Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights
Abstract: Pretraining produces a learned parameter vector that is typically treated as a starting point for further iterative adaptation. In this work, we instead view the outcome of pretraining as a distribution over parameter vectors, whose support already contains task-specific experts. We show that in small models such expert solutions occupy a negligible fraction of the volume of this distribution, making their discovery reliant on structured optimization methods such as gradient descent. In contrast, in large, well-pretrained models the density of task-experts increases dramatically, so that diverse, task-improving specialists populate a substantial fraction of the neighborhood around the pretrained weights. Motivated by this perspective, we explore a simple, fully parallel post-training method that samples $N$ parameter perturbations at random, selects the top $K$, and ensembles predictions via majority vote. Despite its simplicity, this approach is competitive with standard post-training methods such as PPO, GRPO, and ES for contemporary large-scale models.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper asks a simple question: after we pretrain a big AI model (like a LLM), what does the space of “nearby” models look like if we nudge its settings a tiny bit? The surprising answer: for large, well‑trained models, there are many nearby versions that work better on specific tasks. It’s like walking through a dense forest (“thicket”) of specialists—some are great at math, others at coding, others at writing, and so on.
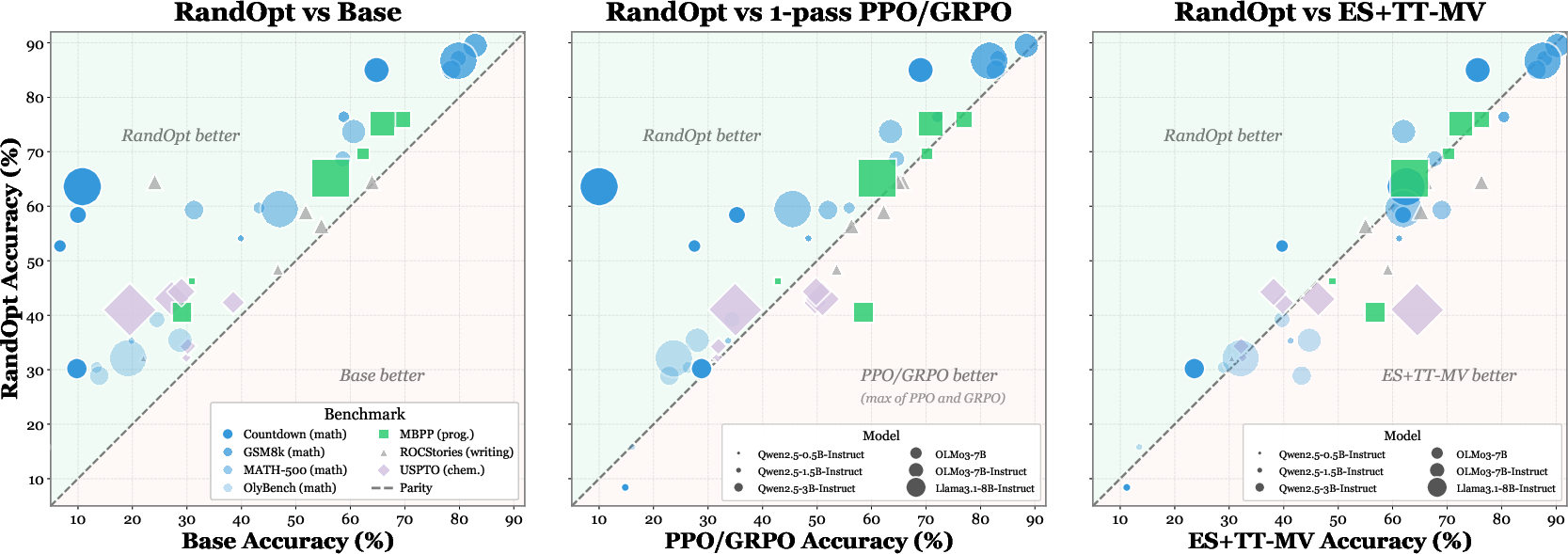
Based on this, the authors introduce a very simple method called RandOpt: make lots of tiny random tweaks to the model, keep the few tweaks that work best on a small practice set, and then combine their answers by majority vote. Despite sounding like “guess and check,” it works shockingly well for large models—competitive with much more complicated training methods.
What the authors wanted to find out
The paper focuses on three plain‑English questions:
- How common are “good” nearby versions of a model after pretraining?
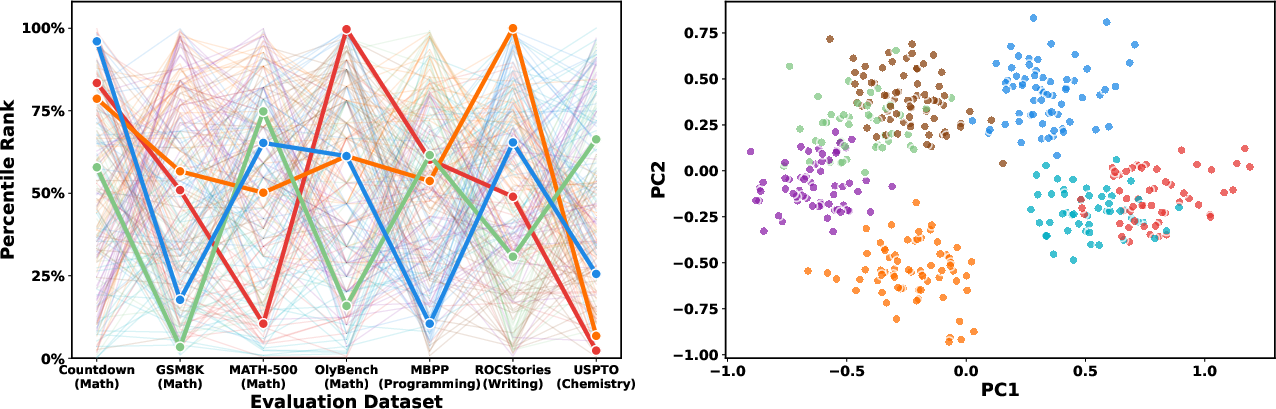
- Are those good nearby versions “generalists” (good at everything) or “specialists” (good at one thing but worse at others)?
- Can we practically take advantage of this by just sampling (guessing) tweaks and combining the best ones?
How they studied it (methods in simple terms)
Think of a pretrained model as a huge machine with billions of tiny knobs (“weights”). The authors:
- Made small random tweaks to the knobs (this is called a “perturbation”). Picture gently jiggling the settings.
- Checked whether each tweaked model did better on a task than the original.
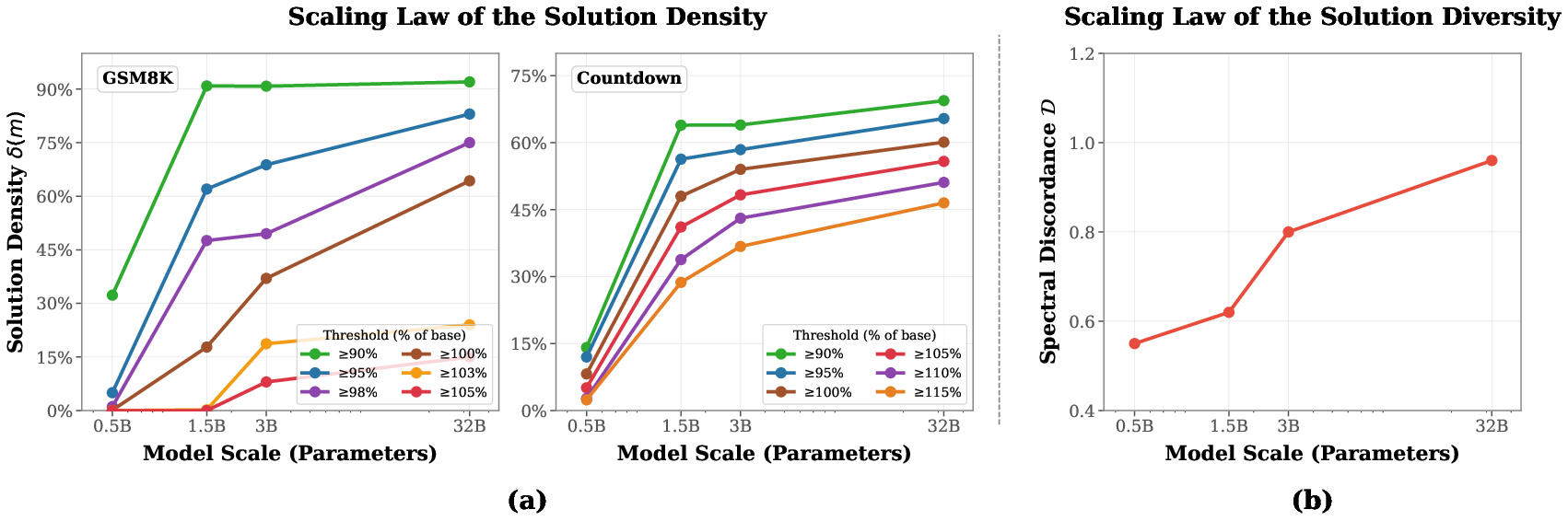
- Counted how often random tweaks helped. They call this “solution density”—basically, “How often do my random guesses improve things?”
- Checked whether helpful tweaks were specialists or generalists by seeing if a tweak that helps one task also helps or hurts other tasks. They summarize this “disagreement” with a number (higher = more specialist behavior).
Then they tried a simple two‑step method, RandOpt:
- Random Guessing: Create many tweaked models in parallel and try them on a small training/validation set.
- Ensembling (Voting): Keep the best K tweaked models and have them vote on answers. The final answer is the majority vote.
They also:
- Tested this on many tasks (math, coding, writing, chemistry) and models (from small to large).
- Tried the same idea on a vision‑LLM (answers questions about images).
- Built a tiny “toy” example with simple 1D signals to show the core idea isn’t limited to LLMs.
- Used “distillation” to copy the group’s behavior back into a single model, reducing the cost of voting at test time.
Key technical terms translated:
- “Gaussian neighborhood”: a fancy way of saying “we make many tiny, random nudges around the original weights.”
- “Solution density”: how often those nudges give you a better model for a task (i.e., the hit rate of guess‑and‑check).
- “Ensemble” and “majority vote”: a team of models each gives an answer; the most common answer wins.
What they found and why it matters
Here are the main results in clear terms:
- Big models live in “thickets,” not “haystacks.”
- Small, untrained models: good tweaks are extremely rare—like a needle in a haystack.
- Large, well‑pretrained models: good tweaks are common—like a dense forest of specialists around you.
- There’s a scaling law: as model size increases, the hit rate of helpful random tweaks goes up. So pretraining (and size) transforms the landscape from barren to thriving.
- Nearby tweaks tend to be specialists. One tweak may boost math but harm coding; another may help writing but not math. Diversity grows with model size.
- RandOpt works well.
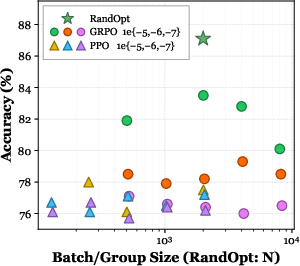
- With thousands of random tweaks and an ensemble of the top K, performance often matches or beats standard methods like PPO, GRPO, and Evolution Strategies—while requiring no step‑by‑step training (it’s fully parallel).
- On a vision‑language task (GQA), this simple approach improved accuracy a lot on a 3B‑parameter model.
- Voting matters. Using a team (ensemble) of the best tweaked models is much better than picking just one.
- Distillation helps deployability. You can train a single model to mimic the ensemble’s behavior, keeping most of the gains without needing to run K models at test time.
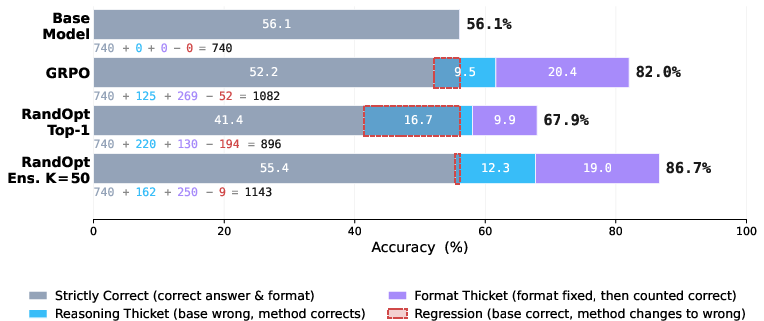
- It’s not just formatting tricks. Some gains come from fixing answer formats (like giving the result in the expected style), but a solid chunk comes from truly solving problems the base model previously missed.
Why this matters:
- It challenges the assumption that post‑training always needs complex, careful optimization.
- It suggests that pretraining creates a rich neighborhood full of useful, different experts, and simple selection + voting can unlock them.
What this could change (implications)
- Think of pretrained models as a “distribution,” not a single point. Around the original weights, there’s a crowd of nearby specialist models waiting to be sampled.
- Post‑training might be easier than we thought for large models. If good solutions are everywhere nearby, many methods—gradient descent, evolutionary search, or even random sampling—can work.
- Faster wall‑clock adaptation. Because RandOpt is fully parallel (no step‑by‑step updates), it can be fast if you have enough machines to test tweaks at once.
- Practical trade‑off. Ensembling increases test‑time cost (you run K models), but distillation can compress the team back into one model with similar performance.
- A new way to study models. Instead of only looking at a single “loss” number, studying the multi‑task landscape (how different tasks improve or worsen with small tweaks) can reveal hidden structure—like the “thicket” of specialists that pretraining creates.
In short: once a model is big and well‑trained, you don’t always need fancy fine‑tuning. Sometimes, a smart version of “guess and check” plus voting can be enough to uncover powerful, diverse experts already living near the model’s current settings.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete, unresolved issues that the paper leaves open. Each item is phrased to guide actionable follow-up work.
Theory and measurement of “thickets”
- Lack of a formal theory for why solution density scales with model size: What properties of the Hessian/Fisher spectrum, overparameterization, or pretraining data induce dense neighborhoods of task-improving weights?
- Parameterization dependence: Gaussian perturbations in raw weight space are not invariant to reparameterizations (e.g., layer rescaling, optimizer states). How do density/diversity estimates change under different parameterizations or metrics (e.g., Fisher-preconditioned, natural gradient, or per-layer normalized spaces)?
- Anisotropy of the local landscape: The paper assumes isotropic Gaussian noise; how anisotropic is the true “thicket,” and can sampling along principal curvature directions (eigenvectors of the Hessian/Fisher) increase hit rate per sample?
- Sensitivity to perturbation scale: Results are shown for a small set of σ values; how do solution density/diversity curves vary with σ, per-layer σ schedules, or adaptive perturbation magnitudes?
- Task-conditioned density: Density is measured with accuracy on specific benchmarks; how do estimates vary with evaluation set size, noise in scoring, or alternative metrics (e.g., reward models, calibration scores, pass@k)?
- Stability/variance of measurements: How robust are density/diversity curves across seeds, evaluation subset choices, and decoding settings? Confidence intervals and variance decompositions are not reported.
Method design and scalability (RandOpt)
- Compute and memory cost at scale: For N up to 5,000 and K up to 50, what are the wall-clock and memory footprints for 7B–70B+ models without massive parallel clusters? Are there incremental/streaming or sharing strategies that reduce memory (e.g., rank-1 updates, on-the-fly perturbation application, or parameter sharing)?
- Layer- and module-wise ablations: Which layers (attention vs MLP, embeddings, layer norms) drive most gains/harms under perturbation? Can targeting specific submodules or low-rank subspaces reduce N while preserving gains?
- Better sampling distributions: Do structured perturbations (LoRA-space, low-rank Gaussians, learned proposal distributions, per-layer scaling) outperform global isotropic noise for the same compute?
- Multi-objective selection: Because single-task gains often induce regressions elsewhere, how can selection be made multi-objective (e.g., optimizing vector-valued performance with fairness or safety constraints) to reduce regressions?
- Ensemble aggregator design: Majority vote over final answers is used; do weighted voting, stacking, verifier-guided reranking, or confidence-calibrated aggregation yield better accuracy/calibration than simple voting?
- Test-time vs train-time selection: Can “RandOpt at inference” (select specialists per query via verifiers) outperform preselected fixed ensembles, and what is the latency/quality trade-off?
- Robustness to decoding choices: How do temperature, nucleus sampling, or CoT prompting affect selection and ensemble gains? Are improvements robust to standardized decoding protocols?
Generalization, robustness, and safety
- Overfitting in selection: How large must D_train be to avoid overfitting when selecting top-K? What is the sample complexity of selection, and how well do top-K seeds transfer to unseen data and to other tasks?
- Catastrophic regressions: The paper shows small regressions in one case; how frequent and severe are regressions across broader task suites, long-context settings, and multilingual or code generation tasks?
- Out-of-distribution behavior: Do “thicket” gains persist on OOD inputs, adversarial prompts, or noisy real-world datasets?
- Alignment and safety impacts: Random weight perturbations can degrade guardrails, increase toxicity, or induce jailbreak susceptibility. How do safety metrics (toxicity, bias, hallucination rates, prompt injection resilience) change under RandOpt and after distillation?
- Calibration and uncertainty: Does ensembling over perturbed weights improve or degrade calibration, abstention behavior, and reliability under distribution shift?
- Persistent capability trade-offs: Can we characterize and control the specialist/generalist trade-off to prevent hurting non-target capabilities (e.g., factuality while improving math)?
Evaluation scope and fairness
- Benchmark sensitivity: The paper acknowledges formatting sensitivity; beyond GSM8K, how much of the gains on other tasks are due to formatting/style vs genuine reasoning or knowledge improvements?
- Baseline comparability: Equal FLOP budgets are used, but baselines differ in test-time ensembling (e.g., 1-pass PPO/GRPO vs 50-pass TT-MV for ES). How do conclusions change under matched test-time ensembles and stronger hyperparameter sweeps for baselines?
- Task coverage: Results center on math, code, ROCStories, chemistry, and one VLM dataset. Do thickets and RandOpt gains hold for knowledge-heavy QA, instruction-following, summarization, retrieval-augmented tasks, tool use, and long-horizon planning?
- Model coverage: Most scaling results use Qwen2.5 models and a few others up to 32B. Do thickets persist and does RandOpt remain efficient for larger (70B–>100B) or different-architecture models (e.g., Mixture-of-Experts, state-space models)?
Distillation and deployment
- Distillation generality: Distillation results are shown on GSM8K and two models; does ensemble-to-single distillation match ensemble performance across tasks and model sizes, and how stable is it with limited data?
- Retaining safety and generality in distillation: Does distilling top-K specialists preserve alignment and general-purpose abilities, or does it overfit to the selection task?
- Data and compute budgeting: What is the optimal split between N (search), K (ensemble size), and distillation budget to minimize total latency and cost for deployment scenarios?
- Latency and memory at inference: With K>1, ensembles multiply inference cost. What are practical latency/memory footprints and serving strategies (e.g., early exit voting, partial sharing of KV caches) to make this deployable?
Extensions and alternatives
- Beyond weight-space: Would perturbations in adapter/LoRA space, activation space, or optimizer-state space yield higher-quality specialists per unit compute?
- Task-adaptive or gated ensembles: Can we learn a router that picks different specialist subsets per query, converting a fixed top-K into a conditional mixture for better efficiency and accuracy?
- Verifier-driven selection: For tasks without ground-truth labels (e.g., summarization), can verifiers or reward models reliably score seeds to select top-K without introducing reward hacking or spurious correlations?
- Applicability to other modalities: VLM experiments are limited. Do similar thickets emerge in ASR, speech synthesis, diffusion models (beyond “color thickets”), and control policies, and how should perturbations be applied there?
- Relationship to PEFT and model soups: How does RandOpt compare to and combine with LoRA fine-tuning, model soups, or snapshot ensembles under matched compute and inference budgets?
Causality and pretraining factors
- What in pretraining causes thickets? Is task-expert density primarily driven by model size, data diversity, objective choice (next-token vs contrastive vs multi-task), or architectural inductive biases?
- Can pretraining be shaped to produce denser/more useful thickets earlier (e.g., curriculum design, multi-task pretraining, regularizers that increase local diversity without hurting pretraining loss)?
- Can we predict thicket density from pretraining metrics (loss, gradient norms, curvature) to decide when RandOpt will be effective without large pilot searches?
These gaps outline concrete directions for theory, methodology, evaluation, and deployment that would clarify when and how “neural thickets” and RandOpt can be safely and efficiently leveraged.
Practical Applications
Immediate Applications
The findings and RandOpt method enable deployable workflows today, especially with open-weight models and access to modest parallel compute. Below are concrete applications, sectors, and practical considerations.
- Plug-and-play post-training of open-weight LLMs for enterprise tasks (software, finance, healthcare, legal)
- What: Rapidly adapt a pretrained LLM to a narrow task (e.g., internal Q&A, report generation, claim adjudication rationale, contract clause extraction) by sampling N random weight perturbations, ranking on a small validation set, and ensembling the top K.
- Tools/workflows: RandOpt library; MLOps pipeline step “Parallel Weight Sampling & Selection”; small held-out eval set + reward/verifier; majority-vote aggregator; cached top-K seed list per task.
- Assumptions/dependencies: Access to model weights; a reliable task-specific scoring function; enough parallel compute for N=1k–5k seeds; model scale ≥1–3B parameters; guardrail/safety evaluation for selected seeds.
- Ensemble “committee” inference for higher accuracy and robustness (healthcare, finance, safety-critical ops, customer support)
- What: Deploy a small ensemble (e.g., K=5–50) of selected seeds to reduce variance and improve correctness in math/code reasoning, structured outputs, or safety-sensitive decisions.
- Tools/workflows: Lightweight inference microservice that runs K models in parallel and returns majority vote; confidence/consensus metrics; per-task “expert routing.”
- Assumptions/dependencies: Latency/cost budget for K forward passes; careful monitoring to avoid format-induced failures; ongoing regression tests.
- Distill top-K into a single production model to cut inference cost (software, education, finance)
- What: Use the paper’s hard-example SFT to compress an ensemble into one model with near-ensemble accuracy, reducing runtime and serving cost.
- Tools/workflows: “Thicket Distiller” job that (a) collects top-K responses, (b) creates hard-example pairs [reasoning; answer], (c) runs 1–2 epochs SFT.
- Assumptions/dependencies: Access to training API for SFT; small additional compute (~2% of the selection budget in the paper); data governance for generated traces.
- Format-robust output pipelines (compliance reporting, finance ops, healthcare EHR coding, government forms)
- What: Improve pass@1 by selecting seeds that naturally adhere to strict schemas (JSON, fixed tags, ICD codes) and/or adding format checkers that re-score.
- Tools/workflows: Schema validators; “format reward” in scoring; auto-retry with format-favoring seeds; style/format thicket dashboards.
- Assumptions/dependencies: Clear output specifications; measurable format reward; awareness that some observed gains may be format fixes rather than deeper capability gains.
- Vision–language specialization for visual QA and inspection (manufacturing QA, retail catalog QA, robotics perception)
- What: Improve VLM reasoning (e.g., GQA-like tasks) by perturbing only the language head and selecting seeds specialized for your visual questions.
- Tools/workflows: Freeze visual encoder; apply RandOpt to LM head; small photo/question validation set; top-K ensemble at inference.
- Assumptions/dependencies: Access to VLM weights; good visual QA reward function; compute for N~1–5k seeds.
- Rapid method selection and benchmarking via solution density and spectral discordance (academia, eval teams, MLOps)
- What: Use the paper’s metrics to (a) quantify how “thick” the neighborhood is for your base model, (b) decide if selection/ensembling is worthwhile, and (c) characterize specialist diversity before committing to long fine-tunes.
- Tools/workflows: “Thicket Explorer” that estimates solution density δ(m) and spectral discordance; seed-sweep reports; per-task diversity maps.
- Assumptions/dependencies: Access to a small multi-task eval battery; compute for seed sweeps; stable evaluation harness.
- Code generation with unit-test–driven weight selection (software engineering)
- What: Treat unit-test pass rate as the reward to select top-K seeds for a specific codebase/language; ensemble or distill for higher pass@1.
- Tools/workflows: CI-integrated RandOpt; containerized seed evaluators; “Best-of-N in weight space” complementing “Best-of-N in output space.”
- Assumptions/dependencies: Deterministic tests; reasonable evaluation throughput; environment isolation for evaluation.
- Internal “seed banks” for tasks and styles (marketing, sales ops, customer support)
- What: Maintain a catalog of task- and style-specific seed ensembles (e.g., concise vs. persuasive tone, brand voice, regional compliance forms).
- Tools/workflows: Versioned seed registries; per-use-case selection; A/B tools for seed ensembles; usage analytics by task.
- Assumptions/dependencies: Stable reward metrics per style; governance of content risk; controlled drift monitoring.
- Safety and alignment sweeps via seed selection (safety engineering, policy teams)
- What: Use seed sweeps to stress-test guardrails, spot formatting or refusal regressions, and select ensembles that balance capability and safety.
- Tools/workflows: Red-team prompts; alignment scorecards as reward; exclusion rules for unsafe seeds; ensemble-level safety gating.
- Assumptions/dependencies: Safety evaluators with good coverage; systematic logging; review processes for unexpected behaviors.
- Low-compute, no-gradient post-training in resource-constrained settings (SMEs, edge servers)
- What: Achieve noticeable gains without any gradient steps by running a modest N (e.g., 256–1024), selecting K=5–10, and optionally distilling.
- Tools/workflows: Batch inference orchestration; checkpoint diffing; on-prem deployment playbooks.
- Assumptions/dependencies: Base model at sufficient scale/quality; minimal validation set; acceptance of smaller but quick gains.
Long-Term Applications
Beyond immediate deployment, the thickets perspective suggests new systems, training paradigms, and policy frameworks that need additional research, scaling, or productization.
- Thicket-aware pretraining and post-training objectives (foundation model training)
- What: Explicitly shape pretraining to maximize downstream solution density and controllable diversity, making post-training predominantly a selection problem.
- Tools/workflows: Multi-task curricula; objectives that promote low-dimensional task-relevant directions; regularizers that improve specialist diversity without harmful behaviors.
- Assumptions/dependencies: Access to pretraining stack; reliable multi-task decomposition; safety constraints to prevent dense harmful “thickets.”
- Weight-space generative samplers for targeted experts (software, robotics, healthcare)
- What: Learn a conditional sampler over weights (or low-rank directions) to draw specialists for a given task/reward—moving from Gaussian noise to learned, targeted proposals.
- Tools/workflows: Variational/Bayesian weight models; low-rank noise parameterizations; conditional proposal networks.
- Assumptions/dependencies: Stable reward signals; safe exploration in weight space; strong priors to avoid capability regressions.
- Hardware–software co-design for ensemble inference (cloud providers, chip vendors)
- What: Optimize accelerators and serving stacks for small-K parallel ensembles and rapid seed switching; memory-sharing across similar checkpoints.
- Tools/workflows: Multi-checkpoint weight deltas; KV cache reuse across seeds; scheduling policies for ensemble batches.
- Assumptions/dependencies: Vendor support; memory-efficient diff storage; standard APIs for ensemble serving.
- Safety-by-committee certification standards (policy, regulators, safety-critical industries)
- What: Create norms requiring ensemble-based decisions, seed-sensitivity analysis, and disclosure of ensemble composition for regulated applications (e.g., clinical decision support, credit decisions).
- Tools/workflows: Certification checklists around δ(m), spectral discordance, and regression rates; audit logs for seed selection and distillation steps.
- Assumptions/dependencies: Consensus on evaluation suites; regulatory buy-in; traceable provenance of derived weights and ensembles.
- Thicket shaping for safety (alignment research)
- What: Reduce the density of harmful or non-compliant solutions while preserving useful experts via safety-aware selection and training signals.
- Tools/workflows: Safety rewards during selection; adversarial/threat modeling in weight space; mechanisms to quarantine risky seeds.
- Assumptions/dependencies: High-quality safety evaluators; techniques to avoid “over-pruning” beneficial diversity.
- Robotics/control: parallel selection instead of long-horizon RL (robotics, manufacturing)
- What: For policies initialized from pretrained visuomotor/backbone models, use parallel weight perturbation selection on simulator or on-device telemetry to discover task specialists faster than sequential RL.
- Tools/workflows: Simulator-based reward evaluation; population selection; occasional distillation into a single deployable policy.
- Assumptions/dependencies: Sim-to-real fidelity; safety interlocks; real-time evaluation budgets.
- Federated “seed portfolios” and tenant-specific experts (cloud, SaaS platforms)
- What: Offer customer-specific ensembles derived from a shared base, improving privacy/latency without full fine-tunes; share only weight deltas or seed IDs.
- Tools/workflows: Multi-tenant seed catalogs; per-tenant reward definitions; confidential checkpoint diff distribution.
- Assumptions/dependencies: Licensing for derivative weights; secure isolation; governance for model drift.
- AutoML via population selection in weight space (ML platforms)
- What: Treat N×K selection as a first-class optimization primitive, integrated with existing HPO; combine with LoRA/low-rank updates for targeted improvements.
- Tools/workflows: Unified selection dashboards; budget allocation between seed sweeps and gradient steps; automated distillation triggers.
- Assumptions/dependencies: Scheduling across GPUs/TPUs; robust comparison protocols; cost governance.
- Low-rank/noise-direction libraries for safe perturbations (open-source ecosystem)
- What: Precompute/task-share low-rank directions with good empirical properties (format adherence, safety, reasoning styles) to reduce search space and improve reliability.
- Tools/workflows: Community-curated direction hubs; provenance and scoring metadata; plug-ins for common frameworks.
- Assumptions/dependencies: Standardized evaluations; license clarity for derived artifacts.
- Legal and IP frameworks for derived weights and ensembles (policy, legal)
- What: Clarify ownership, licensing, and compliance obligations for models produced by random weight perturbations, selection, and distillation.
- Tools/workflows: Policy templates for derivative works; disclosures for ensemble composition and training data used in distillation.
- Assumptions/dependencies: Evolving jurisprudence on model derivatives; alignment with OSS licenses.
- Thicket-driven evaluation science (academia)
- What: New benchmarks and methodologies to separate gains from formatting vs. reasoning; standardized measurement of δ(m) and spectral discordance across model families and tasks.
- Tools/workflows: Open leaderboards that report format- vs. reasoning-derived gains; cross-model thicket maps; reproducible seed-sweep protocols.
- Assumptions/dependencies: Community consensus on metrics; transparent data and harnesses.
Cross-cutting assumptions and risks
- Scale and pretraining quality: Thickets emerge at larger, well-pretrained models; very small models show limited gains.
- Reward/evaluator quality: Selection is only as good as the scoring function (risk of overfitting superficial criteria like format).
- Cost/latency: Ensembles increase inference cost; distillation mitigates but adds an extra step.
- Safety and regressions: Some seeds improve one task while degrading others; require regression tests and safety checks.
- Access constraints: Closed APIs often disallow weight perturbations; output-space Best-of-N may be a practical proxy where weights are inaccessible.
Glossary
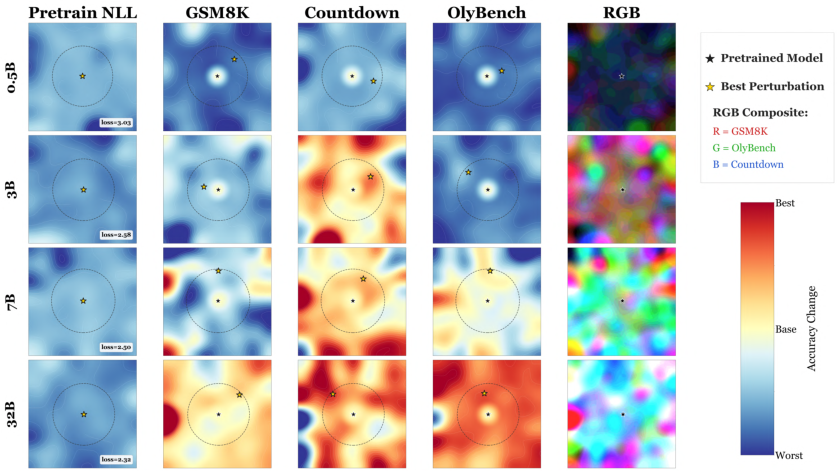
- Accuracy landscape: The surface describing performance (e.g., accuracy) as a function of model parameters, used to reason about local maxima/minima in weight space. "small models reside on local maxima of the accuracy landscape"
- Autoregressive rollout: Generating future tokens/values by repeatedly feeding model outputs back as inputs, conditioned on prior context. "This model can generate predictions by autoregressive rollout given an initial observed context."
- Bayesian neural nets: Neural networks that treat weights as random variables, enabling sampling-based uncertainty estimation and ensembling. "Bayesian neural nets treat parameters as random variables, which can be sampled from to estimate distributions over outputs"
- Best-of-N: A guess-and-check strategy that samples multiple candidates and selects the best according to a verifier or score. "Parallel guess-and-check methods, such as Best-of-N, are also commonly used at test-time to improve model performance"
- Distillation: Transferring the behavior of an ensemble or larger model into a single model via supervised training on generated data. "We perform distillation on the Qwen2.5-1.5B-Instruct and Qwen2.5-3B-Instruct models."
- ES: Short for Evolution Strategies; a family of black-box optimization methods that use population-based random perturbations and selection. "competitive in converged accuracy with GRPO and ES."
- Evolutionary algorithms: Population-based optimization methods inspired by natural evolution that maintain and evolve sets of candidate solutions. "gradient-based search, evolutionary algorithms, and brute-force parallel selection all will do."
- Flat minima: Regions of parameter space where the loss remains low across broad neighborhoods, often linked to better generalization. "training tends toward flat minima"
- FLOP-efficient: Achieving performance with relatively low floating-point operation counts during training or inference. "RandOpt is O(1) in training steps, FLOP-efficient, and competitive in converged accuracy with GRPO and ES."
- Gaussian neighborhood: A local region around parameters defined by Gaussian perturbations, used to probe nearby solutions. "density of task-improving weights in a Gaussian neighborhood of the pretrained weights"
- GRPO: A reinforcement learning–style policy optimization method used for post-training LLMs. "PPO, GRPO, and ES"
- K-means clustering: An unsupervised algorithm that partitions data into K clusters by minimizing within-cluster variance. "we project the 7-dimensional performance vectors into 2D and apply K-means clustering."
- KL-regularized methods: Optimization approaches that penalize divergence (KL) from a reference model or distribution to stabilize updates. "KL-regularized methods such as PPO constrain the policy to remain close to the pretrained model"
- Linear mode connectivity: The empirical phenomenon that low-loss paths often exist between different trained solutions when interpolating linearly in weight space. "multi-task linear mode connectivity"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning technique that inserts trainable low-rank matrices while freezing most weights. "parameter-efficient fine-tuning methods such as LoRA~\citep{hu2022lora} restrict updates to low-rank components while freezing most of the base model"
- Lottery Ticket Hypothesis: The idea that large networks contain sparse subnetworks that can be trained effectively from an appropriate initialization. "The Lottery Ticket Hypothesis suggests that, when training from scratch, finding a good initialization is akin to winning the lottery"
- Majority voting: An ensembling rule where the most frequently predicted answer among a set of models is selected as the final output. "ensembled via majority voting"
- MAML: Model-Agnostic Meta-Learning; an algorithm that learns initializations enabling fast adaptation to new tasks with few updates. "Prominent in this family is the MAML algorithm of \citet{finn2017model}."
- Negative log-likelihood: A loss function equal to the negative log of the model’s predicted probability for observed data, commonly used for maximum likelihood training. "The SFT objective minimizes the negative log-likelihood of the reasoning trace and final answer"
- Overparameterization: The regime where models have more parameters than strictly needed, often yielding broad basins and surprising optimization properties. "a broad loss basin induced by pretraining and overparameterization"
- Pareto front learning: Methods that explore trade-offs between multiple objectives, seeking solutions that are non-dominated across tasks. "Pareto front learning, where paths in weight space are identified that tradeoff between different task objectives"
- Parameter-efficient fine-tuning: Techniques that modify a small subset or low-rank portion of parameters to adapt large models cheaply. "parameter-efficient fine-tuning methods such as LoRA~\citep{hu2022lora}"
- pass@k: The metric measuring whether at least one of k generated attempts is correct; commonly used to assess sampling-based performance. "aim to convert high pass@k performance into high pass@1 performance"
- PCA (Principal Component Analysis): A dimensionality-reduction technique that projects data onto directions of maximal variance. "PCA visualization of these performance vectors"
- Pearson correlation matrix: A matrix of pairwise Pearson correlation coefficients capturing linear relationships between variables. "let C be the Pearson correlation matrix of its columns"
- Population size: The number of sampled candidates (e.g., perturbed models) evaluated in a population-based search. "Heatmap of accuracy across population size N and selection ratio K/N."
- PPO: Proximal Policy Optimization; a reinforcement learning algorithm with clipped updates and often KL regularization. "PPO, GRPO, and ES"
- Quality-diversity algorithms: Evolutionary methods that seek not only high-performing solutions but also diverse behaviors or niches. "evolutionary methods and quality-diversity algorithms, which maintain a population of promising solutions"
- Random projection: A technique that projects high-dimensional data into lower dimensions using random linear maps, approximately preserving structure. "project the perturbed models into 2D using random projection"
- RandOpt: The paper’s proposed method that randomly perturbs weights, selects top performers, and ensembles their predictions. "We call this algorithm RandOpt."
- Sandbagging: Intentionally or unintentionally suppressing performance on certain tasks during training, which can be undone by perturbations. "Can Sandbagging Explain These Results?"
- Selection ratio: The fraction of sampled candidates retained for ensembling, typically K/N in population-based selection. "Heatmap of accuracy across population size N and selection ratio K/N."
- Solution Density: The probability that a random parameter perturbation yields at least a specified improvement over the base model. "We define the Solution Density as:"
- Spectral Discordance: A measure of diversity/specialization across tasks based on correlations of seed rankings, with higher values indicating more orthogonality. "We define the Spectral Discordance as:"
- Supervised fine-tuning (SFT): Training a model on labeled input–output pairs, often to adapt or distill capabilities. "perform supervised fine-tuning (SFT) on the base model"
- Test-time Majority Vote (TT-MV): Ensembling multiple outputs at inference by voting on the final answer. "K-pass baselines use Test-time Majority Vote (TT-MV)."
- Thicket regime: The regime where many nearby, diverse, task-specific solutions surround pretrained weights, enabling simple selection to work. "We term this the thicket regime."
- Vision-LLM (VLM): A model that processes both visual and textual inputs for multimodal tasks. "a 3B-parameter vision-LLM (VLM)."
- Weight space: The high-dimensional space of model parameters; exploring neighborhoods here reveals nearby solutions. "Accuracy landscapes in weight space across model scales and reasoning tasks."
- Xavier initialization: A weight initialization scheme designed to keep signal variance stable across layers at the start of training. "Xavier initialization"
Collections
Sign up for free to add this paper to one or more collections.