Stop Probing, Start Coding: Why Linear Probes and Sparse Autoencoders Fail at Compositional Generalisation
Abstract: The linear representation hypothesis states that neural network activations encode high-level concepts as linear mixtures. However, under superposition, this encoding is a projection from a higher-dimensional concept space into a lower-dimensional activation space, and a linear decision boundary in the concept space need not remain linear after projection. In this setting, classical sparse coding methods with per-sample iterative inference leverage compressed sensing guarantees to recover latent factors. Sparse autoencoders (SAEs), on the other hand, amortise sparse inference into a fixed encoder, introducing a systematic gap. We show this amortisation gap persists across training set sizes, latent dimensions, and sparsity levels, causing SAEs to fail under out-of-distribution (OOD) compositional shifts. Through controlled experiments that decompose the failure, we identify dictionary learning -- not the inference procedure -- as the binding constraint: SAE-learned dictionaries point in substantially wrong directions, and replacing the encoder with per-sample FISTA on the same dictionary does not close the gap. An oracle baseline proves the problem is solvable with a good dictionary at all scales tested. Our results reframe the SAE failure as a dictionary learning challenge, not an amortisation problem, and point to scalable dictionary learning as the key open problem for sparse inference under superposition.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but important question about how we “read” what a big AI model is thinking. Many people use two tools for this: linear probes (simple classifiers) and sparse autoencoders (SAEs), which try to break model activations into human-meaningful features. The authors show that both of these tools can fail when the model’s internal signals are “superposed” (many ideas squashed into a small number of activations), especially when we see new combinations of ideas that weren’t in the training data. They argue that the main problem isn’t that we need fancier decoders or more data—it’s that we’re learning the wrong “dictionary” of features in the first place. They suggest focusing on better ways to learn this dictionary.
Key objectives and questions
The authors set out to understand:
- When can we correctly recover which concepts are active inside a model from its compressed activations?
- Why do linear probes and SAEs often break when tested on new combinations of known ideas (out-of-distribution, or OOD)?
- Is the failure caused by the way we decode each example (inference), or by the set of features we learned to decode with (the dictionary)?
Methods explained simply
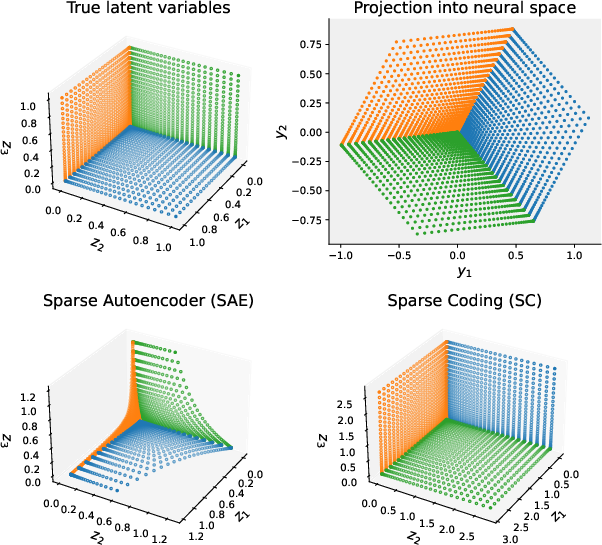
Think of a model’s activations like a shadow. Many high-level “concepts” (say, topics like “Paris,” “past tense,” “negation”) are mixed together and projected into fewer activation dimensions—like a 3D object casting a 2D shadow. This mixing is called superposition. If only a few concepts are active at once (sparsity), it’s possible to reconstruct which ones were active even from a compressed “shadow,” but you typically need nonlinear methods to do it well.
The paper compares three approaches:
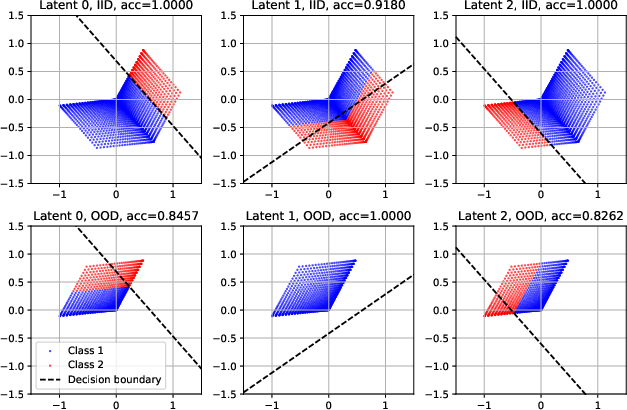
- Linear probes: A simple straight-line rule tries to read a concept directly from activations. Works if the boundary between “yes” and “no” is straight in activation space—but compression can bend that boundary into a curved one, so linear probes miss it.
- Sparse Autoencoders (SAEs): Learn an encoder that produces a sparse code (only a few features turned on) and a decoder “dictionary” that recombines those features to reconstruct the activation. SAEs “amortize” inference, meaning they learn a fixed shortcut to decode any input in one go. This shortcut can fit training patterns but fail on new combinations.
- Per-sample sparse coding (e.g., FISTA): Instead of a fixed shortcut, this solves a small optimization problem for each input to find the few features that best reconstruct the activation. It’s slower but more reliable, especially when combinations change. It needs a good dictionary.
Important ideas, with everyday analogies:
- Dictionary: Like a set of Lego pieces. If you have the right pieces, you can build any structure. If your pieces are wrong, no building method will save you.
- Amortization gap: If you learn a shortcut based on training combos, that shortcut can break when the combos change (like memorizing recipes instead of learning to cook).
- Compositional generalization: Being able to handle new “recipes” made from familiar ingredients.
The authors test these methods on controlled toy problems where they know the ground truth, and on many scales. They hold out certain combinations of concepts during training and test on those withheld mixes (OOD).
Main findings and why they matter
Here’s what they discovered:
- Linear probes can look good in training but fail on new combos. Even if a label is a straight line in concept space, the compression bends it in activation space. A straight-line probe can’t follow a bent boundary.
- SAEs do nonlinear decoding, but their “learned shortcut” fits co-occurrence patterns from training. When new combinations appear, performance drops. This is the amortization gap.
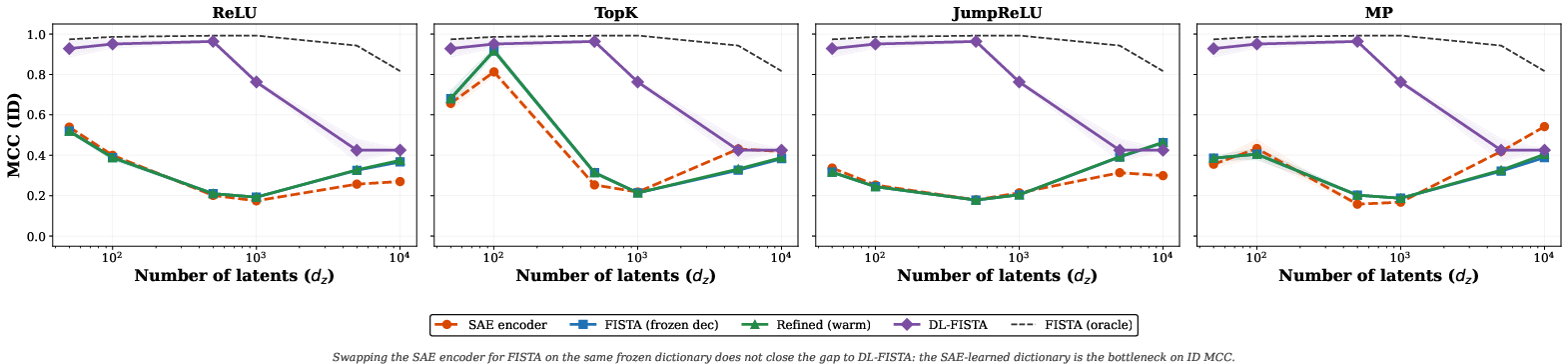
- The big surprise: the main bottleneck is the dictionary, not the encoder. If you keep the SAE’s dictionary and replace its encoder with a careful per-example solver (FISTA), it still doesn’t fix the problem much. That means the features themselves point in the wrong directions.
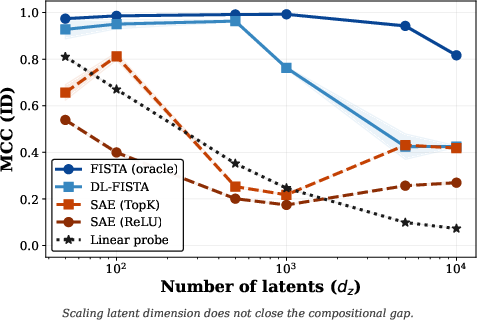
- With an oracle dictionary (the true directions), per-example inference recovers concepts almost perfectly—even OOD—across all tested scales. So the problem is solvable in principle.
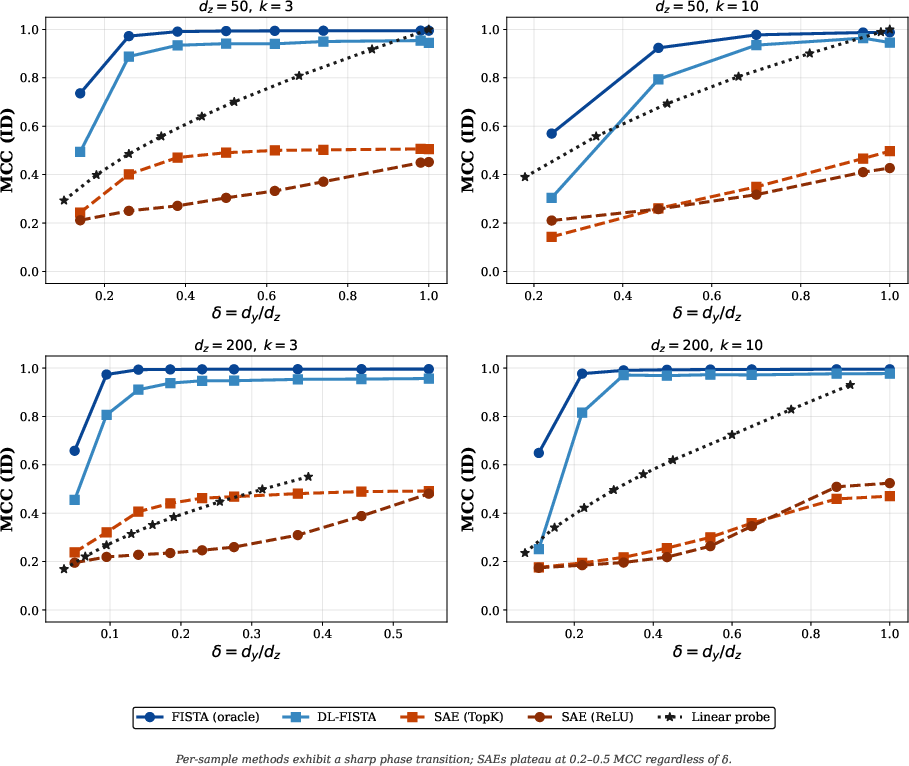
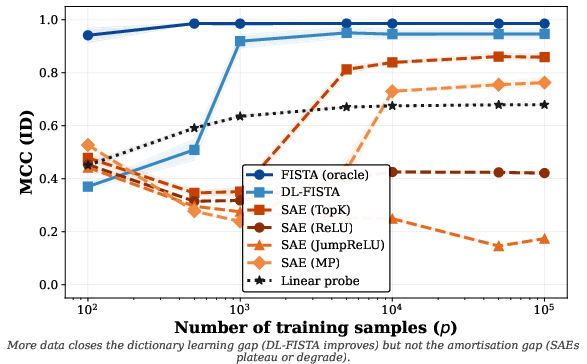
- Classical dictionary learning plus per-sample inference (DL-FISTA) learns better dictionaries than SAEs at small and medium scales and outperforms linear probes OOD when it succeeds. But as the number of possible concepts grows very large, dictionary learning becomes harder for everyone.
- More training data does not fix SAEs’ amortization gap. Giving SAEs much more data didn’t make them catch up. In contrast, more data did help classical dictionary learning (DL-FISTA) a lot.
Why this matters:
- It’s not enough that representations are “linear” at some level. After compression, the easy-to-read “straightness” can be lost.
- Nonlinear, per-example decoding is often necessary—and it can work very well if the dictionary is good.
- The key challenge is learning the right dictionary at scale.
Implications and impact
- For interpretability: Be cautious about relying on linear probes or standard SAEs to find stable, reusable “features.” They may look good in-distribution but fail on new combinations.
- For robust AI behavior: If we want systems that generalize to new mixes of known ideas, we need better dictionary learning methods that produce correct, sparse features. Once the dictionary is good, per-sample sparse inference can recover active concepts reliably—even when combinations shift.
- For research directions:
- Invest in scalable, principled dictionary learning under sparsity (the “compressed sensing” viewpoint).
- Evaluate methods on compositional OOD tests, not just in-distribution.
- Don’t conflate “linearly represented” with “linearly decodable.” Compressed activations often require nonlinear decoding.
In short: Stop relying on probing shortcuts that fit training patterns. Start “coding”—learn the right feature dictionary and use robust sparse inference—if you want stable, generalizable understanding of what models represent.
Knowledge Gaps
Below is a single, concrete list of the main knowledge gaps, limitations, and open questions that remain unresolved by the paper; each item is phrased to guide actionable follow‑up research.
- External validity to real LLMs: Do the paper’s conclusions, derived from controlled linear superposition with synthetic data, hold on real LLM activations where the LRH is only approximate and noise/residual nonlinearities are present?
- Noise robustness: How do dictionary learning and per-sample inference perform under additive noise, heavy-tailed noise, or structured/model-mismatch noise in activations (beyond the near-noiseless setting implicitly used)?
- Model mismatch beyond exact LRH: What is the impact of systematic deviations from linearity (e.g., layerwise nonlinearities, saturation, residual paths) on sparse recovery and OOD compositional generalisation?
- Characterising “ill-posed” regions: Can we design diagnostics to detect when a downstream label is not a function of (due to collisions under ), and how often this occurs in real activations?
- Beyond binary single-latent labels: How do results change for multi-label/multiclass targets, labels depending on multiple latents (e.g., logical AND/OR/XOR), regression targets, or non-thresholded functions of ?
- Broader OOD regimes: Does the amortisation/dictionary gap persist under other shifts (e.g., changes in sparsity level , shifts in latent value distributions, novel supports of larger cardinality, or correlated/antagonistic co-activations)?
- Unknown and variable sparsity: How to recover when is unknown, varies across inputs, or exceeds the theoretical thresholds sporadically? Can adaptive per-sample sparsity control improve OOD generalisation?
- Nonnegativity and sign structure: The experiments use but inference and losses are sign-agnostic; does imposing nonnegativity or sign constraints on codes/dictionaries improve identifiability and OOD performance?
- Dictionary learning at scale: What algorithms can reliably learn dictionaries that enable recovery when (e.g., – atoms) under realistic compute/memory budgets, without saturating at low MCC?
- Enforcing RIP/incoherence during learning: Can we design practical training objectives or regularisers (e.g., mutual coherence penalties, spectral constraints) that induce dictionaries satisfying RIP-like conditions at relevant sparsities?
- Sample complexity of dictionary learning: What are tight, practical sample-complexity bounds for learning identifiable dictionaries under the paper’s compositional OOD splits and sparse latent distributions?
- Initialisation strategies: Which initialisations (e.g., PCA/whitening, K-SVD seeds, random Gaussian, learned from broader support coverage) make dictionary learning more stable and scalable in the overcomplete regime?
- Structured/parametric dictionaries: Can structured dictionaries (e.g., convolutional, block-structured, hierarchical/group-sparse) reduce learning complexity while preserving recoverability and OOD compositionality?
- Hybrid pipelines: Do pipelines that (i) learn dictionaries via classical alternating minimisation (or other DL) and (ii) amortise only inference via deep unfolding (LISTA/ALISTA with tied weights) close the gap more than SAEs?
- Missing baselines: How do deep-unfolded sparse coders (LISTA/ALISTA), unrolled FISTA with learned step sizes, or OMP-based per-sample methods compare to both SAEs and DL-FISTA in ID and OOD regimes?
- Encoder–decoder tying: Would tying SAE encoders to their decoders via unrolled optimisation constraints (rather than free encoders) improve generalisation to unseen supports?
- Regularisation and training protocols: Are SAE failures due in part to suboptimal hyperparameters (e.g., sparsity penalties, TopK thresholds, learning rates) or training curricula? Systematic sweeps/ablation studies are missing.
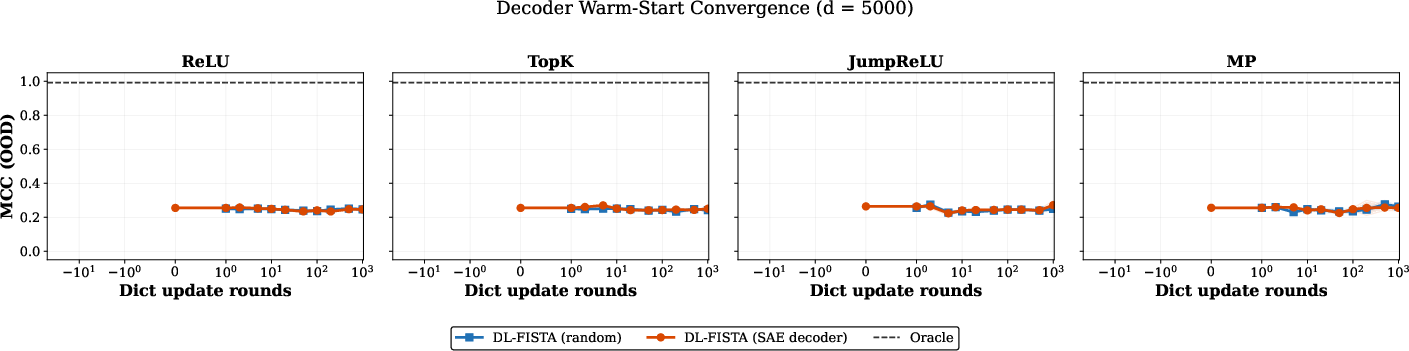
- Warm starts beyond cosine proximity: Are there better warm-start strategies for per-sample inference than SAE codes (e.g., multi-step amortised initialisers, coarse-to-fine thresholding) that improve support recovery on frozen dictionaries?
- Measuring dictionary errors: The paper states SAE dictionaries “point in wrong directions,” but lacks quantitative analyses (e.g., subspace angles, mutual coherence, RIP constants, spark proxies); which metrics best predict OOD failure?
- Activation pre-processing: How do whitening, normalisation, or random projection preprocessing of activations affect dictionary identifiability, RIP properties, and OOD generalisation?
- Nonlinear probing baselines: Can simple nonlinear readouts (e.g., kernel logistic regression, shallow MLPs) on raw activations close much of the gap to per-sample sparse coding, and when do they fail relative to sparse methods?
- Computation–accuracy trade-offs: How do per-sample inference methods degrade under tight compute budgets (few ISTA/FISTA iterations), and can learned unrolled networks match oracle FISTA with far fewer steps?
- Support coverage vs sample count: Beyond more samples, how does diversity of observed supports (combinatorial coverage) drive dictionary identifiability and OOD robustness, and how can training data be curated to maximise this?
- Partially supervised DL: Can a small amount of supervision (e.g., labels or known supports for a subset of samples) guide dictionary learning toward disentangled atoms and improve OOD compositional generalisation?
- Cross-layer and cross-domain transfer: Do dictionaries learned at one layer or domain transfer to others, and does per-sample sparse inference preserve compositionality across layers better than SAEs?
- Detecting when linear probes suffice: Can we characterise conditions (on , , and the label function) under which linear probes will not incur nonlinear distortions after projection, enabling a priori method selection?
- Formalising boundary nonlinearity: Provide theoretical bounds linking , , and properties of to the induced nonlinearity and Bayes error of linear probes in -space for latent-linear labels.
- Robustness to correlated latents: How do dictionary learning and sparse inference behave when latent factors exhibit strong correlations or structured co-activation (violating independent support assumptions)?
- Distribution of latent magnitudes: Sensitivity analysis for different active-value distributions (signed, heavy-tailed, discrete) rather than uniform [0,1]; do these alter identifiability and OOD behaviour?
- Bias terms and centring: How should offsets/biases (present in SAEs) be handled in compressed sensing–style pipelines; does centring or bias-aware inference materially affect recovery and OOD tasks?
- Benchmarks and datasets: A standardised suite of compositional OOD benchmarks for interpretability methods (beyond toy set-ups) on real LLM activations is lacking; what tasks and splits best stress-test compositionality?
- Practical scaling claims: Although CS theory suggests dictionary size can grow exponentially with , real training faces memory/compute limits; a systematic study of practical scaling laws is missing.
- Detecting ill-posed recovery online: Methods to detect when a given is compatible with multiple sparse codes yielding different labels (non-functionality), and policies for abstention or uncertainty quantification, are not explored.
Practical Applications
Practical Applications of “Stop Probing, Start Coding: Why Linear Probes and Sparse Autoencoders Fail at Compositional Generalisation”
Below we distill actionable, real-world uses of the paper’s findings and methods, grouped by time horizon. Each item notes sectors, possible tools/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
These can be deployed today using existing tooling and moderate engineering effort.
- Build OOD-robust interpretability pipelines for foundation models (software, AI labs, safety teams)
- What to do: Replace or augment SAE-based pipelines with per-sample sparse inference (e.g., FISTA/ISTA/LISTA) on moderate-size layers to recover concept-level codes; use DL-FISTA at small-to-medium latent scales when dictionary learning works.
- Tools/workflows: PyTorch/JAX implementations of FISTA/ISTA; SPAMS/Lightning/Sklearn Lasso for dictionary learning; layer-wise activation dumping; evaluation with MCC/accuracy/AUC as in the paper.
- Dependencies/assumptions: Access to activations; sufficiently sparse co-activations (small k); manageable dictionary size; compute budget for per-input iterative inference; LRH approximately holds for chosen layers.
- Introduce compositional-OOD evaluation harnesses for interpretability methods (industry, academia)
- What to do: Adopt the paper’s withheld co-occurrence split (hold out combinations of latent factors) as a standard eval for SAEs, linear probes, and sparse coding methods; report MCC and downstream accuracy/AUC ID vs OOD.
- Tools/workflows: Dataset generators that hold out factor combinations; CI tests for interpretability regressions; dashboards.
- Dependencies/assumptions: Ability to approximate “factor” co-occurrences through prompts/tasks; sufficient data diversity; reproducible activation extraction.
- Diagnose SAE failures with “frozen-decoder FISTA” tests (software/AI labs)
- What to do: After training an SAE, freeze its decoder and run FISTA on it to disentangle encoder vs dictionary failures. If FISTA does not improve, the dictionary is the bottleneck.
- Tools/workflows: Plug-in module that swaps SAE encoder with FISTA; hyperparameter sweeps for λ; reporting templates.
- Dependencies/assumptions: Access to SAE weights; stable numerical behavior for iterative solvers; moderate compute.
- Safer activation steering via per-sample sparse inference (AI safety, alignment)
- What to do: Localize features associated with behaviors using pointwise inference to avoid brittle SAE-driven steering; steer via activation edits on reliably recovered features.
- Tools/workflows: FISTA-based feature identification; steering hooks in inference servers; A/B tests on steering efficacy OOD.
- Dependencies/assumptions: Actionable mapping from codes to steering interventions; sparse recoverability in targeted layers; governance of intervention risks.
- Audit and de-risk linear probing in production (software, content moderation, finance compliance)
- What to do: Validate linear-probe signals by checking for nonlinearity induced by superposition; where risks are high, backstop linear probes with sparse coding heads or nonlinear classifiers.
- Tools/workflows: Nonlinearity checks via OOD splits; swap-in sparse coding for high-stakes decisions; calibration monitoring.
- Dependencies/assumptions: Clear OOD definitions; monitoring infrastructure; acceptance of slightly higher latency.
- Data curation for better dictionary learning (R&D, applied ML)
- What to do: Proactively collect training data that increases support diversity and sparsity (reduce systematic co-activations) to improve learned dictionaries.
- Tools/workflows: Prompt/program synthesis that varies factor combinations; active data collection for underrepresented compositions.
- Dependencies/assumptions: Ability to influence data; observability of co-activation patterns; privacy/compliance constraints.
- Sector-specific immediate wins
- Healthcare (clinical LLMs, medical QA): Use sparse inference for concept-level sanity checks on critical outputs; detect spurious co-occurrence shortcuts across specialties.
- Finance (KYC/AML, model risk): Replace brittle linear-probe signals with sparse coding for OOD scenarios (e.g., novel transaction combinations).
- Robotics (policy interpretability): Apply pointwise inference to disentangle task primitives and detect novel co-activations that cause control failures.
- Energy/IoT (predictive maintenance): Recover sparse fault factors from sensor mixtures for robust anomaly detection.
- Tools/workflows: Domain-specific OOD splits; per-decision concept audits; anomaly and drift dashboards.
- Dependencies/assumptions: Domain data sparsity; compliant logging of activations/sensors; compute budget for iterative decoding.
- Engineering guidance for setting k, d_y, d_h (ML engineering, MLOps)
- What to do: Use the paper’s compressed-sensing rule-of-thumb: choose k and d_h so that d_y ≳ C·k·ln(d_h/k) (C≈2) to keep recovery feasible; avoid training SAEs in regimes where unique recovery is impossible.
- Tools/workflows: Pre-deployment feasibility calculator; pipeline guards that alert when k/d_h choices violate bounds.
- Dependencies/assumptions: Reasonable estimates of k; layer-specific d_y known; adherence to constraints during training.
- Academic curricula and tutorials on “linear representation vs linear accessibility” (education, research)
- What to do: Integrate the paper’s geometric arguments into interpretability courses and lab trainings; provide toy demos similar to Fig. 1 and Fig. 4.
- Tools/workflows: Teaching notebooks; visualization utilities.
- Dependencies/assumptions: None beyond standard course infra.
Long-Term Applications
These require further research, scaling advances, or infrastructure changes.
- Scalable dictionary learning at foundation-model scale (software, AI labs, academia)
- What to build: GPU/TPU-accelerated, online algorithms for dictionary learning that maintain RIP-like properties and scale to 106–107 features; hybrid LISTA+DL objectives tied to compressed-sensing theory.
- Products: “Dictionary server” that trains/serves dictionaries alongside model checkpoints; open-source libs with streaming updates.
- Dependencies/assumptions: New optimization methods; memory-efficient factorization; convergence guarantees at scale.
- Concept atlases for foundation models (software, safety, policy)
- What to build: Stable, shareable “atlas” of reliably recovered features across layers and domains, with provenance and OOD performance guarantees.
- Products: Browsable atlas portals; APIs for querying and steering concepts; “explain-ability bundles” for audits.
- Dependencies/assumptions: Scalable dictionary learning; versioning and monitoring for concept drift; governance frameworks.
- Compositionality-aware model training (research, foundation model providers)
- What to build: Training objectives and architectures that encourage sparse, diverse, and identifiable representations (e.g., regularizers that favor RIP-compatible encoders or curriculum that reduces co-activation shortcuts).
- Products: Training plugins; compositional risk minimization combined with sparse recoverability metrics.
- Dependencies/assumptions: Access to pretraining pipeline; willingness to adjust objectives; measurable trade-offs with model quality.
- Certified explanations for high-stakes AI (policy, regulation, healthcare, finance)
- What to build: Standards and audits based on pointwise sparse inference for per-decision explanations that are robust under OOD compositions; certification checklists that include compositional-OOD tests.
- Products: RegTech assessment suites; reporting formats linking outcomes to sparse features with stability evidence.
- Dependencies/assumptions: Regulatory buy-in; activation access; standardization of metrics and protocols.
- Robustness monitors for OOD compositions (safety engineering, MLOps)
- What to build: Real-time detectors that flag shifts in co-activation patterns and activate fallback decoders (e.g., per-sample sparse inference) when novel compositions arise.
- Products: Runtime gates; observability dashboards; automated A/B routing between decoders.
- Dependencies/assumptions: Low-latency iterative solvers; high-quality dictionaries; integration into serving infra.
- Mechanistic alignment and intervention frameworks (AI safety)
- What to build: Training-time and inference-time interventions guided by reliably recovered sparse latents (e.g., penalize undesired feature co-activations; reinforce desired compositions).
- Products: “Mechanistic guardrails” modules; red-teaming toolkits that stress-test compositional generalization.
- Dependencies/assumptions: Validated concept atlases; non-destructive interventions; monitoring for regressions.
- Cross-modal and embodied extensions (vision, speech, robotics)
- What to build: Apply compressed-sensing-based concept recovery to multimodal models and policies (e.g., disentangling visual and linguistic factors or skills).
- Products: Multimodal concept atlases; policy debuggers for complex tasks.
- Dependencies/assumptions: Sparsity holds in targeted layers; scalable dictionary learning for high-dimensional modalities.
- Hardware acceleration for iterative sparse inference (semiconductor, systems)
- What to build: On-accelerator kernels for FISTA/ISTA/LISTA (possibly unrolled networks with guarantees) to cut latency for per-sample decoding in production.
- Products: CUDA/XLA kernels; compiler passes; firmware primitives.
- Dependencies/assumptions: Vendor support; predictable convergence behavior; interoperability with existing serving stacks.
- Data governance for sparse recoverability (policy, data engineering)
- What to build: Organizational policies and data pipelines that deliberately maintain sufficient sparsity and support diversity to enable identifiable dictionaries.
- Products: Data “sparsity scorecards”; automated prompt/data generation to cover rare compositions.
- Dependencies/assumptions: Ability to shape data distributions; tracking of co-activation statistics; privacy-preserving logging.
- Benchmarks and community standards (academia, open-source)
- What to build: Public compositional-OOD interpretability benchmarks and leaderboards that evaluate recovery (MCC) and downstream OOD performance across methods.
- Products: Datasets, baselines, metrics packages; reproducibility kits.
- Dependencies/assumptions: Community adoption; compute sponsorship; clear task taxonomies.
Notes on feasibility across all applications:
- Core assumptions: approximate linear representation in chosen layers; sufficiently sparse active concepts (k small relative to d_y and d_h); dictionaries with RIP-like behavior or learned to approximate it.
- Key risks: when k is large or activations are dense, unique recovery may be impossible regardless of method; access to proprietary model activations may be restricted; per-sample inference increases latency/compute; dictionary learning is the main bottleneck at scale and remains an open research problem.
Glossary
- Activation steering: Techniques that intervene on model activations to steer behavior or outputs. "linear probing for concept discovery and activation steering"
- Additive decoders: Decoder architectures that compose outputs by summing contributions of features, often to enforce disentanglement. "such as additive decoders"
- Amortisation gap: The systematic performance difference between amortised encoders and per-sample optimisation, especially under distribution shift. "We show this amortisation gap persists across training set sizes, latent dimensions, and sparsity levels"
- Amortised autoencoding: Learning both encoder and decoder jointly so that a single forward pass produces a (typically sparse) code and reconstruction. "SAEs, the dominant amortised approach in interpretability, are amortised autoencoding"
- Amortised inference: A feed-forward, learned approximation to an optimisation-based inference procedure over a training distribution. "Amortised inference \citep{gregor2010learning}, as implemented by Sparse Autoencoders (SAEs)"
- Basis pursuit: An optimisation method that recovers sparse signals by minimising an ℓ1 norm under linear constraints. "e.g., basis pursuit, iterative thresholding"
- Compressed sensing: Theoretical framework guaranteeing recovery of sparse signals from undersampled linear measurements under suitable conditions. "Compressed sensing is precisely the framework that characterises when sparse signals can be recovered"
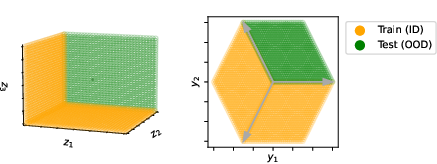
- Compositional generalisation: The ability to handle novel combinations of learned components or concepts. "Compositional generalisation---the ability to understand and produce novel combinations of learned concepts---remains a fundamental challenge for neural networks"
- Compositional risk minimisation: A training objective that seeks robustness to compositional shifts by enforcing structure at training time. "compositional risk minimisation"
- DL-FISTA: A hybrid method that alternates dictionary learning with FISTA-based per-sample sparse inference. "Classical dictionary learning (DL-FISTA) produces better dictionaries at small scale"
- Dictionary atoms: The columns of a dictionary matrix that serve as basis elements for sparse representation. "a consistent sparse selection of dictionary atoms"
- Dictionary learning: The process of estimating the decoding matrix whose columns define the feature basis used for sparse codes. "we identify dictionary learning---not the inference procedure---as the binding constraint"
- FISTA: Fast Iterative Shrinkage-Thresholding Algorithm; an accelerated method for ℓ1-regularised sparse recovery. "per-sample FISTA on the same dictionary does not close the gap"
- Ill-posedness: A setting where a problem lacks a unique or stable solution, often due to non-invertible mappings. "Ill-posedness arises when with but "
- In-distribution (ID): Data drawn from the same distribution as training, used to assess performance without distribution shift. "in-distribution (ID) amortisation strategies"
- Independent component analysis (overcomplete): ICA in the regime where the number of latent sources exceeds the number of observed variables. "overcomplete independent component analysis"
- Injectivity: A property of a mapping where distinct inputs produce distinct outputs, ensuring uniqueness of recovery. "Ensuring injectivity under overcompleteness."
- ISTA (Iterative Shrinkage-Thresholding Algorithm): An iterative method for solving sparse coding problems via gradient and thresholding updates. "Algorithms such as Iterative Shrinkage-Thresholding Algorithm (ISTA) and FISTA compute"
- JumpReLU: A ReLU-like activation with a learned thresholding “jump” used in some SAE encoders. "JumpReLU \citep{rajamanoharan2024jumpingaheadimprovingreconstruction}"
- Linear probes: Linear classifiers trained on fixed activations or features to test for linear accessibility of information. "linear probes trained on top of LLM activations"
- Linear representation hypothesis (LRH): The assumption that model activations encode high-level concepts as linear mixtures. "The linear representation hypothesis (LRH) is a foundational assumption in mechanistic interpretability"
- Linear unmixing: A linear transformation intended to invert mixing and recover latent sources from observed activations. "one cannot simply learn a linear unmixing to map activations back to concepts"
- LISTA: Learned ISTA; an unrolled, trainable version of ISTA that amortises sparse inference. "amortised sparse inference (e.g., LISTA"
- Mean Correlation Coefficient (MCC): A metric assessing identifiability by measuring alignment between inferred features and ground-truth latents. "The mean correlation coefficient (MCC) evaluates identifiability"
- Monosemantic features: Learned features that correspond to single, interpretable concepts rather than mixtures. "monosemantic features"
- Oracle baseline: A reference method with access to ground-truth components (e.g., dictionary) to establish an upper bound on achievable performance. "An oracle baseline proves the problem is solvable"
- Out-of-distribution (OOD): Test data drawn from a distribution different from training, used to assess robustness to shifts. "out-of-distribution (OOD) compositional shifts"
- Overcompleteness: The regime where the number of latent or code dimensions exceeds the number of observed dimensions. "When (overcompleteness)"
- Overcomplete regime: The undersampled setting where observations are lower-dimensional than codes. " is the overcomplete regime."
- Per-sample inference: Solving the sparse coding optimisation separately for each input rather than using a learned encoder. "per-sample inference"
- Phase transition: A sharp change in recovery performance predicted by compressed sensing as sampling crosses a critical threshold. "Compressed sensing theory predicts a phase transition in sparse recovery"
- Restricted Isometry Property (RIP): A matrix property ensuring that all sparse vectors approximately preserve their lengths after projection, enabling unique recovery. "restricted isometry property (RIP)"
- ROC AUC: Area under the Receiver Operating Characteristic curve; a threshold-free measure of binary classification performance. "ROC AUC"
- Sparse Autoencoders (SAEs): Autoencoders trained to produce sparse latent codes, often with linear decoders for interpretability. "Sparse Autoencoders (SAEs)"
- Sparse coding: Representing data as sparse combinations of dictionary atoms, typically recovered by optimisation. "classical sparse coding"
- Spark (of a matrix): The smallest number of columns that are linearly dependent; used to characterise uniqueness of sparse representations. "spark of a matrix is the smallest number of its columns that are linearly dependent"
- Superposition: Encoding more concepts than activation dimensions by linearly mixing them, causing overlap in activations. "a regime known as superposition"
- Support set: The index set of non-zero entries in a sparse vector. "A support set is drawn first"
- Support variability condition: A diversity condition on observed supports that enables identifying the dictionary. "support variability condition"
- TopK: A sparsity mechanism that retains only the k largest-magnitude activations in a code vector. "TopK \citep{gao2024scalingevaluatingsparseautoencoders, costa2025flat}"
- Undersampling ratio: The ratio of observation to code dimensions controlling the severity of overcompleteness. "We sweep the undersampling ratio "
Collections
Sign up for free to add this paper to one or more collections.

