Just-in-Time: Training-Free Spatial Acceleration for Diffusion Transformers
Abstract: Diffusion Transformers have established a new state-of-the-art in image synthesis, but the high computational cost of iterative sampling severely hampers their practical deployment. While existing acceleration methods often focus on the temporal domain, they overlook the substantial spatial redundancy inherent in the generative process, where global structures emerge long before fine-grained details are formed. The uniform computational treatment of all spatial regions represents a critical inefficiency. In this paper, we introduce Just-in-Time (JiT), a novel training-free framework that addresses this challenge by acceleration in the spatial domain. JiT formulates a spatially approximated generative ordinary differential equation (ODE) that drives the full latent state evolution based on computations from a dynamically selected, sparse subset of anchor tokens. To ensure seamless transitions as new tokens are incorporated to expand the dimensions of the latent state, we propose a deterministic micro-flow, a simple and effective finite-time ODE that maintains both structural coherence and statistical correctness. Extensive experiments on the state-of-the-art FLUX.1-dev model demonstrate that JiT achieves up to a 7x speedup with nearly lossless performance, significantly outperforming existing acceleration methods and establishing a new and superior trade-off between inference speed and generation fidelity.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is about making text-to-image AI models faster without hurting image quality. The authors focus on a popular kind of model called a Diffusion Transformer (DiT), which creates pictures step by step from random noise. These models make great images but are slow, especially for big, detailed pictures. The paper introduces a new, “training-free” method called Just‑in‑Time (JiT) that speeds things up by being smart about where and when to spend computing power inside the image.
Key questions the paper asks
- Can we make image generation much faster without retraining the model and without losing quality?
- Since images form from rough shapes to fine details, can we compute less in areas that don’t matter yet, and focus more on important regions as the picture develops?
How the method works (in everyday terms)
Think of drawing a picture. You usually sketch the big shapes first and only later shade fine details like textures and tiny patterns. Current models treat every part of the image the same at every step—which wastes time. JiT changes that by doing “just enough, just in time.”
Here are the main ideas:
- Spatial focus using “anchor tokens”
- The model represents an image as many small patches (called tokens), like a puzzle made of tiny pieces.
- JiT only fully computes on a small, carefully chosen subset of those pieces called anchor tokens (like checking a few key puzzle pieces to see the big picture).
- For the rest of the pieces, it estimates (smoothly fills in) what they should do based on the anchors. This avoids computing everything everywhere at once.
- A gentle handoff when adding more detail (Deterministic Micro-Flow)
- As the image gets clearer, JiT adds more tokens into the “fully computed” set.
- Instead of snapping new tokens in abruptly (which can cause visual glitches), JiT uses a tiny, smooth transition so new areas blend in correctly with the right amount of noise and structure—like softly fading in new parts of a painting.
- Choosing where to focus (Importance-Guided Token Activation)
- JiT measures which parts of the image are “most active”—for example, where edges and textures are forming—and activates those areas first.
- This is like spending more time shading the busy, detailed areas and less time on empty backgrounds until later.
Under the hood, the paper describes this process as a simple, step-by-step rule (an ODE, or ordinary differential equation) that transforms noise into an image. JiT modifies this rule so it:
- Computes the “velocity” (the direction each token should move to become a better image) only on anchor tokens.
- “Lifts” that information to the whole image by interpolation, so inactive tokens still evolve sensibly.
- Smoothly adds new tokens with the deterministic micro‑flow to avoid artifacts.
The key point: JiT doesn’t need extra training. It changes how we sample (generate) images, not the model itself.
Main findings and why they matter
- Much faster generation: JiT speeds up image generation by about 4× to 7×.
- Almost no quality loss: Even at 7× speedup, images remain sharp, consistent, and faithful to the text prompt.
- Better than other speed-up tricks: Methods that mainly cut the number of steps or cache old features often lose quality at high speedups. Spatial methods that resize and upsample can introduce blur or artifacts. JiT avoids both problems by working directly on tokens and handling transitions smoothly.
- People prefer the results: In user studies, people picked JiT’s images more often than those from competing fast methods.
Why this matters: Faster image generation means better real-time tools, more responsive apps on regular devices, and lower costs for big services—all without sacrificing quality.
What this could lead to
- Real-time creativity: Faster, high-quality image (and possibly video) generation makes interactive art and design tools more practical.
- Works on current models: Because JiT is training-free, you can bolt it onto existing diffusion transformers like FLUX.1-dev.
- Smarter computing: The broader idea—spend compute where it matters, when it matters—could apply to other AI tasks, like video generation, editing, or even non-visual tasks that naturally go from coarse to fine.
In simple terms: JiT lets AI “draw like an artist”—rough shapes first, details later—so it works faster without messing up the final picture.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
- Lack of formal error bounds: No quantitative analysis of global/local approximation error introduced by SAG-ODE relative to the full ODE, nor convergence guarantees to the same terminal distribution as the baseline sampler.
- Statistical correctness of DMF: The deterministic micro-flow is claimed to maintain “statistical correctness,” but the paper does not provide proofs or diagnostics (e.g., marginal/conditional KL, trajectory consistency) verifying that the induced distribution matches the intended flow.
- Sensitivity to solver choice and step size: How SAG-ODE/DMF interact with different ODE solvers (Euler, Heun, DPM-Solver variants) and coarse step schedules remains unexplored; stability and accuracy may vary.
- Interpolation operator design: The specific choices for the interpolation operator and the structural prior operator are not compared against alternatives (e.g., edge-aware, anisotropic, learned, graph-based, or attention-weighted interpolation) nor is their effect on fidelity quantified.
- Adaptive schedule design: The paper uses a fixed stage schedule {}, but provides no method to automatically choose stage times and token counts under a compute budget or target quality.
- Importance metric alternatives: ITA uses local velocity variance; there is no comparison to other activity measures (e.g., gradient/Jacobian norms, curvature, attention weights, predictive uncertainty, or divergence of the velocity field) and their impact on quality/speed trade-offs.
- Overhead of importance computation: The cost of computing the importance map and ranking tokens is not profiled relative to the FLOPs saved; regimes where overhead diminishes gains are not identified.
- Robustness of ITA: Failure cases where dynamic selection misallocates computation (e.g., thin structures, small text, high-frequency textures distributed across the scene) are not analyzed or mitigated.
- Schedule mis-specification: Sensitivity analyses for , patch sizes, and the number of stages are not reported; guidelines for safe hyperparameter ranges are missing.
- Effect on sample diversity: The impact of spatial approximation on diversity and coverage (e.g., FID/KID, precision/recall, intra-class diversity, multi-seed variability) is not measured.
- Guidance interactions: Compatibility with classifier-free guidance scales, negative prompts, and other conditioning (e.g., style, long/complex prompts) is not evaluated; trade-offs may differ with strong guidance.
- Compositionality and spatial relations: While T2I-CompBench/GenEval are reported, deeper stress tests on spatial relations (e.g., counting, relative positioning, multiple objects) under high acceleration are absent.
- Applicability beyond FLUX.1-dev: Generalization to other backbones (UNet-based diffusion, different DiT variants), non-flow-matching samplers (DDPM/DDIM/SDE), or different latent spaces is not validated.
- Scaling to higher resolutions/aspect ratios: Behavior at 2K–4K resolutions, extreme aspect ratios, and non-uniform patch grids is unknown; interpolation and token selection may degrade.
- Video and long sequences: Extension to video DiTs (spatiotemporal tokens) is not tested; it is unclear how to allocate tokens across space-time and maintain temporal coherence during stage transitions.
- Conditioning-rich tasks: Compatibility with ControlNet-like controls, inpainting/outpainting/masking, image-to-image, or multi-modal inputs is unaddressed; anchor selection may need to respect masks/controls.
- Attention dynamics under subspace evolution: How restricting to anchor tokens affects attention patterns (e.g., long-range dependencies, cross-attention to text) and whether it biases semantics is not studied.
- DMF hyperparameters: The role of the micro-flow duration , choice of hitting ODE, potential stochastic variants, and their effects on artifacts and bias are not characterized.
- Numerical discontinuities at transitions: Although DMF aims for smoothness, the practical continuity of velocity and higher-order derivatives across stage boundaries is not analyzed; artifacts may emerge with high-order solvers.
- Integration with temporal accelerators: Interactions and composability with few-step distillation, adaptive time-step schedulers, and solver optimizations are not benchmarked for compound speedups and failure modes.
- Interaction with quantization/caching: Whether JiT remains effective under low-bit quantization or heavy feature caching and whether these methods interfere with importance estimates is unclear.
- Memory and hardware portability: Results are reported on a single A800 setup; performance, memory footprint, and speedups across GPUs/TPUs/consumer-grade devices and batch sizes are not provided.
- Worst-case behavior: The paper highlights averages and preferences; it does not report worst-case degradations (e.g., fraction of prompts with noticeable artifacts) or calibration under hard prompts (text, signage, micro-details).
- Energy and cost metrics: Throughput, energy per image, and cost per image are not reported; these are important for deployment evaluations.
- Reproducibility of ITA/DMF: Precise hyperparameters (window sizes, ranking tie-breaking, interpolation kernels), code for /, and ablation protocols are not fully specified in the main text.
- Theoretical connection to subspace diffusion: The relationship between JiT’s token-subspace evolution and prior subspace diffusion theory is not formalized; criteria for choosing anchor tokens to approximate principal subspaces are missing.
- Learned lifter/interpolator: Potential benefits of lightly trained or meta-learned interpolators/lifters (vs. hand-crafted) are not explored; small finetuning might further reduce approximation error.
- Safety and bias: Whether spatially selective computation exacerbates or mitigates biases, safety failures, or prompt hijacking (e.g., over-focusing on salient but inappropriate regions) is not examined.
- Diagnostics and interpretability: Tools to visualize and audit evolving active token sets, importance maps, and lifted velocities across steps are not provided; they could help detect and correct failure modes.
Practical Applications
Immediate Applications
These applications can be deployed now with modest engineering effort, leveraging JiT’s training-free spatial acceleration for Diffusion Transformers (DiTs) and its demonstrated 4–7× speedups on FLUX.1-dev with near-lossless quality.
- Accelerated image generation in creative/marketing pipelines
- Sectors: Media/entertainment, advertising, e‑commerce, gaming
- Tools/workflows: Add a “JiT mode” to inference stacks (HuggingFace Diffusers, ComfyUI/Automatic1111 extensions); expose a knob for “anchor-token budget” (m_k schedule) and acceleration tiers (≈4×, ≈7×); integrate importance-guided token activation (ITA) to prioritize salient regions (logos, faces, product textures)
- Assumptions/dependencies: DiT-based, flow-matching models with VAE latents; access to token-level velocity predictions; coarse-to-fine generation holds for the domain
- Lower-cloud-cost, higher-throughput T2I serving
- Sectors: AI model hosting, SaaS design platforms
- Tools/workflows: Deploy JiT as a drop-in wrapper around DiT forward passes; add SLA-aware switching between vanilla and JiT paths; report reductions in FLOPs/latency and $/image
- Assumptions/dependencies: Benchmarked gains translate to target GPUs; importance-map and interpolation overheads are negligible vs. attention savings
- Real-time and interactive UIs (progressive previews)
- Sectors: Design tools, photo editing, prompt engineering assistants
- Tools/workflows: “Draft-to-final” preview—start with sparse anchor tokens for fast previews, expand anchors as the user confirms; display intermediate frames using DMF to avoid artifacts during token activation
- Assumptions/dependencies: Stable user experience requires tuned transition times (T_k) and micro-flow duration; UI must support progressive refresh
- On-device/mobile image generation
- Sectors: Consumer apps, AR/VR, social media
- Tools/workflows: Port JiT operators (selector/lifter, interpolation, variance maps) to mobile accelerators (Core ML, NNAPI, TensorRT‑Mobile); enable faster stickers/filters/backgrounds on-device
- Assumptions/dependencies: Memory constraints and custom kernel support; DiT models quantized/pruned for edge devices; quality validated on device cameras/content
- Faster synthetic data generation for CV/ML
- Sectors: Robotics, autonomous systems, retail (virtual try-on), industrial vision
- Tools/workflows: Use JiT to accelerate large-scale dataset creation (domain randomization, style variants) while maintaining fidelity; prioritize high-variance regions (e.g., edges, text, textures) via ITA for label-critical details
- Assumptions/dependencies: Generated distributions remain suitable for downstream training; validate task-specific metrics (mAP, IoU)
- Energy and carbon footprint reduction
- Sectors: Data centers, sustainability programs, public sector IT
- Tools/workflows: Integrate JiT into Green-AI dashboards; report kWh and CO₂e per 1k images; use speed tiers to meet energy budgets
- Assumptions/dependencies: Energy savings correlate with FLOPs/latency reductions on deployed hardware
- MLOps integration for dynamic resource allocation
- Sectors: Cloud platforms, enterprise IT
- Tools/workflows: Add policy hooks that select JiT tiers by user class or budget; autoscaling rules and canary A/B tests comparing fidelity metrics (CLIP-IQA, HPSv2/GenEval) before rollout
- Assumptions/dependencies: Monitoring pipelines for quality regression; per-prompt fallbacks for outlier cases
- Research baselines and ablations for spatial acceleration
- Sectors: Academia, corporate research
- Tools/workflows: Use JiT as a training-free baseline for spatial acceleration in papers; inspect token-variance maps as a diagnostic for coarse-to-fine behavior; test on other DiTs
- Assumptions/dependencies: Availability of code-level access to token sequences and DiT velocity field
Long-Term Applications
These opportunities require further research, adaptation to new modalities/architectures, or engineering for production-grade reliability.
- Video generation with spatiotemporal JiT
- Sectors: Film, advertising, gaming, telepresence
- Tools/products: Extend ITA to space-time (3D windows), token activation across frames; temporally consistent DMF for artifact-free token activation; “real-time” or near-real-time preview for storyboarding
- Assumptions/dependencies: Temporal consistency constraints; new interpolation/lifter for time dimension; evaluation on long-duration videos
- 3D/4D content generation (NeRFs, Gaussian splats)
- Sectors: VFX, CAD/CAE, AR/VR, digital twins
- Tools/products: Anchor “voxel/point” tokens and spatial lifters in 3D; DMF for activating new regions of a scene progressively
- Assumptions/dependencies: Tokenization of 3D fields and suitable interpolation operators; verification of fidelity for geometry and materials
- Generalization beyond flow-matching DiTs
- Sectors: Broad AI model ecosystems
- Tools/products: Adapters for U‑Net‑based diffusion (score/SDE samplers), hybrid DiT–U‑Net models; “JiT‑compatibility layer” to derive per-token velocities
- Assumptions/dependencies: Access to equivalent velocity/score signals; alignment with non-ODE samplers
- Hardware-accelerated kernels and compilers
- Sectors: Semiconductors, AI systems software
- Tools/products: TensorRT/TVM ops for selector matrices, lifter/interpolation, and fast local variance; attention-aware sparsity planners integrated with memory schedulers
- Assumptions/dependencies: Vendor support and kernel fusion; performance portability across GPU/TPU/ASIC targets
- Budgeted quality–latency controllers (API-level)
- Sectors: Model APIs, marketplaces
- Tools/products: “Quality tiers” that tune anchor-token schedules (m_k) and transition times (T_k) to hit latency or cost targets; online quality predictors guiding dynamic token budgets
- Assumptions/dependencies: Robust, prompt-agnostic quality predictors; guardrails for worst-case prompts (fine text, microtextures)
- Hybridization with quantization, KV-caching, and distillation
- Sectors: Inference platforms, edge AI
- Tools/products: Stacked acceleration (JiT + 4–8‑bit quantization + KV/feature caching) for multiplicative gains; compatibility testing suites
- Assumptions/dependencies: Interaction effects (e.g., interpolation noise with low-bit errors); retraining-free behavior maintained
- Safety and content moderation in-the-loop
- Sectors: Platforms, regulators
- Tools/products: Early-stage safety filters operating on sparse anchor tokens to preempt unsafe generations; progressive gating that halts refinement upon violation
- Assumptions/dependencies: Reliable early-stage classifiers; low false-positive rates to avoid stalling benign generations
- Edge AR/robotics visual experiences
- Sectors: Wearables, human–robot interaction
- Tools/products: On-device background synthesis, textures, or overlays with ms-level response; ITA focusing compute on ROI (hands, objects) for interactive latency
- Assumptions/dependencies: Tight energy budgets and thermal limits; robust real-time scheduling
- Domain-adapted healthcare/biomed generation (non-diagnostic)
- Sectors: Healthcare IT, pharma R&D
- Tools/products: Faster privacy-preserving synthetic images for augmentation/anonymization; controlled “region-of-interest first” generation in microscopy or histology
- Assumptions/dependencies: Strict validation for bias/data leakage; regulatory compliance; non-diagnostic use unless clinically validated
- Enterprise content automation
- Sectors: Finance, retail, HR/ops
- Tools/products: Faster creation of compliant marketing assets, report illustrations, and internal visuals; integration with DAM/CPQ systems using JiT tiers
- Assumptions/dependencies: Brand/identity fidelity for small text/logos; governance workflows for content approval
- Standards and policy for efficient generative AI
- Sectors: Standards bodies, public sector procurement
- Tools/products: Benchmarks and reporting schemes for “speed–fidelity–energy” trade-offs; best-practice guidelines encouraging efficiency-first deployment
- Assumptions/dependencies: Community consensus on metrics; transparent measurement and reproducibility
Cross-cutting assumptions and dependencies affecting feasibility
- Model compatibility: JiT is demonstrated on flow-matching DiT (FLUX.1-dev). Adapting to other backbones or training paradigms may require exposing per-token velocity fields and revisiting interpolation operators.
- Coarse-to-fine behavior: The approach assumes global structures form before fine details; domains that violate this may need customized ITA windows or schedules.
- Implementation access: Requires hooks at tokenized latents, selector/lifter operators, and ODE scheduling (T_k, m_k). Closed-box APIs may limit integration.
- Quality guardrails: Some prompts (e.g., microtext, intricate patterns) may stress the approximation. Deploy with A/B tests, fallback to full inference, and per-prompt heuristics.
- Interactions with other accelerations: Quantization/caching can compound gains but may introduce stability issues; test combined stacks carefully.
- Licensing/governance: Use of third-party models (e.g., FLUX) must respect licensing; faster generation may increase moderation load—ensure safety tooling scales accordingly.
Glossary
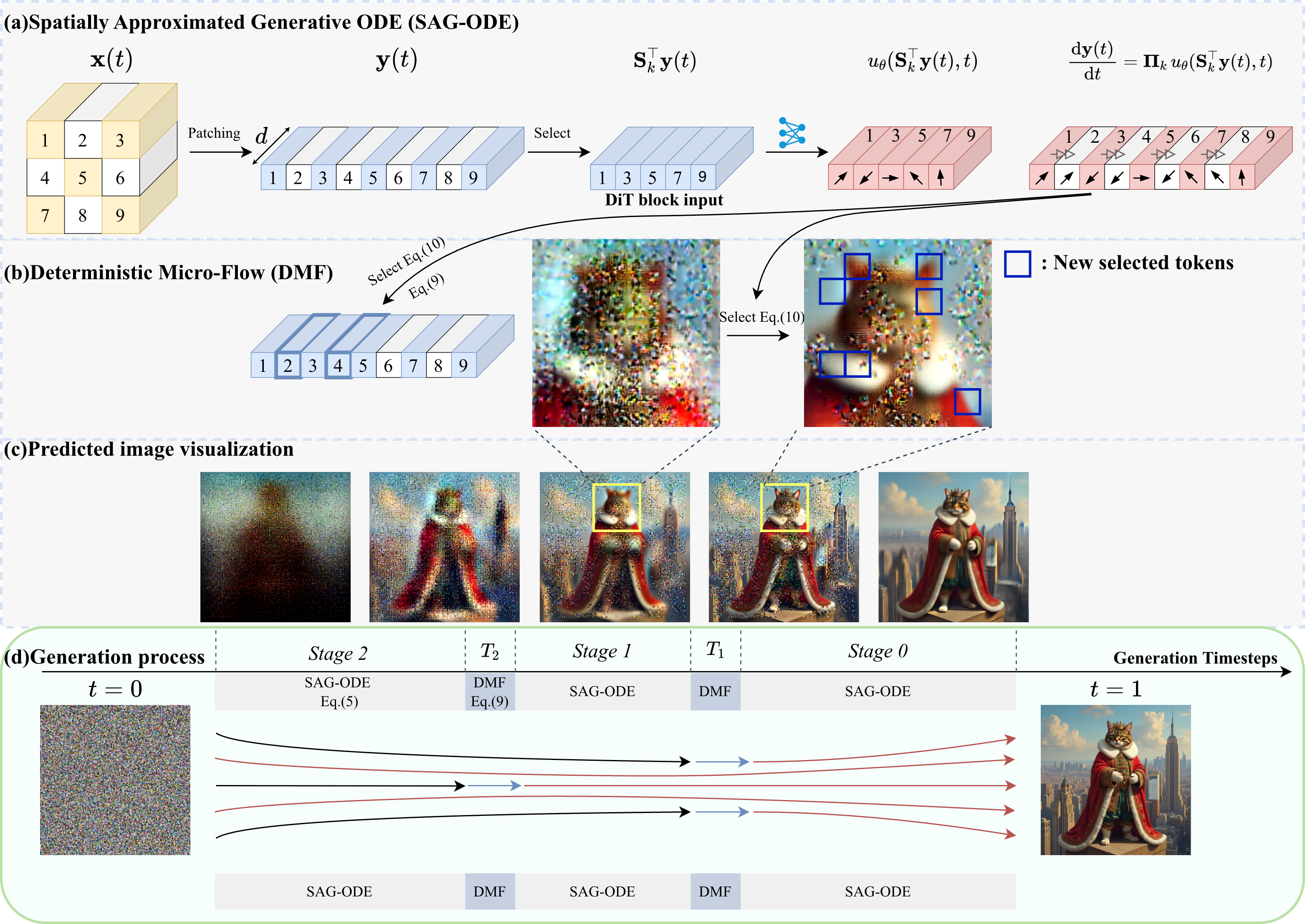
- Anchor tokens: A dynamically selected subset of tokens on which the model performs exact computations to guide generation, while other tokens are approximated. "sparse subset of anchor tokens"
- Augmented lifter operator: A mapping that embeds the computed velocities on anchor tokens back into full token space and interpolates velocities for inactive tokens. "the augmented lifter operator, "
- Deterministic micro-flow (DMF): A short, deterministic ODE-based procedure that moves newly activated tokens to a statistically correct, structurally coherent state during stage transitions. "we propose a deterministic micro-flow, a simple and effective finite-time ODE"
- Denoising diffusion implicit models (DDIM): A deterministic sampler for diffusion models that follows an ODE trajectory instead of an SDE. "to deterministic ODE samplers, such as DDIM~\cite{ddim},"
- Denoising diffusion probabilistic models (DDPMs): A class of generative models that iteratively denoise data starting from noise, defined as a diffusion process. "Denoising diffusion probabilistic models (DDPMs)~\cite{ddpm}"
- Diffusion Transformer (DiT): A diffusion-model architecture that uses Transformer-style self-attention over tokenized latent representations. "the diffusion Transformer (DiT)~\cite{dit,dit1,dit2} has emerged as a particularly potent architecture."
- Feature caching: An acceleration technique that reuses intermediate activations across timesteps to reduce computation. "feature caching, which exploits temporal redundancy by reusing intermediate activations across iterations"
- Finite-time hitting ODE: An ODE designed to reach a specified target state at a prescribed time within a finite, short interval. "is governed by a finite-time hitting ODE"
- Flow Matching: A generative modeling paradigm that learns an ODE vector field to transport noise to data. "Flow Matching formulates generative modeling as solving an ODE"
- Generative ordinary differential equation (ODE): The differential equation that governs the deterministic evolution of latents from noise to data in ODE-based diffusion/flow models. "a spatially approximated generative ordinary differential equation (ODE)"
- Importance-guided token activation (ITA): A strategy that activates new tokens based on a content-aware importance score, focusing computation where the model’s dynamics vary most. "we introduce a dynamic selection strategy importance-guided token activation (ITA)"
- Importance map: A spatial map of scores (e.g., local velocity variance) used to rank and select which inactive tokens to activate next. "we compute a spatial importance map ."
- Interpolation operator: The operator that smoothly estimates velocities for inactive tokens from the velocities of active (anchor) tokens. "the interpolation operator "
- Latent state: The current tokenized latent representation of the image being generated, evolved over time by the ODE. "full latent state evolution"
- Low-bit quantization: Representing weights/activations with reduced numerical precision to accelerate matrix operations and save memory. "low-bit quantization, which accelerates underlying matrix operations and reduces the memory footprint by representing weights and activations with lower numerical precision"
- Neural function evaluations (NFEs): The number of times the neural network is evaluated during sampling, commonly used as a proxy for inference cost. "requiring a large number of neural function evaluations (NFEs)."
- Orthogonal projector: A linear operator that projects the full token space onto the subspace spanned by the currently active (anchor) tokens. "the orthogonal projector onto the subspace spanned by the anchor tokens"
- Selector matrix: A binary matrix that extracts the currently active (anchor) tokens from the full tokenized sequence. "we define a selector matrix "
- Self-attention mechanisms: Transformer operations that compute interactions among all tokens, enabling long-range dependency modeling but with quadratic complexity in token count. "self-attention mechanisms~\cite{attention}"
- Spatial redundancy: The property that not all spatial regions require equal computation at all times because global structures form before fine details. "spatial redundancy inherent in the generative process"
- Spatially approximated generative ODE (SAG-ODE): The paper’s ODE that updates all tokens using exact velocities on anchor tokens and interpolated velocities elsewhere. "the spatially approximated generative ODE (SAG-ODE)"
- Stochastic differential equations (SDEs): Differential equations with stochastic noise terms; in diffusion models, they describe the forward/backward noising-denoising processes. "score-based stochastic differential equations (SDEs)~\cite{score}"
- Subspace diffusion: A generation approach that confines sampling to a lower-dimensional subspace without explicit resizing operations. "subspace diffusion~\cite{jing2022subspace}"
- Tweedie's formula: A result relating noisy observations to the posterior mean of clean data, used to estimate the clean latent from the model’s velocity. "Tweedie's formula~\cite{lipman2024flow}"
- Unified structural prior operator: The operator that interpolates the predicted clean tokens to the full spatial layout when constructing targets for newly activated tokens. "the unified structural prior operator"
- Variational autoencoder (VAE): A learned encoder–decoder that maps images to and from a compressed latent space for efficient generative modeling. "variational autoencoder (VAE)~\cite{vae}"
- Velocity field: The vector field predicted by the model that specifies the instantaneous rate of change of the tokenized latents over time. "the underlying velocity field"
Collections
Sign up for free to add this paper to one or more collections.