on the unavoidable update residual.
- Dynamics over training: Measure how the fraction of lost gradient norm and the cosine alignment between projected and full logit gradients evolve from early to late training, and how this varies with learning rate schedules, temperatures, and model size.
- Per-token and frequency-stratified effects: Identify which token classes (e.g., frequent vs. rare, function vs. content, special tokens) contribute most to the lost gradient energy and whether the bottleneck disproportionately harms long-tail learning.
- Generality beyond autoregressive LM: Does the gradient bottleneck manifest similarly in masked LM, sequence-to-sequence tasks, classification with very large label sets, retrieval-augmented models, and non-text modalities with large output spaces (e.g., vision vocabularies, speech units)?
- Tokenizer and vocabulary design: Systematically decouple from tokenization by training on the same text with multiple tokenizers (BPE, unigram, byte-level) to assess causality between , D/V ratio, and gradient loss; identify tokenization strategies that mitigate compression.
- Batch composition and sampled objectives: Evaluate whether reducing in-batch vocabulary (e.g., sampled/approximate softmax, adaptive/hierarchical softmax, in-batch vocabulary capping) lowers the logit-gradient rank in practice and improves training efficiency without harming final performance.
- Optimizer and curvature effects: Test whether optimizers that better account for curvature (e.g., K-FAC/NGD, Shampoo, Sophia) or preconditioning at the output layer reduce the harmful impact of the bottleneck compared to AdamW.
- Second-order or quasi-Newton signal at the head: Analyze how the low-rank Jacobian interacts with the Hessian; determine whether curvature-aware updates can recover components of the ideal logit step that first-order backprop misses.
- Controlled “pseudo-logit” updates: Implement and evaluate updates that approximate the ideal logit step (e.g., via pseudoinverse of , feedback alignment, target propagation, or synthetic gradients) to test whether better alignment accelerates training.
- Alternative LM head designs for gradient flow: Propose and benchmark concrete architectures that prioritize Jacobian conditioning/gradient preservation (e.g., block-diagonal/parallel projections, whitening layers, preconditioned projections, multi-branch heads), not just log-probability expressivity.
- Clarify Jacobian rank for proposed softmax alternatives: Rigorously analyze the Jacobian rank and gradient-preservation properties of specific alternatives (e.g., Mixture-of-Softmax, Mixtape, adaptive/hierarchical softmax). The assertion that has rank ≤ D for all such requires verification or counterexamples per design.
- Scaling laws for the bottleneck: Derive and empirically validate predictive relationships linking D/V ratio to (i) fraction of gradient lost, (ii) convergence speed, and (iii) compute required for a target loss—across model sizes from small to frontier-scale.
- Interaction with weight tying: Provide a thorough study (beyond brief mention) of how tying vs. untying embeddings affects ’s null space, the fraction of lost gradient norm, convergence, and downstream performance.
- Robustness across data and languages: Test whether the 95–99% gradient loss generalizes across non-English corpora, code, math, scientific text, and high-entropy domains; identify datasets where the bottleneck is most harmful.
- SpamLang and other synthetic tasks: Extend beyond repetition-only languages to diverse synthetic setups that isolate different structures (multi-modality distributions, long-range dependencies, compositionality) and quantify when optimization—not expressivity—becomes the limiting factor.
- Direct causal tests: Introduce targeted interventions that explicitly reduce lost gradient (e.g., low-rank augmentation, gradient routing) and measure the causal impact on convergence and final performance under matched compute.
- Diminishing returns with larger D: Determine thresholds where increasing D yields minimal additional recovery of gradient information and quantify the trade-off with compute/memory; identify “sweet spots” for D/V in practice.
- Calibration and tail behavior: Connect observed transfer of gradient energy to the coefficient tail with measurable effects on calibration, likelihood assignment to rare tokens, and open-ended generation quality (e.g., hallucinations, diversity).
- Effect of training hyperparameters: Systematically ablate learning rate, warmup/cooldown schedules, gradient clipping, weight decay, and temperature scaling to probe their interactions with the gradient bottleneck.
- Batch size and accumulation: Empirically test whether larger or smaller effective batch sizes alter the in-batch gradient rank and the severity of compression, especially near convergence.
- Practicality and cost of fixes: Analyze the compute/memory overhead of candidate head designs or preconditioning strategies and quantify end-to-end wall-clock and energy savings versus baseline increases in D.
- Extensions to non-Transformer backbones: Assess whether state-space models (e.g., Mamba), RNNs, or hybrid architectures experience comparable gradient compression and whether head-level fixes transfer across backbones.
- Downstream and finetuning regimes: Evaluate how the bottleneck affects instruction tuning, RLHF/DPO, domain adaptation, and task-specific finetuning, where signal sparsity and label structure differ from pretraining.
- Reproducibility and release: The paper notes that code/data/checkpoints will be released; until then, independent replication of gradient-loss measurements and training-speed gaps remains an open need.
Practical Applications
Immediate Applications
Below are practical steps teams can take now to mitigate or leverage the paper’s findings. Each item notes target sectors and key dependencies.
- Increase effective LM-head rank relative to vocabulary size
- Sectors: software/AI platforms, cloud ML training, foundation model labs
- What: Avoid low-rank LM heads that reduce the head’s effective rank D. Where architecture allows, set the LM head to full rank (match the backbone hidden size) and avoid extra compression on the output projection.
- Why: The paper shows 95–99% of logit-gradient norm is lost when backpropagating through a rank-D head with D ≪ V, slowing convergence (up to ×16 in controlled 2B experiments).
- Dependencies/assumptions: Increases memory/compute; inference-time costs may rise. Benefits are larger when D/V is small; gains taper as D grows.
- Prefer smaller vocabularies (V) when possible, especially for small/medium backbones
- Sectors: healthcare, finance, code/enterprise NLP, on-device/edge AI
- What: Use compact tokenizers (e.g., 32k–50k vocabularies) and/or domain-specific vocabularies to reduce V without excessive fragmentation of text.
- Why: Lower V directly reduces the dimensionality of the logit gradient and the D/V mismatch.
- Tools/workflows: Tokenizer selection as a first-class hyperparameter; domain-adaptive tokenizers; offline evaluation of tokenization trade-offs (sequence length vs. V).
- Dependencies/assumptions: Smaller V can increase sequence length and training compute; requires empirical evaluation for each domain (e.g., clinical notes vs. code vs. legal).
- Add LM-head diagnostics to training dashboards
- Sectors: MLOps/DevOps for ML, foundation model labs
- What: Track D, V, D/V, and the fraction of logit-gradient norm lost by projection onto ker(Wᵀ) (as in the paper’s Eq. (lostgrad)). Also track cosine similarity between the full logit gradient and the backpropagated gradient.
- Why: Provides early warning that training feedback is being destroyed by the head, enabling timely architecture or tokenizer changes.
- Tools/workflows: Lightweight QR-based routines to estimate lost gradient fraction; periodic sampling on calibration batches to avoid overhead.
- Dependencies/assumptions: Extra logging and linear algebra cost; ensure privacy/security of logged statistics.
- Architecture and hyperparameter guidelines for new trainings
- Sectors: software/AI platforms, open-source model builders
- What: When budget-constrained, prioritize increasing D over adding more layers if the LM head is rank-limited; avoid post-backbone low-rank factorization of the head for memory savings; favor optimizers/schedules that are robust to noisy gradients at the tail of the logit coefficients.
- Why: Paper shows stronger bottlenecks hurt data efficiency even with identical backbones.
- Dependencies/assumptions: May trade off inference latency and memory; revisit design choices when moving from pretraining to deployment.
- Fine-tuning best practices that reduce head bottleneck sting
- Sectors: enterprise fine-tuning services, vertical AI (healthcare, finance, legal)
- What: For parameter-efficient fine-tuning, consider adding a higher-rank (or full-rank) LM head adaptation while keeping the backbone frozen (e.g., train an additional projection A,B so W=AB with larger D), instead of only training adapters inside the backbone.
- Why: In many PEFT setups the output head is unchanged; increasing head rank can improve how much signal reaches upstream layers during task adaptation.
- Dependencies/assumptions: Slight increase in parameters; careful regularization to avoid overfitting on small fine-tuning sets.
- Procurement, budgeting, and energy planning using D/V-aware cost models
- Sectors: industry R&D, cloud cost optimization, sustainability teams
- What: Incorporate D/V and expected gradient-loss metrics into training cost/energy calculators to predict convergence time more accurately.
- Why: The paper shows large, persistent convergence gaps attributable to LM-head rank; budgeting that ignores this risk underestimates training time/energy.
- Dependencies/assumptions: Requires historical training logs or small pilot runs to calibrate models.
- Reporting standards in model cards and evaluations
- Sectors: policy/compliance, responsible AI teams, open-source communities
- What: Report D, V, D/V, fraction of lost logit-gradient norm, and whether the LM head is low-rank or full-rank.
- Why: Enables fairer comparisons and better reproducibility; clarifies why some models are slower/faster to converge under similar compute budgets.
- Dependencies/assumptions: Requires minimal extra measurement; aligns with transparency goals.
- Domain tokenizer co-design and A/B testing
- Sectors: healthcare (EHR), finance (contracts/filings), code assistants
- What: A/B test different vocabularies balancing sequence length vs. V, using the lost-gradient metric as a key decision criterion alongside perplexity and downstream metrics.
- Why: Tightly couples tokenizer choice to optimization efficiency, not just modeling performance.
- Dependencies/assumptions: Must validate downstream task impact and latency trade-offs; may require re-tokenization of corpora for large-scale A/Bs.
- Safety/risk teams: integrate gradient-efficiency checks into red-teaming of training recipes
- Sectors: policy, trust-and-safety
- What: Check whether training recipes inadvertently induce extreme D/V regimes that slow convergence, increase costs, or cause brittle optimization on safety-critical datasets.
- Why: Bottleneck-induced undertraining can skew safety fine-tunes or delay convergence to safe behavior.
- Dependencies/assumptions: Requires cooperation between safety and infra teams; modest extra tooling.
Long-Term Applications
These require further research, scaling, or engineering. They are promising directions suggested by the paper’s theory and evidence.
- New LM-head designs that preserve gradient information
- Sectors: foundation model labs, academia (ML theory/architecture), ML framework vendors
- What: Architect heads with higher Jacobian rank or better conditioning so that backpropagated gradients retain more logit-space information (e.g., multi-branch heads, learned preconditioners at the head, gradient-preserving or invertible mappings).
- Why: The paper argues that expressivity-oriented alternatives don’t fix optimization; we need heads that improve gradient flow specifically.
- Dependencies/assumptions: Must ensure inference cost is acceptable and stability/regularization are well handled.
- Logit-space preconditioning and pseudo-inverse updates
- Sectors: ML optimization research, enterprise training platforms
- What: Approximate the optimal logit update by solving min_ΔH ||W ΔH − g_L||² (with g_L the logit gradient), e.g., via low-cost approximations to the pseudo-inverse W⁺. Use second-order or block-diagonal approximations (e.g., K-FAC/Shampoo variants) focused on the head.
- Why: Best-fit ΔH in least squares can better align updates with the true logit gradient despite rank limits.
- Dependencies/assumptions: Exact W⁺ is expensive for large V; needs sketching/low-rank approximations and careful engineering.
- Curriculum on vocabulary size (dynamic V)
- Sectors: foundation model labs, academic research
- What: Start pretraining with a smaller vocabulary (lower V) and expand gradually as the model matures; optionally co-increase head rank or introduce staged token merges.
- Why: Early phases are most sensitive to optimization bottlenecks; a curriculum can ease learning before increasing V.
- Dependencies/assumptions: Requires data re-tokenization or dynamic tokenization infrastructure and careful checkpoint migration; not widely supported in current tooling.
- Tokenizer–model co-design for gradient efficiency
- Sectors: code assistants, biomedical NLP, legal AI
- What: Optimize tokenizers jointly with head design and training objectives to keep D/V in a favorable range while controlling sequence inflation.
- Why: Co-design can deliver better Pareto fronts across convergence speed, accuracy, and latency.
- Dependencies/assumptions: Requires new automated search tools and joint evaluation pipelines.
- Alternative objectives to ease high-rank gradient pressure
- Sectors: academia, foundation model labs
- What: Explore losses that reduce harmful high-rank components or redistribute gradient energy more effectively (e.g., calibrated label smoothing, hierarchical or contrastive objectives, or hybrid ranking losses).
- Why: May reduce noise transfer to the coefficient tail described in the paper and improve batch-level update efficiency.
- Dependencies/assumptions: Must be validated for language modeling quality and alignment with downstream tasks.
- Hardware–algorithm co-design for head-centric optimization
- Sectors: semiconductor/accelerator vendors, hyperscalers
- What: Accelerate head operations (e.g., fast sketching for W⁺ approximations, efficient large-V Jacobian-vector products) to enable more sophisticated head-side optimization during training.
- Why: Makes gradient-preserving methods feasible at scale.
- Dependencies/assumptions: Requires close collaboration between hardware and framework teams.
- Extensions to non-NLP domains with very large output spaces
- Sectors: recommendation systems (millions of items), protein sequence modeling, large discrete planners/robotics
- What: Re-evaluate output layer designs where V is huge; replace or augment sampled softmax workflows with gradient-preserving heads to improve training efficiency.
- Why: Similar D ≪ V regimes exist beyond NLP; the same bottleneck likely harms optimization.
- Dependencies/assumptions: Domain-specific losses and sampling schemes may complicate direct translation; careful benchmarking needed.
- Policy and governance for efficient AI training
- Sectors: research funders, standards bodies, sustainability programs
- What: Encourage or require reporting of D, V, D/V, and gradient-loss metrics in funded projects; incorporate gradient-efficiency as a factor in energy/compute grants and reproducibility checklists.
- Why: Aligns incentives toward more efficient, environmentally responsible training.
- Dependencies/assumptions: Community consensus on metrics; minimal extra burden for submitters.
- Energy and cost accounting frameworks that include gradient efficiency
- Sectors: sustainability, ESG reporting, cloud providers
- What: Add gradient-efficiency factors to lifecycle analyses of model training to better estimate energy/cost per performance point.
- Why: The paper links poor gradient flow to large convergence slowdowns; accounting frameworks should reflect this hidden inefficiency.
- Dependencies/assumptions: Needs validated empirical models to translate D/V and gradient-loss into cost/energy estimates across diverse settings.
Key assumptions and dependencies across applications
- The detrimental effect is strongest when D ≪ V and persists even with SGD, particularly near convergence.
- Many natural-language contexts display unique next-token observations, making logit gradients intrinsically high-rank in practice.
- Reducing V trades off against sequence length (and hence compute); increasing D trades off against memory/latency.
- Improvements targeting expressivity alone (e.g., higher-rank log-probabilities) do not necessarily fix the gradient-flow bottleneck; the Jacobian rank into hidden space remains ≤ D without additional mechanisms.
- Empirical gains (e.g., ×16 faster convergence) were shown in controlled 2B-scale setups; real-world magnitudes will vary with architecture, optimizer, data quality, compute budget, and engineering constraints.
Glossary
- Adjacency matrix: A binary matrix indicating which vertices in a graph are adjacent (connected by an edge). "adjacency matrix of a connected graph."
- Argmax: The argument (input) at which a function attains its maximum value. "\argmax(\tilde{N}_i)"
- Autoregressive: A modeling setup where each output token is predicted conditioned on previous tokens in sequence. "most autoregressive LMs"
- Backpropagation: The algorithmic process of propagating gradients from outputs back through network layers to update parameters. "Backpropagating -dimensional gradients through a rank- linear layer induces unavoidable compression"
- Connected graph: A graph in which there is a path between every pair of vertices. "adjacency matrix of a connected graph."
- Eckart--Young--Mirsky theorem: A result stating that the best low-rank approximation of a matrix (in unitarily invariant norms) is given by truncating its singular value decomposition. "This is a direct application of the Eckart--Young--Mirsky theorem."
- Expressivity bottleneck: A limitation where a model cannot represent certain target distributions due to architectural constraints. "not only an expressivity bottleneck but also an optimization bottleneck."
- Gradient bottleneck: A restriction that compresses or discards gradient information during backpropagation, impeding optimization. "In that sense, the LM head is a gradient bottleneck."
- Greedy decoding: A decoding strategy that selects the highest-probability token at each step without lookahead. "for greedy decoding."
- Jacobian: The matrix of all first-order partial derivatives of a vector-valued function, describing local linearization. "where the Jacobian is rank at most."
- Logit gradient: The gradient of the loss with respect to the pre-softmax activations (logits). "the first-order optimal update direction in the limit would be given by the logit gradient"
- Logit space: The vector space of pre-softmax activations for class scores. "the loss gradients in the high-dimensional logit space"
- Log-likelihood: The logarithm of the likelihood function, commonly maximized in statistical learning. "We rewrite the conventional log-likelihood loss in matrix notation"
- Low-rank: A matrix or mapping with rank much smaller than its dimensions, implying reduced degrees of freedom. "Low-rank LM heads hamper optimization dynamics"
- Maximum likelihood: An estimation principle that chooses parameters maximizing the probability of observed data. "The standard maximum likelihood objective for a LLM"
- Mini-batch: A subset of training samples used to compute stochastic gradient estimates. "even mini-batch gradients are high-rank"
- Null space: The set of vectors mapped to zero by a linear transformation. "the null space of "
- Pre-conditioning: Transformations applied to improve optimization (e.g., scaling or rotating gradients). "pre-conditioning or regularization."
- Pretraining: Large-scale initial training on broad data before task-specific fine-tuning. "pretraining setups"
- QR decomposition: A matrix factorization into an orthonormal matrix Q and an upper triangular matrix R. "their decomposition."
- Rank constraint: A restriction limiting a matrix to have at most a certain rank. "rank constraints on ."
- Representation degeneration: A collapse of learned representations into a narrow subspace, reducing diversity. "representation degeneration"
- Row-normalized: A matrix normalized so each row sums to one (often to represent distributions). "row-normalized version of ."
- Row space: The subspace spanned by the rows of a matrix. "the row space is spanned"
- Scaling laws: Empirical relations describing how performance scales with model/data/compute. "scaling laws"
- Singular value decomposition (SVD): A factorization of a matrix into singular vectors and singular values. "computing the SVD of the gradients"
- Singular values: The non-negative values in the SVD indicating the strength of orthogonal components. "the singular values of "
- Softmax bottleneck: The limitation arising from mapping a low-dimensional hidden state to a high-dimensional vocabulary via softmax. "softmax bottleneck"
- Softmax denominator: The normalizing term in the softmax function’s denominator ensuring probabilities sum to one. "the of the softmax denominator"
- Spectral saturation: A regime where the spectrum (eigen/singular values) reaches limiting behavior that hampers learning. "spectral saturation"
- Stochastic gradient descent (SGD): An optimization method updating parameters using gradients from random data subsets. "stochastic gradient descent (SGD) mitigates this issue"
- Tokenizer: A component that converts text into discrete tokens from a fixed vocabulary. "SmolLM2 tokenizer"
- Weight tying: Sharing parameters between embedding and output (softmax) layers to reduce parameters and improve consistency. "embedding weight tying"
- Zero-shot: Evaluating or performing tasks without task-specific fine-tuning. "We perform zero-shot downstream evaluation"
Collections
Sign up for free to add this paper to one or more collections.