- The paper introduces a novel inference-time module, MeMix, that employs selective token updates to reduce state drift in streaming 3D reconstruction.
- It partitions the recurrent state into patches and applies a Bottom-k routing policy, significantly limiting interference compared to full or soft updates.
- Empirical evaluations on benchmarks show up to 40% improvement in reconstruction error and notable reductions in pose drift over long image sequences.
MeMix: Training-Free Memory Mixtures for Stable Streaming 3D Reconstruction
Streaming 3D reconstruction imposes a constant-memory, real-time constraint on recurrent models tasked with fusing long image sequences. Historically, two dominant paradigms have emerged: (1) attention-KV-cache-based methods with linear memory growth, and (2) fixed-state recurrent architectures, such as CUT3R and TTT3R, which maintain O(1) inference cost. However, fixed-state frameworks universally suffer from cumulative state drift and catastrophic forgetting over long horizons, manifesting as geometric implausibility, pose drift, and poor surface continuity. Previous attempts to mitigate this (e.g., test-time training gating in TTT3R) address only the magnitude, not the locality, of state overwrites. This paper presents MeMix—an inference-time module that reinterprets the latent recurrent state as a mixture-of-memory (MoM), enabling sparse, token-level writes and selective state preservation.
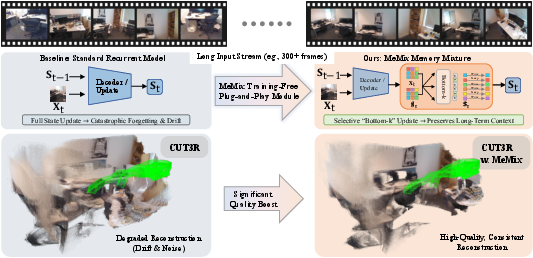
Figure 1: The MeMix module routes state updates to Bottom-k patches, preserving the majority of the recurrent state, and thus reducing long-term interference and drift in streaming reconstruction pipelines (O(1) inference memory).
Architecture and Sparse Memory Routing
MeMix is agnostic to the underlying backbone and can be integrated into any fixed-state recurrent streaming pipeline without parameter or code changes. At each step, MeMix partitions the state tokens into patches, evaluates a relevance score (e.g., dot product) between the current decoder-proposed state and the new observation, and constructs a binary routing mask. Only the Bottom-k (least-aligned) state patches receive the new update; the remaining tokens are exactly preserved. This design sharply contrasts with full-state overwrite (CUT3R) or dense soft gating (TTT3R/TTSA3R), which, while offering some improvement, always introduce interference by updating every token (potentially by a small value).
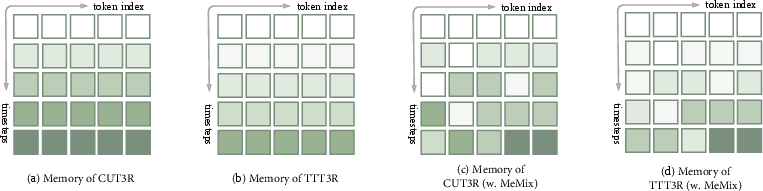
Figure 2: Diagram illustrating the difference between full overwrites (CUT3R), soft token-wise gating (TTT3R), and MeMix's selective Bottom-k patch updates, which enforce exact token preservation.
The formalized MeMix state update obeys:
St=Mt⊙S^t+(1−Mt)⊙St−1
Optionally, MeMix can also leverage adaptive test-time scaling (like TTT3R), resulting in
St=(Mt⊙βt)⊙S^t+(1−Mt⊙βt)⊙St−1
This extension remains training-free, as βt is derived from cross-attention and does not introduce learnable parameters.
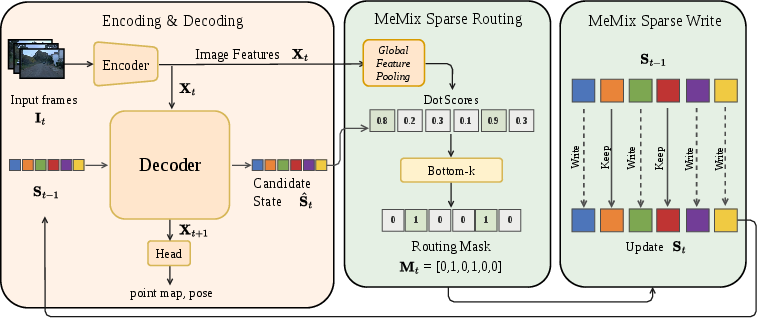
Figure 3: MeMix operational overview describing ViT encoding, token fusion through dual-stream cross-attention, sparse mask construction via Bottom-k routing, and selective state update.
Empirical Evaluation: 3D Reconstruction, Pose, and Depth
Across standard benchmarks—7-Scenes, NRGBD, ScanNet, KITTI, etc.—the effects of MeMix are quantitatively and qualitatively evaluated. Baseline models used include CUT3R, TTT3R, and TTSA3R, compared against their MeMix variants. For extremely long input sequences (300–500 frames), offline or causal-KV memory models (VGGT, StreamVGGT) encounter out-of-memory failures, whereas fixed-state backbones drift rapidly. MeMix consistently yields superior long-horizon stability.
On 7-Scenes, MeMix reduces reconstruction completeness error by an average of 15.3% (up to 40%) compared to the corresponding recurrent baselines, and always preserves or improves accuracy and normal consistency. NRGBD exhibits similar trends, especially in the most memory-constrained or long-stream regimes.

Figure 4: Qualitative 3D reconstructions show MeMix corrects major baseline artifacts, including surface tearing, missing geometry, and ghosting on long sequences.
In long-sequence pose estimation (TUM, ScanNet), MeMix plug-ins on all backbones manifest lower absolute trajectory error (ATE) than their corresponding vanilla versions. The reduction of accumulated drift is particularly evident as the number of frames increases.
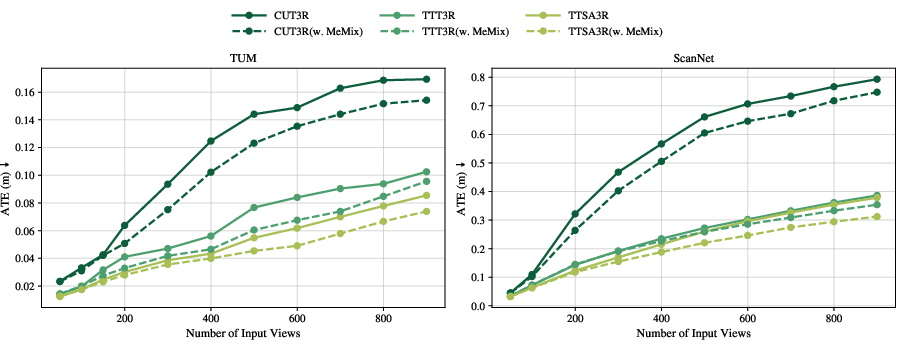
Figure 5: MeMix improves ATE on challenging long-sequence pose estimation benchmarks, indicating improved stability and accuracy under long-term streaming.
In video depth estimation on KITTI, Bonn, and Sintel, MeMix generally improves scale-invariant and metric depths across a sequence length spectrum (50 to 1000 frames). Importantly, improvements on shorter sequences are also observed, suggesting MeMix's benefit is not limited to memory saturation scenarios.
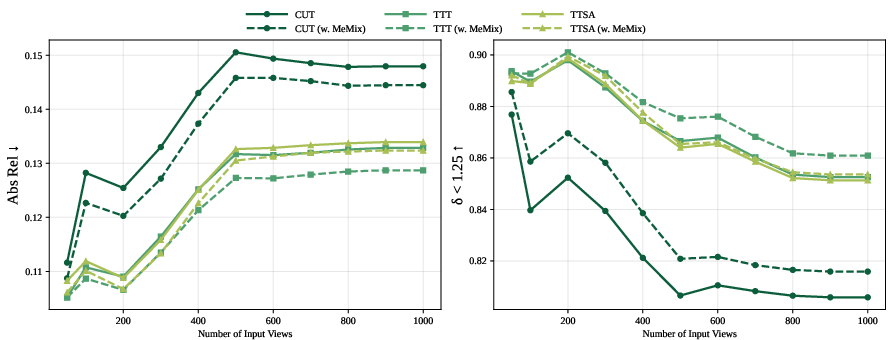
Figure 6: Video depth estimation on a range of frame counts demonstrates that MeMix robustly suppresses state degradation effects across tasks and horizons.
Sparse Routing Analysis and Implementation
Ablation studies systematically probe patch selection policies (Bottom-k/Top-k/Random-k), gating functions (dot/cosine/attention score), and update strategies (single/full/no update). Bottom-k selection achieves higher update frequency and more uniform token utilization. Top-k creates a positive feedback loop, disproportionately reinforcing a subset of highly-aligned tokens, which can lead to memory underutilization. MeMix’s Bottom-k policy ensures a balanced and dynamic long-term state evolution.

Figure 7: Representative sweep of Bottom-k parameter on depth and pose tasks for MeMix-enabled and baseline models; performance peaks as k approaches a task-specific optimum.
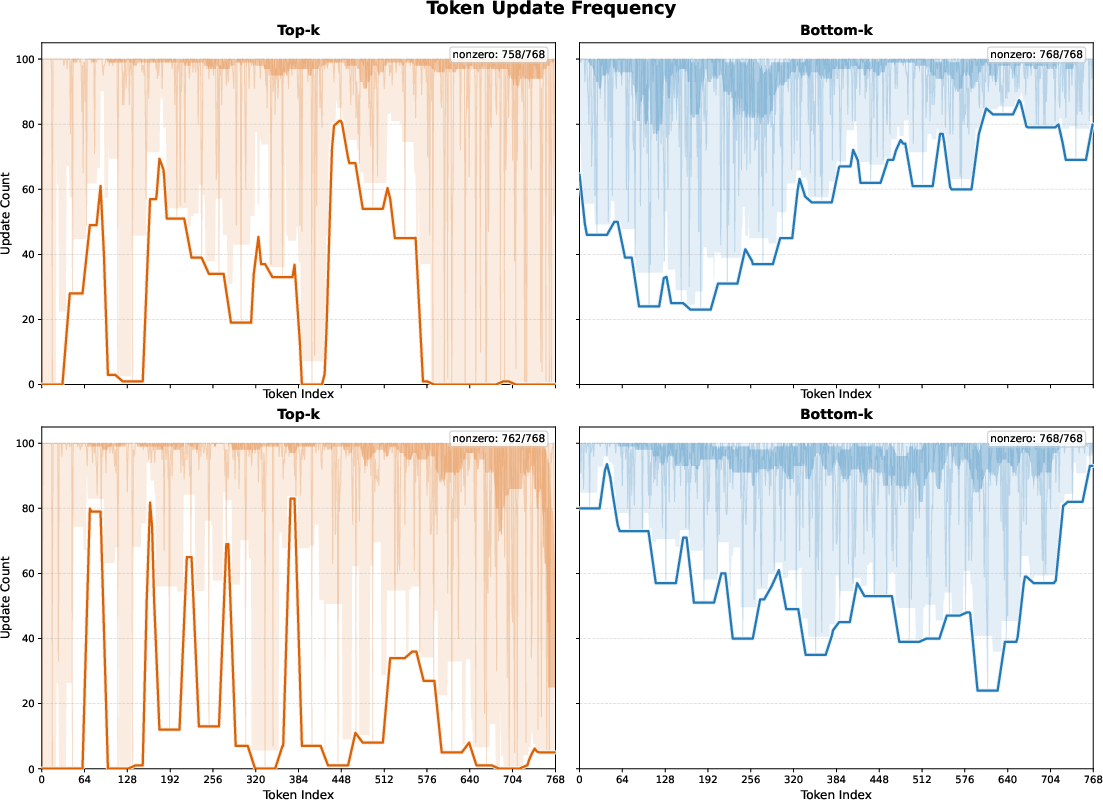
Figure 8: Visualization of Top-k vs. Bottom-k patch selection demonstrates MeMix's balanced memory utilization, avoiding state staleness common in Top-k.
Inference speed and peak GPU memory usage remain unchanged by MeMix: latency and resource cost is dominated by the base model, confirming the plug-and-play and deployment-friendly nature of the approach.
Broader Implications and Limitations
MeMix makes the bold claim that most recurrent state overwrites in online 3D reconstruction models are unnecessary and harmful on long horizons—a single sparse masking strategy suffices to mitigate catastrophic forgetting and drift. By decoupling the "where-to-write" and "how-much-to-write" aspects of memory update and providing a plug-in mechanism, MeMix enhances long-term consistency without retraining or architectural change.
Practically, MeMix can be dropped into any memory-constrained streaming spatial model, enabling robust scene understanding in robotics, augmented reality, and autonomous navigation under unbounded input. Theoretically, MeMix aligns with principles found in mixture-of-expert and sparse-gated architectures, and moves toward scaling sequence models in vision by borrowing memory stabilizers previously applied in language.
Limitations include heuristic Bottom-k selection and a lack of interpretability for its parameter, as well as the absence of validation on thousands-of-frames or kilometer-scale trajectories, where hybrid memory or retrieval-augmented architectures may still be necessary.
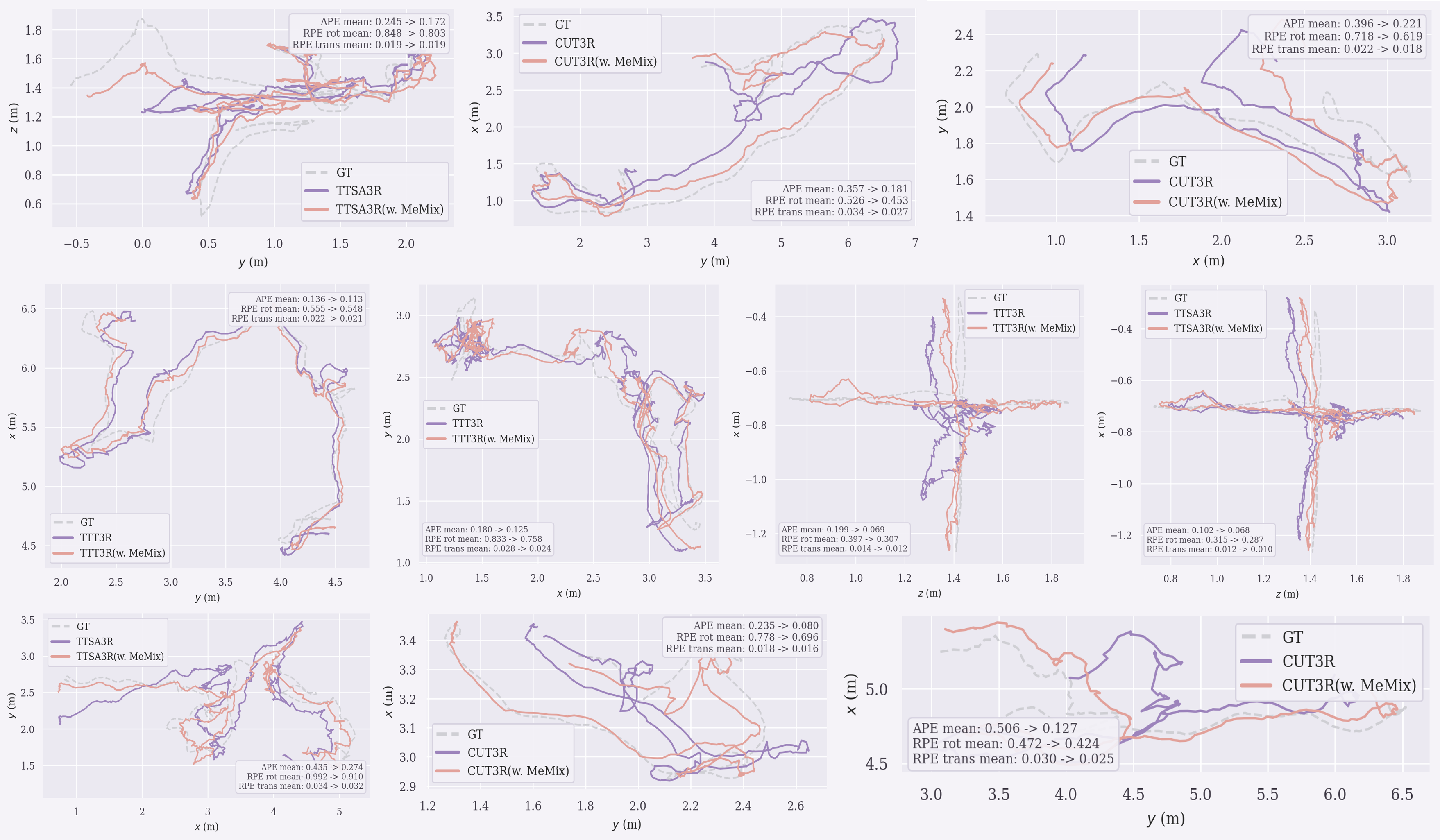
Figure 9: Long sequence camera pose visualization; MeMix variants more closely track the ground truth and mitigate drift over time.
Conclusion
MeMix introduces an inference-time, training-free memory mixture update that resolves catastrophic forgetting in fixed-state streaming 3D reconstruction. Across datasets, tasks, and backbones, MeMix consistently stabilizes long-horizon inference, recovers coherent geometry, and improves global pose and depth metrics, all while preserving computational footprint and deployment simplicity. The method motivates further study into sparse state routing, domain-adaptive memory management, and the integration of geometry-aware update policies for next-generation spatial intelligence systems.
Reference:
"MeMix: Writing Less, Remembering More for Streaming 3D Reconstruction" (2603.15330)