LoGeR: Long-Context Geometric Reconstruction with Hybrid Memory
Abstract: Feedforward geometric foundation models achieve strong short-window reconstruction, yet scaling them to minutes-long videos is bottlenecked by quadratic attention complexity or limited effective memory in recurrent designs. We present LoGeR (Long-context Geometric Reconstruction), a novel architecture that scales dense 3D reconstruction to extremely long sequences without post-optimization. LoGeR processes video streams in chunks, leveraging strong bidirectional priors for high-fidelity intra-chunk reasoning. To manage the critical challenge of coherence across chunk boundaries, we propose a learning-based hybrid memory module. This dual-component system combines a parametric Test-Time Training (TTT) memory to anchor the global coordinate frame and prevent scale drift, alongside a non-parametric Sliding Window Attention (SWA) mechanism to preserve uncompressed context for high-precision adjacent alignment. Remarkably, this memory architecture enables LoGeR to be trained on sequences of 128 frames, and generalize up to thousands of frames during inference. Evaluated across standard benchmarks and a newly repurposed VBR dataset with sequences of up to 19k frames, LoGeR substantially outperforms prior state-of-the-art feedforward methods--reducing ATE on KITTI by over 74%--and achieves robust, globally consistent reconstruction over unprecedented horizons.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces LoGeR, a new AI method that builds detailed 3D maps from very long videos (thousands to tens of thousands of frames) quickly and consistently. Instead of using slow, heavy optimization like traditional SLAM systems, LoGeR is a fast, “feedforward” model that processes the video in manageable pieces while keeping the whole scene’s shape and scale steady over time.
Key questions the authors wanted to answer
- How can we make fast AI models handle minutes-long videos without running out of memory or getting confused?
- How do we keep both:
- local details sharp from one moment to the next, and
- the global structure stable over long distances (so the map doesn’t “drift” or change size)?
- Can a model trained on relatively short clips still work well on very long videos?
How the method works (in everyday terms)
Think of turning a long movie into a 3D map. Doing this all at once is too heavy for the computer, and the model forgets what happened far back in time. LoGeR solves this with two simple ideas:
- Split the video into chunks
- Like reading a long book chapter by chapter.
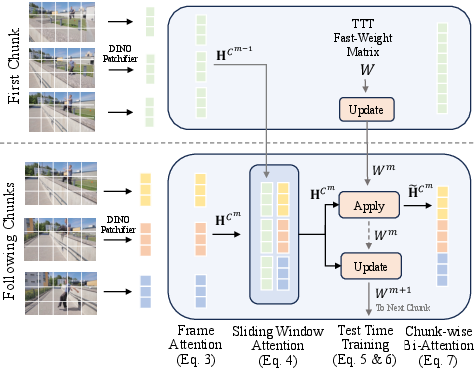
- Inside each chunk, the model uses powerful “look both ways” attention (bidirectional attention) to understand how frames relate and to produce detailed 3D points and camera positions.
- Connect the chunks with a “hybrid memory” LoGeR uses two kinds of memory at the same time, each good at a different job:
- Sliding Window Attention (SWA):
- Imagine keeping a few “recent pages” open side-by-side.
- The model directly looks at the previous chunk when processing the current one.
- This passes along uncompressed, high-detail information so neighboring chunks line up cleanly.
- It’s fast because it only looks at nearby chunks.
- Test-Time Training (TTT):
- Imagine a compact summary notebook you keep updating as you go.
- The model stores a compressed memory of what it has seen (using “fast weights”) and updates it while it runs.
- This helps maintain the global scale and orientation of the whole scene over long stretches, reducing drift.
- It’s efficient and grows linearly with the length of the video.
Optional add-on: LoGeR* (LoGeR star)
- A simple “snap-into-place” step that aligns each new chunk to the previous one using their overlapping frame.
- Think of it as gently adjusting a puzzle piece to fit exactly with the last piece.
Training and “the data wall”
- The team trains on sequences up to 128 frames but carefully designs the model so it generalizes to thousands of frames at test time.
- They also use a curriculum (start easier, get harder) and mix in larger-scale datasets to help the model learn how to handle long scenes.
- This tackles two big challenges: the “context wall” (attention is expensive on very long sequences) and the “data wall” (most training data has short clips, but we want long videos).
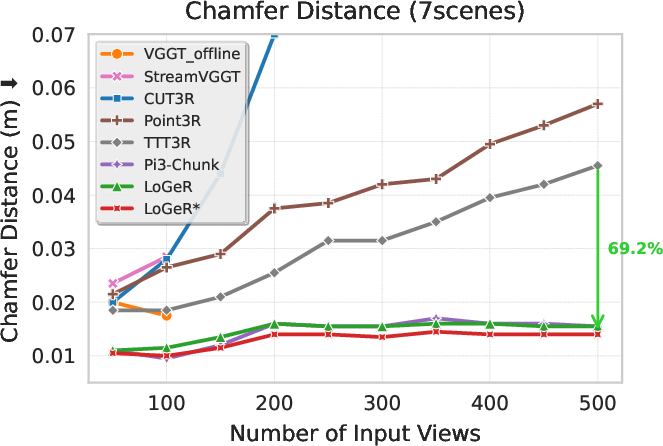
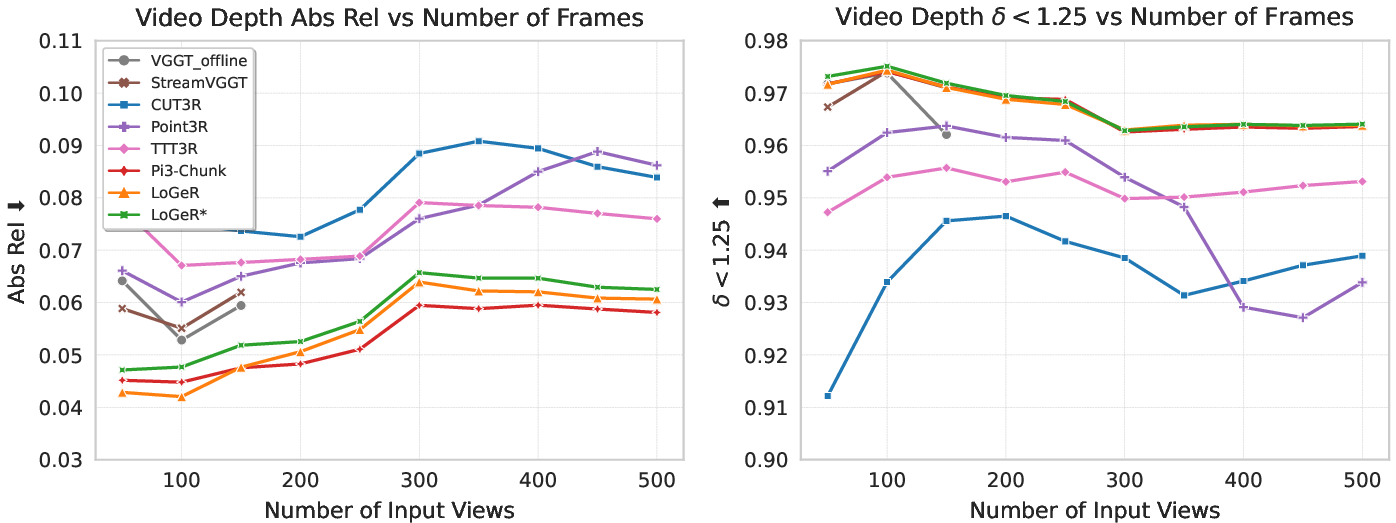
Main findings and why they matter
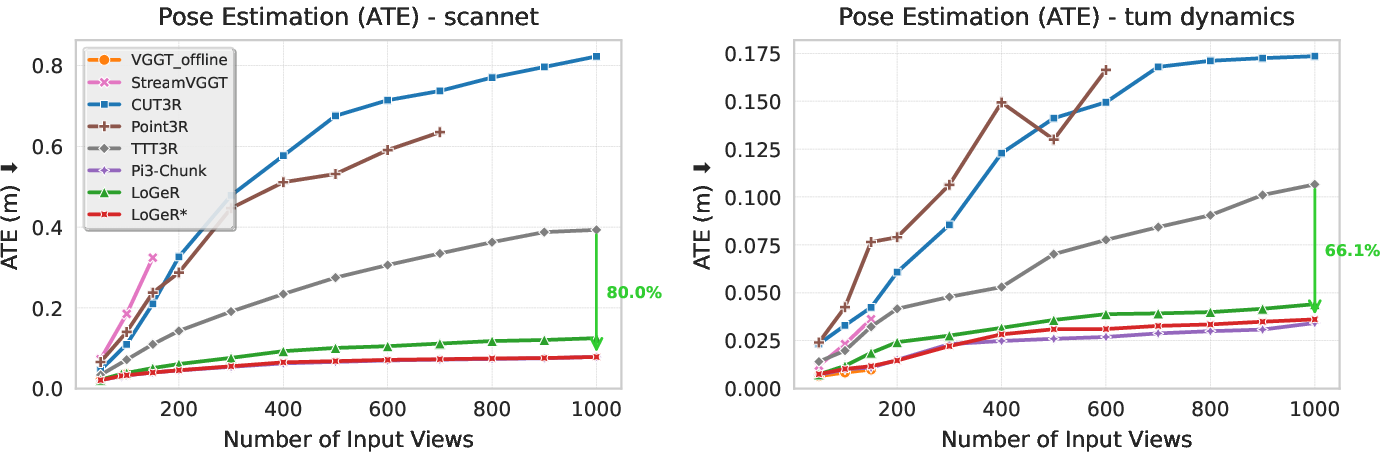
- Much better accuracy on long sequences:
- On the KITTI benchmark, LoGeR reduces trajectory error (ATE) from about 72.86 to 18.65 meters among feedforward methods, a big improvement.
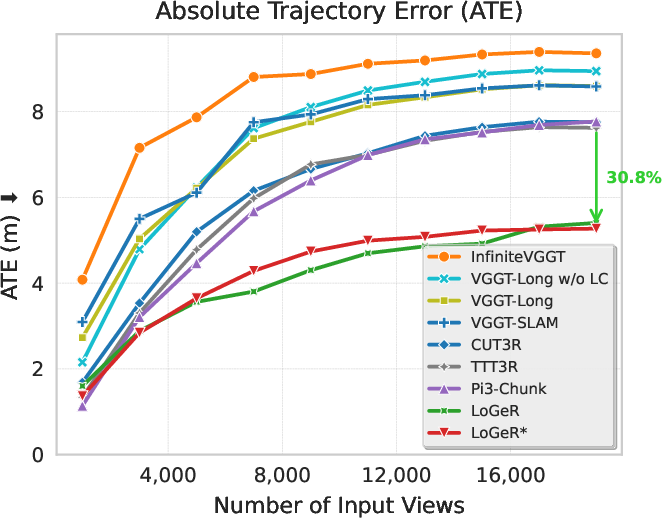
- On very long city-scale videos from the VBR dataset (up to ~19,000 frames and 11.5 km), LoGeR improves results by about 30.8% over previous feedforward approaches.
- Stable global shape and scale:
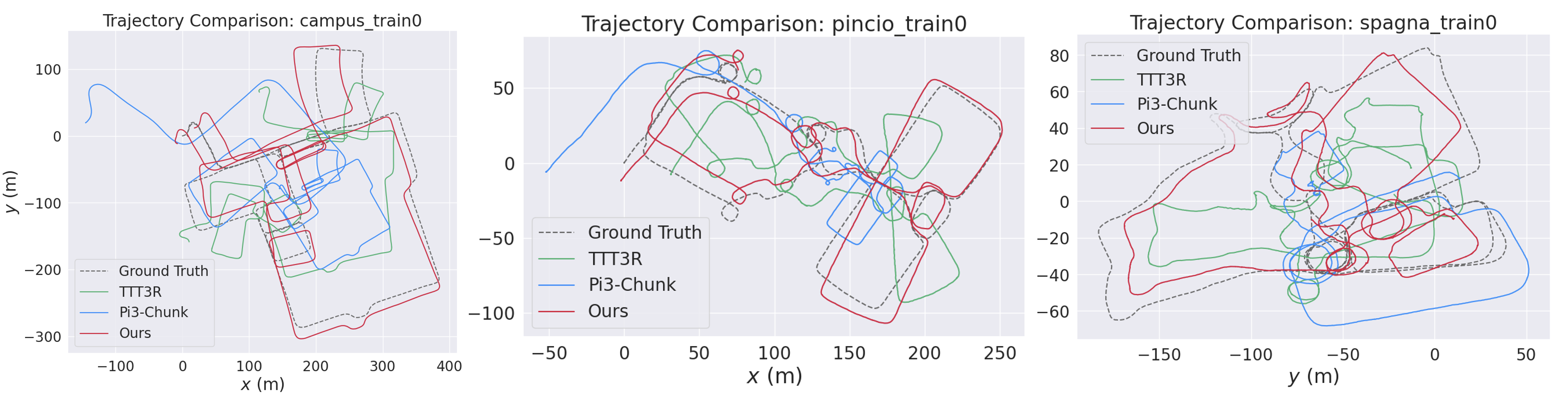
- The model avoids “scale drift,” where things slowly grow or shrink in the map.
- It preserves fine details between adjacent chunks and closes loops more reliably.
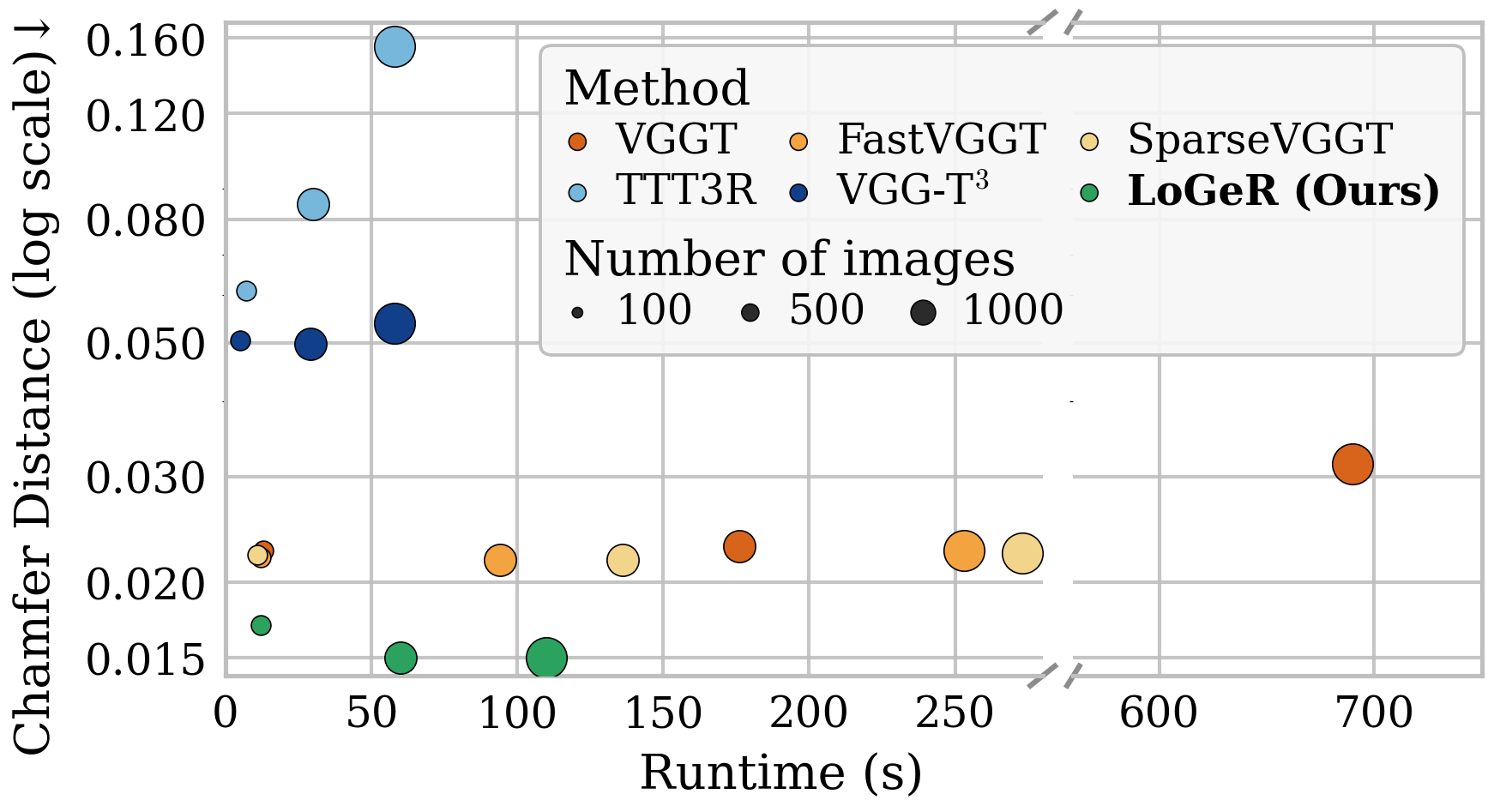
- Efficient and scalable:
- Because LoGeR uses chunking plus hybrid memory, its compute grows steadily with video length instead of exploding, letting it handle much longer videos without slow post-processing.
Why this matters: Better long-range 3D reconstruction means more reliable maps for robots, AR/VR, and autonomous systems. It also makes it easier to turn long videos into accurate 3D scenes without waiting for slow optimization steps.
What this could lead to (implications)
- Real-time or near real-time mapping for robots and self-driving cars across long routes.
- More robust AR/VR experiences that keep consistent scale and geometry over large spaces.
- Faster, more scalable 3D scene creation from consumer videos or drones.
- The hybrid memory idea (detailed short-term + compact long-term) could help other long-context vision tasks, not just 3D mapping.
In short: LoGeR shows that splitting long videos into chunks and combining two kinds of memory—one for precise recent details and one for compressed global context—can deliver accurate, large-scale 3D reconstructions quickly and consistently.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Length generalization of TTT fast weights: The model requires periodic state resets to avoid drift on very long sequences (>1k frames). How to design fast-weight mechanisms that maintain stability and accuracy without resets and generalize beyond the trained context length?
- Reset policy design: Resets are applied every five windows, but no principled, adaptive criterion is provided. Can we develop error- or uncertainty-triggered reset policies (or learned reset gates) that minimize context loss while preventing divergence?
- Memory interference and capacity: As fast weights are continually updated, earlier information may be overwritten (interference/forgetting). What are the capacity limits and interference dynamics of the TTT memory in this setting, and can partitioned, gated, or sparse-update policies mitigate them?
- TTT update objective and hyperparameters: The paper adopts a TTT update with Muon and a self-supervised loss but does not ablate objective variants, learning rates, or optimizer settings. Which update objectives, schedules, or meta-learned hyperparameters yield the best long-horizon stability?
- Read/write policies for TTT: There is no mechanism to gate or filter memory writes (e.g., under motion blur or low texture). Can confidence-weighted or content-aware write/read policies reduce error injection and improve robustness?
- SWA–TTT interplay and placement: SWA is inserted at four layers and attends over adjacent chunks only. What is the sensitivity to the number/positions of SWA layers, SWA window size, and attention sparsity patterns, and how do these choices trade off local vs. global consistency?
- Chunking strategy: Chunk size, stride, and overlap (e.g., single-frame vs multi-frame overlap) are set heuristically. How do these parameters affect drift, loop consistency, and compute, and can we learn or adapt chunking online based on scene dynamics and uncertainty?
- Robust loop closure without optimization: The approach relies on adjacent-chunk SWA and TTT compression; there is no explicit non-adjacent re-localization/loop-closure mechanism. How can a feedforward loop-closure module (e.g., retrieval + alignment) be integrated into the hybrid memory?
- Failure under weak overlaps: When the overlap frame(s) between chunks are unreliable (blur, lighting change, occlusion), SWA cannot help and TTT is lossy. What strategies (e.g., multi-frame overlaps, keyframe retrieval, robust overlap selection) improve resilience to poor adjacency?
- Metric scale estimation: ATE is reported after Umeyama alignment, and the model uses per-sequence scale during training. Can the method recover metric scale in monocular setups (or leverage auxiliary cues) and how accurate is it without global alignment?
- Dynamic and non-rigid scenes: The method and losses largely assume static, rigid geometry. How does the model perform with significant dynamics (crowds, traffic), and can motion segmentation or layered scene models be integrated into the hybrid memory?
- Geometry evaluation at kilometer scale: On VBR, results emphasize pose ATE; there is limited evaluation of dense reconstruction fidelity (e.g., long-range drift of pointmaps, map completeness/consistency). What metrics and protocols best assess dense geometry at city scale?
- Long-horizon ablations: SWA/TTT ablations are demonstrated on ≤1k-frame sequences; the impact on 10k–20k frames is not quantified. How do components degrade with length, and what are the scaling laws for drift vs. sequence length and reset interval?
- Real-time performance and compute: End-to-end latency, throughput (FPS), and memory footprint (including TTT update cost) are not reported across resolutions and chunk sizes. Can the system meet real-time constraints on edge hardware, and what are the compute bottlenecks?
- Robustness to sensor artifacts and domain shifts: Rolling shutter, severe motion blur, exposure changes, and lens distortion are not explicitly handled. How robust is LoGeR to intrinsics/extrinsics shifts and uncalibrated cameras, and can pre-rectification or learned undistortion be integrated?
- Resolution scaling: The method’s scalability with input resolution and token density is not analyzed. How do accuracy and compute trade off with high-resolution inputs, and can multiscale tokenization or pyramidal memory reduce cost?
- Training “data wall”: Although the paper biases training toward long-horizon/synthetic datasets, there remains a gap in diverse, real, large-scale data. What is the minimal real-world long-horizon data needed for strong generalization, and how severe are the domain gaps from synthetic?
- Cross-chunk supervision: Training pairs are limited to intra-chunk and overlapping frames; there is no supervisory signal for far-apart frames. Does adding long-range supervision (e.g., sampled nonadjacent pairs or pseudo-loop pairs) improve global consistency?
- Uncertainty estimation: Outputs lack calibrated uncertainty, which could guide TTT updates, overlap selection, and SE(3) alignment. Can predictive uncertainty be integrated to reduce memory corruption and improve robust alignment?
- Multimodal fusion: The architecture is vision-only. How can IMU/GPS/LiDAR be incorporated into the hybrid memory to further anchor global scale and improve robustness over extreme horizons?
- Principled theory/analysis: There is no formal analysis of error propagation, stability, or bounds for the hybrid memory. Can we derive theoretical guarantees or empirical scaling laws that link memory capacity, reset intervals, and drift?
- Reproducibility at scale: The paper repurposes VBR for kilometer-scale evaluation but omits detailed public protocols for long-sequence geometry evaluation. Clear releases of scripts, alignment settings, and ground-truth handling would enable standardized benchmarking.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can be implemented today using LoGeR’s chunk-based, feedforward long-context reconstruction and its LoGeR* variant (with feedforward pose alignment). Each item includes sector tags, suggested tools/workflows, and key dependencies.
- 3D mapping and visual odometry front-ends for robots and drones (Robotics; Manufacturing; Logistics; Agriculture)
- Use LoGeR as a drop-in, optimization-free mapping/odometry module to replace or augment SLAM back-ends in GPS-denied or texture-poor environments. Run chunked inference with small overlaps; enable LoGeR* alignment and periodic TTT resets to curb drift over very long traversals.
- Tools/workflows: ROS2 node for LoGeR; a “Reset Scheduler” that resets TTT fast weights every K chunks; on-robot streaming inference with bounded compute.
- Dependencies/assumptions: GPU/edge accelerator for inference; controlled overlap between chunks (e.g., 1–3 frames); occasional resets; potential IMU fusion for metric scale anchoring; domain fine-tuning for specific robot cameras and environments.
- Fleet log post-processing for large-scale map creation (Automotive/AV; Mobility; GIS)
- Process hours of dashcam/AV logs to produce dense 3D reconstructions at city scale without heavy bundle adjustment. LoGeR’s linear complexity and LoGeR* alignment provide scalable stitching; results can serve map seeding, localization priors, or change detection.
- Tools/workflows: “Video-to-3D” batch pipeline; SIM(3) chunk stitching; map tiling and QA dashboard to automatically detect segments needing re-run or reset; cloud GPU jobs.
- Dependencies/assumptions: Legal permission for data capture; privacy-preserving preprocessing (e.g., face/license blurring); stable overlap planning; retraining for nighttime/weather variability if needed.
- Infrastructure and asset inspection from long UAV videos (Energy; Utilities; Civil Infrastructure)
- Convert long inspection flights into dense 3D for bridges, power lines, wind turbines, oil & gas pipelines. Chunk-wise processing yields consistent spans without costly optimization; improved loop closures help long corridors.
- Tools/workflows: Drone flight planner to enforce overlap; “Asset Reconstruction” service producing point clouds/meshes per flight; progressive export to BIM/GIS.
- Dependencies/assumptions: Sufficient texture/visual features; controlled flight speed and overlap; safety and regulatory approvals; optional GPS/RTK/IMU for metric scale.
- Construction and facility digitalization at scale (AEC/BIM; Real Estate)
- Turn long walk-through videos into building-scale 3D with lower compute budgets than BA-heavy methods. Use LoGeR* to align wing-by-wing scans; export to BIM viewers.
- Tools/workflows: Site “Video-Scan” kits and mobile app; cloud reconstruction; QA tools for drift hotspots and re-capture recommendations; BIM connectors.
- Dependencies/assumptions: Domain fine-tuning for indoor scenes (lighting transitions, repetitive textures); privacy controls for occupied spaces.
- AR content capture for large venues and campuses (AR/VR; Media & Entertainment; Tourism)
- Capture multi-minute videos to produce persistent, drift-minimized 3D anchors for AR navigation and experiences in museums, campuses, or stadiums.
- Tools/workflows: Mobile capture app with live “chunk health” feedback; “Anchor Packager” that cuts the 3D into tiled anchors usable by AR SDKs.
- Dependencies/assumptions: Cross-device generalization (phone cameras); consistent exposure/auto-focus settings; on-device or near-edge inference with chunk scheduling.
- Location capture for film, TV, and game production (Media & Entertainment; Gaming)
- Turn location-scouting long takes into dense 3D recon for pre-viz and environment building; fewer reshoots thanks to better loop closures and less drift.
- Tools/workflows: DCC (Maya/Blender/Unreal) importers; “LoGeR dailies” pipeline that runs overnight on footage; mesh/texturing post-processors.
- Dependencies/assumptions: High-resolution inputs for detail; creative pipeline integration; controlled camera motion to maximize overlap.
- Cultural heritage and urban tourism reconstructions (Public Sector; Nonprofits; Cultural Heritage)
- Build city-scale 3D tours from volunteer or curated long videos (e.g., historical districts, archaeological sites), with improved consistency over kilometers.
- Tools/workflows: Crowd-capture mobile app; public map portal with change history; compliance toolkit for sensitive sites.
- Dependencies/assumptions: Data rights/permissions; privacy filtering; mixed lighting/weather robustness.
- Forensic scene reconstruction from CCTV and bodycam footage (Public Safety; Security)
- Aggregate long surveillance videos into consistent 3D for incident analysis, line-of-sight studies, or trajectory estimation without heavy optimization.
- Tools/workflows: “Forensics Stitcher” that ingests multi-hour streams with chunk overlap; drift monitors and time-slicing exports for legal review.
- Dependencies/assumptions: Camera calibration unknowns and rolling shutter; legal chain-of-custody protocols; careful handling of dynamic actors.
- Academic baseline and benchmarking for long-context vision (Academia)
- Use LoGeR and the repurposed VBR benchmark to stress-test long-horizon modeling, hybrid memory, and chunked training curricula; extend to other tasks (tracking, video QA).
- Tools/workflows: Open-source training recipes with curriculum; ablation harnesses to flip SWA/TTT at inference; leaderboards for >1k frames.
- Dependencies/assumptions: Access to GPUs for training; dataset licensing; reproducible seeds.
- Consumer “long-walk to 3D” capture (Daily Life; Prosumer)
- Turn hiking or neighborhood videos into geo-consistent 3D maps for sharing or personal archiving with drift reduced via LoGeR*.
- Tools/workflows: Mobile app with local chunk pre-processing and cloud upload; privacy redaction before reconstruction; export to WebGL viewers.
- Dependencies/assumptions: Bandwidth for uploads; power constraints; terms of service for public-space capture.
- Privacy and compliance assessment for city-scale 3D (Policy; Governance)
- Pilot tools that test de-identification pipelines (face/plate blurring) and evaluate re-identification risk in dense 3D outputs created from long videos.
- Tools/workflows: “Privacy Risk Scanner” that runs pre/post-reconstruction; DPIA templates for public mapping programs.
- Dependencies/assumptions: Jurisdiction-specific regulations (GDPR/CCPA); stakeholder engagement; auditability of processing pipelines.
Long-Term Applications
The following opportunities rely on further research, scaling, or ecosystem development, including improved length generalization of TTT fast weights, reduced need for resets, robust dynamic-scene modeling, and broader datasets.
- Reset-free, real-time city-scale AR navigation on-device (AR/VR; Mobile)
- Continuous, drift-free mapping and re-localization on phones/headsets without server support, enabling persistent spatial computing across cities.
- Potential products: Spatial OS with “memory-on-device”; AR SDKs that expose long-context anchors.
- Dependencies/assumptions: Efficient on-device accelerators; improved TTT length generalization; power-aware chunk scheduling and memory compaction.
- Fully feedforward SLAM replacement in autonomous driving stacks (Automotive/AV)
- Production-grade, long-horizon feedforward front-ends that maintain absolute scale and consistency over hours without BA/loop closure back-ends.
- Potential products: “LoGeR-AV” perception module; cross-sensor fusion with LiDAR/IMU for robustness.
- Dependencies/assumptions: Safety certification; extreme robustness to weather/night; standardized benchmarks beyond KITTI/VBR.
- Continuous, city-scale digital twins with automated change detection (Smart Cities; Utilities; Urban Planning)
- Always-on capture (vehicle fleets, drones) feeds streaming reconstruction to maintain up-to-date 3D twins; automatic alerts for construction progress, asset degradation, or hazards.
- Potential products: “TwinOps” platform with spatiotemporal diffs; maintenance prioritization tools.
- Dependencies/assumptions: Data governance and consent; sustainable compute costs; integration with GIS and asset management systems.
- Collaborative multi-robot mapping with shared parametric memory (Robotics; Defense; Disaster Response)
- Robots share a global, compressed “TTT Memory Vault” to maintain consistent scale and structure across teams, even with partial overlap and intermittent connectivity.
- Potential products: Memory-as-a-service backends; on-robot fast-weight synchronization protocols.
- Dependencies/assumptions: Federated or privacy-preserving memory sharing; robustness to heterogeneous cameras; consensus under conflicting updates.
- Long-horizon medical video reconstruction (Healthcare)
- Dense 3D reconstruction of entire endoscopic/laparoscopic procedures to aid navigation, documentation, and training.
- Potential products: Surgical 3D viewers with tissue motion compensation; skill assessment analytics.
- Dependencies/assumptions: Domain transfer to specular, deformable tissues; regulatory approval; stringent data privacy and security.
- Wearable navigation aids for the visually impaired (Assistive Tech)
- Long-context mapping and re-localization that guide users over extended routes with consistent 3D understanding.
- Potential products: Low-power wearable with sparse updates to a global memory; haptic/audio guidance.
- Dependencies/assumptions: Robustness to crowds and dynamic objects; privacy-preserving on-device processing.
- Generative world-building and simulation at real-world scale (Gaming; Simulation; AI Agents)
- Turn city-scale captures into editable, simulation-ready worlds; fuse with generative priors for completion and stylization; use for training embodied AI.
- Potential products: “Video-to-Sim” pipeline; procedural completion tools guided by LoGeR’s geometry.
- Dependencies/assumptions: Content licensing; scalable mesh/texturing; dynamic-scene synthesis.
- Environmental and disaster monitoring at scale (Environmental Science; Insurance)
- Periodic reconstructions of coastlines, forests, and flood zones from long aerial/terrestrial videos to detect erosion, encroachment, or damage; inform underwriting and claims.
- Potential products: Risk scoring services; policy pricing tools with 3D change analytics.
- Dependencies/assumptions: Longitudinal data access; standardized uncertainty metrics; regulatory acceptance in underwriting.
- Standards and policy frameworks for public 3D reconstruction (Policy; Standards)
- Governance for city-scale 3D capturing with rules on data retention, re-identification risks, and safe sharing; audit standards for reconstruction pipelines.
- Potential products: Certification programs; compliance toolkits for municipalities and vendors.
- Dependencies/assumptions: Multi-stakeholder consensus; transparent technical reporting (drift, coverage, anonymization effectiveness).
- Cross-domain long-context vision with hybrid memory (Academia; Software)
- Apply the SWA+TTT hybrid to other long-sequence tasks: multi-object tracking, video QA, long-form action understanding, video editing, and long-horizon planning.
- Potential products: “Hybrid Memory” layers in mainstream vision backbones; curriculum strategies for length generalization.
- Dependencies/assumptions: Task-specific objectives; benchmarks for minute-scale sequences; efficient, stable online updates.
Notes on feasibility and dependencies shared across applications
- Compute and latency: While LoGeR is linear in sequence length, high-resolution dense prediction remains compute-intensive. Today, many deployments will rely on server/cloud GPUs or powerful edge devices; real-time on mobile is a longer-term target.
- Length generalization and resets: TTT fast weights trained on limited chunk counts can accumulate error on very long runs. Periodic state resets and LoGeR* alignment are recommended today; reset-free operation is a research target.
- Absolute scale: Monocular inputs may need auxiliary signals (IMU, wheel odometry, altimeter, known baselines) to fix absolute metric scale in some domains.
- Data diversity and domain shift: Robustness to night, weather, rolling shutter, rapid exposure changes, and highly dynamic scenes may require domain-specific fine-tuning and additional training data.
- Privacy, safety, and legal compliance: City-scale and indoor reconstructions must account for PII, sensitive locations, and data retention policies; integrate redaction and DPIA workflows.
- Integration complexity: Successful deployments require chunk scheduling, overlap management, health monitoring for drift, and export pipelines to mapping/BIM/GIS/DCC systems.
Glossary
- Absolute Trajectory Error (ATE): A scalar metric measuring the positional deviation of an estimated trajectory from ground truth (often after alignment). Example: "reducing the Absolute Trajectory Error (ATE) from 72.86 to 18.65,"
- Affine-invariant relative pose loss: A loss that supervises relative camera motion while being invariant to affine transformations. Example: "an affine-invariant relative pose loss, where the losses do not require a reference view."
- Bidirectional attention: Transformer attention that attends to both past and future tokens within a window for stronger context. Example: "where bidirectional attention handles intra-chunk reasoning"
- Bundle adjustment: A nonlinear optimization that jointly refines camera poses and 3D structure. Example: "bundle-adjusted camera poses."
- Chunk-causal: A causal processing design that stitches chunk outputs using only past and overlapping information. Example: "Based on the philosophy of chunk-causal, we also propose a simple baseline built on top of for long sequence reconstruction."
- Chunk-wise processing: Processing long sequences by dividing them into bounded-size chunks handled sequentially. Example: "we argue that end-to-end chunk-wise processing is a practical and effective strategy."
- Curriculum training: A training schedule that progressively increases difficulty to stabilize learning. Example: "we employ a progressive curriculum strategy."
- Fast weights: Parameters updated online during inference to store transient memory and adapt to context. Example: "It achieves this using fast weights, a set of parameters updated during both train and inference time."
- Feedforward pose alignment: A non-iterative alignment step that adjusts predicted poses to a consistent frame during inference/training. Example: "with periodic state resets and an optional feedforward pose-alignment."
- Hybrid memory: A combined memory design that leverages multiple mechanisms (e.g., parametric and non-parametric) to maintain coherence across scales. Example: "we propose a learning-based hybrid memory module."
- Large-Chunk Test-Time Training (LaCT): A TTT variant that updates fast weights at the chunk level for efficiency. Example: "we utilize Large-Chunk Test-Time Training (LaCT)~\cite{zhang2025test}, which has been shown to be more efficient than standard TTT."
- Linear attention: An attention mechanism with computation linear in sequence length, enabling long-context efficiency. Example: "and linear attention~\citep{katharopoulos2020transformers,schlag2021linear} to reduce the quadratic cost of Transformers."
- Loop closure: Detecting revisits to previously seen locations to correct accumulated drift in SLAM. Example: "graph construction, loop closure, and global optimization."
- Muon optimizer: An optimizer used to update fast weights during test time. Example: "and employ the Muon optimizer~\cite{jordan2024muon} for the test-time updates."
- Parametric associative memory: Memory stored in learnable parameters that associates keys with values to compress and recall context. Example: "a parametric associative memory (Test-Time Training~\cite{sun2024learning}) that compresses global context."
- Patchify: To convert images into fixed-size patches that are treated as tokens by a transformer backbone. Example: "The geometry backbone first patchifies images into tokens and feeds them into a stack of residual network blocks."
- Pointmap: A dense per-pixel 3D point representation predicted in camera or world coordinates. Example: "directly outputting pointmaps in a canonical space"
- Scale drift: Gradual inconsistency in estimated global scale over time leading to trajectory deformation. Example: "anchor the global coordinate frame and prevent scale drift,"
- SE(3): The group of 3D rigid body transformations (rotation and translation). Example: "We compute a rigid SE(3) alignment that maps the current chunk to the aligned coordinate system of the previous chunk"
- SIM(3): The group of 3D similarity transformations (rigid motion plus global scale). Example: "compute a SIM(3) transformation based on the overlapping frames to stitch the predictions of different chunks together."
- Sliding Window Attention (SWA): Local attention across adjacent windows/chunks that preserves high-fidelity short-range context. Example: "composing Sliding Window Attention (SWA) for detailed local memory"
- Slow weights: The base model parameters that remain fixed during inference, in contrast to fast weights. Example: "the model's base parameters, or slow weights, which remain frozen during inference."
- State-space models: Sequence models that represent dynamics via latent state evolution governed by state-space equations. Example: "Efficient long-sequence architectures revisit recurrent/state-space models~\citep{gu2021efficiently,gu2024mamba} and linear attention"
- SwiGLU: An activation/MLP variant combining Swish and gated linear units, used in fast-weight layers. Example: "we implement the fast weight architecture using SwiGLU layer"
- Test-Time Training (TTT): On-the-fly updating of a model’s fast weights during inference to accumulate and exploit context. Example: "Test-Time Training (TTT) for compressed global context."
- Umeyama alignment: A closed-form similarity alignment used to align predicted and ground-truth trajectories. Example: "after Umeyama alignment~\cite{umeyama1991least},"
Collections
Sign up for free to add this paper to one or more collections.